etcd
简介
etcd是使用Go语言开发的一个开源的、高可用的分布式key-value存储系统,可以用于配置共享和服务的注册和发现。
etcd具有以下特点:
- 完全复制:集群中的每个节点都可以使用完整的存档
- 高可用性:Etcd可用于避免硬件的单点故障或网络问题
- 一致性:每次读取都会返回跨多主机的最新写入
- 简单:包括一个定义良好、面向用户的API
- 安全:实现了带有可选的客户端证书身份验证的自动化TLS
- 快速:每秒10000次写入的基准速度
- 可靠:使用Raft算法实现了强一致、高可用的服务存储目录
场景
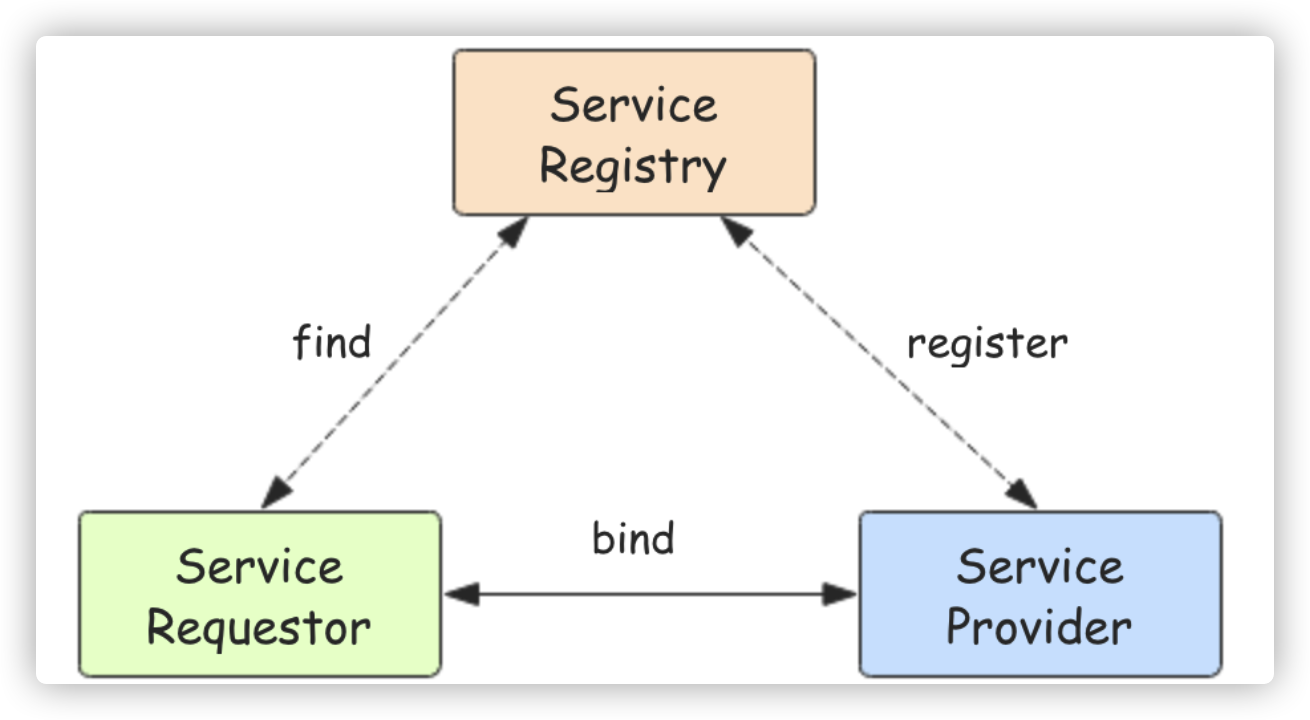
服务发现
服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。
本质上来说,服务发现就是想要了解集群中是否有进程在监听 udp 或 tcp 端口,并且通过名字就可以查找和连接。
配置中心
将一些配置信息放到 etcd 上进行集中管理。
这类场景的使用方式通常是这样:应用在启动的时候主动从 etcd 获取一次配置信息,同时,在 etcd 节点上注册一个 Watcher 并等待,
以后每次配置有更新的时候,etcd 都会实时通知订阅者,以此达到获取最新配置信息的目的。
分布式锁
因为 etcd 使用 Raft 算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
- 保持独占即所有获取锁的用户最终只有一个可以得到。etcd 为此提供了一套实现分布式锁原子操作 CAS(CompareAndSwap)的 API。通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。
- 控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序。etcd 为此也提供了一套 API(自动创建有序键),对一个目录建值时指定为POST动作,这样 etcd 会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用 API 按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
Raft
介绍
- Raft提供了一种在计算系统集群中分布状态机的通用方法,确保集群中的每个节点都同意一系列相同的状态转换
- 它有许多开源参考实现,具有Go,C ++,Java和Scala中的完整规范实现
- 一个Raft集群包含若干个服务器节点,通常是5个,这允许整个系统容忍2个节点的失效,每个节点处于以下三种状态之一
- follower(跟随者) :所有节点都以 follower 的状态开始。如果没收到 leader消息则会变成 candidate状态
- candidate(候选人):会向其他节点“拉选票”,如果得到大部分的票则成为leader,这个过程就叫做Leader选举(Leader Election)
- leader(领导者):所有对系统的修改都会先经过leader
一致性算法
- Raft通过选出一个leader来简化日志副本的管理,例如,日志项(log entry)只允许从leader流向follower
- 基于leader的方法,Raft算法可以分解成三个子问题
- Leader election (领导选举):原来的leader挂掉后,必须选出一个新的leader
- Log replication (日志复制):leader从客户端接收日志,并复制到整个集群中
- Safety (安全性):如果有任意的server将日志项回放到状态机中了,那么其他的server只会回放相同的日志项
领导选举
- Raft 使用一种心跳机制来触发领导人选举
- 当服务器程序启动时,节点都是 follower(跟随者) 身份
- 如果一个跟随者在一段时间里没有接收到任何消息,也就是选举超时,然后他就会认为系统中没有可用的领导者然后开始进行选举以选出新的领导者
- 要开始一次选举过程,follower 会给当前term加1并且转换成candidate状态,然后它会并行的向集群中的其他服务器节点发送请求投票的 RPC来给自己投票。
- 候选人的状态维持直到发生以下任何一个条件发生的时候
- 他自己赢得了这次的选举
- 其他的服务器成为领导者
- 一段时间之后没有任何一个获胜的人
日志复制
- 当选出 leader 后,它会开始接收客户端请求,每个请求会带有一个指令,可以被回放到状态机中
- leader 把指令追加成一个log entry,然后通过AppendEntries RPC并行地发送给其他的server,当该entry被多数server复制后,leader 会把该entry回放到状态机中,然后把结果返回给客户端
- 当 follower 宕机或者运行较慢时,leader 会无限地重发AppendEntries给这些follower,直到所有的follower都复制了该log entry
- raft的log replication要保证如果两个log entry有相同的index和term,那么它们存储相同的指令
- leader在一个特定的term和index下,只会创建一个log entry
etcd的内部机制
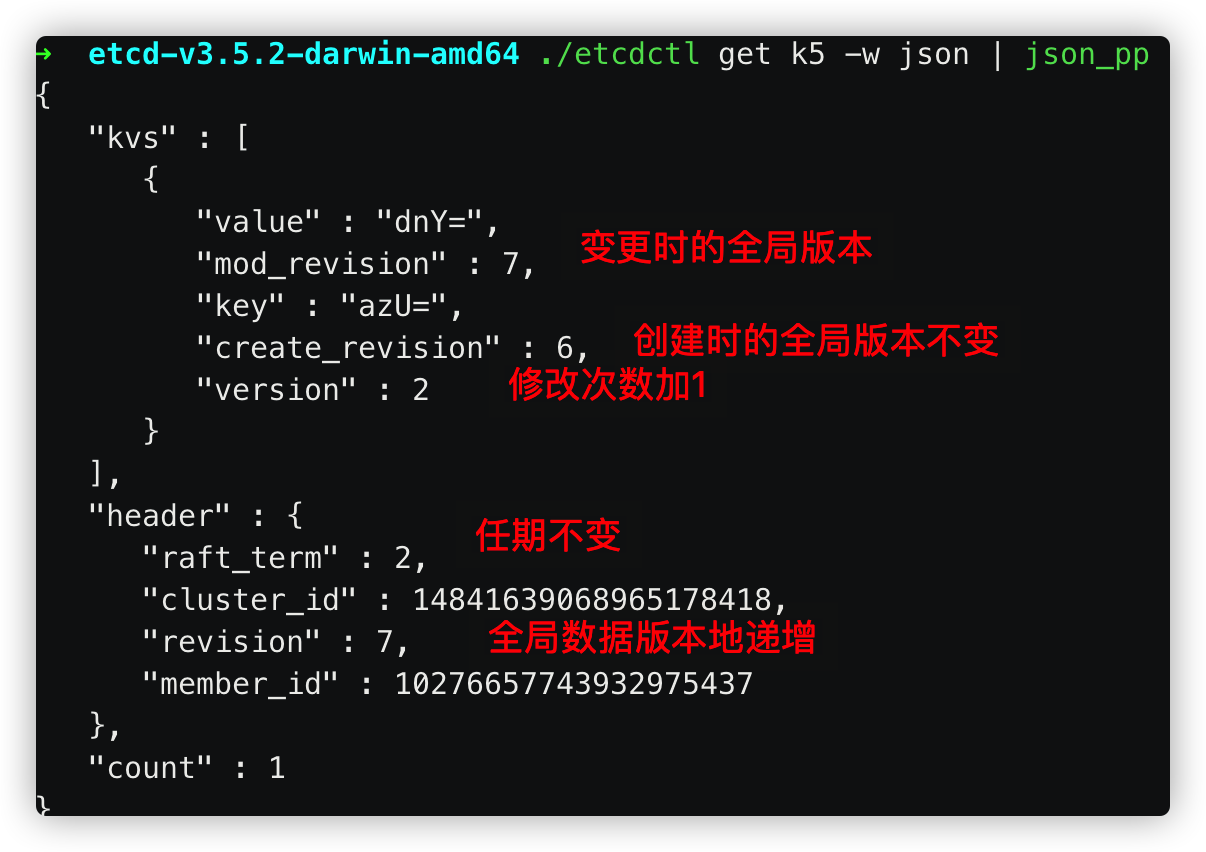
etcd的数据版本号机制:
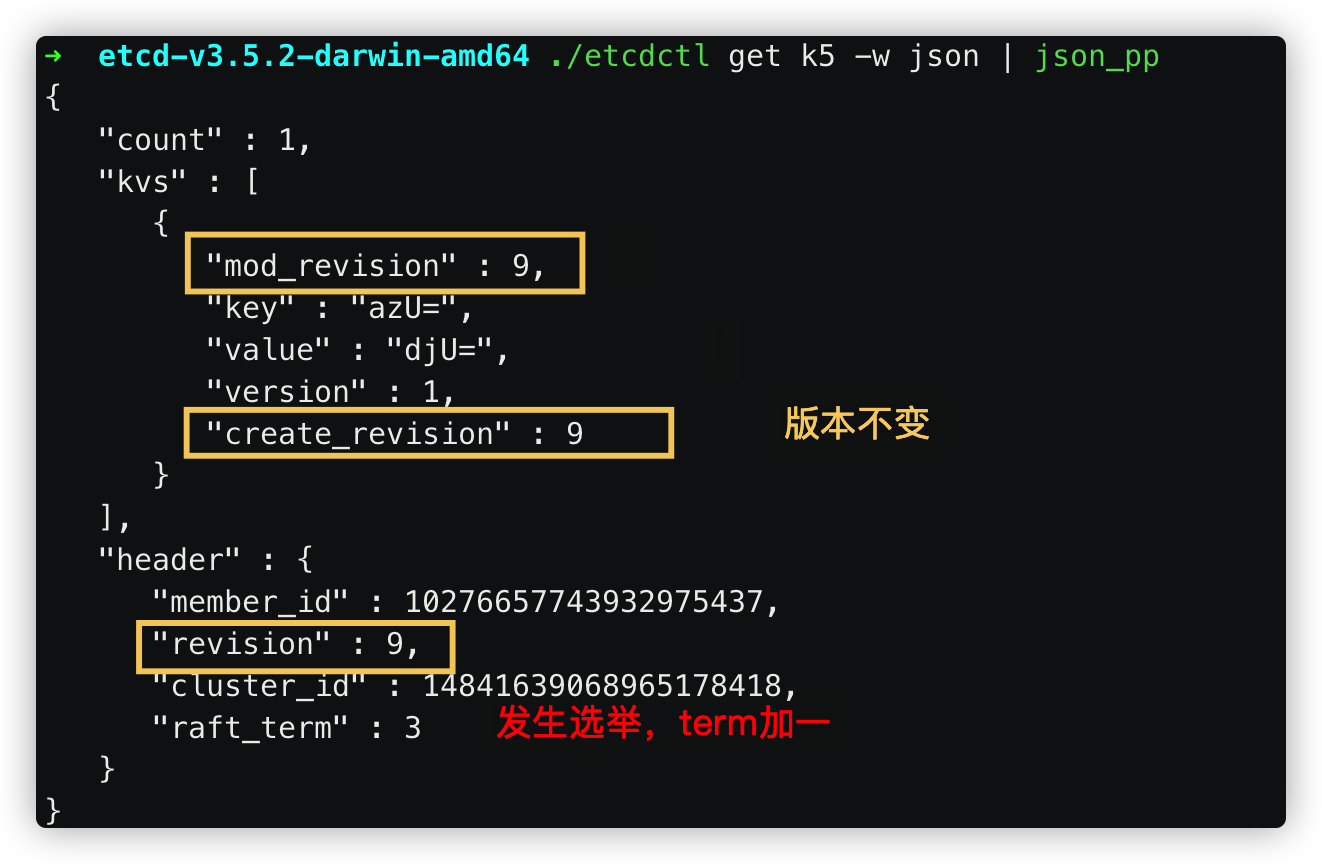
term:全局单调递增。 每当出现新的leader,term就递增
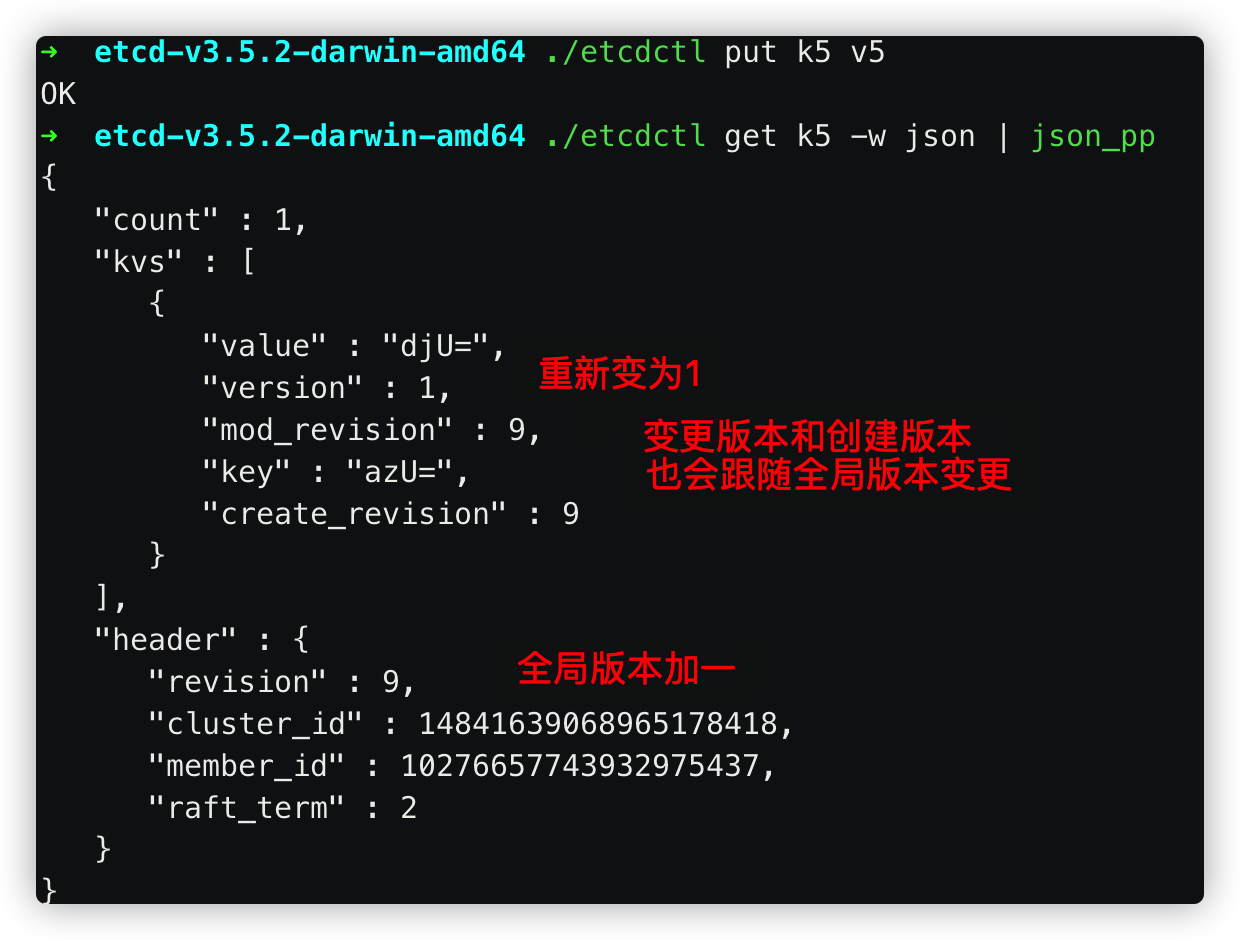
revision:全局单调递增。全部数据的版本。每当数据发生变更,包括新增、修改和删除,都会递增。正是由于revision,etcd支持mvcc和数据的watch
keyValue:
create_resivion:数据创建的版本号
modify_revision:数据修改的版本号
vision:数据被修改的次数
数据以b+树的数据结构存储在磁盘中,并以mmap的方式映射到内存中,加速查询操作。存储的数据是revision->value。通过版本查询对应的数据。
又以一颗b数存储key和revision的关系,通过key知道revision,然后再通过revision找到value。
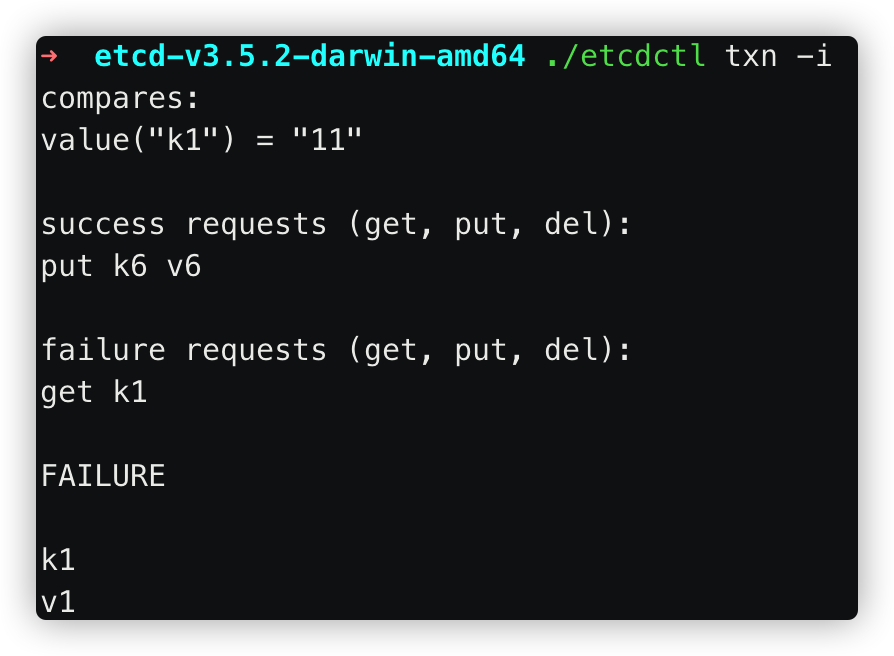
transaction:
Txn.if(
Compare(Value(k1), ">", "v1"),
Compare(Version(k1),"=",2),
...
).Then(
Put(k2,v2),
delete(k3),
...
).Else(
Put(k4,v4)
).Commit()
lease:
lease=CreateLease(10s)
put(k1, v1,lease)
...
lease.KeepAlive()
lease.Revoke()
在分布式系统中,可为某个服务创建一个租约,并通过keepalive进行续约,当服务挂了,etcd就会回收,以此来判断服务是否存活。
此外,etcd将多个相同租约期相同的key绑定在一个lease对象上,降低etcd判断key是否到期的压力。
常用操作

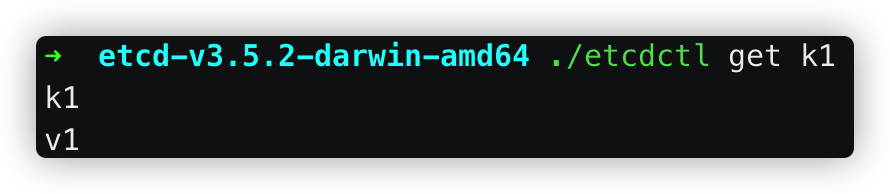
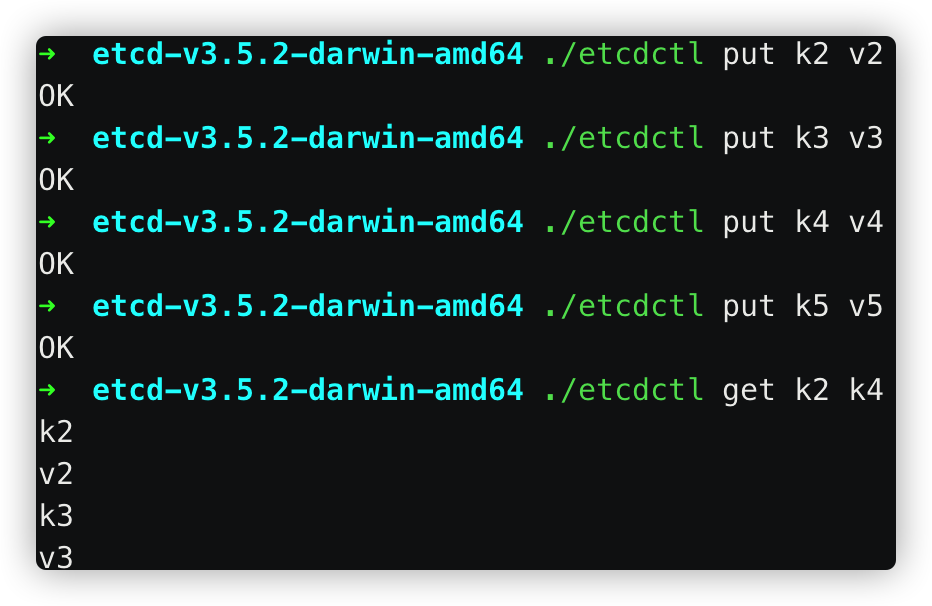
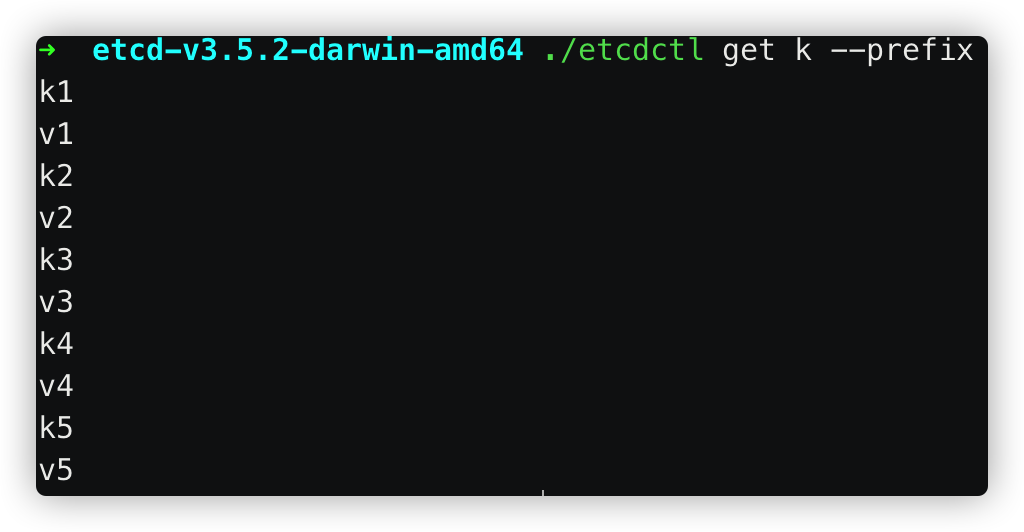

此时,修改k5的值之后,再查看
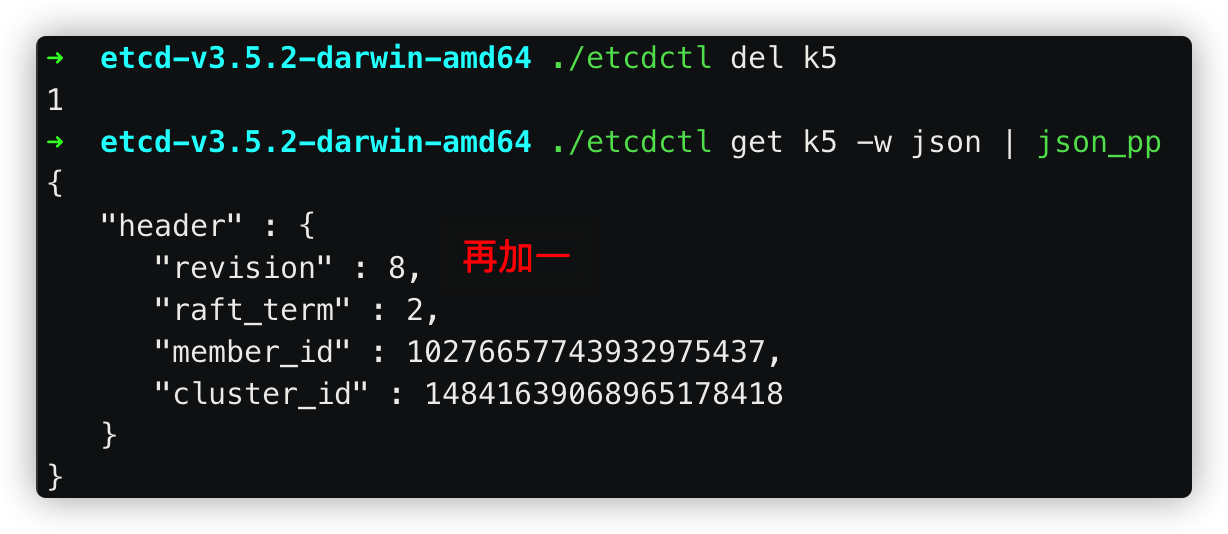
重启etcd。
事务操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号