java源码 -- LinkedHashMap
一、概述
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。
除此之外,LinkedHashMap 对访问顺序也提供了相关支持。在一些场景下,该特性很有用,比如缓存。
在实现上,LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。
本文重点放在双向链表的维护上:包括链表的建立过程,删除节点的过程,以及访问顺序维护的过程等
Entry
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
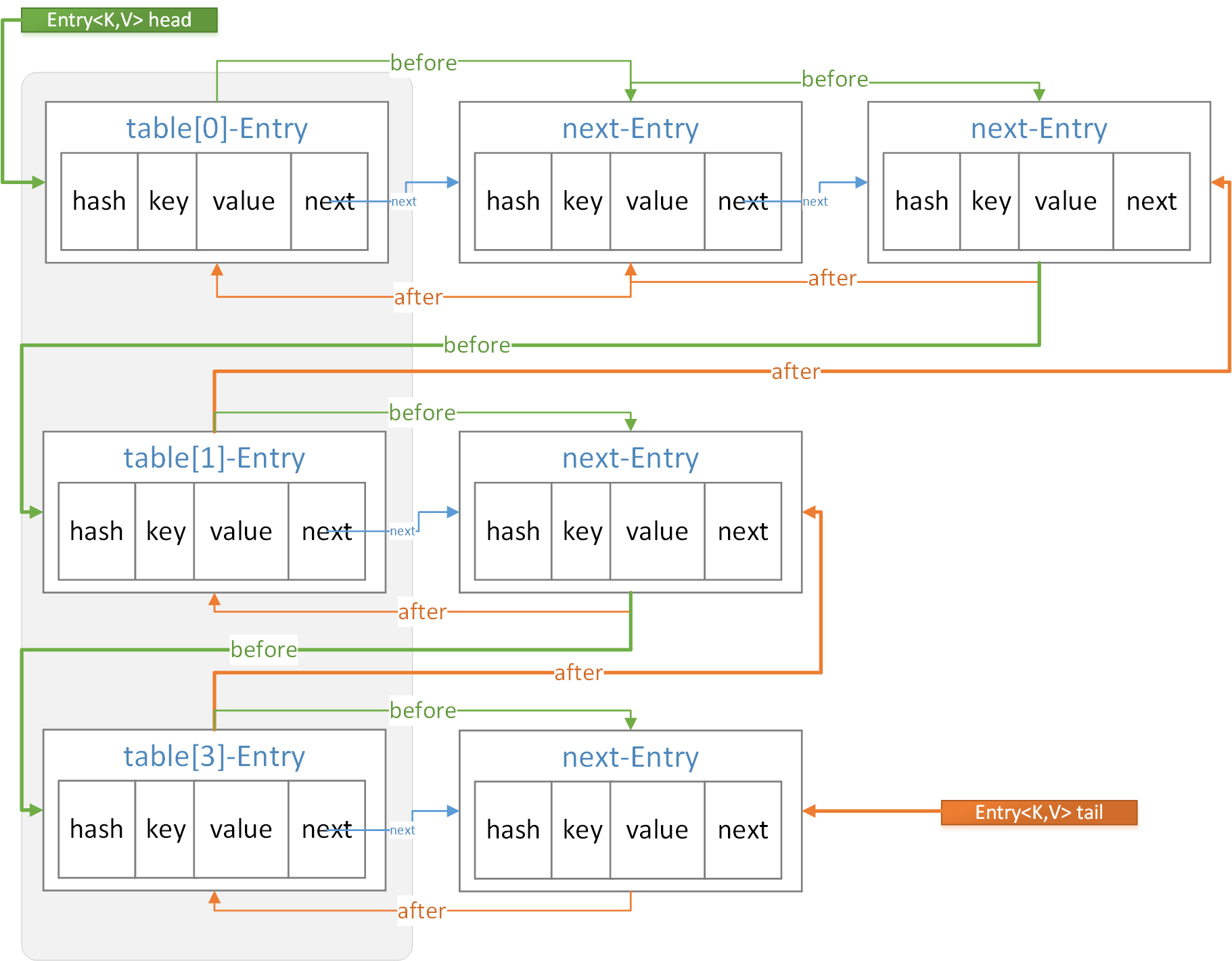
before 与 after 提供了一种视图,从该角度看是一个所有节点按插入顺序排列的双向链表。
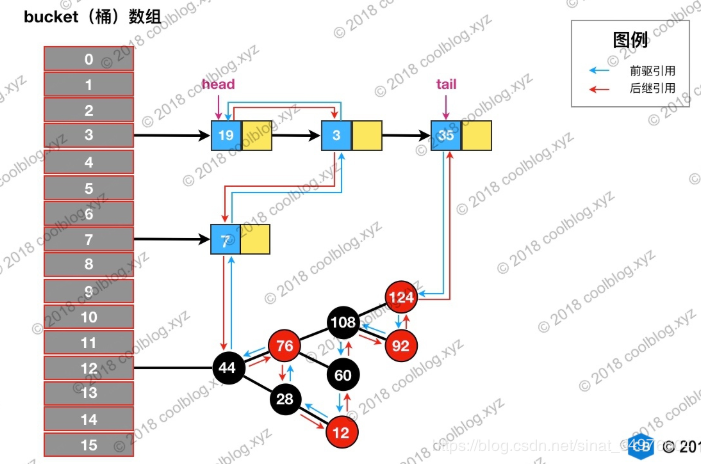
之前在分析HashMap的红黑树相关操作时说过,每个table[ i ] 位置处的链/树按 next 看则是一个普通的单向链表,按left,right,parent看则是一个二叉树(还有一个prev 与 next 构成双向链,目的是便于链节点的删除操作),
而 LinkedHashMap 继承自HashMap 所以对于它来说同时存在三种视图角度。
LinkedHashMap将具体操作都交给了HashMap,二者直接究竟是如何配合的?
这涉及到LinkedHashMap如何利用HashMap来实现自己的功能,是这样的,在HashMap的插入删除等操作后会调用钩子方法(afterNodeAccess, afterNodeInsertion, afterNodeRemoval),而这些方法的实现就在LinkedHashMap中,这些方法的目的就是操作 before 和 after 指针。
LinkedHashMap 重写newNode,newTreeNode 方法,这两个方法是在插入时HashMap构建新节点时调用的,对于重写后的newNode 先是创建LinkedHashMap#Entry节点,之后将其加到 before/after 链的尾部;
对于重写后的newTreeNode 先是创建HashMap的TreeNode节点,因为其继承自LinkedHashMap#Entry,所以含有before/after 指针,之后同样加入到链尾。
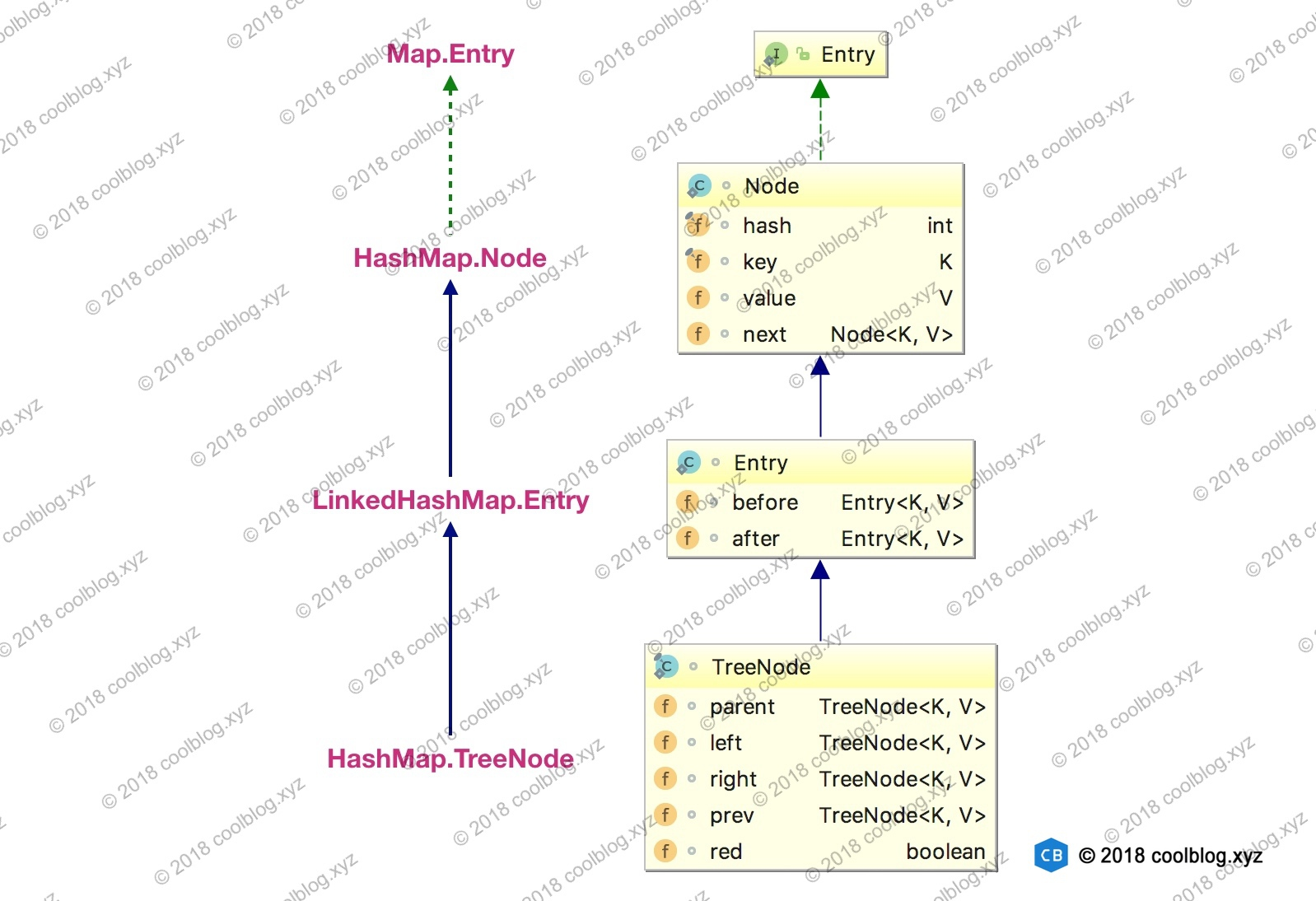
上面的继承体系乍一看还是有点复杂的,同时也有点让人迷惑。HashMap 的内部类 TreeNode 不继承它的了一个内部类 Node,却继承自 Node 的子类 LinkedHashMap 内部类 Entry。这里这样做是有一定原因的,这里先不说。
先来简单说明一下上面的继承体系。
LinkedHashMap 内部类 Entry 继承自 HashMap 内部类 Node,并新增了两个引用,分别是 before 和 after。这两个引用的用途不难理解,也就是用于维护双向链表。同时,TreeNode 继承 LinkedHashMap 的内部类 Entry 后,就具备了和其他 Entry 一起组成链表的能力。
但是这里需要大家考虑一个问题。当我们使用 HashMap 时,TreeNode 并不需要具备组成链表能力。如果继承 LinkedHashMap 内部类 Entry ,TreeNode 就多了两个用不到的引用,这样做不是会浪费空间吗?简单说明一下这个问题(水平有限,不保证完全正确),这里这么做确实会浪费空间,但与 TreeNode 通过继承获取的组成链表的能力相比,这点浪费是值得的。在 HashMap 的设计思路注释中,有这样一段话:
Because TreeNodes are about twice the size of regular nodes, we
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used.
大致的意思是 TreeNode 对象的大小约是普通 Node 对象的2倍,我们仅在桶(bin)中包含足够多的节点时再使用。当桶中的节点数量变少时(取决于删除和扩容),TreeNode 会被转成 Node。当用户实现的 hashCode 方法具有良好分布性时,树类型的桶将会很少被使用。
通过上面的注释,我们可以了解到。一般情况下,只要 hashCode 的实现不糟糕,Node 组成的链表很少会被转成由 TreeNode 组成的红黑树。也就是说 TreeNode 使用的并不多,浪费那点空间是可接受的。假如 TreeNode 机制继承自 Node 类,那么它要想具备组成链表的能力,就需要 Node 去继承 LinkedHashMap 的内部类 Entry。这个时候就得不偿失了,浪费很多空间去获取不一定用得到的能力。
说到这里,大家应该能明白节点类型的继承体系了。
二、源码
属性
//头节点
transient LinkedHashMap.Entry<K,V> head;
//尾节点
transient LinkedHashMap.Entry<K,V> tail;
//true代表哈希映射顺序;false代表插入顺序
final boolean accessOrder;
构造器
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
可以看到前四个构造器accessOrder都为false,也就是保持插入顺序;最后一个提供了设置accessOrder值的机会。
LinkedHashMap的构造函数就是调用HashMap的,再加上accessOrder的设置。head 是最早插入的或是最久未被操作的节点,tail 与其相反。
插入操作
LinkedHashMap并没有put方法,插入操作交给了HashMap,通过重写newNode/newTreeNode方法来创建自己的节点,并对before与after进行操作
这个几个方法在HashMap中的作用如下:
newNode方法:插入元素时,构造一个新的单向链表的Node
replacementNode方法: 当由红黑树转换成单向链表时,将原来的TreeNode转换成单向链表Node
newTreeNode方法: 插入元素时,构造一个红黑树节点元素TreeNode
replacementTreeNode方法:当单向链表转换为红黑树时,将原来的单向链表Node转换为TreeNode
//在每次构建新节点时,通过linkNodeLast(p);将新节点链接在内部双向链表的尾部。
//在构建新节点时,构建的是`LinkedHashMap.Entry` 不再是`Node`.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
//将新增的节点,连接在链表的尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
//集合之前是空的
if (last == null)
head = p;
else {//将新节点连接在链表的尾部
p.before = last;
last.after = p;
}
}
Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
LinkedHashMap.Entry<K,V> t =
new LinkedHashMap.Entry<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
TreeNode<K,V> t = new TreeNode<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
}
// 连接两个节点之间的前后指针
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
}
按访问顺序迭代
为了让元素按访问顺序排列,HashMap 定义了以下 Hook 方法,供 LinkedHashMap 实现:
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
各个方法实现的原理如下:
afterNodeAccess 的原理是:访问的元素如果不是尾节点,那么就把它与尾节点交换,所以随着元素的访问,访问次数越多的元素越靠后
afterNodeRemoval 这个没有特殊操作,正常的断开链条
afterNodeInsertion 的原理是:元素插入后,可能会删除最旧的、访问次数最少的元素,也就是头节点
//从链式关系中删除节点e
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
//该元素是头元素
if (b == null)
head = a;
else
b.after = a;
//该元素是尾元素
if (a == null)
tail = b;
else
a.before = b;
}
//按需删除最早插入的一个元素
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//removeEldestEntry默认返回false,可以被子类改写,如果实现LRU Cache,可以返回true
//把最老的没有被访问的元素移除掉
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//通过afterNodeAccess方法维护访问顺序,每次访问该元素就将该元素移动到双向链表的末尾
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//如果是按照访问元素顺序遍历,将该元素移到到最后一个,注意要求该元素不能是最后一个元素
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
//该元素为头元素
if (b == null)
head = a;
else
b.after = a;
//该元素不是尾元素
if (a != null)
a.before = b;
else
last = b;
//如果没有尾元素
if (last == null)
head = p;
else {
//将p放在last的后面
p.before = last;
last.after = p;
}
tail = p;
//注意此时modCount会自增
++modCount;
}
}
对HashIterator的改写保证迭代顺序为双向链表的顺序:
abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount;
LinkedHashIterator() {
//从双向链表的头元素开始遍历
next = head;
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//按照双向链表而不是哈希数组的顺序遍历
current = e;
next = e.after;
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
// key键迭代
final class LinkedKeyIterator extends LinkedHashIterator
implements Iterator<K> {
public final K next() { return nextNode().getKey(); }
}
//value值迭代
final class LinkedValueIterator extends LinkedHashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
//节点迭代
final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
键集合、值集合、节点集合
//键集合
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new LinkedKeySet();
keySet = ks;
}
return ks;
}
//封装一个LinkedKeySet集合
final class LinkedKeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<K> iterator() {
return new LinkedKeyIterator();
}
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer<? super K> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
//值集合
public Collection<V> values() {
Collection<V> vs = values;
if (vs == null) {
vs = new LinkedValues();
values = vs;
}
return vs;
}
//封装成一个LinkedValues 集合
final class LinkedValues extends AbstractCollection<V> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<V> iterator() {
return new LinkedValueIterator();
}
public final boolean contains(Object o) { return containsValue(o); }
public final Spliterator<V> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED);
}
public final void forEach(Consumer<? super V> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
//节点集合
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
}
//封装为一个节点集合
final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new LinkedEntryIterator();
}
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Node<K,V> candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
public final Spliterator<Map.Entry<K,V>> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer<? super Map.Entry<K,V>> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
总结
LinkedHashMap 代码比较简单,难的都被 HashMap 实现了:),它们的异同点分别如下:
- 底层都是数组+链表+红黑树(废话)
- 迭代器都是快速失败的,都是非线程安全
- LinkedHashMap 有按插入和访问两种迭代顺序,而HashMap 乱序,迭代顺序不可预测
看这个类的源码,最主要的还是看 HashMap 定义 Hook 方法,使得 LinkedHashMap 保持有序的机制相对独立的设计,这是模板模式的应用。
LinkedHashMap相对于HashMap的源码比,是很简单的。因为大树底下好乘凉。它继承了HashMap,仅重写了几个方法,以改变它迭代遍历时的顺序。这也是其与HashMap相比最大的不同。
在每次插入数据,或者访问、修改数据时,会增加节点、或调整链表的节点顺序。以决定迭代时输出的顺序。
- accessOrder ,默认是false,则迭代时输出的顺序是插入节点的顺序。若为true,则输出的顺序是按照访问节点的顺序。为true时,可以在这基础之上构建一个LruCache.
- LinkedHashMap并没有重写任何put方法。但是其重写了构建新节点的newNode()方法.在每次构建新节点时,将新节点链接在内部双向链表的尾部
- accessOrder=true的模式下,在afterNodeAccess()函数中,会将当前被访问到的节点e,移动至内部的双向链表的尾部。值得注意的是,afterNodeAccess()函数中,会修改modCount,因此当你正在accessOrder=true的模式下,迭代LinkedHashMap时,如果同时查询访问数据,也会导致fail-fast,因为迭代的顺序已经改变。
- nextNode() 就是迭代器里的next()方法 。该方法的实现可以看出,迭代LinkedHashMap,就是从内部维护的双链表的表头开始循环输出。 而双链表节点的顺序在LinkedHashMap的增、删、改、查时都会更新。以满足按照插入顺序输出,还是访问顺序输出。
- 它与HashMap比,还有一个小小的优化,重写了containsValue()方法,直接遍历内部链表去比对value值是否相等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号