
Shedlock分布式锁、Redis实现分布式锁
在SpringBoot中常使用Scheduler做定时任务,只需要使用注解@Scheduled和@EnableScheduling之后,便可通过cron表达式执行计划任务。但是我们生产环境中,由于业务需要,防止单点出现问题,往往需要时间分布式多节点的部署,并通过代理形成负载均衡的集群。在这种情况下,由于定时任务的特殊性,以及一些方法的幂等性要求,某些定时任务只需要执行一次。因此需要一种机制来保证集群中同一时间仅有一个服务实例执行计划任务。
- 悲观锁:总是认为资源正在被其他线程同时访问,都要上锁,安全,但增加了开销。
- 乐观锁:总是认为资源访问不存在冲突,仅在提交数据更新时进行版本校验以确认是否冲突,并把问题抛给用户,由用户决策。
- 分布式:一个业务分拆多个子业务,部署在不同的服务器上(微服务化)。
- 集群:同一个业务,部署在多个服务器上。(集群是解决高可用的,而分布式是解决高性能、高并发的)
Shedlock分布式锁原理及实现
实现原理
Shedlock 从严格意义上来说不是一个分布式任务调度框架,而是一个分布式锁。(相比于Shedlock,Quartz作为定时任务框架功能更为全面,但也意味着其更为复杂)
所谓的分布式锁,解决的核心问题就是各个节点中无法通信的痛点。各个节点并不知道这个定时任务有没有被其他节点的定时器执行,所以理论上只需要有一个各个节点都能够访问到的资源,用这个资源去标记这个定时任务有没有执行就可以了。
Shedlock基于数据库、Redis等公共存储实现其功能。
以MySQL数据库为例,相关表数据包含的信息有:上锁主机信息、定时任务名、上锁时间、锁释放时间等。
Shedlock上锁时,其以定时任务名为主键,在定时任务执行前,先到数据表执行add或update操作,更新时若该任务已被其他主机上锁且尚未达到锁释放时间,则上锁失败,更新成功则上锁成功。(注:要求集群的机器时间基本一致,防止上锁无效)
实现步骤
-
引入Shedlock相关依赖
<!-- shedlock --> <dependency> <groupId>net.javacrumbs.shedlock</groupId> <artifactId>shedlock-spring</artifactId> <version>${shedlock.version}</version> </dependency> <dependency> <groupId>net.javacrumbs.shedlock</groupId> <artifactId>shedlock-provider-jdbc-template</artifactId> <version>${shedlock.version}</version> </dependency> -
新建定时任务表,用于存储定时任务上锁信息,表结构如下
name:定时任务名称,作为锁的主键lock_until:锁释放时间locked_at:上锁时间locked_by:持锁主机信息

-
编写Shedlock配置类,指定使用的表
@Configuration public class ScheduledLockConfiguration { private final static String tableName = "SHEDLOCK";//shedlock表名 @Bean public LockProvider lockProvider(DataSource dataSource) { return new JdbcTemplateLockProvider(dataSource,tableName); } } -
在使用注解
@Scheduled定时任务处,对需要避免并发的定时任务同时使用@SchedulerLock注解,并为相关属性赋值name:定时任务名称,作为锁的主键lockAtMostFor:锁的最大时间,单位毫秒lockAtLeastFor:锁的最小时间,单位毫秒
private static final long lockTimeAtLeast = 5000L;//锁的最小时间,单位毫秒 private static final long lockTimeAtMost = 30000L;//锁的最大时间,单位毫秒 @Scheduled(cron = "0 15 2 * * ?") @SchedulerLock(name = "task-1", lockAtMostFor = lockTimeAtMost, lockAtLeastFor = lockTimeAtLeast) public void executeJob() { // TODO }
Redis实现分布式锁方案
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。如下图所示:
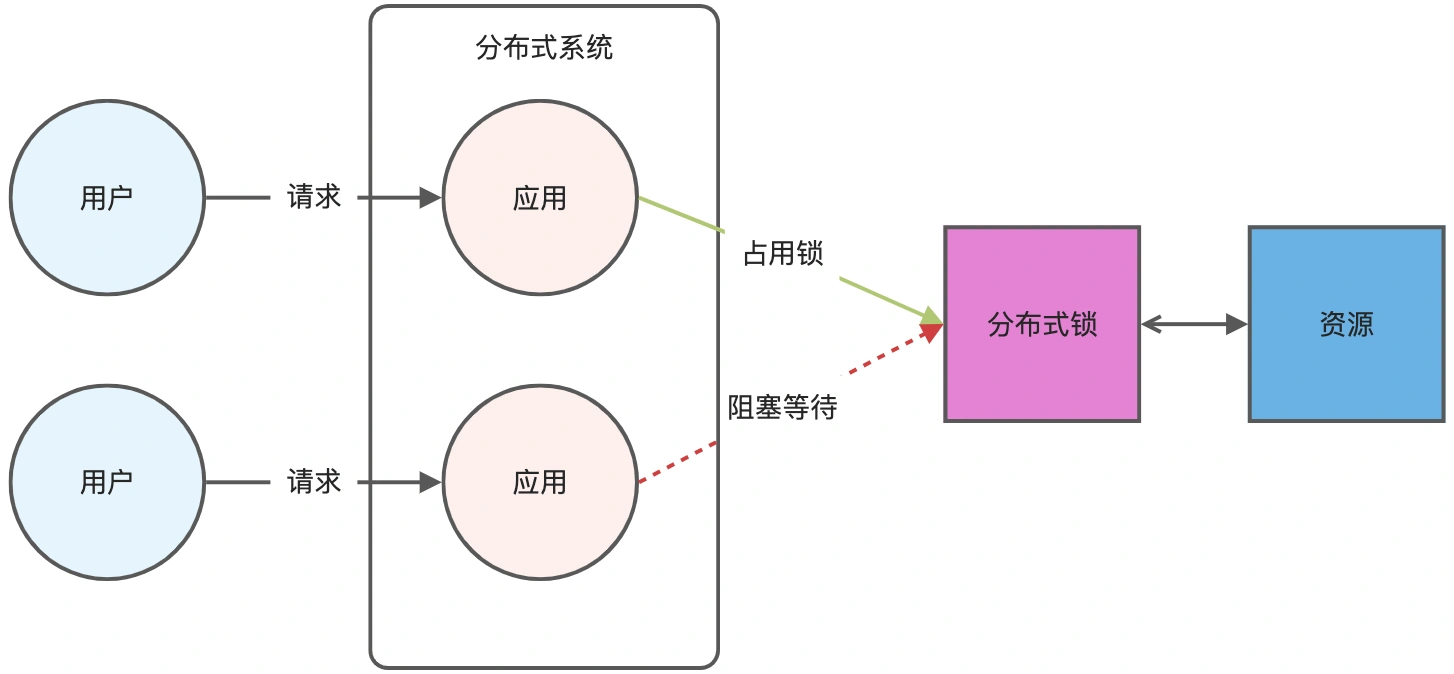
Redis 本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁,而且 Redis 的读写性能高,可以应对高并发的锁操作场景。
Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:
- 如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
- 如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
- 加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
- 锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
- 锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
满足这三个条件的分布式命令如下:
SET lock_key unique_value NX PX 10000
- lock_key 就是 key 键;
- unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
基于 Redis 实现分布式锁有什么优缺点?
基于 Redis 实现分布式锁的优点
- 性能高效(这是选择缓存实现分布式锁最核心的出发点)。
- 实现方便。很多研发工程师选择使用 Redis 来实现分布式锁,很大成分上是因为 Redis 提供了 setnx 方法,实现分布式锁很方便。
- 避免单点故障(因为 Redis 是跨集群部署的,自然就避免了单点故障)。
基于 Redis 实现分布式锁的缺点
- 超时时间不好设置。如果锁的超时时间设置过长,会影响性能,如果设置的超时时间过短会保护不到共享资源。比如在有些场景中,一个线程 A 获取到了锁之后,由于业务代码执行时间可能比较长,导致超过了锁的超时时间,自动失效,注意 A 线程没执行完,后续线程 B 又意外的持有了锁,意味着可以操作共享资源,那么两个线程之间的共享资源就没办法进行保护了。
那么如何合理设置超时时间呢?
- 使用Redis的SET命令结合SetOption进行加锁。
public boolean setNX(final String key, final String value, final long expirationTime) { boolean result = redisTemplate.execute((RedisCallback<Boolean>) connection -> { RedisSerializer<String> serializer = redisTemplate.getStringSerializer(); // Boolean aBoolean = connection.setNX(serializer.serialize(key), serializer.serialize(value)); // 使用SET代替SETNX ,相当于SETNX+EXPIRE实现了原子性,不必担心SETNX成功,EXPIRE失败的问题,有效避免死锁 Boolean aBoolean = connection.set(serializer.serialize(key), serializer.serialize(value), Expiration.seconds(expirationTime), RedisStringCommands.SetOption.SET_IF_ABSENT); connection.close(); return aBoolean; }); return result; } - 可以基于续约的方式设置超时时间:先给锁设置一个超时时间,然后启动一个守护线程,让守护线程在一段时间后,重新设置这个锁的超时时间。实现方式就是:写一个守护线程,然后去判断锁的情况,当锁快失效的时候,再次进行续约加锁,当主线程执行完成后,销毁续约锁即可,不过这种方式实现起来相对复杂。
- 使用Redis的SET命令结合SetOption进行加锁。
- Redis 主从复制模式中的数据是异步复制的,这样导致分布式锁的不可靠性。如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
Redis 如何解决集群情况下分布式锁的可靠性?
为了保证集群环境下分布式锁的可靠性,Redis 官方已经设计了一个分布式锁算法 Redlock(红锁)。
它是基于多个 Redis 节点的分布式锁,即使有节点发生了故障,锁变量仍然是存在的,客户端还是可以完成锁操作。官方推荐是至少部署 5 个 Redis 节点,而且都是主节点,它们之间没有任何关系,都是一个个孤立的节点。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 节点依次请求申请加锁,如果客户端能够和半数以上的节点成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
这样一来,即使有某个 Redis 节点发生故障,因为锁的数据在其他节点上也有保存,所以客户端仍然可以正常地进行锁操作,锁的数据也不会丢失。
Redlock 算法加锁三个过程:
- 客户端获取当前时间(t1)。
- 客户端按顺序依次向 N 个 Redis 节点执行加锁操作:
- 加锁操作使用 SET 命令,带上 NX,EX/PX 选项,以及带上客户端的唯一标识。
- 如果某个 Redis 节点发生故障了,为了保证在这种情况下,Redlock 算法能够继续运行,我们需要给「加锁操作」设置一个超时时间(不是对「锁」设置超时时间,而是对「加锁操作」设置超时时间),加锁操作的超时时间需要远远地小于锁的过期时间,一般也就是设置为几十毫秒。
- 一旦客户端从超过半数(大于等于 N/2+1)的 Redis 节点上成功获取到了锁,就再次获取当前时间(t2),然后计算计算整个加锁过程的总耗时(t2-t1)。如果 t2-t1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败。
可以看到,加锁成功要同时满足两个条件(简述:如果有超过半数的 Redis 节点成功的获取到了锁,并且总耗时没有超过锁的有效时间,那么就是加锁成功):
- 客户端从超过半数(大于等于 N/2+1)的 Redis 节点上成功获取到了锁;
- 客户端从大多数节点获取锁的总耗时(t2-t1)小于锁设置的过期时间。
加锁成功后,客户端需要重新计算这把锁的有效时间,计算的结果是「锁最初设置的过期时间」减去「客户端从大多数节点获取锁的总耗时(t2-t1)」。如果计算的结果已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况。
加锁失败后,客户端向所有 Redis 节点发起释放锁的操作,释放锁的操作和在单节点上释放锁的操作一样,只要执行释放锁的 Lua 脚本就可以了。

