19. 迭代器模式
一、迭代器模式
在软件开发时,经常需要使用聚合对象来存储一系列数据。聚合对象拥有两个职责:一是 存储数据;二是 遍历数据。从依赖性来看,前者是聚合对象的基本职责;而后者既是可变化的,又是可分离的。因此,可以将遍历数据的行为从聚合对象中分离出来,封装在一个被称之为 “迭代器” 的对象中。由迭代器来提供遍历聚合对象内部数据的行为,这将简化聚合对象的设计,更符合单一职责原则的要求。
迭代器模式(Iterator Pattern)是一种行为设计模式,用于提供一种在不暴露集合底层表现形式(如数组、链表等)的情况下遍历集合中各个元素的方法。这种模式分离了集合的遍历行为与集合的底层结构,使得同样的遍历行为可以用于不同的集合类型上。
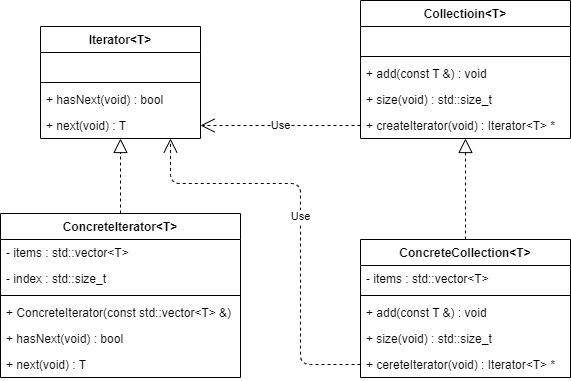
迭代器模式的主要角色如下:
- 迭代器接口(Iterator) :它定义了访问和遍历元素的接口,声明了用于遍历数据元素的方法。
- 具体迭代器类 (ConcreteIterator):它实现了抽象迭代器接口,完成对聚合对象的遍历,同时在具体迭代器中通过游标来记录在聚合对象中所处的当前位置。在具体实现时,游标通常是一个表示位置的非负整数。
- 集合接口(Aggregate) :它用于存储和管理元素对象,声明一个 createIterator() 方法用于创建一个迭代器对象,充当抽象迭代器工厂角色。
- 具体集合类(ConcreteAggregate) :它实现了在抽象聚合类中声明的 createIterator() 方法,该方法返回一个与该具体聚合类对应的具体迭代器 ConcreteIterator 实例。
在迭代器模式中,通常会定义一个迭代器接口,用于声明访问和遍历元素的接口方法,如 hasNext()和 next()。然后具体的迭代器类会实现这个接口,并提供访问特定集合的方法。这样,不管集合的底层结构如何变化,只要迭代器接口保持不变,使用迭代器的代码就不需要修改。
迭代器模式中,提供了一个外部的迭代器来对聚合对象进行访问和遍历。迭代器定义了一个访问该聚合元素的接口,并且可以跟踪当前遍历的元素,了解哪些元素已经遍历过而哪些没有。迭代器的引入,将使得对一个复杂聚合对象的操作变得简单。
二、C++实现迭代器模式
在抽象迭代器中声明了用于遍历聚合对象中所存储元素的方法。
// 迭代器接口
template <typename T>
class Iterator
{
public:
virtual bool hasNext(void) = 0;
virtual T next(void) = 0;
};
在具体迭代器中将实现在抽象迭代器中声明的遍历数据方法。
// 具体迭代器
template <typename T>
class ConcreteIterator : public Iterator<T>
{
private:
std::vector<T> items;
std::size_t index;
public:
ConcreteIterator(const std::vector<T>& items);
bool hasNext(void) override;
T next(void) override ;
};
template <typename T>
ConcreteIterator<T>::ConcreteIterator(const std::vector<T>& items) : items(items), index(0) {}
template <typename T>
bool ConcreteIterator<T>::hasNext(void)
{
return index < items.size();
}
template <typename T>
T ConcreteIterator<T>::next(void)
{
if (!hasNext())
{
throw std::out_of_range("Iterator out of range");
}
return items[index++];
}
聚合类用于存储数据并负责创建迭代器对象。
// 集合接口
template <typename T>
class Collection
{
public:
virtual void add(const T & item) = 0;
virtual std::size_t size(void) = 0;
virtual Iterator<T> * createIterator(void) = 0;
};
具体聚合类作为抽象聚合类的子类,一方面负责存储数据,另一方面实现了在抽象聚合类中声明的工厂方法 createIterator(),用于返回一个与该具体聚合类对应的具体迭代器对象。
// 具体集合
template <typename T>
class ConcreteCollection : public Collection<T>
{
private:
std::vector<T> items;
public:
void add(const T & item) override;
std::size_t size(void) override;
Iterator<T> * createIterator(void) override;
};
template <typename T>
void ConcreteCollection<T>::add(const T & item)
{
items.push_back(item);
}
template <typename T>
std::size_t ConcreteCollection<T>::size(void)
{
return items.size();
}
template <typename T>
Iterator<T> * ConcreteCollection<T>::createIterator(void)
{
return new ConcreteIterator<T>(items);
}
main() 函数:
#include <iostream>
#include <vector>
int main(void)
{
ConcreteCollection<int> collection;
collection.add(1);
collection.add(2);
collection.add(3);
collection.add(4);
Iterator<int>* iterator = collection.createIterator();
while (iterator->hasNext())
{
std::cout << iterator->next() << std::endl;
}
delete iterator;
return 0;
}
三、使用内部类实现迭代器
具体迭代器类和具体聚合类之间存在双重关系,其中一个关系为关联关系。在具体迭代器中需要维持一个对具体聚合对象的引用,该关联关系的目的是访问存储在聚合对象中的数据,以便迭代器能够对这些数据进行遍历操作。除了使用关联关系外,为了能够让迭代器可以访问到聚合对象中的数据,还可以将迭代器类设计为聚合类的内部类。
在具体聚合类内部定义具体迭代器类。
// 具体集合
template <typename T>
class ConcreteCollection : public Collection<T>
{
private:
std::vector<T> items;
// 具体迭代器
class ConcreteIterator : public Iterator<T>
{
private:
std::vector<T> items;
std::size_t index;
public:
ConcreteIterator(const std::vector<T>& items);
bool hasNext(void) override;
T next(void) override ;
};
public:
void add(const T & item) override;
std::size_t size(void) override;
Iterator<T> * createIterator(void) override;
};
template <typename T>
void ConcreteCollection<T>::add(const T & item)
{
items.push_back(item);
}
template <typename T>
std::size_t ConcreteCollection<T>::size(void)
{
return items.size();
}
template <typename T>
Iterator<T> * ConcreteCollection<T>::createIterator(void)
{
return new ConcreteIterator(items);
}
template <typename T>
ConcreteCollection<T>::ConcreteIterator::ConcreteIterator(const std::vector<T>& items) : items(items), index(0) {}
template <typename T>
bool ConcreteCollection<T>::ConcreteIterator::hasNext(void)
{
return index < items.size();
}
template <typename T>
T ConcreteCollection<T>::ConcreteIterator::next(void)
{
if (!hasNext())
{
throw std::out_of_range("Iterator out of range");
}
return items[index++];
}
四、迭代器模式的总结
通过引入迭代器可以将数据的遍历功能从聚合对象中分离出来。聚合对象只负责存储数据,而遍历数据由迭代器来完成。
4.1、迭代器模式的优点
- 支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多种遍历方式。在迭代器模式中只需要用一个不同的迭代器来替换原有迭代器即可改变遍历算法,也可以自己定义迭代器的子类以支持新的遍历方式。
- 迭代器简化了聚合类。由于引入了迭代器,在原有的聚合对象中不需要再自行提供数据遍历等方法,这样可以简化聚合类的设计。
- 在迭代器模式中,由于引入了抽象层,增加新的聚合类和迭代器类都很方便,无须修改原有代码,满足开闭原则的要求。
4.2、迭代器模式的缺点
- 由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
- 抽象迭代器的设计难度较大,需要充分考虑到系统将来的扩展。
4.3、迭代器模式的适用场景
- 访问一个聚合对象的内容而无须暴露它的内部表示。将聚合对象的访问与内部数据的存储分离,使得访问聚合对象时无须了解其内部实现细节。
- 需要为一个聚合对象提供多种遍历方式。
- 为遍历不同的聚合结构提供一个统一的接口,在该接口的实现类中为不同的聚合结构提供不同的遍历方式,而客户端可以一致性地操作该接口。
