线性判别分析(Linear Discriminat Analysis)
PCA找寻的投影向量力求找到使得特征点方差较大(也就是说散的比较开),与PCA所找寻的投影向量不同,LAD所找寻的投影向量具有下面两种特性:
- 映射后不同类数据之间的中心点(均值点)相距较远
- 映射后同类数据之间方差较小(分布比较集中)
类似于一种聚类分析,但是却是一种监督学习算法。而PCA属于一种无监督学习算法。
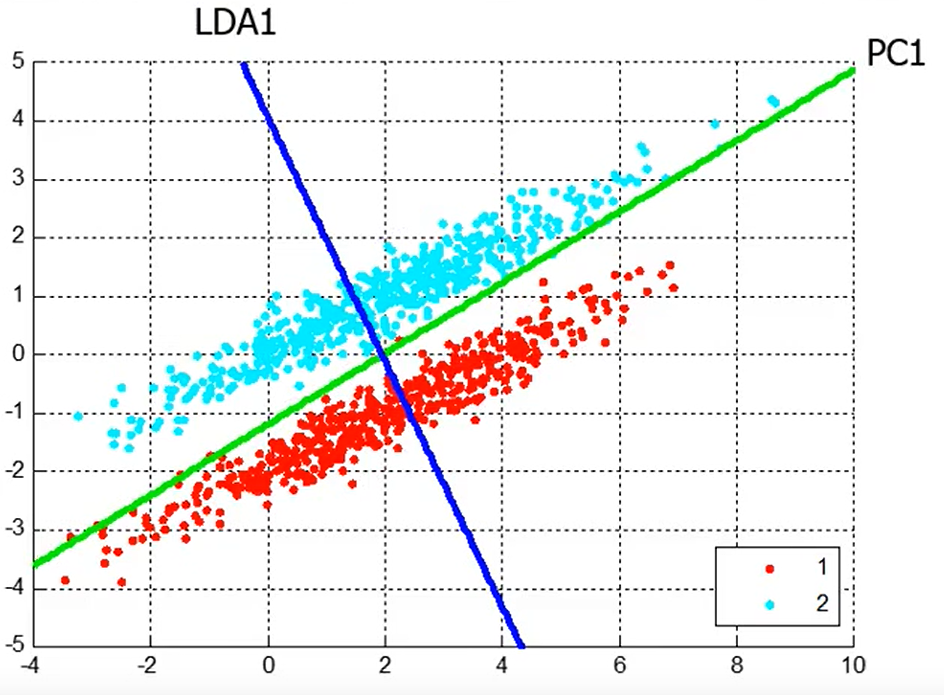
那么将LDA的主轴与PCA的主轴画出如下:
![在这里插入图片描述]()
可以看出实际上数据在映射在 LDA 的主轴上可分性更高。
在下面的正文中的一些数学符号的表示:
\[\begin{aligned} L & : \text { number of classes } \\ n _ { i } & : \text { number of samples in class } i \\ n & : \text { number of all samples } \\ x _ { \ell } ^ { ( i ) } & : \text { the } \ell \text { -th sample in class } i \\ P _ { i } & : \text { the prior probability of class } i \end{aligned}
\]
类间分散矩阵(Between-class Scatter Matrix)
那么所有的样本点 \(x _ { \ell } ^ { ( i ) }\) 在方向 \(e\) 上的投影为:
\[\left\{ e ^ { T } x _ { 1 } ^ { ( 1 ) } , \ldots , e ^ { T } x _ { n _ { 1 } } ^ { ( 1 ) } , e ^ { T } x _ { 1 } ^ { ( 2 ) } , \ldots , e ^ { T } x _ { n _ { 2 } } ^ { ( 2 ) } , \ldots , e ^ { T } x _ { \ell } ^ { ( i ) } , \ldots , e ^ { T } x _ { 1 } ^ { ( L ) } , \ldots , e ^ { T } x _ { n _ { L } } ^ { ( L ) } \right\}
\]
投影之后的中心点为:
\[m _ { i } = \frac { 1 } { n _ { i } } \sum _ { \ell = 1 } ^ { n _ { i } } \boldsymbol { e } ^ { T } \boldsymbol { x } _ { \ell } ^ { ( i ) } = \boldsymbol { e } ^ { T } \left\{ \frac { 1 } { n _ { i } } \sum _ { \ell = 1 } ^ { n _ { i } } \boldsymbol { x } _ { \ell } ^ { ( i ) } \right\} = \boldsymbol { e } ^ { T } \boldsymbol { m } _ { i }
\]
其中 \(\boldsymbol { m } _ { i } = \frac { 1 } { n _ { i } } \sum _ { \ell = 1 } ^ { n _ { i } } \boldsymbol { x } _ { \ell } ^ { ( i ) }\) 实际上就是投影之前的中心,所以投影之后的中心则是原数据中心得投影。
那么不同类中心之间的平方距离(欧氏距离):
\[\begin{aligned}
&\frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \left| \kern-0.15em \left| m _ { i } - m _ { j } \right| \kern-0.15em \right| \\
= &\frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } (m _ { i } - m _ { j })(m _ { i } - m _ { j })^T \\
= &\frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } (e ^ { T } \boldsymbol m _ { i } - e ^ { T } \boldsymbol m _ { j })(e ^ { T } \boldsymbol m _ { i } - e ^ { T } \boldsymbol m _ { j })^T \\
= &\frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } e ^ { T } ( \boldsymbol m _ { i } - \boldsymbol m _ { j })(\boldsymbol m _ { i } - \boldsymbol m _ { j })^T e \\
= &e ^ { T } \underbrace{\left( \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \left( \boldsymbol { m } _ { i } - \boldsymbol { m } _ { j } \right) \left( \boldsymbol { m } _ { i } - \boldsymbol { m } _ { j } \right) ^ { T } \right)}_{S^{LDA}_b} e \\
\end{aligned}
\]
其中 \(S^{LDA}_b\) 代表了类间分散矩阵(Between-class Scatter Matrix),其中下标 \(b\) 代表的 between。
加入每一类的比例是认为这个距离也就是说拉的有多开,跟这两类数据的占比有关。
下面要证明:
\[S _ { b } ^ { L D A } = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \left( \boldsymbol { m } _ { i } - \boldsymbol { m } _ { j } \right) \left( \boldsymbol { m } _ { i } - \boldsymbol { m } _ { j } \right) ^ { T } = \sum _ { i = 1 } ^ { L } P _ { i } \left( \boldsymbol { m } _ { i } - \boldsymbol { m } \right) \left( \boldsymbol { m } _ { i } - \boldsymbol { m } \right) ^ { T }
\]
其中 \(\boldsymbol { m }\) 代表了全部样本点的中心(均值):
\[\boldsymbol { m } = \frac { 1 } { n } \sum _ { i = 1 } ^ { L } \sum _ { \ell = 1 } ^ { n _ { i } } \boldsymbol { x } _ { \ell } ^ { ( i ) }
\]
直接换项不容易,所以这里将两边进行整理转换然后使得转换后等式相等。
先进行左边的等式转换:
\[\begin{aligned}
S _ { b } ^ { L D A } & = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \left( \boldsymbol { m } _ { i } - \boldsymbol { m } _ { j } \right) \left( \boldsymbol { m } _ { i } - \boldsymbol { m } _ { j } \right) ^ { T } \\
& = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \left( \boldsymbol { m } _ { i } \boldsymbol { m } _ { i }^ { T } -\boldsymbol { m } _ { i } \boldsymbol { m } _ { j }^ { T } - \boldsymbol { m } _ { j } \boldsymbol { m } _ { i }^ { T } + \boldsymbol { m } _ { j } \boldsymbol { m } _ { j }^ { T } \right)\\
& = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \boldsymbol { m } _ { i } \boldsymbol { m } _ { i }^ { T } - \frac { 1 } { 2 }\sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \boldsymbol { m } _ { i } \boldsymbol { m } _ { j }^ { T } - \frac { 1 } { 2 }\sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \boldsymbol { m } _ { j } \boldsymbol { m } _ { i }^ { T } + \frac { 1 } { 2 }\sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \boldsymbol { m } _ { j } \boldsymbol { m } _ { j }^ { T } \\
& = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } P _ { i} \boldsymbol { m } _ { i } \boldsymbol { m } _ { i }^ { T } \left( \sum _ { j = 1 } ^ { L } P _ { j } \right)
-\frac { 1 } { 2 } \left(\sum _ { i = 1 } ^ { L } P _ { i} \boldsymbol { m } _ { i }\right) \left(\sum _ { j = 1 } ^ { L } P _ { j } \boldsymbol { m } _ { j }^ { T } \right)
-\frac { 1 } { 2 } \left(\sum _ { j = 1 } ^ { L } P _ { j } \boldsymbol { m } _ { j } \right) \left(\sum _ { i = 1 } ^ { L } P _ { i} \boldsymbol { m } _ { i } ^ { T } \right)+ \frac { 1 } { 2 } \left( \sum _ { i = 1 } ^ { L } P _ { i } \right) \sum _ { j = 1 } ^ { L } P _ { j} \boldsymbol { m } _ { j } \boldsymbol { m } _ { j }^ { T }
\end{aligned}
\]
其中所有概率相加为一:
\[ \left( \sum _ { j = 1 } ^ { L } P _ { j } \right) = \left( \sum _ { i = 1 } ^ { L } P _ { i } \right) = 1
\]
同时:
\[\begin{aligned}
P _ { i } \boldsymbol m _ { i } & = \frac { n _ { i } } { n } \frac { x ^ { ( i ) }_ { 1 } + x ^ { ( i ) } _ { 2 } + \cdots + x _ { n _i } ^ { ( n ) } } { n _ { i } } \\& = \frac { 1 } { n } \left\{ x ^ { ( i ) }_ { 1 } + x ^ { ( i ) } _ { 2 } + \cdots + x _ { n _i } ^ { ( n ) } \right\}
\end{aligned}
\]
那么:
\[\begin{aligned}
\sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m _ { i } & = \sum _ { i = 1 } ^ { L } \frac { 1 } { n } \left\{ x ^ { ( i ) }_ { 1 } + x ^ { ( i ) } _ { 2 } + \cdots + x _ { n _i } ^ { ( n ) } \right\} \\& = \frac { 1 } { n } \left\{ x ^ { ( 1 ) }_ { 1 } + \cdots + x _ { n _ { 1 } } ^ { ( 1 ) } + x ^ { ( 2 ) }_ { 1 }+ \cdots + x _ { n _ { 2 } } ^ { ( 2 ) } + \cdots + x _ { 1 } ^ { ( i ) } + \cdots + x _ { n _ { i } } ^ { ( i ) } \right\} \\ &= \frac { 1 } { n } \sum _ { i = 1 } ^ { L } \sum _ { \ell = 1 } ^ { n _ { i } } \boldsymbol { x } _ { \ell } ^ { ( i ) } = \boldsymbol { m }
\end{aligned}
\]
所以做如下改写:
\[\begin{aligned}
S _ { b } ^ { L D A }
& = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } P _ { i} \boldsymbol { m } _ { i } \boldsymbol { m } _ { i }^ { T } \left( \sum _ { j = 1 } ^ { L } P _ { j } \right)
-\frac { 1 } { 2 } \left(\sum _ { i = 1 } ^ { L } P _ { i} \boldsymbol { m } _ { i }\right) \left(\sum _ { j = 1 } ^ { L } P _ { j } \boldsymbol { m } _ { j }^ { T } \right)
-\frac { 1 } { 2 } \left(\sum _ { j = 1 } ^ { L } P _ { j } \boldsymbol { m } _ { j } \right) \left(\sum _ { i = 1 } ^ { L } P _ { i} \boldsymbol { m } _ { i } ^ { T } \right)+ \frac { 1 } { 2 } \left( \sum _ { i = 1 } ^ { L } P _ { i } \right) \sum _ { j = 1 } ^ { L } P _ { j} \boldsymbol { m } _ { j } \boldsymbol { m } _ { j }^ { T } \\
& = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } P _ { i} \boldsymbol { m } _ { i } \boldsymbol { m } _ { i }^ { T }
-\frac { 1 } { 2 } \boldsymbol { m } \boldsymbol { m } ^T -\frac { 1 } { 2 } \boldsymbol { m } \boldsymbol { m } ^T+
\frac { 1 } { 2 } \sum _ { j = 1 } ^ { L } P _ { j} \boldsymbol { m } _ { j } \boldsymbol { m } _ { j }^ { T } \\
& = \sum _ { i = 1 } ^ { L } P _ { i} \boldsymbol { m } _ { i } \boldsymbol { m } _ { i }^ { T }
-\boldsymbol { m } \boldsymbol { m } ^T
\end{aligned}
\]
现在进行右边的等式转换:
\[\begin{aligned}
& \sum _ { i = 1 } ^ { L } P _ { i } \left( \boldsymbol { m } _ { i } - \boldsymbol { m } \right) \left( \boldsymbol { m } _ { i } - \boldsymbol { m } \right) ^ { T }\\
= & \sum _ { 1 = 1 } ^ { L } P _ { i } \boldsymbol m _ { i } \boldsymbol m _ { i } ^T- \sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m _ { i } \boldsymbol m ^ T- \sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m \boldsymbol m _ { i } ^T + \sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m \boldsymbol m ^ T \\
= & \sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m _ i \boldsymbol m _ { i } ^T - \left( \sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m _ { i } \right) \boldsymbol m ^T- \boldsymbol m \left( \sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m _ { i } ^T\right) + \left(\sum _ { i = 1 } ^ { L } P _ { i } \right) \boldsymbol m \boldsymbol m ^ T \\
= & \sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m _ i \boldsymbol m _ { i } ^T - \boldsymbol m \boldsymbol m ^T- \boldsymbol m \boldsymbol m ^T + \boldsymbol m \boldsymbol m ^ T \\
= & \sum _ { i = 1 } ^ { L } P _ { i } \boldsymbol m _ i \boldsymbol m _ { i } ^T - \boldsymbol m \boldsymbol m ^T
\end{aligned}
\]
所以两者相等。即:
\[S _ { b } ^ { L D A } = \frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \left( \boldsymbol { m } _ { i } - \boldsymbol { m } _ { j } \right) \left( \boldsymbol { m } _ { i } - \boldsymbol { m } _ { j } \right) ^ { T } = \sum _ { i = 1 } ^ { L } P _ { i } \left( \boldsymbol { m } _ { i } - \boldsymbol { m } \right) \left( \boldsymbol { m } _ { i } - \boldsymbol { m } \right) ^ { T }
\]
类内分散矩阵(Within-class Scatter Matrix)
全部类的方差之和为:
\[\begin{aligned}
& \sum _ { i = 1 } ^ { L } { P } _ { i } \sum _ { \ell = 1 } ^ { n _ { i } } \left( e ^ { T } { x } _ { \ell } ^ { ( i ) } - m _ { i } \right) ^ { 2 } \\
= & \sum _ { i = 1 } ^ { L } P _ { i } \sum _ { l = 1 } ^ { n _ { i } } \left( e ^ { T } x _ { l } ^ { ( i ) } - e ^ { T} \boldsymbol m _ { i } \right) ^ { 2 } \\
= & \sum _ { i = 1 } ^ { L } P _ { i } \sum _ { l = 1 } ^ { n _ { i } } \left( e ^ { T} x _ { l } ^ { ( i ) } - e ^ { T} \boldsymbol m _ { i } \right) \left( e ^ { T} x _ { l } ^ { ( i ) } - e ^ { T} \boldsymbol m _ { i } \right) ^ T \\
= & e^ { T} \left\{ \underbrace { \sum _ { i = 1 } ^ { L } P _ { i } \sum _ { l = 1 } ^ { n _ { i } } \left( x _ { i } ^ { ( i ) } - \boldsymbol m _ { i } \right) \left( x _ { i } ^ { ( i ) } - \boldsymbol m _ { i } \right) ^ { T } }_{\boldsymbol { S } _ { w } ^ { L D A }}\right\} e
\end{aligned}
\]
其中 \(\boldsymbol S^{LDA}_w\) 代表了类间分散矩阵(Within-class Scatter Matrix),其中下标 \(w\) 代表的 within。
\[\boldsymbol { S } _ { w } ^ { L D A } = \sum _ { i = 1 } ^ { L } P _ { i } \sum _ { \ell = 1 } ^ { n _ { i } } \left( \boldsymbol { x } _ { \ell } ^ { ( i ) } - \boldsymbol { m } _ { i } \right) \left( \boldsymbol { x } _ { \ell } ^ { ( i ) } - \boldsymbol { m } _ { i } \right) ^ { T }
\]
希望类(组)间距离越大越好:
\[\frac { 1 } { 2 } \sum _ { i = 1 } ^ { L } \sum _ { j = 1 } ^ { L } P _ { i } P _ { j } \left( m _ { i } - m _ { j } \right) ^ { 2 } = e ^ { T } \left( \sum _ { i = 1 } ^ { L } P _ { i } \left( \boldsymbol { m } _ { i } - \boldsymbol { m } \right) \left( \boldsymbol { m } _ { i } - \boldsymbol { m } \right) ^ { T } \right) e = e^T \boldsymbol { S } _ { b } ^ { L D A } e
\]
希望类(组)间距离越小越好:
\[\sum _ { i = 1 } ^ { L } P _ { i } \sum _ { \ell = 1 } ^ { n _ { i } } \left( e ^ { T } x _ { \ell } ^ { ( i ) } - m _ { i } \right) ^ { 2 } = e ^ { T } { \left( \sum _ { i = 1 } ^ { L } P _ { i } \sum _ { \ell = 1 } ^ { n _ { i } } \left( x _ { \ell } ^ { ( i ) } - m _ { i } \right) \left( x _ { \ell } ^ { ( i ) } - m _ { i } \right) ^ { T } \right) } e = e^ T \boldsymbol { S } _ { w } ^ { L D A } e
\]
所以两个不能分开来看,所以选择目标函数的表示为:
\[e = \arg \max _ { e \in R ^ { d } } \frac { e ^ { T } S _ { b } ^ { L D A } e } { e ^ { T } S _ { w } ^ { L D A } e }
\]
来保证分子最大,分母最小,也就是说 组间距离/组内距离 越大越好。
现在引入一个概念:Rayleigh Quotient
\[r ( { e } ) = \frac { { e } ^ { T } { S } _ { b } ^ { L D A } { e } } { { e } ^ { T } { S } _ { w } ^ { L D A } { e } }
\]
那么凸最优解,就是求导为零:
\[\begin{aligned}
\nabla r ( \boldsymbol { e } ) & = \frac { 1 } { \left( \boldsymbol { e } ^ { T } \boldsymbol { S } _ { w } ^ { L D A } \boldsymbol { e } \right) ^ { 2 } } \left\{ \left( \boldsymbol { e } ^ { T } \boldsymbol { S } _ { w } ^ { L D A } \boldsymbol { e } \right) \left( 2 \boldsymbol { S } _ { b } ^ { L D A } \boldsymbol { e } \right) - \left( \boldsymbol { e } ^ { T } \boldsymbol { S } _ { b } ^ { L D A } \boldsymbol { e } \right) \left( 2 \boldsymbol { S } _ { w } ^ { L D A } \boldsymbol { e } \right) \right\} = 0\\
& = \frac { 1 } { e ^ { T } S _ { w } ^ { LDA } e } \left\{\underbrace {1 \cdot 2 S _ { b } ^ { L D A } e - \frac { e ^ { T} S _ { b } ^ { L D A } e } { e ^ { T} S _ { w } ^ { L D A} e } 2 S _ { W } ^ { L D A } e}_{0} \right\}
\end{aligned}
\]
也就是说
\[S _ { b } ^ { L D A } e = \frac { e ^ { T} S _ { b } ^ { L D A } e } { e ^ { T} S _ { w } ^ { L D A} e } S _ { w } ^ { L D A } e = r(e) S _ { w } ^ { L D A } e
\]
这是一种广义特征值问题(generalized eigenvalue problem),即:
\[\boldsymbol { S } _ { b } ^ { L D A } \boldsymbol { e } = \lambda \boldsymbol { S } _ { w } ^ { L D A } \boldsymbol { e }
\]
这里的特征向量不在是原来的特征向量而是原来的特征向量乘以一个矩阵,所以是在求 \(\boldsymbol { S } _ { b } ^ { L D A }\) 的广义特征值 \(\lambda\) 。
工程上的解法是,做如下转换:
\[\text{pinv} (\boldsymbol { S } _ { w } ^ { L D A } )\boldsymbol { S } _ { b } ^ { L D A } \boldsymbol { e } = \lambda \boldsymbol { e }
\]
然后使用特征值求解方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号