数据结构 -- 并查集
什么是并查集?
讲个故事,大概就会明白!
江湖上散落着各式各样的大侠,有上千个之多。他们没有什么正当职业,整天背着剑在外面走来走去,碰到和自己不是一路人的,就免不了要打一架。
但大侠们有一个优点就是讲义气,绝对不打自己的朋友。而且他们信奉“朋友的朋友就是我的朋友”,只要是能通过朋友关系串联起来的,不管拐了多少
个弯,都认为是自己人。这样一来,江湖上就形成了一个一个的帮派,通过两两之间的朋友关系串联起来。
而不在同一个帮派的人,无论如何都无法通过朋友关系连起来,于是就开打了。但是两个原本互不相识的人,如何判断是否属于一个朋友圈呢?
我们可以在每个朋友圈内推举出一个比较有名望的人,作为该圈子的代表人物。这样,每个圈子就可以这样命名“中国同胞队”美国同胞队”……两人
只要互相对一下自己的队长是不是同一个人,就可以确定敌友关系了。但是还有问题啊,大侠们只知道自己直接的朋友是谁,很多人压根就不认识队长
抓狂要判断自己的队长是谁,只能漫无目的的通过朋友的朋友关系问下去:“你是不是队长?你是不是队长?”这样,想打一架得先问个几十年,没什么
必要了就。
这样一来,队长面子上也挂不住了,不仅效率太低,还有可能陷入无限循环中。于是队长下令,重新组队。队内所有人实行分等级制度,形成树状
结构,我队长就是根节点,下面分别是二级队员、三级队员。每个人只要记住自己的上级是谁就行了。遇到判断敌友的时候,只要一层层向上问,直到
最高层,就可以在短时间内确定队长是谁了。由于我们关心的只是两个人之间是否是一个帮派的,至于他们是如何通过朋友关系相关联的,以及每个圈
子内部的结构是怎样的,甚至队长是谁,都不重要了。
所以我们可以放任队长随意重新组队,只要不搞错敌友关系就好了。于是,门派产生了。
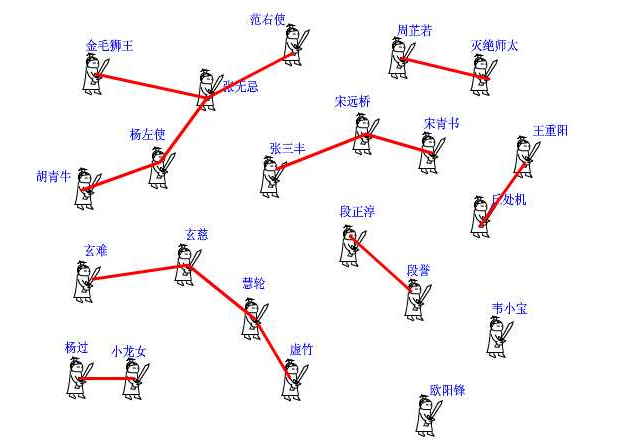
如果一个人的上级就是他自己,那说明他就是掌门人了,查找到此为止。也有孤家寡人自成一派的,比如欧阳锋,那么他的上级就是他自己。每个人都只认自己的上级。比如胡青牛同学只知道自己的上级是杨左使。
张无忌是谁?不认识!要想知道自己的掌门是谁,只能一级级查上去。
假设现在武林中的形势如图所示。虚竹帅锅与周芷若MM是我非常喜欢的两个人物,他们的终极boss分别是玄慈方丈和灭绝师太,那明显就是两个阵营了。我不希望他们互相打架,就对他俩说:“你们两位拉拉勾,做好
朋友吧。”他们看在我的面子上,同意了。
这一同意可非同小可,整个少林和峨眉派的人就不能打架了。这么重大的变化,可如何实现呀,要改动多少地方?其实非常简单,我对玄慈方丈说:“大师,麻烦你把你的上级改为灭绝师太吧。
这样一来,两派原先的所有人员的终极boss都是师太,那还打个球啊!反正我们关心的只是连通性,门派内部的结构不要紧的。”玄慈一听肯定火大了:“我靠,凭什么是我变成她手下呀,怎么不反过来?我抗议!”
于是,两人相约一战,杀的是天昏地暗,风云为之变色啊,但是啊,这场战争终究会有胜负,胜者为王。弱者就被吞并了。反正谁加入谁效果是一样的,门派就由两个变成一个了。
路径压缩算法
建立门派的过程是用join函数两个人两个人地连接起来的,谁当谁的手下完全随机。最后的树状结构会变成什么样,我也无法预知,一字长蛇阵也有可能。这样查找的效率就会比较低下。
最理想的情况就是所有人的直接上级都是掌门,一共就两级结构,只要找一次就找到掌门了。哪怕不能完全做到,也最好尽量接近。这样就产生了路径压缩算法。
设想这样一个场景:两个互不相识的大侠碰面了,想知道能不能干一场。 于是赶紧打电话问自己的上级:“你是不是掌门?” 上级说:“我不是呀,我的上级是谁谁谁,你问问他看看。” 一路问下去,原来两人的最终
boss都是东厂曹公公。 “哎呀呀,原来是自己人,有礼有礼,在下三营六组白面葫芦娃!” “幸会幸会,在下九营十八组仙子狗尾巴花!” 两人高高兴兴地手拉手喝酒去了。
“等等等等,两位大侠请留步,还有事情没完成呢!” 我叫住他俩。 “哦,对了,还要做路径压缩。”两人醒悟。 白面葫芦娃打电话给他的上级六组长:“组长啊,我查过了,其实偶们的掌门是曹公公。不如偶们一起结拜
在曹公公手下吧,省得级别太低,以后查找掌门麻烦。” “唔,有道理。” 白面葫芦娃接着打电话给刚才拜访过的三营长……仙子狗尾巴花也做了同样的事情。这样,查询中所有涉及到的人物都聚集在曹公公的直接领导下。
每次查询都做了优化处理,所以整个门派树的层数都会维持在比较低的水平上。
路径压缩的代码,看得懂很好,看不懂可以自己模拟一下,很简单的一个递归而已。总之它所实现的功能就是这么个意思。

正文
在计算机科学中,并查集是一种树型的数据结构,用于处理一些不交集(Disjoint Sets)的合并及查询问题。有一个联合-查找算法(union-find algorithm)定义了两个用于此数据结构的操作:
1. Find:确定元素属于哪一个子集。这个确定方法就是不断向上查找它的根节点,它可以被用来两个元素时否属于同一子集。
2. Union:将两个子集合并成同一个集合。
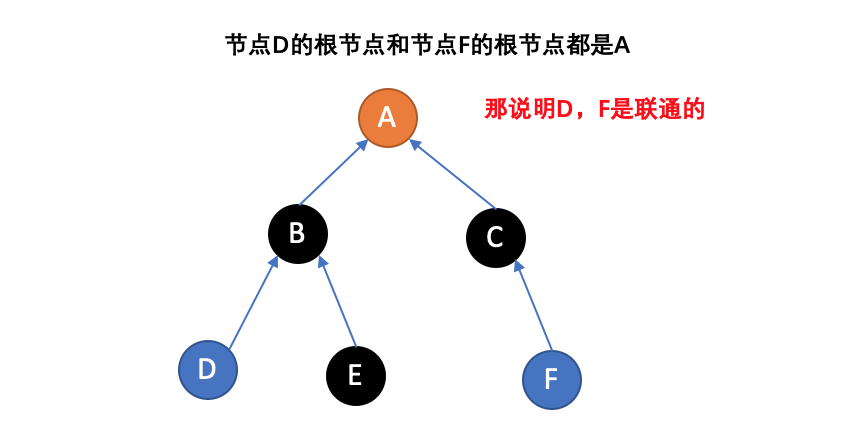
由于支持这两种操作,一个不相交集也常被称为联合-查找数据结构(union-find data structure)或合并-查找集合(merge-find set)。其他的重要方法,MakeSet,用于建立单元素集合。有了这些方法,许多经典的划分问题可以被解决。
为了更加精确的定义这些方法,需要定义如何表示集合。一种常用的策略是为每个集合选定一个固定的元素,称为代表,以表示整个集合。接着,Find(x) 返回 x 所属集合的代表,而 Union 使用两个集合的代表作为参数。

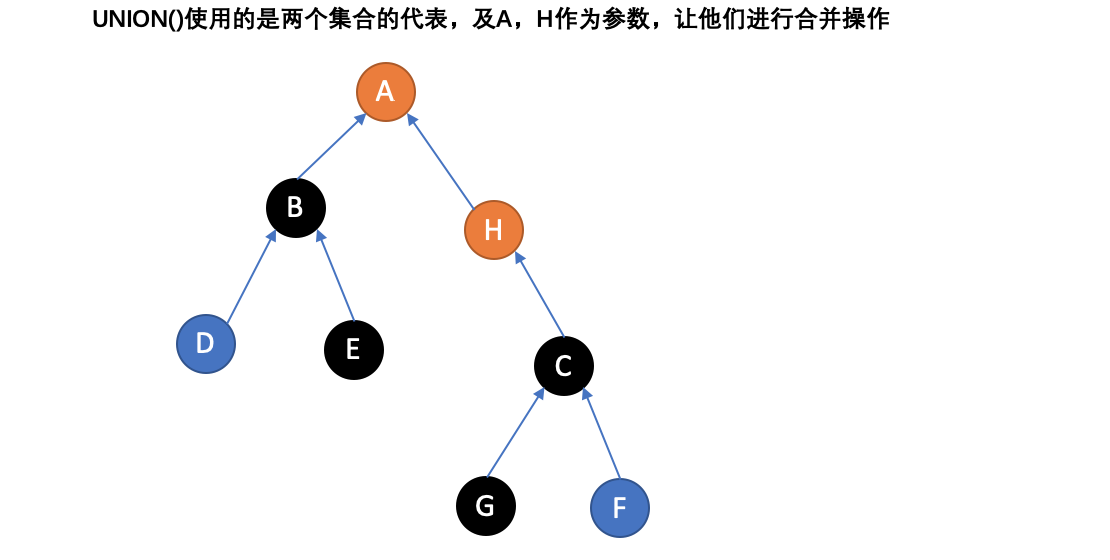
上图中简单演示了并查集的两个操作,一个是FIND,一个UNION
代码
接口
//用于实现并查集的统一接口
public interface UF { int getSize(); boolean isConnected(int p, int q); void unionElements(int p, int q); }
第一版实现
// 我们的第一版Union-Find public class UnionFind1 implements UF { private int[] id; // 我们的第一版Union-Find本质就是一个数组 public UnionFind1(int size) { id = new int[size]; // 初始化, 每一个id[i]指向自己, 没有合并的元素 for (int i = 0; i < size; i++) id[i] = i; } @Override public int getSize(){ return id.length; } // 查找元素p所对应的集合编号 // O(1)复杂度 private int find(int p) { if(p < 0 || p >= id.length) throw new IllegalArgumentException("p is out of bound."); return id[p]; } // 查看元素p和元素q是否所属一个集合 // O(1)复杂度 @Override public boolean isConnected(int p, int q) { return find(p) == find(q); } // 合并元素p和元素q所属的集合 // O(n) 复杂度 @Override public void unionElements(int p, int q) { int pID = find(p); int qID = find(q); if (pID == qID) return; // 合并过程需要遍历一遍所有元素, 将两个元素的所属集合编号合并 for (int i = 0; i < id.length; i++) if (id[i] == pID) id[i] = qID; } }
第二版实现
// 我们的第二版Union-Find public class UnionFind2 implements UF { // 我们的第二版Union-Find, 使用一个数组构建一棵指向父节点的树 // parent[i]表示第一个元素所指向的父节点 private int[] parent; // 构造函数 public UnionFind2(int size){ parent = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合 for( int i = 0 ; i < size ; i ++ ) parent[i] = i; } @Override public int getSize(){ return parent.length; } // 查找过程, 查找元素p所对应的集合编号 // O(h)复杂度, h为树的高度 private int find(int p){ if(p < 0 || p >= parent.length) throw new IllegalArgumentException("p is out of bound."); // 不断去查询自己的父亲节点, 直到到达根节点 // 根节点的特点: parent[p] == p while(p != parent[p]) p = parent[p]; return p; } // 查看元素p和元素q是否所属一个集合 // O(h)复杂度, h为树的高度 @Override public boolean isConnected( int p , int q ){ return find(p) == find(q); } // 合并元素p和元素q所属的集合 // O(h)复杂度, h为树的高度 @Override public void unionElements(int p, int q){ int pRoot = find(p); int qRoot = find(q); if( pRoot == qRoot ) return; parent[pRoot] = qRoot; } }
第三版实现
在第二版实现中,p所在的树总是会被作为q所在树的子树,从而实现两颗独立的树的融合。那么这样的约定是不是总是合理的呢?显然不是!
比如p所在的树的规模比q所在的树的规模大的多时,p和q结合之后形成的树就是十分不和谐的一头轻一头重的”畸形树“了。所以我们应该考虑树的大小,即树的元素个数。
我们约定:总是size小的树作为子树和size大的树进行合并。这样就能够尽量的保持整棵树的平衡。
// 我们的第三版Union-Find public class UnionFind3 implements UF{ private int[] parent; // parent[i]表示第一个元素所指向的父节点 private int[] sz; // sz[i]表示以i为根的集合中元素个数 // 构造函数 public UnionFind3(int size){ parent = new int[size]; sz = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合 for(int i = 0 ; i < size ; i ++){ parent[i] = i; sz[i] = 1; } } @Override public int getSize(){ return parent.length; } // 查找过程, 查找元素p所对应的集合编号 // O(h)复杂度, h为树的高度 private int find(int p){ if(p < 0 || p >= parent.length) throw new IllegalArgumentException("p is out of bound."); // 不断去查询自己的父亲节点, 直到到达根节点 // 根节点的特点: parent[p] == p while( p != parent[p] ) p = parent[p]; return p; } // 查看元素p和元素q是否所属一个集合 // O(h)复杂度, h为树的高度 @Override public boolean isConnected( int p , int q ){ return find(p) == find(q); } // 合并元素p和元素q所属的集合 // O(h)复杂度, h为树的高度 @Override public void unionElements(int p, int q){ int pRoot = find(p); int qRoot = find(q); if(pRoot == qRoot) return; // 根据两个元素所在树的元素个数不同判断合并方向 // 将元素个数少的集合合并到元素个数多的集合上 if(sz[pRoot] < sz[qRoot]){ parent[pRoot] = qRoot; sz[qRoot] += sz[pRoot]; } else{ // sz[qRoot] <= sz[pRoot] parent[qRoot] = pRoot; sz[pRoot] += sz[qRoot]; } } }
可以发现,通过sz数组决定如何对两棵树进行合并之后,最后得到的树的高度大幅度减小了。这是十分有意义的,因为在Quick-Union算法中的任何操作,都不可避免的需要调用find方法,而该方法的执行效率依赖于树的高度。
树的高度减小了,find方法的效率就增加了,从而也就增加了整个Quick-Union算法的效率。
第四版实现
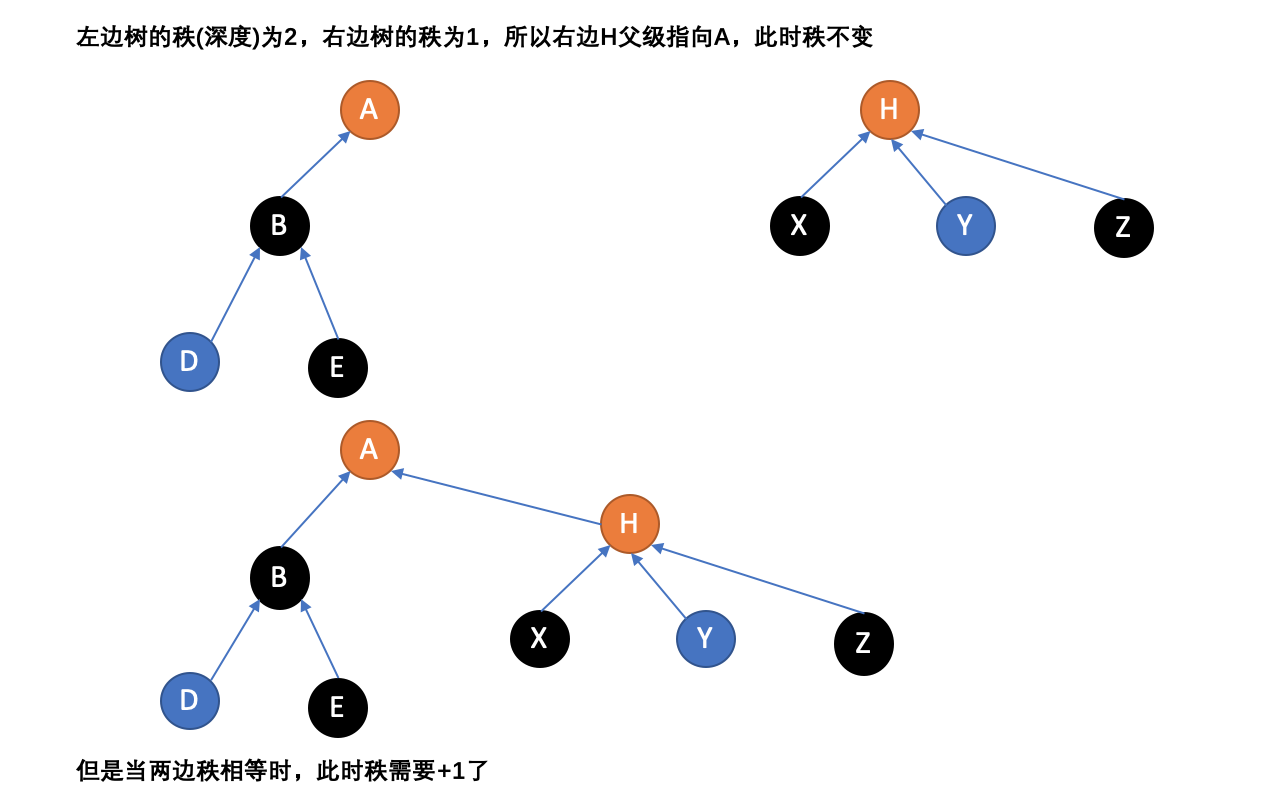
“按秩合并”,是一种优化方式,即总是将更小的树连接至更大的树上。因为有一种情况是,所以数据串成一条线,形成类似于链表的结构,深度很大。影响运行时间是树的深度,更小的树添加到更深的树的根上将不会增加深度,
除非它们的深度相同。在这个算法中,术语“秩”替代了“深度”。
// 我们的第四版Union-Find public class UnionFind4 implements UF { private int[] rank; // rank[i]表示以i为根的集合所表示的树的层数 private int[] parent; // parent[i]表示第i个元素所指向的父节点 // 构造函数 public UnionFind4(int size){ rank = new int[size]; parent = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合 for( int i = 0 ; i < size ; i ++ ){ parent[i] = i; rank[i] = 1; } } @Override public int getSize(){ return parent.length; } // 查找过程, 查找元素p所对应的集合编号 // O(h)复杂度, h为树的高度 private int find(int p){ if(p < 0 || p >= parent.length) throw new IllegalArgumentException("p is out of bound."); // 不断去查询自己的父亲节点, 直到到达根节点 // 根节点的特点: parent[p] == p while(p != parent[p]) p = parent[p]; return p; } // 查看元素p和元素q是否所属一个集合 // O(h)复杂度, h为树的高度 @Override public boolean isConnected( int p , int q ){ return find(p) == find(q); } // 合并元素p和元素q所属的集合 // O(h)复杂度, h为树的高度 @Override public void unionElements(int p, int q){ int pRoot = find(p); int qRoot = find(q); if( pRoot == qRoot ) return; // 根据两个元素所在树的rank不同判断合并方向 // 将rank低的集合合并到rank高的集合上 if(rank[pRoot] < rank[qRoot]) parent[pRoot] = qRoot; else if(rank[qRoot] < rank[pRoot]) parent[qRoot] = pRoot; else{ // rank[pRoot] == rank[qRoot] parent[pRoot] = qRoot; rank[qRoot] += 1; // 此时, 我维护rank的值 } } }
路径压缩
优化另一种方式:“路径压缩”,是一种在执行“查找”时扁平化树结构的方法。关键在于在路径上的每个节点都可以直接连接到根上;他们都有同样的表示方法。
为了达到这样的效果,Find递归地经过树,改变每一个节点的引用到根节点。得到的树将更加扁平,为以后直接或者间接引用节点的操作加速。

第五版实现
// 我们的第五版Union-Find public class UnionFind5 implements UF { // rank[i]表示以i为根的集合所表示的树的层数 // 在后续的代码中, 我们并不会维护rank的语意, 也就是rank的值在路径压缩的过程中, 有可能不在是树的层数值 // 这也是我们的rank不叫height或者depth的原因, 他只是作为比较的一个标准 private int[] rank; private int[] parent; // parent[i]表示第i个元素所指向的父节点 // 构造函数 public UnionFind5(int size){ rank = new int[size]; parent = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合 for( int i = 0 ; i < size ; i ++ ){ parent[i] = i; rank[i] = 1; } } @Override public int getSize(){ return parent.length; } // 查找过程, 查找元素p所对应的集合编号 // O(h)复杂度, h为树的高度 private int find(int p){ if(p < 0 || p >= parent.length) throw new IllegalArgumentException("p is out of bound.");
//路径压缩核心代码 while( p != parent[p] ){ parent[p] = parent[parent[p]]; p = parent[p]; } return p; } // 查看元素p和元素q是否所属一个集合 // O(h)复杂度, h为树的高度 @Override public boolean isConnected( int p , int q ){ return find(p) == find(q); } // 合并元素p和元素q所属的集合 // O(h)复杂度, h为树的高度 @Override public void unionElements(int p, int q){ int pRoot = find(p); int qRoot = find(q); if( pRoot == qRoot ) return; // 根据两个元素所在树的rank不同判断合并方向 // 将rank低的集合合并到rank高的集合上 if( rank[pRoot] < rank[qRoot] ) parent[pRoot] = qRoot; else if( rank[qRoot] < rank[pRoot]) parent[qRoot] = pRoot; else{ // rank[pRoot] == rank[qRoot] parent[pRoot] = qRoot; rank[qRoot] += 1; // 此时, 我维护rank的值 } } }
第六版实现
路径压缩优化
// 我们的第六版Union-Find public class UnionFind6 implements UF { // rank[i]表示以i为根的集合所表示的树的层数 // 在后续的代码中, 我们并不会维护rank的语意, 也就是rank的值在路径压缩的过程中, 有可能不在是树的层数值 // 这也是我们的rank不叫height或者depth的原因, 他只是作为比较的一个标准 private int[] rank; private int[] parent; // parent[i]表示第i个元素所指向的父节点 // 构造函数 public UnionFind6(int size){ rank = new int[size]; parent = new int[size]; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合 for( int i = 0 ; i < size ; i ++ ){ parent[i] = i; rank[i] = 1; } } @Override public int getSize(){ return parent.length; } // 查找过程, 查找元素p所对应的集合编号 // O(h)复杂度, h为树的高度 private int find(int p){ if(p < 0 || p >= parent.length) throw new IllegalArgumentException("p is out of bound."); // path compression 2, 递归算法 if(p != parent[p]) parent[p] = find(parent[p]); return parent[p]; } // 查看元素p和元素q是否所属一个集合 // O(h)复杂度, h为树的高度 @Override public boolean isConnected( int p , int q ){ return find(p) == find(q); } // 合并元素p和元素q所属的集合 // O(h)复杂度, h为树的高度 @Override public void unionElements(int p, int q){ int pRoot = find(p); int qRoot = find(q); if( pRoot == qRoot ) return; // 根据两个元素所在树的rank不同判断合并方向 // 将rank低的集合合并到rank高的集合上 if( rank[pRoot] < rank[qRoot] ) parent[pRoot] = qRoot; else if( rank[qRoot] < rank[pRoot]) parent[qRoot] = pRoot; else{ // rank[pRoot] == rank[qRoot] parent[pRoot] = qRoot; rank[qRoot] += 1; // 此时, 我维护rank的值 } } }
测试效率
import java.util.Random; public class Main { private static double testUF(UF uf, int m){ int size = uf.getSize(); Random random = new Random(); long startTime = System.nanoTime(); for(int i = 0 ; i < m ; i ++){ int a = random.nextInt(size); int b = random.nextInt(size); uf.unionElements(a, b); } for(int i = 0 ; i < m ; i ++){ int a = random.nextInt(size); int b = random.nextInt(size); uf.isConnected(a, b); } long endTime = System.nanoTime(); double time = (endTime - startTime) / 1000000000.0; return time; } public static void main(String[] args) { int size = 10000000; int m = 10000000; // UnionFind1 uf1 = new UnionFind1(size); // System.out.println("UnionFind1 : " + testUF(uf1, m) + " s"); // // UnionFind2 uf2 = new UnionFind2(size); // System.out.println("UnionFind2 : " + testUF(uf2, m) + " s"); UnionFind3 uf3 = new UnionFind3(size); System.out.println("UnionFind3 : " + testUF(uf3, m) + " s");
UnionFind4 uf4 = new UnionFind4(size); System.out.println("UnionFind4 : " + testUF(uf4, m) + " s"); UnionFind5 uf5 = new UnionFind5(size); System.out.println("UnionFind5 : " + testUF(uf5, m) + " s"); UnionFind6 uf6 = new UnionFind6(size); System.out.println("UnionFind6 : " + testUF(uf6, m) + " s"); } }
结果

参考:https://www.cnblogs.com/MrSaver/p/9607552.html https://blog.csdn.net/qq_41593380/article/details/81146850

 浙公网安备 33010602011771号
浙公网安备 33010602011771号