联邦学习综述性论文
Client Selection in Federated Learning: Principles, Challenges, and Opportunities
一、摘要
大量的工作旨在解决FL训练的不同方面,如优化聚合方法,增强隐私保护和改进鲁棒性。
一个有效的FL客户端选择方案可以显著提高模型的准确性,增强公平性,增强鲁棒性,并减少训练开销。
二、异质性 heterogeneity
2.1 系统的异构性
计算能力
通信能力
其他因素:如电池电量低、后台运行许多应用程序
2.2 统计异质性
大规模分布式数据,FL客户端的数量远远大于客户端的平均数据点数量。例如,一百万部智能手机参与了谷歌键盘查询建议项目[47],但一个用户通常每天最多只提出几十个查询
数据不平衡
非IID数据
三、效用
每轮根据客户端的“效用”排序客户端,选择效用最大的客户端
效应=统计效用*系统效用
3.1 统计效用
统计效用主要考虑量化当前训练轮每个客户端的重要性
3.1.1 基于数据样本的效用度量
基于数据样本的效用利用客户端的本地数据来量化统计效用
(1)根据数据集数量\(|D_i|\)
当每个数据样本具有相同的质量时,这种方法是有效的
(2)数据样本的重要性抽样
这个想法是给偏离模型很远的数据样本分配一个高重要性分数。
用梯度衡量
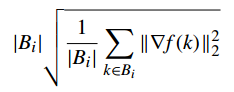
(3)把梯度用Loss值代替
大大减少了计算开销
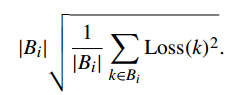
(4)累计损失
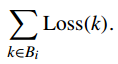
3.1.2 基于模型的效用度量
比较其模型权重
(1)归一化模型散度
用自己的梯度跟全局模型梯度每一维的距离的平均值来表示其重要性,如果均值很小,那么本地更新是微不足道的,可以忽略
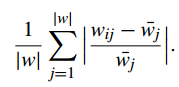
(2)统计同号权重的百分比
将其视为相对于全局模型的方向
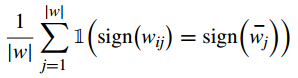
同号权重的百分比越低,收敛时的通信效率越高。
(3)与收敛趋势的相似性
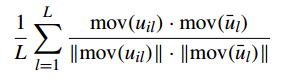
\(u_{il}\)表示第i个客户端的模型的第\(l\)层的梯度,mov表示运动方向。越大越好
(4)不与全局模型比,与上一轮的自己比
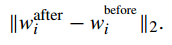
越大越好
(5)梯度长度
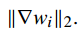
越大越好
(6)梯度的相对方向
计算内积,内积可以代表相对方向
删除具有负内积的客户端
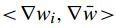
3.2 系统效用
系统效用主要考虑时间开销。
(1)设置一个截止时间
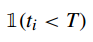
(2)软截止时间
设置截止时间来惩罚掉队者
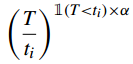
对于非掉队者,式子的值为1,没有惩罚。对于掉队者,式子指数增长
T还可以换成时间之外的其他度量,比如速度、带宽
还可以将T改成“经验的”empirical,即自己调整自己的。
3.3 调度
在得到统计效用和系统效用之后,可以相乘得到整体效用
在每一轮中衡量每个客户端是不现实的,因为效用通常只有在参加了一轮训练后才能得到。所以需要对没参与的客户端进行预测。
可以将效用里的各个项相乘,也可以相加
四、当前的算法实现
4.1 数据模拟
(1)合成数据分离
将不同的数据集分给不同的客户端,这种方法灵活性高,可以模拟不同程度的数据异构。
(2)实际数据分离
采用带有客户端ID的数据集,并使用唯一的客户端ID分开数据集。
这种方法可以更准确地捕捉FL在实际场景中的性能。
4.2 联邦学习框架
略。
五、挑战
设备并不总是可用的,通常情况下,设备只有在闲置、充电和连接WiFi时才可用,以保护用户体验。
总是选择优先的客户端往往导致次优性能,需要在“利用”(选择优先的客户端)和“探索”(选择更多样化的客户端)之间求得平衡
六、研究的机遇
(1)所选客户端的最优数量
提高客户端数量可以提高FL的收敛速度,但随着客户端数量的增加,提高的效果会逐渐减少,且时间和带宽开销变得很大。
一般客户端模式的数量是递增的
在训练时自动调整客户端数量
(2)理论性能保证
现有的FL客户端选择工作大多依靠实验来证明其有效性,容易受到实验偏差的影响。
为算法在模型精度、收敛速度、鲁棒性、公平性等方面提供理论保证是一项挑战
(3)基准和评估指标
现有的工作采用各种度量来评估其性能:Final model accuracy, time-toaccuracy, round-to-accuracy, transmission load, etc.但是,不同的指标是没有可比性的。
需要有更完善的基准和评估指标来公平可观地比较不同的FL客户端选择算法。
(4)扩展到其他联邦学习场景
除了经典的FL场景,FL场景的其他变体也越来越受到学术界的关注。
分层的(hierarchical)FL
基于聚类的FL:根据数据分布或系统能力将客户端分组到不同的簇里,然后调度簇以获得更好的性能
在线FL:需要用户在使用时进行轻量级更新,而不是等待空闲充电的WiFi条件。
无服务器FL:没有用于训练协调的固定和永久的服务器,而是采用点对点方法。
(5)大型开放式FL试验台
现有工作的观察结果并不完全符合实际的FL性能,特别是对于FL客户端选择的研究,其应用场景往往需要大量的客户端。
缺少用于研究的大规模开放式试验台。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号