[MIT 6.S081] Lab: Copy-on-Write Fork for xv6
Lab: Copy-on-Write Fork for xv6
在这个实验中,我们要为 xv6 实现 cow fork 。
Implement copy-on write
根据写时复制的方式,我们在复制页面的时候应该采用的是将父级的物理页面映射到子级的页面,因此我们需要修改 kernel/vm.c 中的 uvmcopy ,将页面复制修改为映射的方式,同时应当将两者的 PTE 中的 PTE_W 清除掉,表示为 COW 页面。
不过,在此之前,我们最好标记一下页面是不是 COW page ,这样会对页面识别很有帮助。根据 hint 2 ,我们应该在 RSW 中标记这个位。来到标记 PTE 的宏定义,添加一个 COW 页面标记。
// kernel/riscv.h #define PTE_V (1L << 0) // valid #define PTE_R (1L << 1) #define PTE_W (1L << 2) #define PTE_X (1L << 3) #define PTE_U (1L << 4) // 1 -> user can access #define PTE_COW_PAGE (1L << 8) // copy on write page
虽然按照提示应该先修改的是 uvmcopy ,不过我们现在需要先为 COW Page 提供一下基础设施。对于 COW page ,我们除了要知道一个页面是否为 COW Page ,也要知道 COW Page 该如何被构造和析构的。对于一个 COW Page 页面,会有一些进程引用它,那么谁一旦修改了这个页面,它应当和这个页面没关系了,即:谁修改,谁拷贝一份然后独立出去。那么,什么时候这个页面会被回收呢?自然是没人用的时候,只要没有进程引用它,那么这个页面就是垃圾内存了,可以让操作系统来回收它。
因此,我们需要维护一下每个页面被引用的次数,不管它是不是 COW Page 。
// kernel/kalloc.c struct { struct spinlock lock; uint64 ref_count; } cow_page_ref_info[PHYSTOP / PGSIZE];
接着,我们要知道每个地址对应的页面是哪一个。
// kernel/kalloc.c uint64 get_cow_page_index(void* pa) { return ((uint64)pa - (uint64)end) / PGSIZE; }
我们需要调整引用次数,这里就写一个函数,将这个功能独立出来。要注意的是,由于对内存的访问和修改存在竞争的问题,因此对于每个引用次数都要加锁来保证没有出错。
// kernel/kalloc.c uint64 adjust_cow_page_ref_count(uint64 pa, int dx) { int idx = get_cow_page_index((void*)pa); uint64 cnt; acquire(&cow_page_ref_info[idx].lock); cow_page_ref_info[idx].ref_count += dx; cnt = cow_page_ref_info[idx].ref_count; release(&cow_page_ref_info[idx].lock); return cnt; }
现在我们还需要对这些进行初始化,直接修改 freerange 函数,让它进行初始化。为什么这里初始化要为 1 ,因为接下来要做的是 kfree 。
// kernel/kalloc.c void freerange(void *pa_start, void *pa_end) { char *p; p = (char*)PGROUNDUP((uint64)pa_start); for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE) { initlock(&cow_page_ref_info[get_cow_page_index(p)].lock, "cow_page_ref_count lock"); cow_page_ref_info[get_cow_page_index(p)].ref_count = 1; kfree(p); } }
既然引入了 COW 机制,那么对于所有的页面的分配和释放就需要做出修改。对于 kalloc 来说,分配一个新的页面后,直接将引用计数修改为 1 就好了。但是对于 kfree 来说,由于涉及到引用减少的问题,就稍微比较复杂了点。
- 若当前页面引用计数大于
1,那么就不能释放它,因为它还在被其他进程所需要; - 若当前页面引用计数就是
1,那么直接释放就好了。
// kernel// kernel/kalloc.c void kfree(void *pa) { struct run *r; if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP) panic("kfree"); // Fill with junk to catch dangling refs. uint64 cnt = adjust_cow_page_ref_count((uint64)pa, -1); if (cnt > 0) { return; } memset(pa, 1, PGSIZE); r = (struct run*)pa; acquire(&kmem.lock); if (cnt == 0) { r->next = kmem.freelist; kmem.freelist = r; } release(&kmem.lock); } void * kalloc(void) { struct run *r; acquire(&kmem.lock); r = kmem.freelist; if(r) { kmem.freelist = r->next; } release(&kmem.lock); if(r) { memset((char*)r, 5, PGSIZE); // fill with junk if (adjust_cow_page_ref_count((uint64)r, 1) != 1) { panic("kalloc: ref cnt is not 1\n"); } } return (void*)r; }
那么现在就出现了一个问题:对于引用计数,有减少的,有初始化为 1 (kalloc) 的,增加的呢?
对于增加的情况,我们思考一下,什么时候一个页面会被多个进程引用?自然是产生一个子进程的时候复制页面,也就是指向了 uvmcopy 。
来到 uvmcopy ,我们将其复制页面的步骤修改为对页面的引用,不要忘记了修改后对原来页面的引用计数要增加 1 ,同时要记得将 PTE 设置为不可写和标记为 COW Page 。
// kernel/vm.c int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz) { pte_t *pte; uint64 pa, i; uint flags; // char *mem; for(i = 0; i < sz; i += PGSIZE){ if((pte = walk(old, i, 0)) == 0) panic("uvmcopy: pte should exist"); if((*pte & PTE_V) == 0) panic("uvmcopy: page not present"); pa = PTE2PA(*pte); *pte = (*pte & (~PTE_W)) | PTE_COW_PAGE; flags = PTE_FLAGS(*pte); if (mappages(new, i, PGSIZE, (uint64)pa, flags) != 0) { goto err; } adjust_cow_page_ref_count(pa, 1); } return 0; err: uvmunmap(new, 0, i / PGSIZE, 1); return -1; }
现在我们处理好引用计数这一块的东西了,我们现在要处理一下什么时候会触发 COW Page 拷贝一份然后自己独立出去的问题,也就是向 COW Page 写入的问题。这么尝试,将会出现写入页面错误的中断,因此回到 usertrap 这边,我们要写一下如何应对 15 号中断的问题。
我们要做的,就是在这个情况下,真正的申请一片页面,然后将原来的页面拷贝一份过来,并设置一下 PTE 为可写的,重新映射一下这个新的地址就好了,如果这个页面引用计数只有 1 ,那么直接修改它就好了。要注意的是,如果这里不先将 pte 设置为无效的话,会出现 remap 的问题,但是这里我们需要再一次 map 。
// kernel/trap.c void usertrap() { ... } else if (r_scause() == 15) { if (cow_page_alloc(p->pagetable, r_stval()) != 0) { p->killed = 1; } } else { ... } // kernel/vm.c int cow_page_alloc(pagetable_t pagetable, uint64 va) { // printf("cow_page_alloc\n"); if (va >= MAXVA) { return -1; } pte_t *pte = walk(pagetable, va, 0); if(pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_COW_PAGE) == 0) { printf("cow_page_alloc: pte cannot be used\n"); return -1; } va = PGROUNDDOWN(va); pte = walk(pagetable, va, 0); if (adjust_cow_page_ref_count(PTE2PA(*pte), 0) == 1) { *pte = (*pte & (~PTE_COW_PAGE)) | PTE_W; return 0; } uint64 src_pa = PTE2PA(*pte); uint64 flags = (PTE_FLAGS(*pte) & (~PTE_COW_PAGE)) | PTE_W; uint64 d_pa = (uint64)kalloc(); if (d_pa == 0) { return -1; } memmove((void *)d_pa, (const void *)src_pa, PGSIZE); *pte = *pte & (~PTE_V); if (mappages(pagetable, va, PGSIZE, d_pa, flags) != 0) { return -1; } kfree((void*)PGROUNDDOWN(src_pa)); return 0; }
最后,我们还要稍微设置一下一个地方:copyout 。这个函数运行在内核态,是无法触发 usertrap 的,因此我们需要单独修改一下它。简单来说,就是它要写入的页面,我们先判断一下这个页面是不是 COW Page 页面,是的话给它分配一个新的就行了。
int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len) { uint64 n, va0, pa0; while(len > 0){ va0 = PGROUNDDOWN(dstva); if (va0 >= MAXVA) { return -1; } pte_t *pte = walk(pagetable, va0, 0); if (pte == 0 || (*pte & (PTE_V)) == 0 || (*pte & (PTE_U)) == 0) { return -1; } if ((*pte & (PTE_COW_PAGE))) { if (cow_page_alloc(pagetable, va0) != 0) { return -1; } } pa0 = PTE2PA(*pte); // pa0 = walkaddr(pagetable, va0); // if(pa0 == 0) // return -1; n = PGSIZE - (dstva - va0); if(n > len) n = len; memmove((void *)(pa0 + (dstva - va0)), src, n); len -= n; src += n; dstva = va0 + PGSIZE; } return 0; }
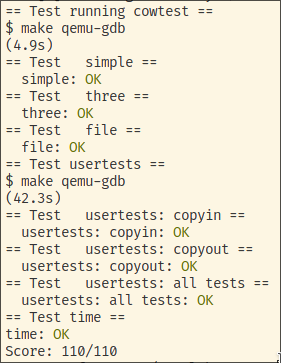
Grade
本文作者:フランドール·スカーレット
本文链接:https://www.cnblogs.com/FlandreScarlet/p/18013406
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步