
美团Leaf号段模式详解
号段模式 VS 批量生成ID
号段模式的一般流程
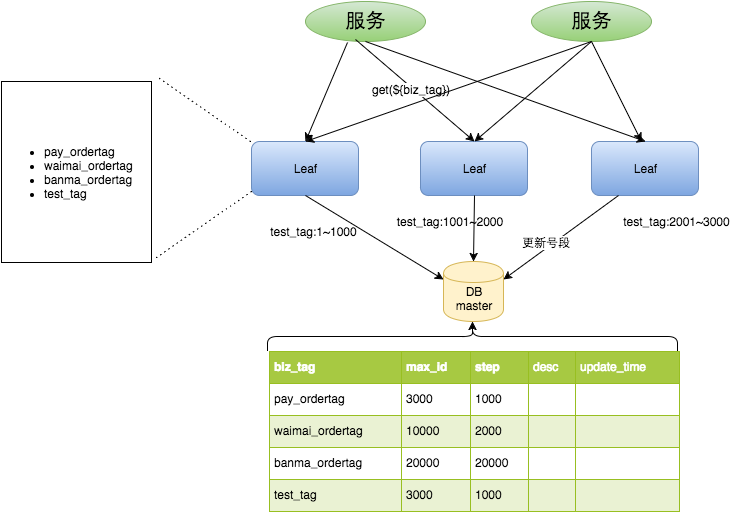
号段模式的新的问题
美团Leaf 号段模式
- 每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
- 每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
美团Leaf号段模式源码分析
public class SegmentIDGenImpl implements IDGen {
private static final Logger logger = LoggerFactory.getLogger(SegmentIDGenImpl.class);
/**
* IDCache未初始化成功时的异常码
*/
private static final long EXCEPTION_ID_IDCACHE_INIT_FALSE = -1;
/**
* key不存在时的异常码
*/
private static final long EXCEPTION_ID_KEY_NOT_EXISTS = -2;
/**
* SegmentBuffer中的两个Segment均未从DB中装载时的异常码
*/
private static final long EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL = -3;
/**
* 最大步长不超过100,0000
*/
private static final int MAX_STEP = 1000000;
/**
* 一个Segment维持时间为15分钟
*/
private static final long SEGMENT_DURATION = 15 * 60 * 1000L;
// 最多5个线程,也就是最多5个任务同时执行(因为可能有多个tag,如果tag 只有1、2个,那么没必要5个线程);idle时间是60s;
// SynchronousQueue意思是,只能有一个线程执行一个tag的任务,立即执行,执行完立即获取;其他的都只能阻塞式等待
private ExecutorService service = new ThreadPoolExecutor(5, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), new UpdateThreadFactory());
private volatile boolean initOK = false;
// 注意它包含了所有的SegmentBuffer,k是业务类型,v是对应的
// 全局缓存
private Map<String, SegmentBuffer> cache = new ConcurrentHashMap<String, SegmentBuffer>();
private IDAllocDao dao;
public static class UpdateThreadFactory implements ThreadFactory {
private static int threadInitNumber = 0;
private static synchronized int nextThreadNum() {
return threadInitNumber++;
}
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "Thread-Segment-Update-" + nextThreadNum());
}
}
@Override
public boolean init() {
logger.info("Init ...");
// 确保加载到kv后才初始化成功
updateCacheFromDb();
initOK = true;
updateCacheFromDbAtEveryMinute();
return initOK;
}
private void updateCacheFromDbAtEveryMinute() {// 顾名思义, 每分钟执行一次。执行什么? 执行 updateCacheFromDb方法
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor(new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setName("check-idCache-thread");
t.setDaemon(true);
return t;
}
});
service.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
updateCacheFromDb();
}
}, 60, 60, TimeUnit.SECONDS);
}
// 通过数据库 来更新cache缓存, 也就是Map<String, SegmentBuffer> cache。注意它包含了所有的SegmentBuffer
// 总结就是, 把db新增的tag, 初始化并添加到cache,把db删除的tag,从cache中删除;db中更新的呢?这里不管,后面由更新线程去维护到cache
// init的时候执行一次,后面每分钟执行一次
private void updateCacheFromDb() {
logger.info("update cache from db");
StopWatch sw = new Slf4JStopWatch();
try {
List<String> dbTags = dao.getAllTags();// 可能有新加的tags, 这里仅仅加载 tag,不包括value
if (dbTags == null || dbTags.isEmpty()) {
return;
}
List<String> cacheTags = new ArrayList<String>(cache.keySet());
Set<String> insertTagsSet = new HashSet<>(dbTags);
Set<String> removeTagsSet = new HashSet<>(cacheTags);
//db中新加的tags灌进cache
for(int i = 0; i < cacheTags.size(); i++){
String tmp = cacheTags.get(i);
if(insertTagsSet.contains(tmp)){
insertTagsSet.remove(tmp); // 数据库中已经存在于cache中的,是旧的,先删除
}
}
for (String tag : insertTagsSet) {// 现在insertTagsSet的部分都是全新的tags
SegmentBuffer buffer = new SegmentBuffer();// 默认 SegmentBuffer的init 是false
buffer.setKey(tag);
Segment segment = buffer.getCurrent();// currentPos 永远只会在 0/1之间切换
segment.setValue(new AtomicLong(0));// value表示 实际的分布式的唯一id值
segment.setMax(0); // max 是 当前号段的 最大值; step 是步长,它会根据消耗的速度自动调整!
segment.setStep(0);// 默认 value、max、 step 都是0 —— 也就是, 全部重置!
cache.put(tag, buffer);// 添加到全局的 cache
logger.info("Add tag {} from db to IdCache, SegmentBuffer {}", tag, buffer);
}
//cache中已失效的tags从cache删除
for(int i = 0; i < dbTags.size(); i++){
String tmp = dbTags.get(i);
if(removeTagsSet.contains(tmp)){ // 两个contains 都是在寻找重叠部分
removeTagsSet.remove(tmp);//cache中存在于数据库中的,先从缓存中删除
}
}
for (String tag : removeTagsSet) { // 现在removeTagsSet的部分都是是旧的、已经失效的tags
cache.remove(tag); // 又从全局的 cache中删除。
logger.info("Remove tag {} from IdCache", tag);
}
} catch (Exception e) {
logger.warn("update cache from db exception", e);
} finally {
sw.stop("updateCacheFromDb");
}
}
@Override
public Result get(final String key) {
if (!initOK) { // 全局cache 是否初始化完成? 一般是不会说没有完成初始化
return new Result(EXCEPTION_ID_IDCACHE_INIT_FALSE, Status.EXCEPTION);
}
if (cache.containsKey(key)) {
SegmentBuffer buffer = cache.get(key);
if (!buffer.isInitOk()) {// 对应key的buffer 是否初始化完成? 第一次调用get方法肯定是false
synchronized (buffer) { // 没完成则加锁, 因为可能有多线程调用此get 方法
if (!buffer.isInitOk()) {// 再次判断, 防止 xxx问题
try {
updateSegmentFromDb(key, buffer.getCurrent());// 通过数据库 初始化、更新buffer中 的当前号段
logger.info("Init buffer. Update leafkey {} {} from db", key, buffer.getCurrent());
buffer.setInitOk(true);// 必须到这里 才算完成buffer的 初始化; 也是全局唯一被调用的地方!
} catch (Exception e) {
logger.warn("Init buffer {} exception", buffer.getCurrent(), e);
}
}
}
}
// 到这里,肯定已经完成对应key的buffer的初始化, 所以直接从号段缓存中 获取id
return getIdFromSegmentBuffer(cache.get(key));// 直接从号段缓存中 获取id
}
//可能数据库中不存在对应的key, 那就暂时只能异常返回
return new Result(EXCEPTION_ID_KEY_NOT_EXISTS, Status.EXCEPTION);
}
// 通过数据库 更新buffer中 的号段
// 注意 initOK为true,号段 缓存可能还没有初始化; 也就是init() 方法实际并没有对缓存做 初始化。
// 全局被调用的地方, 就两处
public void updateSegmentFromDb(String key, Segment segment) {
StopWatch sw = new Slf4JStopWatch();
SegmentBuffer buffer = segment.getBuffer();
LeafAlloc leafAlloc;
if (!buffer.isInitOk()) {// 再次判断,第一次调用get方法肯定init=false,于是进入这个if
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);// 直接查询数据库
buffer.setStep(leafAlloc.getStep());
buffer.setMinStep(leafAlloc.getStep());//leafAlloc中的step为DB中的step; 最小步长,表明真正的步长是可能大于minStep的
} else if (buffer.getUpdateTimestamp() == 0) {// 如果buffer已经init过,第二次会进这个if, 因为setUpdateTimestamp全局被调用两次,这个if和下一个else
leafAlloc = dao.updateMaxIdAndGetLeafAlloc(key);//
buffer.setUpdateTimestamp(System.currentTimeMillis());// 唯二的全局被调用;为什么有这个if, 为什么特地需要特地调用这个方法
buffer.setStep(leafAlloc.getStep());// 和上一个if 是不是重复了? 代码是不是有些啰嗦?
buffer.setMinStep(leafAlloc.getStep());// minStep的作用仅仅是为了 动态调整, 实际使用的还是 step !!
} else {// 如果buffer已经init过,第三次会进这个else; 这里其实是根据duration 动态调整步长!
long duration = System.currentTimeMillis() - buffer.getUpdateTimestamp();
int nextStep = buffer.getStep();
if (duration < SEGMENT_DURATION) {// 如果duration 太短了, 那么说明步长有点小,id 消耗快,那么进入调整。
if (nextStep * 2 > MAX_STEP) { // 如果*2 会超出最大步长,那就不调整了,否则就*2
//do nothing
} else {
nextStep = nextStep * 2;
}
} else if (duration < SEGMENT_DURATION * 2) { 如果 SEGMENT_DURATION < duration < SEGMENT_DURATION * 2, 那么不管
//do nothing with nextStep
} else {// 否则就是 > SEGMENT_DURATION * 2; 那么 步长除以2,但是不能小于min
nextStep = nextStep / 2 >= buffer.getMinStep() ? nextStep / 2 : nextStep;
}
logger.info("leafKey[{}], step[{}], duration[{}mins], nextStep[{}]", key, buffer.getStep(), String.format("%.2f",((double)duration / (1000 * 60))), nextStep);
LeafAlloc temp = new LeafAlloc();
temp.setKey(key);
temp.setStep(nextStep);
leafAlloc = dao.updateMaxIdByCustomStepAndGetLeafAlloc(temp);// 动态调整记录到数据库中~
buffer.setUpdateTimestamp(System.currentTimeMillis());// 唯二的全局被调用
buffer.setStep(nextStep);
buffer.setMinStep(leafAlloc.getStep());//leafAlloc的step为DB中的step
}
// must set value before set max
long value = leafAlloc.getMaxId() - buffer.getStep();//leafAlloc.getMaxId()是后端新的最大值,buffer.getStep()是新的步长
segment.getValue().set(value);// value 和max 构成了 号段的起止值; value 其实命名并不好,容易让人误解!
segment.setMax(leafAlloc.getMaxId()); // value 、max、step 都设置好了,表示 号段初始化、更新完成
segment.setStep(buffer.getStep());
sw.stop("updateSegmentFromDb", key + " " + segment);
}
// 直接从号段缓存中 获取id
// 获取的时候, 需要检查是否超过了 10%, 超过则 另外启动任务去异步 加载新的 号段!
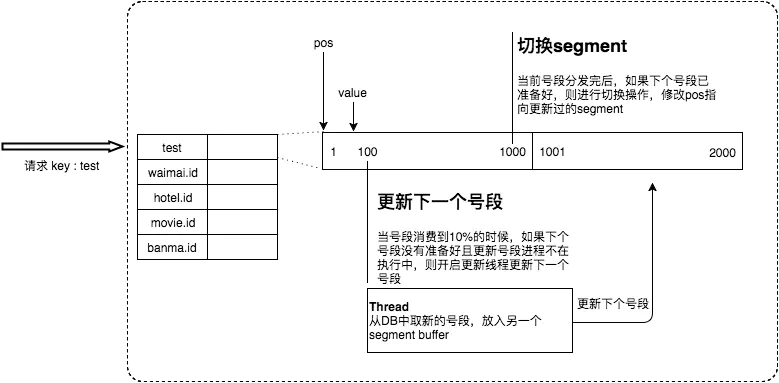
public Result getIdFromSegmentBuffer(final SegmentBuffer buffer) {
while (true) {
buffer.rLock().lock();
try {
final Segment segment = buffer.getCurrent();
// 每次get 都会进入这里,但是其实 isNextReady条件 只有设置一次
if (!buffer.isNextReady() && (segment.getIdle() < 0.9 * segment.getStep()) && buffer.getThreadRunning().compareAndSet(false, true)) {
service.execute(new Runnable() {// 异步执行
@Override
public void run() { // 进入了这个方法,buffer.getThreadRunning 已经被cas设置为了true; 保证了 这个方法不会有并发
Segment next = buffer.getSegments()[buffer.nextPos()];
boolean updateOk = false;
try {
updateSegmentFromDb(buffer.getKey(), next);// next 是指使用 下一个号段;这里也就是更新下一个号段
updateOk = true;
logger.info("update segment {} from db {}", buffer.getKey(), next);
} catch (Exception e) {
logger.warn(buffer.getKey() + " updateSegmentFromDb exception", e);
} finally {
if (updateOk) {
buffer.wLock().lock();// 这里使用了 写锁, 是因为有写 的并发竞争
buffer.setNextReady(true);// 表示下一个号段已经准备好!
buffer.getThreadRunning().set(false);// 操作完毕,又把buffer线程状态设置为false,因为task 已经执行完
buffer.wLock().unlock();
} else {
buffer.getThreadRunning().set(false);// 不管怎么样,需要把buffer线程状态设置为false,因为task 已经执行完
}
}
}
});
}
long value = segment.getValue().getAndIncrement();// 这里可能有读的并发,
if (value < segment.getMax()) { // 未达到号段的最大值,也就是最右端
return new Result(value, Status.SUCCESS);// 到这里, 就成功返回; 一般情况 就是进入这个if 然后返回!
}
} finally {
buffer.rLock().unlock(); // 不管怎么样,这里释放读锁
}
//什么情况会需要wait? 上面的方法没有进入上一个if已经达到号段的最大值! 或者出现异常,当然一般不会有异常;
//达到号段的最大值 意味着需要使用下一个号段,
// waitAndSleep其实是等待 正在执行的线程把任务执行完成;具体是 判断并自旋10000,然后超过10000,那就每次sleep 10毫秒,然后退出..
waitAndSleep(buffer);// 总之,waitAndSleep保证没有正在执行的更新线程; 但也不是100% 保证!
buffer.wLock().lock();// 执行写锁, 排斥任何其他的线程!
try {
final Segment segment = buffer.getCurrent();// 能继续使用同一个号段吗?
long value = segment.getValue().getAndIncrement();
if (value < segment.getMax()) {// 为什么需要再次判断? max会在已经确定的情况下变化? 也不会,大概是保险起见?
return new Result(value, Status.SUCCESS);
}
if (buffer.isNextReady()) {// 已经达到号段的最大值,此时前面必然已经完成了新号段的获取, 肯定进入此判断
buffer.switchPos(); // 全局唯一的 切换! 虽然完成了切换, 但是不立即获取value,而是等待下一次的循环!
buffer.setNextReady(false);
} else {// 这种情况, 不太可能发生吧!
logger.error("Both two segments in {} are not ready!", buffer);
return new Result(EXCEPTION_ID_TWO_SEGMENTS_ARE_NULL, Status.EXCEPTION);
}
} finally {
buffer.wLock().unlock();
}
}
}
private void waitAndSleep(SegmentBuffer buffer) {
int roll = 0;
while (buffer.getThreadRunning().get()) {
roll += 1;
if(roll > 10000) {
try {
TimeUnit.MILLISECONDS.sleep(10);
break;// 不管怎么样,需要退出, 不能在这个方法等太久。 就是说, 极端情况下, 此方法不能保证 等待正在执行的任务完成。
} catch (InterruptedException e) {
logger.warn("Thread {} Interrupted",Thread.currentThread().getName());
break;
}
}
}
}
public List<LeafAlloc> getAllLeafAllocs() {
return dao.getAllLeafAllocs();
}
public Map<String, SegmentBuffer> getCache() {
return cache;
}
public IDAllocDao getDao() {
return dao;
}
public void setDao(IDAllocDao dao) {
this.dao = dao;
}
}
代码质量还是不错的,简直是神乎其神的刀法!
美团leaf号段模式的部署和使用
@Update("UPDATE leaf_alloc SET max_id = max_id + #{step} WHERE biz_tag = #{key}") @Update("UPDATE leaf_alloc SET max_id = max_id + step WHERE biz_tag = #{tag}")
step 是初始化完成的,默认应该是使用方。
官方提供了leaf-core、leaf-server。 其中 leaf-core是核心算法的实现, 但是它主要依赖于mybatis、数据库,但是它不能直接运行。 leaf-server 调用了它, 并负责完成leaf_alloc 表的初始化。对于号段模式,主要就是在SegmentService, 其核心作用就是 实例化了一个IDGen(具体是SegmentIDGenImpl),然后 使用它对外提供分布式id服务。
前面说错了,leaf_alloc 表的初始化并不是 leaf-server 程序完成的,而是需要手动新增自己需要的业务数据, 其实就是一条insert 语句,参见官方:
insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
这个务必记住。
实际怎么做?
因为它不知道你的业务tag和step 是多少啊。 tag 当然是自定义, step 对于高并发的项目就1000,一般小项目就100够了吧!
所以呢,想简单使用的话,一般直接部署一个leaf-server就好了。
leaf-server 是必须的吗
leaf-server 可以独立运行和工作,并提供了rest http接口来获取id,好像也非常合理好用,我们直接使用它就可以了,那么它是不是必须的呢?肯定不是。原因是:
1 它本身有可能存在单点的问题了。
2 如果你不想通过http方式获取id(这样显然有性能损失)
3 它强制依赖了druid
我认为我们可以适当做一些改造、集成。 就是把leaf-server 当做一个普通jar 引入,或者只用其中需要的几个类,或者,完全不用它,就自己写; 因为它强制依赖了druid,如果我们已经使用了比如hikari 这样的数据连接池, 需要统一连接池, 不想引入其他的连接池, 那么我们完全可以 按照自己的方式实例化IDGen !

 浙公网安备 33010602011771号
浙公网安备 33010602011771号