python 简单字体解密
前言
这篇文章主要是讲解简单的字体解密,由于信息敏感,就不透露是哪个网站了
分析过程
①查看情况,可以看见字体是加密过的

②查看网页源代码


如果在网页中看的了这样一些内容,那么就需要注意,这个信息我们后面可能需要用到,我用红色框框框住的是一些比较重要的信息,绿色箭头指向的是我们所需要使用的内容,结尾不需要)
③解码
因为是base64编码的,那么我们需要对应的解码,对谁解码呢,绿色箭头所指向的那部分内容。
④保存成woff文件
就是正常的二进制格式保存,怎么保存图片的就怎么保存它,只不过后缀名要改成.woff。你放心,PyCharm应该看不了woff文件
⑤查看woff文件
PyCharm看不了woff文件,我们只能想办法,使用FontCreator软件查看或者是使用百度字体编辑器(FontEditor (kekee000.github.io))都可以
查看出来的效果可能是这样的
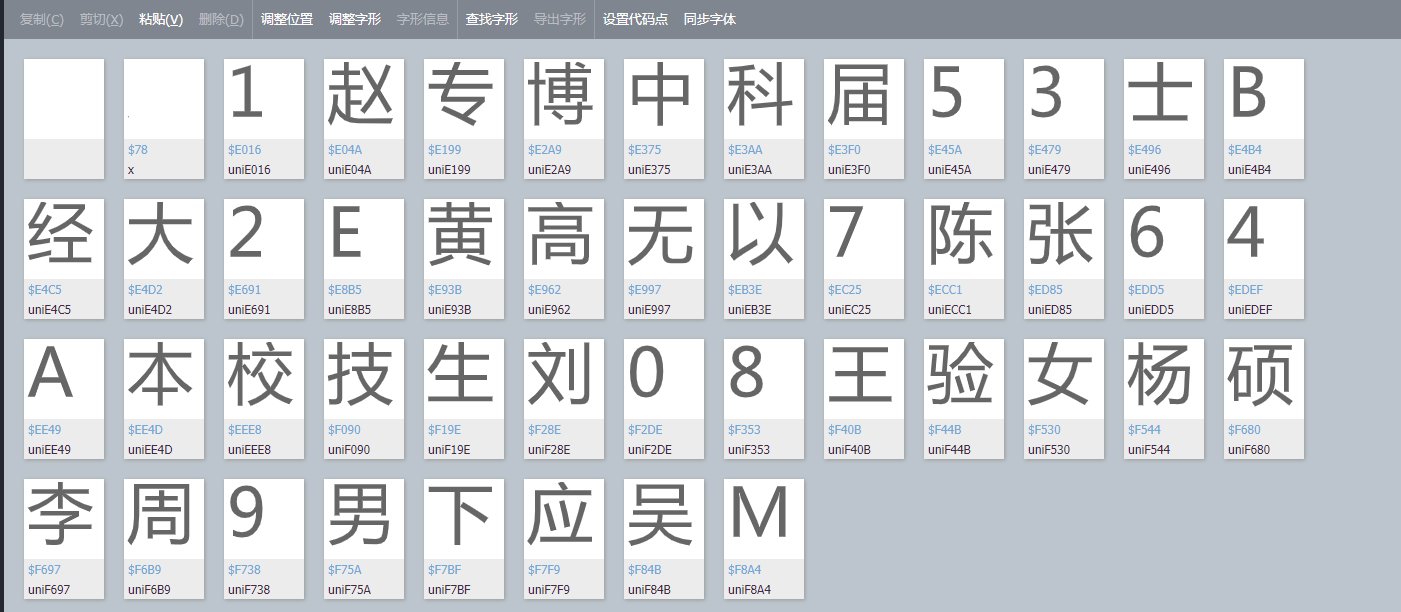
需要格外注意一下下面的uniE016这样的信息,后面要用到。
⑥使用TTFont模块将之前的woff文件保存成xml文件
没有的先安装
pip install fontTools⑦查看xml文件信息
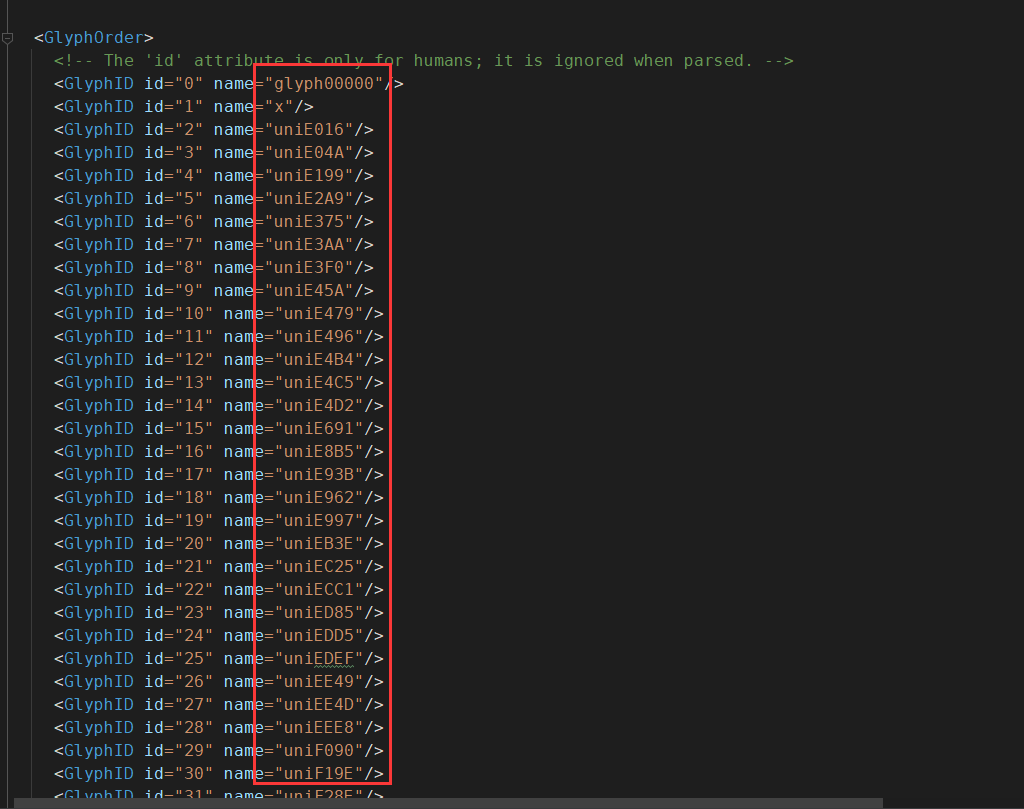
这部分信息与之前woff文件的底部信息是一一对应的,简单理解就是这个字符编码对应着这个字。但事情远没有那么简单,不出意外的话,这些unicode其实是动态的,简单来说就是你在来一次,这些字所对应的编码就会随之改变,但依然是一一对应的。
举个例子,这次1对应的unicode编码是uniE016,下一次执行1对应的unicode编码是uniE018。你想要靠识别unicode编码来识别字体是不太可能的。
⑦找到规律或者是联系
它们之间肯定是有联系的,不然网站自己怎么使用,一般来讲,构成桥梁的都是静态内容。
我爬取的这个网站的规则是这样的
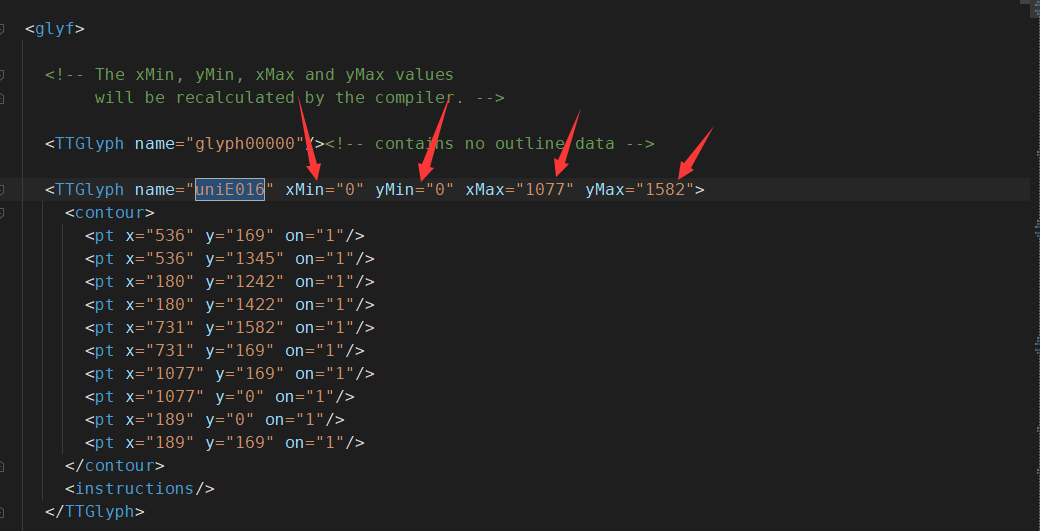
这四个坐标值是关键,不管unicode编码怎么变,下面的x与y值怎们变,这四个坐标值永远不变,这就是桥梁!
⑧构造映射关系
①首先获取每个字体的unicode编码,我们需要这些编码去获取对应的坐标
②构建坐标与字的映射关系
我使用了比较笨的方法,就是手动的构建字典
例如
data_map = {
(0, -255, 1996, 1537): '下',
(0, -303, 2022, 1581): '硕',
(0, -259, 2020, 1691): '张',
}③构建unicode编码与字的映射关系,以坐标为桥梁
例如这样的,因为我要爬取的网页源码上显示的加密内容有所不同,它将uni替换成了&#x还在最后加了;号,要示情况而定

映射关系有了,其实就差不多了
⑨获取html网页信息,将加密内容一一替换
具体实现细节
①bese64解码
import base64
# 解码
decryptContent = base64.b64decode('加密内容')②使用TTFont保存成xml文件
from fontTools.ttLib import TTFont
# 保存成xml文件
fonts = TTFont('字体库.woff')
fontLibraryXML_path = '字体库.xml'
fonts.saveXML(fontLibraryXML_path)③获取每个字体的unicode编码
# 使用内存读写,更方便
tf = TTFont(BytesIO(decryptContent))
# 获取按字母顺序排序的字形名称列表。
print(tf.getGlyphNames())打印出来的结果是类似这样的

④获取四个坐标
coordinate = fonts['glyf'][uniE016].xMin, fonts['glyf'][uniE016].yMin, fonts['glyf'][uniE016].xMax, fonts['glyf'][uniE016].yMax最后一一替换就好了
应该差不多,其他的应该没有太大的问题了
尾声
如果这篇文章对您有所帮助,那么这篇文章就有意义!
感谢您的观看!

