笔趣阁分布式flask爬虫
通过flask+mongo+requests实现一个主从分布式爬虫
一:分布式爬虫介绍
1、对等分布式:每台机器上的的爬虫都一致
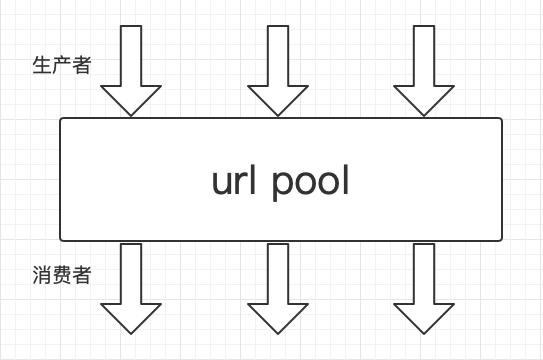
- 无论那台机器掉线,都不会影响其他机器的爬虫
- 可以根据需求动态的增/删计算机和爬虫的数量
试用场景:非递进关系网站
2、主从分布式:不同的机器类型做不同的动作,例如主机器只做详情url的提取,从机器只做详情页的解析

- 分工明确,有效的控制资源消耗
试用场景:递进关系的网站
二:本程序实现构想
读书网站为目录页+书本章节页+内容页,因此主从的分布式架构比较适合

整体架构如图所示:

本例中的数据存储通过flask来转换进行,从机不需要安装mongo,只需要能访问主机开启的flask就行
3、实现(以目录页爬虫为例)
爬虫的代码比较简单就不放了。有兴趣的可以去github上找
关键说说怎么通过了flask将所有的访问的数据进行存储。
首先在主机上开启flask的服务,服务中有:插入任务、插入数据等接口
@app.route('/insert_task', methods=['POST'])
def insert_task():
"""
当存在url时不更新
@return:
"""
rj = request.get_json()
coll_name = rj['coll_name']
data = rj['data']
if not db[coll_name].find_one({'url': data['url']}):
db[coll_name].insert_one(data)
return 'OK'
在每个从机中需要插入数据的时候,进行一层调用,原本直接存储的数据,通过flask来进行指定存储。
for item in items:
novel_url = item.xpath('./li[@class="two"]/a/@href')[0]
name = item.xpath('./li[@class="two"]/a/text()')[0][:-4]
catalog = {
"name": name,
"url": novel_url
}
# 数据插入点,调用的是下面函数
insert_task("catalog_task", catalog)
def insert_task(coll_name, task, logger=None):
"""
通过控制不同的coll_name实现对不同集合的写入
@param coll_name:
@param task:
@param logger:
@return:
"""
while True:
try:
url = '{}/insert_task'.format(HOST)
data = {
'coll_name': coll_name,
'data': task
}
res = requests.post(url, json=data)
if res.status_code != 200:
raise Exception('status_code:{}'.format(res.status_code))
break
except Exception as e:
trace = traceback.format_exc()
info = 'error:{},trace:{}'.format(str(e), trace)
logger.error(info)
time.sleep(5)
4、效果展示


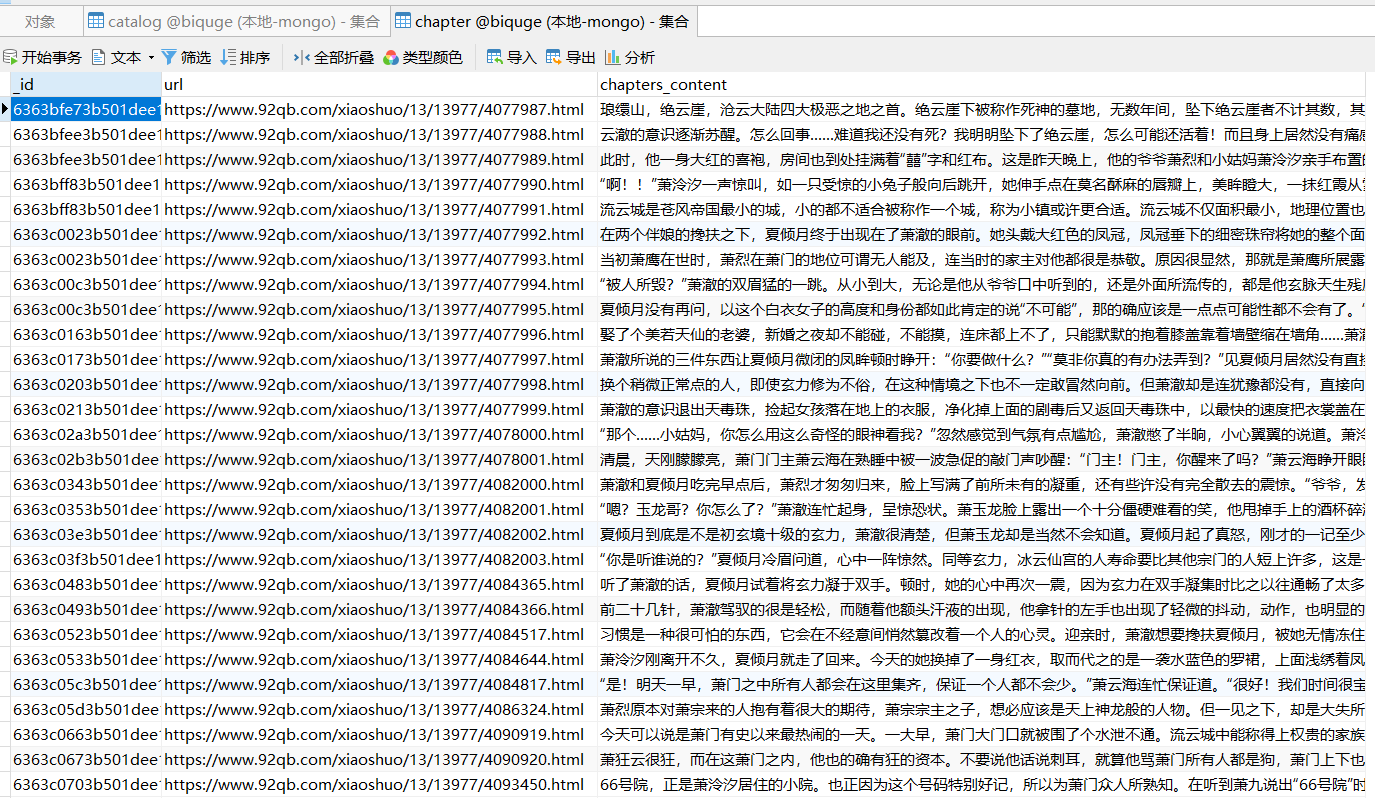
catalog为目录集合,catalog_task,为目录任务集合,novels为章节信息集合,novels_task为章节信息任务集合,chapter为章节内容集合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号