数据结构 -- 优先队列和堆排序
什么是优先队列?
听这个名字就知道,优先队列也是一种队列,只不过不同的是,优先队列的出队顺序是按照优先级来的;在有些情况下,可能需要找到元素集合中的最小或者最大元素,
可以利用优先队列ADT来完成操作,优先队列ADT是一种数据结构,它支持插入和删除最小值操作(返回并删除最小元素)或删除最大值操作(返回并删除最大元素)。
这些操作等价于队列的enQueue和deQueue操作,区别在于,对于优先队列,元素进入队列的顺序可能与其被操作的顺序不同,
作业调度是优先队列的一个应用实例,它根据优先级的高低而不是先到先服务的方式来进行调度;
如果最小键值元素拥有最高级的优先级,那么这种优先队列叫作升序优先队列(即总是删除最小的元素);
如果最大键值元素拥有最高级的优先级,那么这种优先队列叫作降序优先队列(即总是删除最大的元素)。
由于这两种类型时对称的,所以关注一种即可。
优先队列的主要操作
1. insert(key, data):插入键值为key的数据到优先队列中,元素以其key进行排序;
2. deleteMin/deleteMax:删除并返回最小/最大键值的元素;
3. getMinimum/getMaximum:返回最小/最大键值的元素,但不删除。
优先队列的辅助操作
1. 第k最小/第k最大: 返回优先队列中键值为第k个最小/最大的元素
2. 大小(size):返回优先队列中的元素个数;
3. 堆排序(Heap Sort):基于键值的优先级将优先队列中的元素进行排序。
优先队列的应用
数据压缩:赫夫曼编码算法;
最短路径算法:Dijkstra算法;
最小生成树算法:Prim算法;
事件驱动仿真:顾客排队算法;
选择问题:查找第k个最小元素;
等等等等......
优先队列的实现比较
堆和二叉堆
什么是堆
堆是一颗具有特定性质的二叉树。
堆的性质:(1)堆的基本要求就是堆中所有结点的值必须大于或等于(或小于或等于)其孩子结点的值;
(2)当 h > 0 时,所有叶子结点都处于第 h 或 h - 1 层(其中 h 为树的高度,完全二叉树),也就是说,堆应该是一颗完全二叉树。
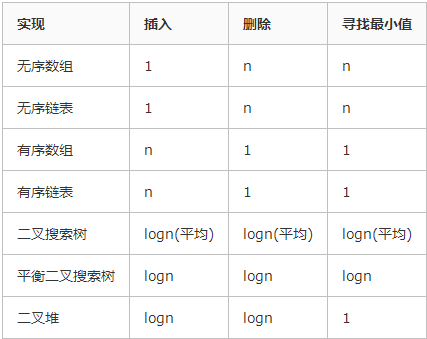
堆有序:当一颗二叉树的每个节点都大于等于它的两个子结点时。
左边的树为堆(每个元素都大于其孩子结点的值),而右边的树不是堆(因为5大于其孩子结点2)
二叉堆
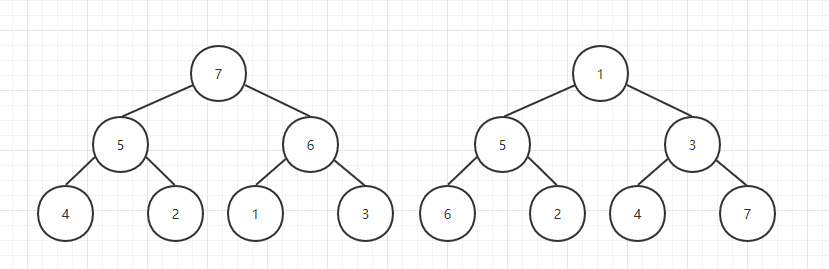
二叉堆是一颗完全二叉树,二叉堆分为最大堆和最小堆。
最大堆的任何一个节点的关键字都大于或等于其子节点的关键字;最小堆的任何一个节点的关键字都小于或等于其子节点的关键字。
堆的表示:在描述堆的操作前,首先来看堆是怎样表示的,一种可能的方法就是使用数组,因为堆在形式上是一颗完全二叉树,用数组来存储它不会浪费任何空间。例如下图:
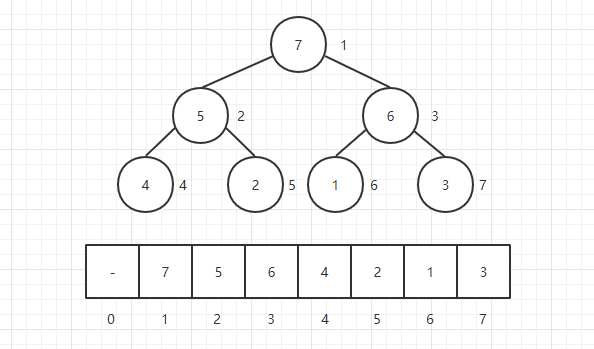
我们使用一个一维数组来存储二叉堆的元素,不仅不会浪费空间,还具有一定的优势。
性质:
-
- 任何一个非树根节点的父节点为
⌊(i - 1) / 2⌋ - 任何一个非叶子节点的左孩子为
2 * i + 1 - 任何一个非叶子节点的右孩子为
2 * i + 2
- 任何一个非树根节点的父节点为
二叉堆的向下调整(元素的下沉)
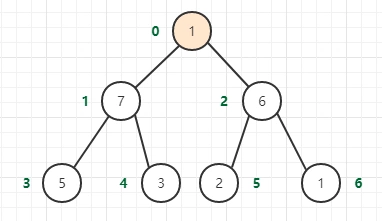

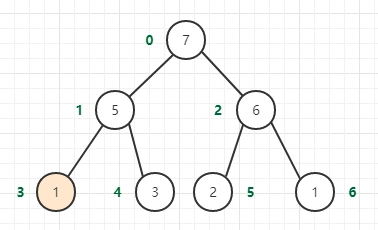
调整策略
1 让第0个节点作为当前节点,选取当前节点的两个子节点,选择子节点中关键字较大的节点,该节点的下标为i,如果这个节点的值大于当前节点的值,则交换它们的位置;
2 如果没有结束则对下标为i的节点继续进行调整
当删除最大元素的时候,也就是删除堆顶端的元素。将最小值放在堆顶,然后通过下沉重新调整堆。
二叉堆的向上调整(元素的上浮)
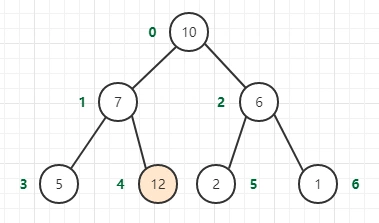
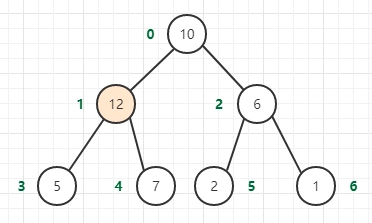

如果堆的有序状态因为某个结点变得比它的两个子节点或者其中之一小而被打破,那么我们需要交换它和两个子节点中较大者来修复堆,
交换后仍然可能出现前面描述的情况,所以继续交换直到它的两个子结点都比它小或者到达了堆的底部。
代码实现:
堆的基本结构
public class MaxHeap<E extends Comparable<E>> {
private Array<E> data;
public MaxHeap(int capacity){ data = new Array<>(capacity); }
public MaxHeap(){ data = new Array<>(); }
// 返回堆中的元素个数
public int size(){ return data.getSize(); }
// 返回一个布尔值, 表示堆中是否为空
public boolean isEmpty(){ return data.isEmpty(); }
// 返回完全二叉树的数组表示中,一个索引所表示的元素的父亲节点的索引
private int parent(int index){
if(index == 0)
throw new IllegalArgumentException("index-0 doesn't have parent.");
return (index - 1) / 2;
}
// 返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引
private int leftChild(int index){ return index * 2 + 1; }
// 返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引
private int rightChild(int index){ return index * 2 + 2; }
}
//Array内容


package com.wj.array; import java.util.Objects; public class ArrayUtil<E> { private E[] data; private int size; //初始化容量 public ArrayUtil(int capacity){ data = (E[]) new Object[capacity]; size =0; } public ArrayUtil(){ this(10); } public ArrayUtil(E[] arr){ data = (E[]) new Object[arr.length]; for (int i=0; i< arr.length; i++){ data[i] = arr[i]; } size = arr.length; } //元素的个数 public int getSize(){ return size; } //容量长度 public int getCapacity(){ return data.length; } //是否为空 public boolean isEmpty(){ return size == 0; } //指定位置插入数据 public void add(int index,E e){ if(index < 0 || index > data.length) throw new IllegalArgumentException("Add failed. Require index >= 0 and index <= size."); if (size == data.length){ resize(data.length * 2); } for (int i = size - 1; i >= index; i--){ data [i+1]= data[i]; } data[index] = e; size++; } public void addLast(E e){ add(size,e); } public void addFirst(E e){ add(0,e); } public E get(int index){ if(index < 0 || index >= size) throw new IllegalArgumentException("Add failed. Require index >= 0 and index <= size."); return data[index]; } public void set(int index, E e){ if(index < 0 || index >= size) throw new IllegalArgumentException("Add failed. Require index >= 0 and index <= size."); data[index] = e; } public boolean contains(E e){ for (int i=0; i < size; i++) { if (Objects.equals(data[i],e)) return true; } return false; } public int find(E e){ for (int i=0; i< size;i++) { if (Objects.equals(data[i],e)) return i; } return -1; } public E remove(int index){ if(index < 0 || index >= size) throw new IllegalArgumentException("Add failed. Require index >= 0 and index <= size."); E resultE = data[index]; data[index] = null; for (int i = index+1; i< size; i++){ data[i-1] = data[i]; } size--; data[size] = null; if (size == data.length && data.length/2 != 0) resize(data.length/2); return resultE; } public E removeFirst(){ return remove(0); } public E removeLast(){ return remove(size - 1); } public void removeElement(E e){ int index = find(e); if (index != -1) remove(index); } public void swap(int i, int j){ if (i < 0 || i >= size || j < 0 || j >= size){ throw new IllegalArgumentException("index is illegal."); } E t = data[i]; data[i] = data[j]; data[j] = t; } @Override public String toString() { StringBuilder stringBuilder = new StringBuilder(); stringBuilder.append("["); for (int i=0;i< size; i++) { stringBuilder.append(data[i]); if(i != size - 1){ stringBuilder.append(","); } } stringBuilder.append("]"); return stringBuilder.toString(); } //扩容 public void resize(int newCapaticy){ E[] newData = (E[]) new Object[newCapaticy]; for (int i = 0; i< size;i++) newData[i] = data[i]; data=newData; } }
添加元素和Sift Up(上浮)
// 向堆中添加元素
public void add(E e){
data.addLast(e);
siftUp(data.getSize() - 1);
}
private void siftUp(int k){
while(k > 0 && data.get(parent(k)).compareTo(data.get(k)) < 0 ){
data.swap(k, parent(k));
k = parent(k);
}
}
取出堆中的最大元素和Sift Down
// 看堆中的最大元素
public E findMax(){
if(data.getSize() == 0)
throw new IllegalArgumentException("Can not findMax when heap is empty.");
return data.get(0);
}
// 取出堆中最大元素
public E extractMax(){
E ret = findMax();
data.swap(0, data.getSize() - 1);
data.removeLast();
siftDown(0);
return ret;
}
private void siftDown(int k){
while(leftChild(k) < data.getSize()){
int j = leftChild(k); // 在此轮循环中,data[k]和data[j]交换位置
if( j + 1 < data.getSize() &&
data.get(j + 1).compareTo(data.get(j)) > 0 )
j ++;
// data[j] 是 leftChild 和 rightChild 中的最大值
if(data.get(k).compareTo(data.get(j)) >= 0 )
break;
data.swap(k, j);
k = j;
}
}
Replace 和 Heapify
Replace这个操作其实就是取出堆中最大的元素之后再新插入一个元素,常规的做法是取出最大元素之后,再利用上面的插入新元素的操作对堆进行Sift Up操作,
但是这里有一个小技巧就是直接使用新元素替换掉堆顶元素,之后再进行Sift Down操作,这样就把两次O(logn)的操作变成了一次O(logn):
// 取出堆中的最大元素,并且替换成元素e
public E replace(E e){
E ret = findMax();
data.set(0, e);
siftDown(0);
return ret;
}
Heapify翻译过来就是堆化的意思,就是将任意数组整理成堆的形状,通常的做法是遍历数组从0开始添加创建一个新的堆,但是这里存在一个小技巧就是把当前数组就看做是一个完全二叉树,
然后从最后一个非叶子结点开始进行Sift Down操作就可以了,最后一个非叶子结点也很好找,就是最后一个结点的父亲结点,大家可以验证一下:

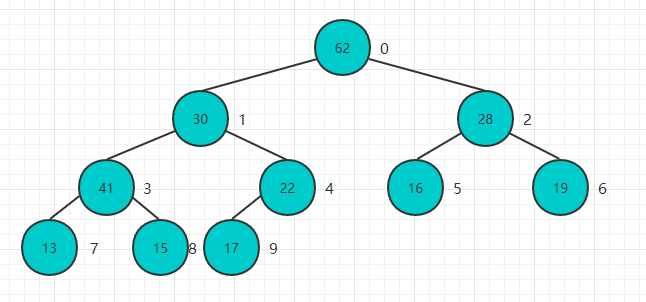

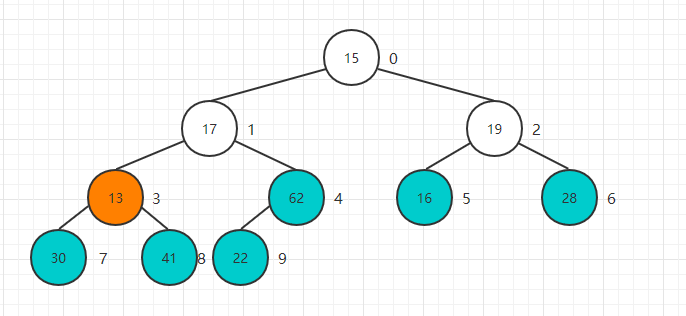

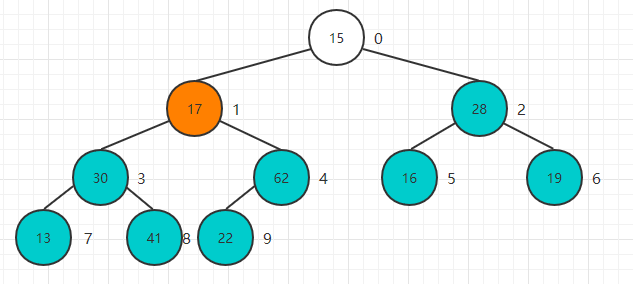
将n个元素逐个插入到一个空堆中,算法复杂度是O(nlogn),而heapify的过程,算法复杂度为O(n),这是有一个质的飞跃的.
public MaxHeap(E[] arr){ data = new Array<>(arr); for(int i = parent(arr.length - 1) ; i >= 0 ; i --) siftDown(i); }
基于堆的优先队列
首先我们的队列仍然需要继承我们之前将队列时候声明的那个接口Queue,然后实现这个接口中的方法就可以了,之类简单写一下:
public class PriorityQueue<E extends Comparable<E>> implements Queue<E> { private MaxHeap<E> maxHeap; public PriorityQueue(){ maxHeap = new MaxHeap<>(); } @Override public int getSize(){ return maxHeap.size(); } @Override public boolean isEmpty(){ return maxHeap.isEmpty(); } @Override public E getFront(){ return maxHeap.findMax(); } @Override public void enqueue(E e){ maxHeap.add(e); } @Override public E dequeue(){ return maxHeap.extractMax(); } }
Java中的PriorityQueue
在Java中也实现了自己的优先队列java.util.PriorityQueue,与我们自己写的不同之处在于,Java中内置的为最小堆,然后就是一些函数名不一样,底层还是维护了一个Object类型的数组,大家可以戳戳看有什么不同。
练习可去LeetCode进行练习
参考:https://www.cnblogs.com/wmyskxz/p/9301021.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号