05. 复合数据类型
一、数组
在程序设计中,为了方便处理数据把具有相同类型的若干变量按有序形式组织起来就称为 数组。数据 就是在 内存 中 连续 的 相同类型 的变量空间。同一个数组所有的成员都是相同的数据类型,同时所有的成员在内存中是连续的。数组属于构造类型。
1.1、一维数组的使用
一维数组用于存储相同类型的数据的集合,它的定义格式如下:
数据类型 数组名[数组长度];
- 数据类型 表示数组中的所有元素的类型;
- 数组名 表示该数组类型变量的名称,命名规则遵循标识符的命名规范;
- 数组长度 定义了数组中存放的数据元素的个数,它可以是 整型常量、整型表达式 或 标识符常量;
在定义数组时,我们可以直接对数组元素进行赋值。这种赋值方式也被称为数组的 静态初始化。如果我们只给一部分元素赋值,未赋值的部分元素值为 0 。它的初始化格式如下:
数据类型 数组名[数据的长度] = {元素1, 元素2, ...};
在对全部数组元素赋初值时可以不指定数据长度。它的简化格式如下:
数据类型 数组名[] = {元素1, 元素2, ...};
声明数组后,我们可以通过 下标(或索引) 的方式给数组的数组元素赋值或者获取一维数组指定位置的元素;数组的下标是从 0 开始的,也就是说下标为 0 表示的是第一个数组元素;C++ 不允许把数组作为一个单元赋给另一个数组,除初始化以外也不允许使用花括号列表的形式赋值。
#include <iostream>
int main(void)
{
// 静态初始化:数组的初始化和赋值操作同时进行
// 数组一旦初始化完成,其长度就去确定了。
int array0[5] = {1001, 1002, 1003};
// 静态初始化的简化格式
int array1[] = {1001, 1002, 1003, 1004, 1005};
for (int element : array0)
{
std::cout << element << std::endl;
}
return 0;
}
数组是多个相同类型数据的组合,一个数组一旦声明/定义了,其长度是固定的,不能动态变化。数组的长度(方括号里的数字)必须是 常量 或者 常量表达式,不能是变量。
如果不初始化数组,数组元素和未初始化的普通变量一样,其中储存的都是垃圾值;
1.2、一维数组的数组名
一维数组的数组名是一个地址的常量,代表数组中首元素的地址。但是有两个例外:
sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节;&数组名,这里的数组名表示整个数组,取出的是整个数组的地址;
#include <iostream>
int main(void)
{
int array[3] = {1001,1002,1003};
// 一维数组的数组名是一个地址常量,代表数组中首元素的地址
std::cout << "一维数组首元素的地址:" << array << std::endl;
std::cout << "一维数组首元素的地址加1:" << (array+1) << std::endl;
std::cout << "一维数组第一个元素的地址:" << &array[0] << std::endl;
std::cout << "一维数组第二个元素的地址:" << &array[1] << std::endl;
std::cout << "一维数组整个数组的地址:" << &array << std::endl;
std::cout << "一维数组整个数组的地址加1:" << (&array+1) << std::endl;
std::cout << "一维数组的大小:" << sizeof(array) << std::endl;
return 0;
}
C++ 规定,数据一旦声明,数组名执行的地址就不可更改。因为声明数组时,编译器会自动为数组分配内存,这个地址与数组名绑定,不可更改;
1.3、二维数组的使用
数组属于引用数据类型,数组的元素也可以是引用数据类型;对于二维数组的理解,可以看成一维数组 array1 作为另一个一维数组 array2 的元素而存在;从数组底层的运行机制来看,其实没有多维数组;二维数组根本意义就是一维数组的数组,二维数组的第一维就是数据的起始地址,第二维就是基于某个数组中的某个值。
在内存中并不存在二维数组,二维数组实际的硬件存储器是连续编址的,也就是说内存中只有一维数组,即放完一行之后顺次放入第二行,和一维数组存放方式是一样的。它的定义格式如下:
数据类型 数组名[常量表达式1][常量表达式2];
二维数组和一维数组一样,也可以在声明时对其进行初始化。
我们可以将所有数据写在同一个大括号内,按照数组元素排列顺序对元素赋值。如果大括号内的数据少于数组元素的个数,则系统默认将后面未赋值的元素值设置为 0。
数据类型 数组名[常量表达式1][常量表达式2] = {元素1,元素2,元素3,...};
我们也可以分行给元素赋值,在分行赋值时,可以只对部分元素赋值。
数据类型 数组名[常量表达式1][常量表达式2] = {{元素1,元素2,元素3,...},{元素4,元素5,...},...};
在为所有元素赋初值时,可以省略行下标,但是不能省略列下标。
数据类型 数组名[][常量表达式] = {元素1,元素2,元素3,元素4,元素5,...};
我们同样可以通过 下标(索引)的方式来为二维数组的元素赋值或者获取二维数组指定位置的元素;行下标的取值范围从 0 到 n-1,列下标的取值范围从 0 到 m-1。二维数组最大的下标元素时 array[n-1][m-1]。
#include <iostream>
using namespace std;
int main(void)
{
// 二维数组静态初始化
int array0[2][3] = {{1, 2, 3},{4, 5}};
// 二维数组静态初始化简化形式
int array1[][3] = {1, 2, 3, 4, 5};
// 行*列*数据类型
cout << "二维数组大小:" << sizeof(array1) << endl;
cout << "二维数组一行大小:" << sizeof(array1[0]) << endl;
cout << "二维数组元素大小:" << sizeof(array1[0][0]) << endl;
cout << "二维数组行数:" << (sizeof(array1)/sizeof(array1[0])) << endl;
cout << "二维数组列数:" << (sizeof(array1[0])/sizeof(array1[0][0])) << endl;
for (auto & row : array1)
{
for (auto element: row)
{
cout << element << "\t";
}
cout << endl;
}
return 0;
}
如果对全部元素赋值,那么第一维的长度可以不给出;
二维数组可以看作是由一维数组嵌套而成的,如果一个数据的每个元素又是一个数组,那么它是二维数组;
定义多维数组的格式与二维数组类似,
数据类型 数组名[n1][n2]...[n3];
1.4、二维数组的数组名
二维数组的数组名也是一个地址的常量,代表数组中首元素(第一行)的地址。但是有两个例外:
sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节;&数组名,这里的数组名表示整个数组,取出的是整个数组的地址;
#include <iostream>
using namespace std;
int main(void)
{
int array[2][3] = {{1,2,3},{4,5,6}};
// 二维数组的数组名是一个地址常量,代表数组中首元素的地址
std::cout << "二维数组首元素的地址:" << array << std::endl;
std::cout << "二维数组首元素的地址加1:" << (array+1) << std::endl;
std::cout << "二维数组第一行元素的地址:" << array[0] << std::endl;
std::cout << "二维数组第二行元素的地址:" << array[1] << std::endl;
std::cout << "二维数组第一个元素的地址:" << &array[0][0] << std::endl;
std::cout << "二维数组第二个元素的地址:" << &array[0][1] << std::endl;
std::cout << "二维数组整个数组的地址:" << &array << std::endl;
std::cout << "二维数组整个数组的地址加1:" << (&array+1) << std::endl;
std::cout << "二维数组的大小:" << sizeof(array) << std::endl;
return 0;
}
1.5、多维数组
多维数组的定义和二维数组相同,只是下标更多,一般形式如下:
数据类型 数组名[常量表达式1][常量表达式2]...[常量表达式n];
由于数组元素的位置都可以同可以通过偏移量计算,因此对于一个三维数组 array[m][n][p] 来说,元素 array[a][i][k] 所在的地址是从 array[0][0][0] 算起到 \((i*n*p + j*p + k)\) 个单位的位置。
1.6、模板类
模板类 vector 是一种动态数组。我们可以在运行阶段设置 vector 对象的而长度,可在末尾附加新数据,还可以在中间插入新数据。要使用 vector 对象,必须包含头文件 vector。vector 包含在名称空间 std 中,因此我们可以使用 using 编译指令、using 声明或 std::vector。然后,模板使用不同的语法来指出它存储的数据类型,vector 类使用不同的语法来指定元素数。
vector<数据类型> 变量名(元素个数, 默认值)
#include <iostream>
#include <vector>
using namespace std;
int main(void)
{
// 定义容器,默认初始化,空的容器
vector<char> v1;
// 列表初始化,可以省略=
vector<char> v2 = {'S', 'a', 'k', 'u', 'r', 'a'};
vector<char> v3 {'K', 'i', 'n', 'o', 'm', 'o', 't', 'o'};
// 直接初始化,括号内的第一个参数是元素个数,第二个参数是默认值
vector<char> v4(5);
vector<char> v5(5, 'a');
// 修改元素
v5[2] = 'c';
// 添加元素
v5.push_back('f');
// 遍历容器
for (int i = 0; i < v5.size(); i++)
{
cout << v5[i] << endl;
}
return 0;
}
vector 类的功能比数组强大,但付出的代价是效率稍低。如果需要的是长度固定的数组,我们可以使用 C++ 11 新增的模板类 array,它也位于名称空间 std 中。与数组一样,array 对象的长度也是固定的,也使用栈(动态内存分配)。要拆功能键 array 对象,需要包含头文件 array。
array<数据类型, 元素个数> 变量名;
#include <iostream>
#include <array>
using namespace std;
int main(void)
{
// 定义容器,默认初始化,空的容器
array<char, 10> v1;
// 列表初始化,可以省略=
array<char, 10> v2 = {'S', 'a', 'k', 'u', 'r', 'a'};
array<char, 10> v3 {'K', 'i', 'n', 'o', 'm', 'o', 't', 'o'};
// 修改元素
v2[0] = 's';
// 遍历容器
for (int i = 0; i < v2.size(); i++)
{
cout << v2[i] << endl;
}
return 0;
}
二、字符串
字符串是存储在内存的连续字节中的一系列字符。C++ 处理字符串的方式有两种。第一种来自 C 语言的 C-风格字符串。另一种是基于 string 类库的方法。
2.1、C-风格字符串
存储在连续字节中的一系列字符意味着可以将字符串存储在 char 数组中,其中每个字符都位于自己的数组元素中。C-风格字符串具有一种特殊的性质:以空字符结尾,空字符被写作 \0,其 ASCII 码为 0,用来标记字符串的结尾。
我们可以使用引号括起来的字符串常量来为字符数组赋值。用引号括起来的字符串隐式地包含结尾地空字符,因此不用显示地包括它。当我们使用字符数组存放字符串字面量时,应该确保数组足够大,能够存储字符串中所有字符(包含空字符)。
在 C++ 中允许拼接字符串字谜那只,即将两个用引号括起来的字符串合并为一个。事实上,任何两个由空白(空格、制表符和换行符)分割的字符串常量都将自动拼接成一个。拼接时,不会在被连接的字符串之间添加空格,第二个字符紧跟在第一个字符串的最后一个字符(不考虑 '\0')后迷奸案。第一个字符串中的 '\0' 字符将被第一个字符串的第一个字符取代。
如果我们想要获取字符串的长度时,我们应该使用标准 C 语言库函数 strlen() 来确定字符串的长度。它位于标准头文件 cstring 中。如果我们使用 sizeof 运算符,那么我们获取的是整个数组的大小。但使用 strlen() 函数可见的字符长度(即不包含空字符 '\0')。
#include <iostream>
#include <cstring>
using namespace std;
int main(void)
{
char str[30] = "Hello, Sakura!";
cout << str << endl;
cout << "sizeof(str): " << sizeof(str) << endl;
cout << "strlen(str): " << strlen(str) << endl;
cout << "Hello, " "world!" << endl;
return 0;
}
我们可以使用 cin 向程序中输入内容,但是 cin 使用空白(空格、制表符和换行符)来确定字符串的结束位置。这意味 cin 在获取字符数组输入时只能读取一个单词。读此该单词后,cin 将该字符串放到数组中,并自动在结尾添加空字符。
#include <iostream>
using namespace std;
int main(void)
{
char str[30] = {0};
cout << "Enter a string: ";
cin >> str;
cout << "You entered: " << str << endl;
return 0;
}
此时,我们可以使用 iostream 中的类(cin)提供一些面向行的类成员函数:getline() 和 get()。这两个函数都读取一行输入,直到到达换行符。然而,随后 getline() 将丢弃换行符,而 get() 将换行符保留在输入序列中。
getline() 函数读取整行,它使用通过回车键换行符来确定输入结尾。该函数有两个参数。第一个参数时用来存储输入行的数组的名称,第二个参数时要读取的字符数。如果这个参数为 30,则函数最多输入 29 个字符,余下的空间用来存储自动在结尾处添加的空字符。getline() 成员函数在读取指定数目的字符或遇到换行符时停止读取,但不保存换行符。
cin 类有另一个名为 get() 的成员函数,该函数有几种变体。其中一种变体的工作方式与 getline() 类似,它们接收的参数相同,解释参数的方式也相同,并且都读取到行尾。但 get() 将换行符保留在输入队列中。
cin.get(firstname, 30);
cin.get(lastname, 30);
由于第一次调用后,换行符将留在输入队列中,因此第二次调用时看到的第一个字符便是换行符。因此,get() 认为已经达到行尾,而没有发现任何可读取的内容,导致 get() 将不能跨越该换行符。但 cin 类提供了 get() 的另一种变体,使用不带任何参数的 cin.get() 可读取下一个字符(即使时换行符)。
#include <iostream>
using namespace std;
int main(void)
{
char firstname[30] = {0};
char lastname[30] = {0};
cout << "Enter firstsname: ";
cin.get(firstname, sizeof(firstname)).get();
cout << "Enter lastname: ";
cin.get(lastname, sizeof(lastname));
cout << "Your name is: " << firstname << " " << lastname << endl;
return 0;
}
2.2、string类
ISO/ANSI C++ 98 标准通过添加 string 类扩展了 C++ 库,因此现在可以 string 类型的变量而不是字符数组来存储字符串。要使用 string 类,必须在程序中包含头文件 string。string 类位于名称空间 std 中,因此你必须提供一个 using 编译指令,或使用 std::string 来引用它。string 类定义隐藏了字符串的数组性质,让你能够处理变量那样处理字符串。
#include <iostream>
#include <string>
using namespace std;
int main(void)
{
// 定义容器,默认初始化,空的容器
string s1;
// 列表初始化,可以省略=
string s2 = {'S', 'a', 'k', 'u', 'r', 'a'};
string s3 {'K', 'i', 'n', 'o', 'm', 'o', 't', 'o'};
// 直接初始化,括号内的第一个参数是元素个数,第二个参数是默认值
string s4("Hello world!");
string s5(5, 'a');
string s6 = "Hello, Sakura!";
// 修改元素
s5[2] = 'c';
// 添加元素
s5.push_back('f');
cout << s5 << endl;
cout << s5.size() << endl;
return 0;
}
我们可以对字符串符串使用 “+” 来相加,这是算数运算符 “+” 的重载,含义是 “字符串拼接”。两个 string 对象,可以直接进行字符串相加,结果是将两个字符串拼接在一起,得到一个新的 string 对象返回。一个 string 对象和一个字符串字面量常量,也可以进行字符串相加,同样是得到一个拼接后的 string 对象返回。但是,两个字符串字面量是不能相加的。
#include <iostream>
using namespace std;
int main(void)
{
// 定义容器,默认初始化,空的容器
string firstname = "Sakura";
string lastname = "Kinomoto";
string name = firstname + " " + lastname;
cout << name << endl;
return 0;
}
string 类还提供几种用来做字符串比较的运算符,== 和 != 用来判断两个字符串是否完全一样,而 <、<=、>、>= 则用来比较两个字符串的大小。这些都是关系运算符的重载。
字符串比较的规则如下:
- 如果两个字符串长度相同,每个位置包含的字符也都相同,那么 “两者” 相等,否则 “不相等”。
- 如果两个字符串长度不同,而较短的字符串都跟较长字符串对应位置字符相同,那么较短字符串 “小于” 较长字符串。
- 如果两个字符在某一位置上开始不同,那么就比较这两个字符的 ASCII 码,比较结果就代表两个字符串的大小关系。
#include <iostream>
using namespace std;
int main(void)
{
// 定义容器,默认初始化,空的容器
string str1 = "Sakura";
string str2 = "Sakura Kinomoto";
string str3 = "Sakura";
cout << ((str1 <= str2) ? true : false) << endl;
cout << ((str1 == str3) ? true : false) << endl;
return 0;
}
2.3、原始字面量
在 C++ 11 中添加原始字符串的字面量,定义方式如下:
R"XXX(原始字符串)XXX"
其中,() 两边的字符串可以省略,如果不省略,则括号两边的字符串必须相等。原始字面量 R 可以直接表示字符串的实际含义,而不需要额外的对字符串做转义或连接操作。
#include <iostream>
using namespace std;
int main(void)
{
string path = R"(E:\Software\C++\test.cpp)";
cout << path << endl;
return 0;
}
三、结构体
“结构体” 是一种构造类型,它是由若干 “成员” 组成的,其中的每一个成员可以是基本数据类型也可以是一个构造类型。既然构造体是一种新的类型,就需要先对其进行构造,这里称这种操作为声明一个结构体。
3.1、结构体变量的声明
我们需要使用 struct 关键字来声明结构体,其一般格式如下:
struct 结构体名
{
数据类型 成员1;
数据类型 成员2;
...
数据类型 成员n;
};
其中,struct 关键字表示声明结构体,其后的结构体名表示该结构体的类型名,大括号中的变量构成结构体的成员,也就是一般形式的成员列表,成员列表可以是任意一种 C 的数据类型,也可以是其它构造类型。右花括号后面的分号是声明所必须的,表示结构体声明的结束。
3.2、结构体变量的定义
声明一个结构体表示的是创建一种新的类型名,需要用新的类型名在定义一个变量。不同结构体变量的成员是相互独立的,互补影响,一个结构体变量的更改,不会影响到另一个结构体。定义的方式有 3 种:
【1】、声明结构体类型,再定义变量
struct 结构体类型名 结构体变量;
【2】、在声明结构体时定义变量
struct 结构体名
{
数据类型 成员1;
数据类型 成员2;
...
数据类型 成员n;
}变量名1,变量名2,...,变量名n;
定义的变量不是只能有一个,可以定义多个变量;
【3】、直接定义结构体类型变量
如果我们只需要确定个数的结构体变量,后面不需要再使用结构体数据类型定义变量,我们可以在定义时不给出结构体名,这种结构体称为 匿名结构体。
struct
{
数据类型 成员1;
数据类型 成员2;
...
数据类型 成员n;
}变量名1,变量名2,...,变量名n;
在 C++ 中允许在声明结构体变量时省略关键字 struct。
struct 结构体名 变量名;
结构体名 变量名;
3.3、结构体变量的初始化
我们可以在结构体类的声明,变量声明,赋初值同时进行。在初始化时,初始化的值放在大括号中,多个值使用逗号 “,” 分隔,并且每一个数据要与结构体的成员列表一一对应。
struct 结构体名
{
数据类型 成员1;
数据类型 成员2;
...
数据类型 成员n;
}变量名={值1,值2,...,值n};
结构体类型与其它基本类型一样,也可以在定义结构体变量时指定初始值。
struct 结构体名 变量名 = {值1,值2,...,值n};
3.4、结构体变量的引用
在定义结构体变量后,我们可以使用成员运算符(.)来访问各个成员。
结构体变量名.成员名
#include <iostream>
using namespace std;
struct Date{
int year;
int month;
int day;
};
struct Person{
char name[20];
int age;
char gender[10];
struct Date birthday;
}person = {"Sakura",10,"女",{1987,4,1}};
int main(void)
{
cout<<"name: "<<person.name<<endl;
cout<<"age: "<<person.age<<endl;
cout<<"gender: "<<person.gender<<endl;
cout<<"birthday:"<<person.birthday.year<<"-"<<person.birthday.month<<"-"<<person.birthday.day<<endl;
return 0;
}
3.5、结构体的自引用
在结构体中包含一个类型为该结构体本身的成员。
struct Node
{
int data;
struct Node * next;
};
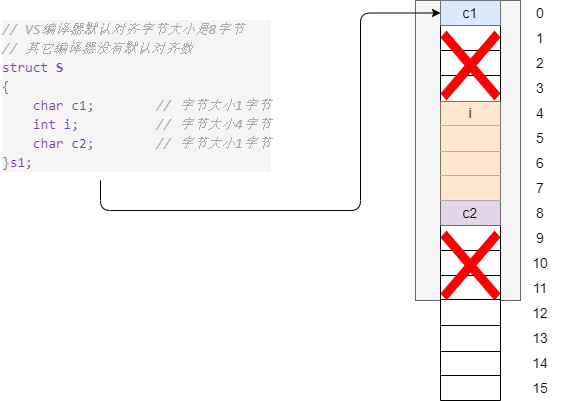
3.6、结构体内存对齐
结构体的对齐规则:
- 第一个成员在结构体变量偏移量为 0 的地址。
- 其它成员变量要对齐到某个整数(对齐数)的整数倍的地址处。
- 对齐数 = 编译器默认的一个对齐数 与 该成员大小 的 较小值
- 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
- 如果嵌套了结构体的情况。嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
#include <iostream>
using namespace std;
// VS编译器默认对齐字节大小是8字节
// 其它编译器没有默认对齐数
// #pragma pack(1) // 修改默认对齐数
struct S
{
char c1; // 字节大小1字节
int i; // 字节大小4字节
char c2; // 字节大小1字节
}s1;
int main(void)
{
cout << sizeof(s1) << endl;
// offsetof宏可以返回一个成员在结构体中的偏移量
cout << offsetof(struct S,c1) << endl;
cout << offsetof(struct S,i) << endl;
cout << offsetof(struct S,c2) << endl;
return 0;
}
#include <iostream>
using namespace std;
struct S1
{
double d; // 字节大小8字节
char c; // 字节大小1字节
int i; // 字节大小4字节
};
struct S2
{
char c; // 字节大小1字节
struct S1 s1;
double d; // 字节大小1字节
}s2;
int main(void)
{
cout << sizeof(s2) << endl;
return 0;
}

为什么要存在结构体内存对齐呢?大部分的参考资料是如下解释的:
①、平台原因
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常;
②、性能原因
数据结构(尤其是栈)应该尽可能在自然边界对齐。原因在于,为了访问未对其的内存,处理器需要做两次内存访问;而对齐的内存仅需要一次访问。
总体上来说,结构体的内存对齐是拿空间获取时间的做法;
我们在设计结构体时,让占用空间小的成员尽量集中在一起,这样既可以满足内存对齐,又可以节省空间;
四、共同体
联合体也称为共用体,它使几种不同类型的变量存放到同一段内存单元中。所以共用体在同一时刻只能有一个值,它属于某一个数据成员。由于所有成员都位于同一块内存,因此共同体的大小至少是最大成员的大小。
结构体与共用体之间的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员值会影响其余所有成员。
共用体类型的变量具有以下特点:
- 同一个内存段可以用来存放几种不同类型的成员,但是每一次只能存放其中一种,而不是同时存放所有的类型。也就是说,在共用体种,只有一个成员起作用,其它成员不起作用。
- 共用体变量中起作用的成员是最后一次存放的成员,在存入一个新的成员后原有的成员就失去作用。
- 共用体变量的地址和它的各成员的地址是一样的。
4.1、共用体的声明
定义共用体变量的一般形式如下:
union 联合体名
{
数据类型 成员1;
数据类型 成员2;
...
数据类型 成员n;
};
其中,uinon 关键字表示声明联合体,其后的联合体名表示该联合体的类型名,大括号中的变量构成联合体的成员,也就是一般形式的成员列表;
4.2、共用体变量的定义
声明一个联合体体表示的是创建一种新的类型名,需要用新的类型名在定义一个变量。定义的方式有 3 种:
【1】、声明联合体类型,再定义变量
union 联合体类型名 结构体变量;
【2】、在声明联合体时定义变量
union 联合体名
{
数据类型 成员1;
数据类型 成员2;
...
数据类型 成员n;
}变量名1,变量名2,...,变量名n;
定义的变量不是只能有一个,可以定义多个变量;
【3】、直接定义联合体类型变量
如果我们只需要确定个数的联合体变量,后面不需要再使用联合体数据类型定义变量,我们可以在定义时不给出联合体名。
union
{
数据类型 成员1;
数据类型 成员2;
...
数据类型 成员n;
}变量名1,变量名2,...,变量名n;
4.3、共用体变量的初始化
在定义共同体变量时,可以同时对共用体变量进行初始化操作。初始化的值放在一对大括号中。对共同体变量进行初始化时,只需要一个初始化值就足够了,其类型需要和共用体的第一个成员的类型一致。如果共用体的第一个成员是一个结构体类型,则初始化值可以包含多个用于初始化该结构体的表达式。
4.4、共用体变量的引用
定义联合体之后,就可以引用其中的成员数据进行使用。引用的一般形式为:
联合体变量.成员名
#include <iostream>
using namespace std;
int main(void)
{
union data
{
int n;
char ch;
short s;
};
union data a = {100};
cout << sizeof(a) << endl;
cout << a.n << " " << a.ch << " " << a.s << endl;
a.ch = 'a';
cout << a.n << " " << a.ch << " " << a.s << endl;
a.s = 50;
cout << a.n << " " << a.ch << " " << a.s << endl;
return 0;
}
五、枚举
枚举是 C++ 中的一种数据类型,它可以让数据更简洁,更易读,对于只有几个有限的特定类型,可以使用枚举。枚举是一组常量的集合,包含一组有限的特定的数据。
5.1、枚举类型的定义
在 C++ 中,我们可以使用 enum 关键字声明枚举类型变量。一个枚举变量包含一组相关的标识符,其中每个标识符都对应一个整数值,称为 枚举常量。它的定义格式如下:
enum 枚举类型名
{
标识符1[=值1],
标识符2[=值2],
标识符3[=值3],
...
标识符n[=值n]
};
在定义枚举类型的变量时,可以为某个特定的标识符指定对应的整数值,紧随其后的标识符对应的值依次加 1。如果没有为枚举变量显示的指定整数值,默认从 0 开始,依次递增。如果为枚举变量中间的某个标识符指定对应的值,那么它之前的标识符对应的整数值从 0 开始,它后面的标识符对应的整数值从该值开始依次加 1。
5.2、枚举变量的定义
【1】、声明枚举类型,再定义变量
enum 枚举类型名 变量名;
【2】、在声明枚举类型时定义变量
enum 枚举类型名
{
标识符1[=值1],
标识符2[=值2],
标识符3[=值3],
...
标识符n[=值n]
}变量名1,变量名2,...,变量名n;
定义的变量不是只能有一个,可以定义多个变量;
【3】、直接定义枚举类型变量
如果我们只需要确定个数的枚举变量,后面不需要再使用枚举类型定义变量,我们可以在定义时不给出枚举类型名。
enum
{
标识符1[=值1],
标识符2[=值2],
标识符3[=值3],
...
标识符n[=值n]
}变量名1,变量名2,...,变量名n;
5.3、枚举变量的赋值
【1】、先声明变量再对变量赋值
enum 枚举类型名 变量名;
变量名 = 枚举常量;
【2】、声明变量的同时赋初值
enum 枚举类型名 变量名 = 枚举常量;
【3】、定义类型的同时声明变量,然后对变量赋值
enum 枚举类型名
{
标识符1[=值1],
标识符2[=值2],
标识符3[=值3],
...
标识符n[=值n]
}变量名;
变量名 = 枚举常量;
【4】、类型定义,变量声明,赋初值同时进行
enum 枚举类型名
{
标识符1[=值1],
标识符2[=值2],
标识符3[=值3],
...
标识符n[=值n]
}变量名 = 枚举常量;
#include <iostream>
using namespace std;
int main(void)
{
enum WEEK
{
MONDAY = 1,
THESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY,
SUNDAY
};
int day = 0;
cout << "请输入一个星期:";
cin >> day;
switch(day)
{
case MONDAY:
cout << "你输入的是星期一\t" << MONDAY << endl;
break;
case THESDAY:
cout << "你输入的是星期二\t" << THESDAY << endl;
break;
case WEDNESDAY:
cout << "你输入的是星期三\t" << WEDNESDAY << endl;
break;
case THURSDAY:
cout << "你输入的是星期四\t" << THURSDAY << endl;
break;
case FRIDAY:
cout << "你输入的是星期五\t" << FRIDAY << endl;
break;
case SATURDAY:
cout << "你输入的是星期六\t" << SATURDAY << endl;
break;
case SUNDAY:
cout << "你输入的是星期七\t" << SUNDAY << endl;
break;
default:
cout << "你输入有误" << endl;
break;
}
return 0;
}
枚举变量的取值范围是固定的,只可以再枚举常量中选择;
对枚举型的变量赋整数值时,需要进行类型转换 ,即 变量名 = (enum 枚举类型名)整数值。
六、指针
内存区的每一个字节都有一个编号,这就是 “地址”。如果在程序中定义了一个变量,在对程序进行编译或运行时,系统就会给这个变量分配内存单元,并确定它的内存地址(编号)。通过访问这个地址,就可以找到所需要的变量,这个变量的地址称为该变量的 指针。指针的实质就是内存 “地址”。指针就是地址,地址就是指针。
变量的地址是变量和指针两者之间连接的纽带,如果一个变量包含了另一个变量的地址,则可以理解为第一个变量指向第二个变量。所谓的指向就是通过地址实现的。因为指针变量是指向一个变量的地址,所以将一个变量的地址赋给这个指针变量后,这个指针变量就指向了该变量。
在程序代码中是通过变量名对内存空间单元进行存取操作的,但是代码经过编译后已经将变量名转换为该变量在内存中的存放地址,对变量值的存储都是通过地址进行的。
我们可以使用 &运算符 来获取变量的地址,使用 *运算符 来获取指针类型所指向的值。
由于通过地址能访问指定的内存存储单元,可以说地址 “指向” 该内存单元。地址可以形象地称为指针,意思是通过指针能找到内存单元。一个变量的地址称为该变量的指针。如果有一个专门用来存放另一个变量的地址,它就是 指针变量。在 C++ 中,有专门存放内存单元地址的变量类型,即 指针类型。
6.1、指针变量的定义
指针也是一种数据类型,指针变量也是一种变量。所有的指针类型的变量存储的都是内存地址。指针变量指向谁,就把谁的地址赋值给指针变量。“*” 操作符操作的是指针变量指向的内存空间。
数据类型 * 指针变量名;
其中,“*” 表示该变量是一个指针变量,变量名即为定义的指针变量名,数据类型表示本指针变量所指向的变量的数据类型;
int * p;
指针类型决定了指针在被解引用的时候访问几个字节;
6.2、指针变量的赋值
给指针变量所赋的值只能是变量的地址值。在 C++ 中,提供了地址运算符 “&” 来表示变量的地址。
指针变量名 = &变量名;
我们可以在定义指针变量的同时进行赋值:
int a = 10;
int* p = &a;
同样,我们也可以先定义指针变量,再进行赋值:
int a = 10;
int *p;
p = &a;
6.3、指针变量的引用
引用指针变量是对变量进行间接访问的一种形式,对指针变量的引用形式如下:
*指针变量名;
其含义是引用指针变量所指向的值;
#include <iostream>
using namespace std;
int main(void)
{
int a = 10;
// int *代表是一种数据类型,int*指针类型,p才是变量名
// 定义了一个指针类型的变量,可以指向一个int类型变量的地址
int * p;
// 将a的地址赋值给变量p,p也是一个变量,值是一个内存地址编号
p = &a;
cout << "a的值:" << a << endl;
cout << "a的地址:" << &a << endl;
cout << "p中保存的地址值:" << p << endl;
// p指向了a的地址,*p就是a的值
cout << "p指向的值为:" << *p << endl;
// 通过指针间接修改变量的值
*p = 100;
cout << "a修改后的值:" << a << endl;
return 0;
}
& 可以取得一个变量在内存中的地址。但是,不能取寄存器变量,因为寄存器变量不在内存里,而在 CPU 里面,所以是没有地址的。
6.4、指针的大小
使用 sizeof() 测量指针的大小,得到的总是:4 或 8。sizeof() 测的是指针变量指向存储地址的大小。在 32位 平台,所有的指针(地址)都是 32位(4字节);在 64位 平台,所有的指针(地址)都是 64位(8字节);
#include <iostream>
using namespace std;
int main(void)
{
cout << "sizeof(short *): " << sizeof(short *) << endl;;
cout << "sizeof(int *): " << sizeof(int *) << endl;
cout << "sizeof(long *): " << sizeof(long *) << endl;
cout << "sizeof(long long*): " << sizeof(long long *) << endl;
cout << "sizeof(float *): " << sizeof(float *) << endl;
cout << "sizeof(double *): " << sizeof(double *) << endl;
cout << "sizeof(long double *): " << sizeof(long double *) << endl;
return 0;
}
在 32 位的机器上,地址是 32 个 0 或 1 组成的二进制序列,那地址就得用 4 个字节的空间来存储,所以一个指针变量的大小就应该是 4 个字节;
那如果在 64 位机器上,如果由 64 个地址线,那一个指针变量的大小应该是 8 个字节,才能存放一个地址;
6.5、野指针和空指针
指针变量也是变量,是变量就可以任意赋值,不要越界即可(32位 为 4字节,64位 为 8字节),但是,任意数值赋值给指针变量没有意义,因为这样的指针就成了野指针,此指针指向的区域是未知(操作系统不允许操作此指针指向的内存区域)。所以,野指针不会直接引发错误,操作野指针指向的内存区域才会出问题。
#include <iostream>
using namespace std;
int main(void)
{
// 野指针 --> 指针变量指向一个未知的空间
// 程序中允许出现野指针
int * p;
*p = 100;
// 操作野指针对应的内存空间可能报错
// 操作系统将地址编号0-255作为系统占用,不允许访问操作
cout << *p << endl;
return 0;
}
但是,野指针和有效指针变量保存的都是数值,为了标志此指针变量没有指向任何变量(空闲可用),C++ 中,可以把 NULL 或 nullptr 赋值给此指针,这样就标志此指针为空指针,没有任何指针。
int * p = NULL;
int * p = nullptr;
int * p = 0;
NULL 是一个值为 0 的宏常量:
#define NULL ((void *)0)
操作空指针对应的内存空间一定报错;
6.6、指针的运算
6.6.1、指针加减整数
指针式一个用数值表示的地址,可以对指针进行算数运算:+、-。指针的算数运算不同于普通变量的算数运算,指针会按照它所指向的数据类型字节长度进行增或减。
我们可以使用 + 运算符把指针与整数相加,或整数与指针相加。无论哪种情况,整数都会和指针所指向的类型的大小(以字节为单位)相乘,然后把结果与初始地址相加。如果相加的结果超出了初始指针指向的数组范围,计算结果则是未定义的。除非正好超过数组末尾第一个位置,C++ 保证该指针有效。
#include <iostream>
using namespace std;
int main(void)
{
int array[10] = {1,2,3,4,5,6,7,8,9};
int * ptr = array;
int i = 0;
for(i = 0; i < sizeof(array)/sizeof(array[0]); i++)
{
cout << *(ptr + i) << " ";
}
cout << endl;
return 0;
}
我们还可以使用 - 运算符从一个指针减去一个整数。指针必须是第 1 个运算对象,整数是第 2 个运算对象。该整数将乘以指针指向类型的大小(以字节为单位),然后用初始地址减去乘积。如果相减的结果超出了初始指针所指向数组的范围,计算结果则是未定义的。除非正好超过数组末尾第一个位置,C++ 保证该指针有效。
#include <iostream>
using namespace std;
int main(void)
{
int array[10] = {1,2,3,4,5,6,7,8,9};
int * ptr = &array[9];
int i = 0;
for(i = 0; i < sizeof(array)/sizeof(array[0]); i++)
{
cout << *(ptr - i) << " ";
}
cout << endl;
return 0;
}
在 C语言 中,指针加(减) 1 指的是增加(减少)一个存储单元;
6.6.2、指针自增自减
递增指向数组元素的指针可以让该指针移动至数组的下一个元素。
#include <iostream>
using namespace std;
int main(void)
{
int array[10] = {1,2,3,4,5,6,7,8,9};
int * ptr = array;
int i = 0;
for(i = 0; i < sizeof(array)/sizeof(array[0]); i++)
{
cout << *ptr++ << " ";
}
cout << endl;
return 0;
}
递减指向数组元素的指针可以让该指针移动至数组的前一个元素。
#include <iostream>
using namespace std;
int main(void)
{
int array[10] = {1,2,3,4,5,6,7,8,9};
int * ptr = &array[9];
int i = 0;
for(i = 0; i < sizeof(array)/sizeof(array[0]); i++)
{
cout << *ptr-- << " ";
}
cout << endl;
return 0;
}
前缀或后缀的自增和递减运算符都可以使用;
6.6.3、指针的减法
指针的减法就是内存地址的偏移量,即 内存地址的差值/sizeof(数据类型),得到的是指针和指针之间的元素的个数。通常,求差的两个指针分别指向同一个数组的不同元素,通过计算求得两元素之间的距离。差值的单位与数组类型的单位相同。
只要两个指针都指向相同的数组(或者其中一个指针指向数组后面的第 1 个地址),C++ 保证相减运算有效。如果指向两个不同数组的指针进行求差运算可能会得出一个值,或者导致运行时错位。
#include <iostream>
using namespace std;
int main(void)
{
int array[] = {1,2,3,4,5,6,7,8,9};
int * p = &array[3];
int step = p-array;
cout << step << endl;
cout << p << endl;
cout << p-2 << endl;
cout << &array[1] << endl;
cout << *(p-2) << endl;
return 0;
}
如果两个指针变量指向的是同一个连续空间的不同存储单元,则这两个指针变量才可以相减,表示两个变量相隔的元素个数。
6.6.4、指针的比较
指针可以用关系运算符进行比较,前提是两个指针都指向相同类型的对象。如果 p1 和 p2 指向两个变量,比如指向同一个数组中的不同元素,则可对 p1 和 p2 进行大小比较。
#include <iostream>
using namespace std;
int main(void)
{
int array[] = {1,2,3,4,5,6,7,8,9};
int * p = array;
if(p == &array[0])
{
cout << p << endl;
}
return 0;
}
C++ 允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许与指向第一个元素之前的那个内存位置的指针进行比较;
6.7、万能指针
void * 指针可以指向任意变量的内存空间,它不指向任何的数据类型,在通过万用指针修改变量的值时,需要找到变量对应的指针的类型。这是因为 void * 是无具体类型的指针,它不能进行解引用操作,也不能加减一个整数。
#include <iostream>
using namespace std;
int main(void)
{
int a = 10;
char ch = 'a';
// 万能指针可以接收任意类型变量的内存地址
void * p;
cout << "万能指针在内存占的字节大小:" << sizeof(void *) << endl;
// 在通过万用指针修改变量的值时,需要找到变量对应的指针的类型
p = &a;
*(int *)p = 100;
cout << a << endl;
cout << *(int *)p << endl;
cout << p << endl << endl;
p = &ch;
*(char *)p = 'c';
cout << ch << endl;
cout << *(char *)p << endl;
cout << p << endl;
return 0;
}
6.8、const修饰的指针变量
6.8.1、指向常量的指针
指针指向的是一个常量,所以只能访问数据,不能通过指针对数据进行修改。不过指针本身是变量,可以指向另外的数据类型。这是 const 应该加在类型前面。
const 数据类型 变量名 = 值;
const 数据类型 * 指针变量名 = &变量名;
#include <iostream>
using namespace std;
int main(void)
{
const int a = 100, b = 200;
int c = 300;
// 指向常量的指针
const int * pc = &a;
cout << *pc << endl;
// 可以修改指针变量存储的地址值
pc = &b;
cout << *pc << endl;
// 也可以指向变量
pc = &c;
cout << *pc << endl;
// 但是不能修改指针指向内存空间的值
// *pc = 400;
return 0;
}
6.8.2、指针常量
指针本身是一个数据类型,所以也可以区分变量和常量。如果指针本身是一个常量,就意味着它保存的地址不能更改,也就是它永远指向同一个对象。而数据对象的内容是可以通过指针改变的。这种指针一般叫作 “指针常量”。指针常量在定义的售后,需要在星号 * 后,标识符前加上 const。
数据类型 变量名 = 值;
数据类型 * const 指针变量名 = &变量名;
#include <iostream>
using namespace std;
int main(void)
{
int a = 100, b = 200;
// const修饰指针变量
int * const cp = &a;
cout << *cp << endl;
// 保存的地址不能更改
// cp = &b;
// 但可以修改指针指向内存空间的值
*cp = 300;
cout << *cp << endl;
return 0;
}
6.8.3、指向常量的指针常量
const 同时修饰指针类型和指针变量,表示我们既不可以修改指针指向内存空间的值,也可以修改指针变量存储的地址值;
#include <iostream>
using namespace std;
int main(void)
{
int a = 10;
int b = 20;
// const 修饰指针类型,修饰指针变量
const int * const ccp = &a;
// 不可以修改指针指向内存空间的值
// *ccp = a;
// 不可以修改指针变量存储的地址值
//ccp = &b;
return 0;
}
6.9、多级指针
一个指针变量既可以 整型变量、浮点型变量 和 字符类型变量,当然也可以指向指针类型变量。当指针变量用于指向指针类型变量时,则称之为 指向指针的指针变量,也就是 多级指针。指向指针的指针变量定义如下:
数据类型 **指针变量名;
其含义为定义一个指针变量,它指向另一个指针变量,该变量又指向一个基本数据类型。
#include <iostream>
using namespace std;
int main(void)
{
int a = 10;
int b = 20;
int * p = &a;
// pp指二级指针变量的值
// *pp指一级指针的值
// **pp指变量的值
int **pp = &p;
**pp = 100;
cout << *p << endl;
cout << a << endl;
*pp = &b; // 相当于p = &b;
cout << *p << endl;
return 0;
}
整型变量 a 的地址是 &a,将其值传递给指针变量 p,则 p 指向 a;同时,将 p 的地址 &p 传递给 pp,则 pp 指向 p。这里的 pp 就是指向指针变量的指针,即指针的指针。int * 是说明 pp 指向的对象是 int * 类型;

二级指针是用来存放一级指针变量的地址;
七、引用
在 C++ 中,我们可以为数据对象另外起一个名字,叫作 “引用”。在声明时,我们可以在变量名前加上 "&" 符号,表示它是另一个变量的引用。引用必须初始化。
数据类型 变量名 = 值;
数据类型 & 引用名 = 变量名;
引用就是一个 “别名”,它本身不是数据对象,所以本身不会存储数据,而是和初始值 “绑定” 在一起,绑定之后就不能在绑定别的对象了。C++ 编译器在编译工程中使用 常指针 作为引用的内部实现,因此引用所占用的空间大小与指针相同。定义了引用之后,对引用做的所有操作,就像直接操作绑定的原始变量一样。所以,引用也是一种间接访问数据对象的方式。
#include <iostream>
using namespace std;
int main(void)
{
int a = 10, b = 20;
int & ref = a;
cout << "ref: " << ref << endl;
cout << "ref的地址: " << &ref << endl;
cout << "a的地址: " << &a << endl;
ref = b;
cout << "ref: " << ref << endl;
cout << "a: " << a << endl;
cout << "ref的地址: " << &ref << endl;
cout << "a的地址: " << &a << endl;
cout << "b的地址: " << &b << endl;
// 引用的引用
int & rref = ref;
cout << "rref: " << rref << endl;
// 对常量的引用
const int c = 100;
const int & cref = c;
cout << "cref: " << cref << endl;
// 对指针的引用
int *p = &b;
int * & pref = p;
cout << "pref: " << *pref << endl;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号