
带你从头看完java集合框架源码之List
带你从头看完java集合框架源码之List
目录:
上一篇文章带大家阅读了集合框架顶层的接口和抽象类,这一篇文章这介绍第一个接口List的实现类
抽象类AbstractList:
继承了抽象类AbstractCollection,实现List接口,是实现List接口所需要的最小工作,实现该抽象类需要一个可以提供随机访问能力的数据结构支持(例如数组)。如果需要顺序访问,则应该使用AbstractSequentialList。
抽象类AbstractSequentialList:
在抽象类AbstractList中说到实现该抽象类需要一个能有随机访问能力的数据结构,而实现AbstractSequentialList可以提供顺序访问。AbstractSequentialList抽象类规定了实现一个顺序访问list需要的最小工作
接下来我们看list的几个最常用的实现类,分别是实现了AbstractList的ArrayList、Vector和Stack,实现了AbstractSequentialList的LinkedList
类Vector
//继承了AbstractList(随机访问能力),实现了list、RandomAccess、Cloneable、Serializable接口
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
看看成员变量
//存放元素的数组,剩余空间以null填充
protected Object[] elementData;
//元素个数
protected int elementCount;
//扩容时数组容量增加的值,当capacityIncrement为0时,扩容时数组容量翻倍
protected int capacityIncrement;
//序列化ID
private static final long serialVersionUID = -2767605614048989439L;
//最大容量,2^31 - 1 - 8
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
然后是构造方法
//无参构造方法
public Vector() {
this(10);
}
Vector的无参构造方法调用了另一个带参的构造方法
//有参构造方法
//1、传入初始大小和扩容大小的构造方法
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
//2、只传入初始大小的构造方法,默认扩容为double
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
//3、传入一个集合,根据该集合构造
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
可以注意到,第三个构造方法有一个有意思的注释
c.toArray might (incorrectly) not return Object[] (see 6260652)
这是一个官方bug,为什么c.toArray有可能返回的不是Object[]数组呢?我们看到collection中toArray的方法的返回值明明写着Object[]。这里实际上是因为我们创建集合的时候,有可能是通过某个数组创建的,例如
Integer[] test = {new Integer(1),new Integer(2)};
List<Integer> list = Arrays.asList(test);
这时候,我们打印一下test数组的class信息
System.out.println(test.getClass());
//输出class [Ljava.lang.Integer;
然后,我们把由test数组转换成的list,调用toArray方法,打印返回的object数组的class信息
Object[] objects = list.toArray();
System.out.println(objects.getClass());
//输出class [Ljava.lang.Integer;
发现一个问题,竟然不是Object数组,这时候我们把object对象放进这个转换出来的数组,就会报异常(向上转型异常)
Exception in thread "main" java.lang.ArrayStoreException: java.lang.Object
所以在这里说明了,数组的类型取决于里面放的对象是什么类型
接下来我们看Vector的一些方法,可以看到基本上方法都加上了synchronized关键字,说明Vector是线程安全的。当然,单个方法是原子操作并不代表调用他们的组合也是原子的,这点应该不难理解。
public synchronized void copyInto(Object[] anArray) {
System.arraycopy(elementData, 0, anArray, 0, elementCount);
}
public synchronized void trimToSize() {
modCount++;
int oldCapacity = elementData.length;
if (elementCount < oldCapacity) {
elementData = Arrays.copyOf(elementData, elementCount);
}
}
翻看下来,看一下扩容的方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
扩容方法,接受一个参数minCapacity(Vector大小的最小值),扩容后新的容量根据capacityIncrement,如果capacityIncrement为0则容量翻倍,不为0则按capacityIncrement的值来确定。之后判断扩容后的新容量是否达到了最小容量minCapacity,再判断是否比规定的最大容量大,如果是则调用hugeCapacity方法确定容量,最后扩容完毕。
看看处理大容量扩容的hugeCapacity方法
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
溢出的话直接就抛OOM,不溢出就根据minCapacity值(最小容量)返回Integer.MAX_VALUE或MAX_ARRAY_SIZE
下面的方法基本上都是一些比较常规的方法没有特别难理解的,我们来看看clone方法
public synchronized Object clone() {
try {
@SuppressWarnings("unchecked")
Vector<E> v = (Vector<E>) super.clone();
v.elementData = Arrays.copyOf(elementData, elementCount);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
我们常说java有浅拷贝和深拷贝,这里clone方法属于深拷贝的实现。首先调用了父类的clone方法,返回的新的Vector对象,注意此时新对象的elementData是原对象elementData的引用,然后这里调用了Arrays.copyOf方法,完全生成了一个新的数组,里面的元素的值是原Vector中元素的值,所以这里是深拷贝。
接着往下,来到两个用于序列化的方法
private void readObject(ObjectInputStream in)
throws IOException, ClassNotFoundException {
ObjectInputStream.GetField gfields = in.readFields();
int count = gfields.get("elementCount", 0);
Object[] data = (Object[])gfields.get("elementData", null);
if (count < 0 || data == null || count > data.length) {
throw new StreamCorruptedException("Inconsistent vector internals");
}
elementCount = count;
elementData = data.clone();
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
final java.io.ObjectOutputStream.PutField fields = s.putFields();
final Object[] data;
synchronized (this) {
fields.put("capacityIncrement", capacityIncrement);
fields.put("elementCount", elementCount);
data = elementData.clone();
}
fields.put("elementData", data);
s.writeFields();
}
这两个方法可以暂时理解为往流中读对象和写对象,序列化以后再谈(挖坑)
看到重写的removeIf方法
public synchronized boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
final int size = elementCount;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {
removeSet.set(i);
removeCount++;
}
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
// shift surviving elements left over the spaces left by removed elements
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
final int newSize = size - removeCount;
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
elementCount = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}
解释一下这个方法的逻辑,首先是获取当前元素个数,然后创建一个BitSet对象,用来标记要移除的元素下标。(这里有个modCount变量,记录的是Vector对象被修改的次数,在调用removeIf对Vector进行修改时不允许有其他对象对其进行修改,如果发现modCount发生了变化,则抛出ConcurrentModificationException异常。)接下来就是遍历Vector,调用传入的Predicate接口对象,判断当前元素是否要被移除,如果是就在BitSet中标记,最后把所有没有被标记的对象从数组开头开始存放,剩下的所有空间用null填充,返回anyToRemove(假如有元素被移除则返回true,否则false)
最后是Spliterator迭代器的实现,这个等流式计算再讲。
类Stack(栈)
//一打开我们就看到继承了Vector
public class Stack<E> extends Vector<E>
朴实无华的无参构造方法
public Stack() {
}
从它的名字Stack我们就知道这是一个栈,栈的特性就是后进先出,所以Stack类基于Vector下添加了一下几个方法
//调用父类的addElement方法,把元素放在数组末尾
public E push(E item) {
addElement(item);
return item;
}
//弹出栈顶元素,也就是从数组最后一个元素
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
//获取栈顶元素,和pop不一样的是,不会移除栈顶元素
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
//查找元素所在下标
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
可以看到Stack中,除了压栈方法push外,都添加了synchronized关键字,是线程安全的
类ArrayList
现在来看我们List中最常用的类之一,ArrayList。
从名字就看得出来,Array,基于数组实现的列表,我们之前也提到他继承了AbstractList抽象类,这个抽象类要求他的实现类是用具有随机访问能力的数据结构去实现的。
特点:可以存放任意元素(包括null),线程不安全,可以大体上看做不同步的Vector。如果想要实现线程安全,需要如下操作得到一个线程安全的list
List list = Collections.synchronizedList(new ArrayList<>());
//继承AbstractList,实现List<E>, RandomAccess, Cloneable, java.io.Serializable,与Vector没什么区别
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
接下来是成员变量
//序列化ID
private static final long serialVersionUID = 8683452581122892189L;
//默认初始化容量值
private static final int DEFAULT_CAPACITY = 10;
//空数组
private static final Object[] EMPTY_ELEMENTDATA = {};
//同样是一个空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//元素存放的数组
transient Object[] elementData;
//元素个数
private int size;
看看构造方法,首先是无参的
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
无参构造,没有什么特别的地方,直接把默认的空数组赋值给了elementData
然后是有参构造
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
第一个是根据容量大小构造,第二个是根据传入的集合构造,6260652这个官方bug上文已经讲过,这里不再赘述
看一下下面扩容的方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
逻辑上基本上和Vector的差不多,这里扩容默认是增加原来大小的一半,之后就是判断是否比最小容量大,是否溢出
下面是clone方法,也是深拷贝
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
//这里也是重新创建了一个数组,把值拷贝进去
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
下面的方法基本上一路走来都看过很多遍了,addAll啊,clear、remove之类的。
看到removeAll和retainAll方法,同样调用了私有的batchRemove方法,我们看看batchRemove方法。
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
解释一下两个参数,第一个是传入一个集合,第二个参数,false表示移除当前List中包含所有集合c的元素,ture则表示保留所有集合c的元素(以下按false解释,true同理)
for循环,两个指针,r指针遍历整个list,找到不在c集合中的元素,然后从头给list赋值,也就是w指针。下面的finally块,有一个判断,if (r != size),那有人就会好奇了为啥r会不等于size,原因在于遍历时c.contains方法有可能抛出异常,导致没遍历结束循环就戛然而止了,所以需要做收尾工作,把已经遍历好的部分进行整理。另一个判断if (w != size),就是遍历完成后,把剩下的空间赋值清理掉。
接下来是迭代器Iterator和ListIterator的实现,我们之前看过这两个接口,ListIterator对比Iterator,多了前向访问的能力。需要注意的是调用迭代器方法时,每个方法都会调用checkForComodification方法,检查List结构是否被改变(也就是有没有增加或删除元素,当然,修改元素的值是无法检查到的),如果被改变则会抛出ConcurrentModificationException并发修改异常,这说明迭代器在使用的过程中不允许修改List的结构。
private class Itr implements Iterator<E> {
int cursor; // 下一个元素的下标
int lastRet = -1; // 上一个元素的下标,没有上一个元素时,lastRet为-1
int expectedModCount = modCount; //修改次数,用于迭代器工作时检查集合结构是否被改变
//无参构造方法
Itr() {}
//检查是否有下一个元素
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
//检查结构
checkForComodification();
int i = cursor;
//检查下标是否越界
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
//再次检查下标是否越界,可能的并发修改异常
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
//检查下标
if (lastRet < 0)
throw new IllegalStateException();
//检查结构
checkForComodification();
//移除
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
//检查是否还有元素未遍历
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
//检查下标越界
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
//调用consumer接口
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
ListIterator多了add和set方法,以及前向访问能力,基本原理都差不多,就不接着看了。
下面是内部类subList,我们来分析一下subList。首先四个成员变量
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
我们发现前三个成员变量,一个是传递进来的父List,还有起始指针和结束指针,都是用final关键字修饰,说明生成的subList大小不可变
构造方法:
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
可以看出,调用subList方法生成的list对象里面,引用的还是原来的ArrayList,并没有生成新的对象。
下面的方法基本没有什么特别特殊的地方,因为有了大小不可变的限制,对一些方法进行了重写,基本上都是先检查有没有溢出限定的大小,然后调用外部类ArrayList的方法。
最后是ArrayListSpliterator,是Spliterator迭代器的实现,还是后边再讲。
类LinkedList
LinkedList,List接口下另一个常用的实现类,和ArrayList不同的是,底层是链表实现,提供的是顺序访问的能力
特点:双向链表实现,可以插入任意值(包括null),线程不安全。
//继承AbstractSequentialList,实现了List、Deque、Cloneable、java.io.Serializable
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
这个Deque接口上面没讲过,Deque接口继承了Queue接口,我们这里插播一下Deque接口里面有什么东西
接口Deque(双端队列)
方法:基本上就是在Queue的基础上,增加了一些双端队列的特性,两头存取,我们可以看到基本每种操作都有两种形式(从头,或从尾)
//添加元素(头、尾),失败抛IllegalStateException异常
void addFirst(E e);
void addLast(E e);
//添加元素(头、尾),与add的区别是,失败返回false,不会抛异常
boolean offerFirst(E e);
boolean offerLast(E e);
//返回并删除元素(头、尾),失败抛NoSuchElementException异常
E removeFirst();
E removeLast();
//返回并删除元素(头、尾),队列为空时返回null
E pollFirst();
E pollLast();
//返回元素但不删除(头、尾),队列空时抛NoSuchElementException异常
E getFirst();
E getLast();
//返回元素但不删除(头、尾),队列空时返回null
E peekFirst();
E peekLast();
//删除第一次出现的指定元素(从头遍历和从尾遍历)
boolean removeFirstOccurrence(Object o);
boolean removeLastOccurrence(Object o);
从接口中方法的说明可以看出,如果实现类是大小受限的Deque,在修改队列时应该调用offer、poll、peek这些失败不会抛异常的方法。如果实现类容量不受限制,则应该调用add、remove、get这些方法
回到LinkedList,我们可以从继承和实现的接口知道,LinkedList是具有顺序访问能力的双端队列
成员变量:
//元素个数
transient int size = 0;
//头结点
transient Node<E> first;
//尾结点
transient Node<E> last;
Node结点的定义:
//平平无奇的双向链表结点
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
构造方法,首先是无参
public LinkedList() {
}
有参构造,接受一个集合,调用addAll方法
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
既然是双端队列,且是链表实现,那就有头插法和尾插法,我们来看看LinkedList的具体实现
//头插法
private void linkFirst(E e) {
//获取当前链表的头结点
final Node<E> f = first;
//构造新结点,因为是头插,所以之前的头结点就是现在新节点的next结点
final Node<E> newNode = new Node<>(null, e, f);
//新节点为头结点
first = newNode;
//判断是不是链表的第一个结点
if (f == null)
//如果是第一个结点,那么他也是尾结点
last = newNode;
else
//否则之前的头结点的prev指针指向新结点
f.prev = newNode;
size++;
modCount++;
}
/**
* Links e as last element.
*/
//尾插法
void linkLast(E e) {
//获取当前链表的尾结点
final Node<E> l = last;
//构造性结点,尾插法,插在链表尾部,所以之前的尾结点是新结点的prev结点
final Node<E> newNode = new Node<>(l, e, null);
//新结点为新的尾结点
last = newNode;
//判断是不是链表的第一个结点
if (l == null)
//如果是第一个结点,那么他也是头结点
first = newNode;
else
//否则之前的尾结点的next指针指向新结点
l.next = newNode;
size++;
modCount++;
}
/**
* Inserts element e before non-null Node succ.
*/
//插入元素到指定结点之前
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//获取指定结点的前结点
final Node<E> pred = succ.prev;
//构造新结点,因为是插到指定结点之前,所以该指定结点是新结点的next结点,指定结点的前结点是新结点的前结点
final Node<E> newNode = new Node<>(pred, e, succ);
//修改指定结点的prev指针,指向新结点
succ.prev = newNode;
//判断指定结点是不是链表的头结点
if (pred == null)
//是的话相当于头插法,新结点为新的头结点
first = newNode;
else
//不是则修改前结点的next指针指向新结点
pred.next = newNode;
size++;
modCount++;
}
往下看,接口方法的实现跟我们在Deque接口上看得一样,add、remove、get这些方法是会抛异常的,offer、poll、peek这些则不会。
看到addAll方法,链表不像数组,数组的addAll可以直接调System.arraycopy方法整个复制进去,我们看看它是如何实现双端队列的addAll
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
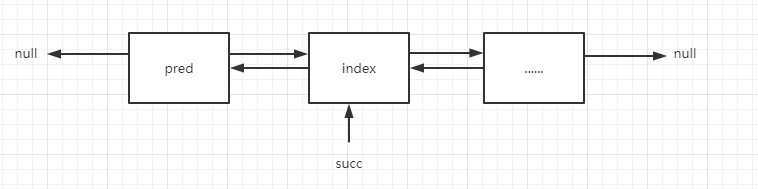
这个方法的实现可以用以下几张图来说明:
首先,保存index结点和index的前向结点pred,因为是要在index这个位置插入,所以是插在pred的后边
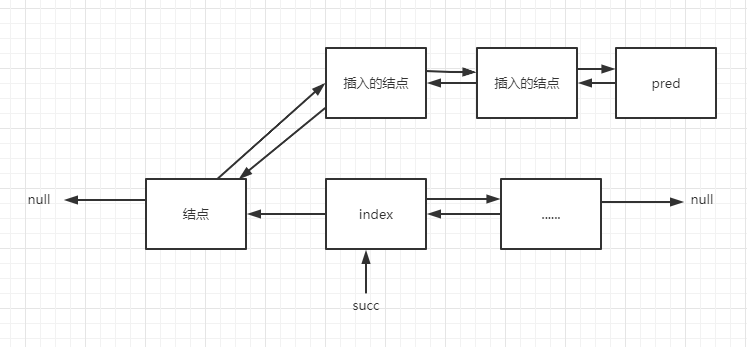
然后不断遍历集合c,将结点插入,pred指针后移,如下图
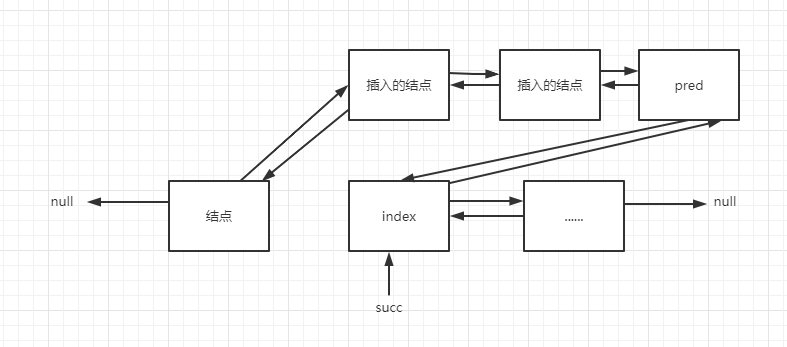
最后修改之前原index结点,也就是succ指针指向的结点,修改他的前向指针指向我们插入的结点的最后一个,然后最后一个结点指向succ结点,插入结束
往下,有一个查找指定下标结点的方法,判断下标的位置在链表左半边还是右半边,选择从头还是从尾进行搜索
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
同样的clone方法,也是深拷贝
public Object clone() {
LinkedList<E> clone = superClone();
// Put clone into "virgin" state
clone.first = clone.last = null;
clone.size = 0;
clone.modCount = 0;
// Initialize clone with our elements
//一个一个的添加clone结点
for (Node<E> x = first; x != null; x = x.next)
clone.add(x.item);
return clone;
}
至此,List接口的内容全部结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号