
从事IT行业十五年+,最近有个运行中项目的列表页面,在本地测试台式机执行效率在三秒以内,布署到服务器(32G内存,16G Cpu)后反而执行20秒+ ,百思不得其解。
解决办法
※以下部分内容来自博主的文章
1.首先查看max_write_lock_count
我个人认为这不是报错的主要原因,因为这是写入空间,如果报错则应该会在导入数据时报错,而不是到运行查询分类时报错(纯粹个人见解,如若不当请多包涵!)
查询语句:show global variables like 'max_write_lock_count';
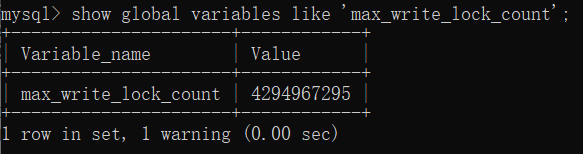
可以看出这个空间的value值有4G,足够存储我的数据,应该不是报错主因。
2.其次查看innodb_buffer_pool_size
查询语句:show global variables like 'innodb_buffer%';
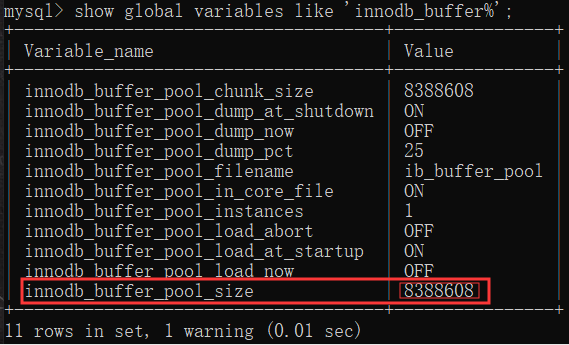
innodb_buffer_pool_size 的默认大小为 8M,
即缓冲区的大小只有8M,完全不足以处理庞大的数据量,
所以我们需要修改这个值的大小(value值大小可根据自己需求修改):
修改语句:set global innodb_buffer_pool_size=4294967296; 这句是解决问题的关键。优化缓冲区内存。 innodb_buffer_pool_size=12000M
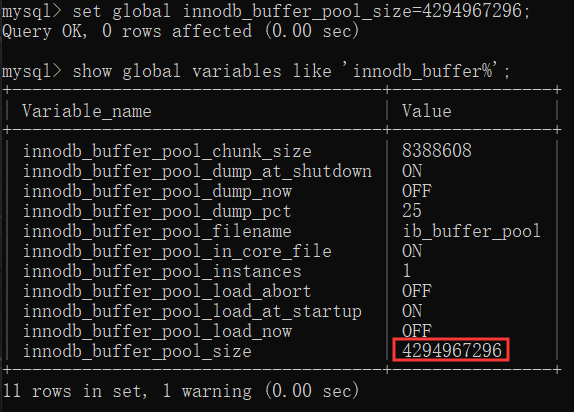
修改完毕后再次在Workbench 或 Navicat Premium 12 中运行尝试:
可以正常运行啦~
至此,该部分问题解决,希望对大家有所帮助!
Mysql对于内存的使用,可以分为两类,一类是我们无法通过配置参数来配置的,如Mysql服务器运行、解析、查询以及内部管理所消耗的内存;另一类如缓冲池所用的内存等。
在服务器中每个连接所分配的内存主要由下面四个参数控制:
(1)sort_buffer_size 连接进行排序时候分配该配置参数大小的内存进行排序操作,比如该大小设置为100M,如果有100个连接同时进行排序将分配10G的内存,很容易造成服务器内存溢出;
(2)join_buffer_size 定义mysql的每个线程所使用连接的缓冲区的大小,对于这个参数需要注意的是,如果一个查询中关联了多张表,那么就会为每个关联分配一个连接缓存,所以每个查询可能会有多个连接缓冲;
(3)read_buffer_size 对MyISAM表进行全表扫描时分配的读缓存池的大小,mysql只会在有查询需要时为该缓存分配内存,分配的内存为配置参数指定内存的大小,大小一般为4K的倍数;
(4)read_rnd_buffer_size 索引缓冲区的大小,有查询需要时才分配内存,分配的大小为需要内存的大小,而不是配置参数的大小;
上面四个参数全部是为每个线程分配的,如果有一百个连接可能会分配100倍以上内存的和。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号