
记一次性能优化的心酸历程【Flask+Gunicorn+pytorch+多进程+线程池,一顿操作猛如虎】
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
本文只是记录我优化的心酸历程。无他,唯记录尔。。。。。小伙伴们可围观,可打call,可以私信与我交流。
干货满满,建议收藏,需要用到时常看看。 小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~。
问题背景
现有一个古诗自动生成的训练接口,该接口通过Pytorch来生训练模型(即生成古诗)为了加速使用到了GPU,但是训练完成之后GPU未能释放。故此需要进行优化,即在古诗生成完成之后释放GPU。
该项目是一个通过Flask搭建的web服务,在服务器上为了实现并发采用的是gunicorn来启动应用。通过pythorch来进行古诗训练。项目部署在一个CentOS的服务器上。
系统环境
| 软件 | 版本 |
|---|---|
| flask | 0.12.2 |
| gunicorn | 19.9.0 |
| CentOS 6.6 | 带有GPU的服务器,不能加机器 |
| pytorch | 1.7.0+cpu |
因为特殊的原因这里之后一个服务器供使用,故不能考虑加机器的情况。
优化历程
pytorch在训练模型时,需要先加载模型model和数据data,如果有GPU显存的话我们可以将其放到GPU显存中加速,如果没有GPU的话则只能使用CPU了。
由于加载模型以及数据的过程比较慢。所以,我这边将加载过程放在了项目启动时加载。
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = GPT2LMHeadModel.from_pretrained(os.path.join(base_path, "model"))
model.to(device)
model.eval()
这部分耗时大约在6秒左右。cuda表示使用torch的cuda。模型数据加载之后所占的GPU显存大小大约在1370MB。优化的目标就是在训练完成之后将这部分占用的显存释放掉。
小小分析一波
现状是项目启动时就加载模型model和数据data的话,当模型数据在GPU中释放掉之后,下次再进行模型训练的话不就没有模型model和数据data了么?如果要释放GPU的话,就需要考虑如何重新加载GPU。
所以,模型model和数据data不能放在项目启动的时候加载,只能放在调用训练的函数时加载,但是由于加载比较慢,所以只能放在一个异步的子线程或者子进程中运行。
所以,我这边首先将模型数据的加载过程以及训练放在了一个单独的线程中执行。
第一阶段:直接上torch.cuda.empty_cache()清理。
GPU没释放,那就释放呗。这不是很简单么?百度一波pytorch怎么释放GPU显存。

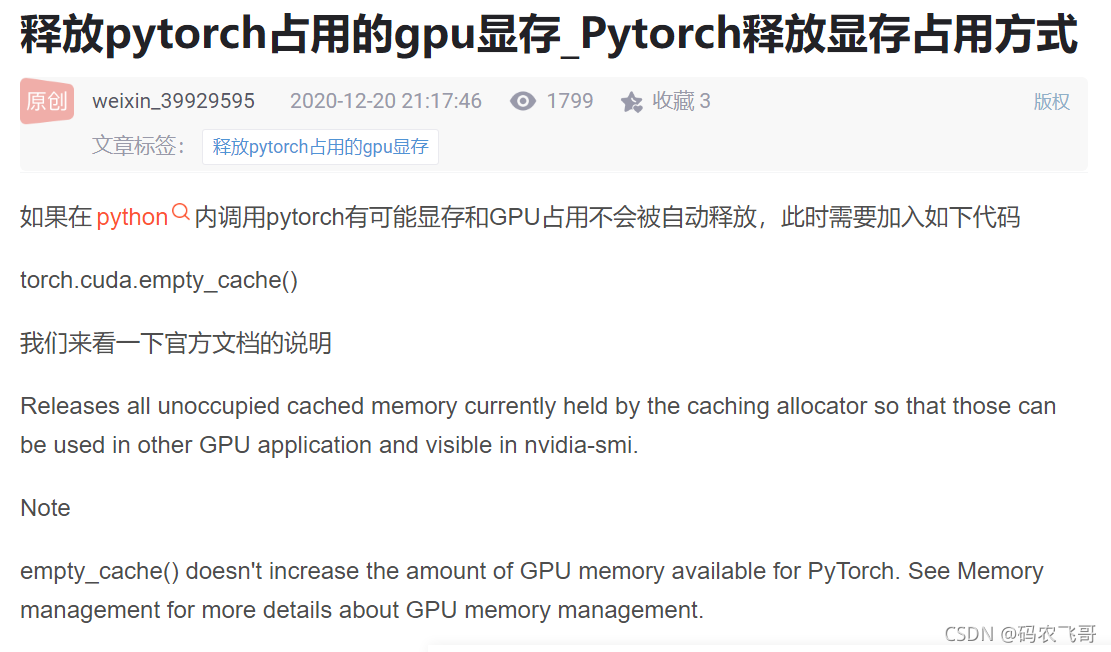
轻点一下,即找到了答案。那就是在训练完成之后torch.cuda.empty_cache() 。代码加上之后再运行,发现并没啥卵用!!!!,CV大法第一运用失败
这到底是啥原因呢?我们后面会分析到!!!
第二阶段(创建子进程加载模型并进行训练)
既然子线程加载模型并进行训练不能释放GPU的话,那么我们能不能转变一下思路。创建一个子进程来加载模型数据并进行训练,
当训练完成之后就将这个子进程杀掉,它所占用的资源(主要是GPU显存)不就被释放了么?
这思路看起来没有丝毫的毛病呀。说干就干。
- 定义加载模型数据以及训练的方法 training。(代码仅供参考)
def training(queue):
manage.app.app_context().push()
current_app.logger.error('基础加载开始')
with manage.app.app_context():
device = "cuda" if torch.cuda.is_available() else "cpu"
current_app.logger.error('device1111开始啦啦啦')
model.to(device)
current_app.logger.error('device2222')
model.eval()
n_ctx = model.config.n_ctx
current_app.logger.error('基础加载完成')
#训练方法
result_list=start_train(model,n_ctx,device)
current_app.logger.error('完成训练')
#将训练方法返回的结果放入队列中
queue.put(result_list)
- 创建子进程执行training方法,然后通过阻塞的方法获取训练结果
from torch import multiprocessing as mp
def sub_process_train():
#定义一个队列获取训练结果
train_queue = mp.Queue()
training_process = mp.Process(target=training, args=(train_queue))
training_process.start()
current_app.logger.error('子进程执行')
# 等训练完成
training_process.join()
current_app.logger.error('执行完成')
#获取训练结果
result_list = train_queue.get()
current_app.logger.error('获取到数据')
if training_process.is_alive():
current_app.logger.error('子进程还存活')
#杀掉子进程
os.kill(training_process.pid, signal.SIGKILL)
current_app.logger.error('杀掉子进程')
return result_list
- 因为子进程要阻塞获取执行结果,所以需要定义一个线程去执行sub_process_train方法以保证训练接口可以正常返回。
import threading
threading.Thread(target=sub_process_train).start()
代码写好了,见证奇迹的时候来了。
首先用python manage.py 启动一下,看下结果,运行结果如下,报了一个错误,从错误的提示来看就是不能在forked的子进程中重复加载CUDA。 "Cannot re-initialize CUDA in forked subprocess. " + msg) RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method。
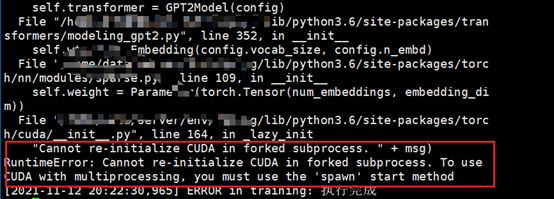
这里有问题,就是 forked 是啥,spawn 又是啥?这里就需要了解创建子进程的方式了。
通过torch.multiprocessing.Process(target=training, args=(train_queue)) 创建一个子进程
fork和spawn是构建子进程的不同方式,区别在于
1. fork: 除了必要的启动资源,其余的变量,包,数据等都集成自父进程,也就是共享了父进程的一些内存页,因此启动较快,但是由于大部分都是用的自父进程数据,所有是不安全的子进程。
2. spawn:从头构建一个子进程,父进程的数据拷贝到子进程的空间中,拥有自己的Python解释器,所有需要重新加载一遍父进程的包,因此启动叫慢,但是由于数据都是自己的,安全性比较高。
回到刚刚那个报错上面去。为啥提示要不能重复加载。
这是因为Python3中使用 spawn启动方法才支持在进程之间共享CUDA张量。而用的multiprocessing 是使用 fork 创建子进程,不被 CUDA 运行时所支持。
所以,只有在创建子进程之前加上 mp.set_start_method('spawn') 方法。即
def sub_process_train(prefix, length):
try:
mp.set_start_method('spawn')
except RuntimeError:
pass
train_queue = mp.Queue()
training_process = mp.Process(target=training, args=(train_queue))
##省略其他代码
再次通过 python manage.py 运行项目。运行结果图1和图2所示,可以看出可以正确是使用GPU显存,在训练完成之后也可以释放GPU。
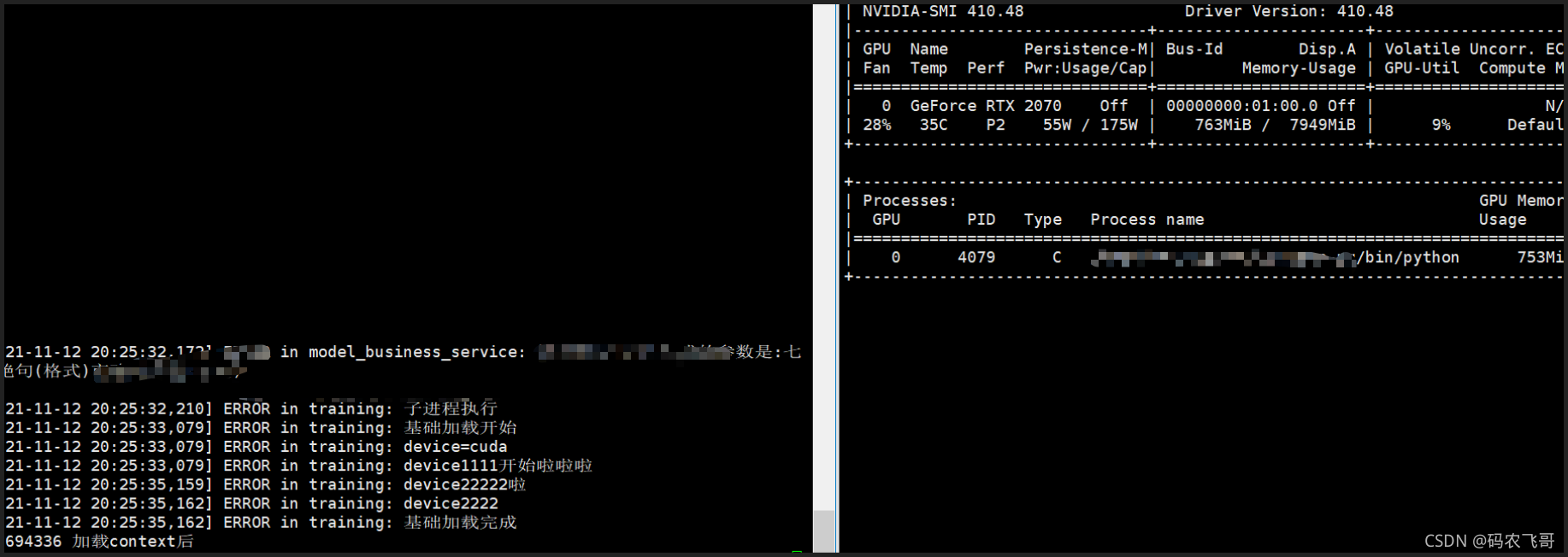
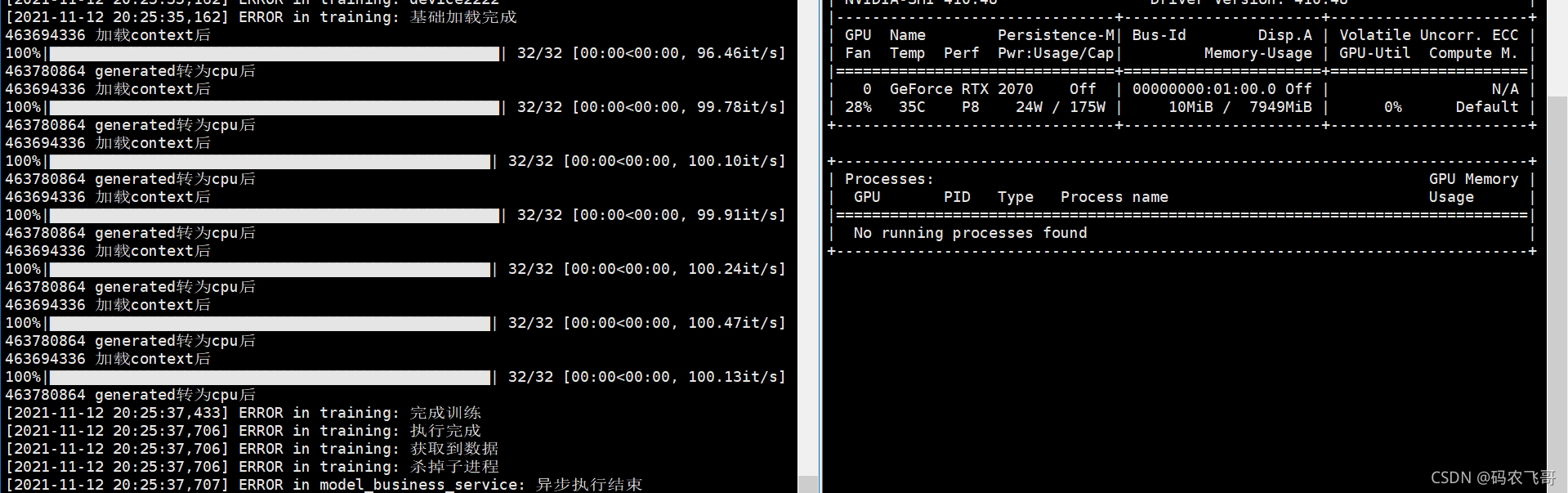
一切看起来都很prefect。 But,But。通过gunicorn启动项目之后,再次调用接口,则出现下面结果。

用gunicorn启动项目子进程竟然未执行,这就很头大了。不加mp.set_start_method('spawn') 方法模型数据不能加载,
加上这个方法子进程不能执行,真的是一个头两个大。
第三阶段(全局线程池+释放GPU)
子进程的方式也不行了。只能回到前面的线程方式了。前面创建线程的方式都是直接通过直接new一个新线程的方式,当同时运行的线程数过多的话,则很容易就会出现GPU占满的情况,从而导致应用崩溃。所以,这里采用全局线程池的方式来创建并管理线程,然后当线程执行完成之后释放资源。
- 在项目启动之后就创建一个全局线程池。大小是2。保证还有剩余的GPU。
from multiprocessing.pool import ThreadPool
pool = ThreadPool(processes=2)
- 通过线程池来执行训练
pool.apply_async(func=async_produce_poets)
- 用线程加载模型和释放GPU
def async_produce_poets():
try:
print("子进程开始" + str(os.getpid())+" "+str(threading.current_thread().ident))
start_time = int(time.time())
manage.app.app_context().push()
device = "cuda" if torch.cuda.is_available() else "cpu"
model = GPT2LMHeadModel.from_pretrained(os.path.join(base_path, "model"))
model.to(device)
model.eval()
n_ctx = model.config.n_ctx
result_list=start_train(model,n_ctx,device)
#将模型model转到cpu
model = model.to('cpu')
#删除模型,也就是删除引用
del model
#在使用其释放GPU。
torch.cuda.empty_cache()
train_seconds = int(time.time() - start_time)
current_app.logger.info('训练总耗时是={0}'.format(str(train_seconds)))
except Exception as e:
manage.app.app_context().push()
这一番操作之后,终于达到了理想的效果。
这里因为使用到了gunicorn来启动项目。所以gunicorn 相关的知识必不可少。在CPU受限的系统中采用sync的工作模式比较理想。
详情可以查看gunicorn的简单总结
问题分析,前面第一阶段直接使用torch.cuda.empty_cache() 没能释放GPU就是因为没有删除掉模型model。模型已经加载到了GPU了。
总结
本文从实际项目的优化入手,记录优化方面的方方面面。希望对读者朋友们有所帮助。
参考
multiprocessing fork() vs spawn()
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java高频面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
全网同名【码农飞哥】。不积跬步,无以至千里,享受分享的快乐
我是码农飞哥,再次感谢您读完本文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号