LLVM笔记(10) - 指令选择(二) lowering
本节主要介绍SelectionDAG的构成与lowering的过程. SelectionDAG是LLVM指令选择的基础框架, 不论是O0编译时使用的FastISel还是O2编译时使用的SelectionDAGISel都会使用SelectionDAG来描述输入的程序流. 将输入的IR转换成SelectionDAG的过程被称作lowering, 在lowering之前我们通过IR表示一段程序, 在lowering之后我们使用SelectionDAG来描述同一段程序.
我们首先从一个简单的case入手讲解SelectionDAG的基本概念, 然后介绍对应的数据结构以及如何建立SelectionDAG(即lowering的流程), 最后总结lowering的注意点以及在支持一个新架构时我们需要做什么.
PS: 本文假定读者已熟悉LLVM IR即其对应代码实现, 对涉及的中端概念不再赘述.
PPS: 由于不同的架构支持的指令集/寄存器/调用约定均不相同, lowering过程也包含架构相关的代码. 如未特殊说明, 本文中涉及的架构相关的代码均指RISCV架构(相对于X86以及AArch64, RISCV指令集更精简, 且历史包袱也较小, 更适合入门理解).
打印SelectionDAG graph
让我们首先从一个简单的case开始入手, test()函数会做一些算术运算与访问内存操作, 并会调用test2()函数, 但它没有循环与条件跳转, 因此只包含一个basic block. 打印它的IR如下所示.
[00:04:16] hansy@hansy:~$ cat 1.c
int test2(int p1);
int test(int *p1, int p2, int p3, char p4) {
int ret, base, off;
base = p1[0];
off = p4 & 0x1f;
ret = (base * p3) << off;
p1[p2] = ret;
return test2(ret);
}
[00:04:19] hansy@hansy:~$ ~/llvm-mono/llvm_install/bin/clang --target=riscv32 -O2 1.c -S -emit-llvm && cat 1.ll
; ModuleID = '1.c'
source_filename = "1.c"
target datalayout = "e-m:e-p:32:32-i64:64-n32-S128"
target triple = "riscv32"
; Function Attrs: nounwind
define dso_local i32 @test(i32* nocapture %p1, i32 %p2, i32 %p3, i8 zeroext %p4) local_unnamed_addr #0 {
entry:是比较少见的依赖
%0 = load i32, i32* %p1, align 4, !tbaa !2
%1 = and i8 %p4, 31
%and = zext i8 %1 to i32
%mul = mul nsw i32 %0, %p3
%shl = shl i32 %mul, %and
%arrayidx1 = getelementptr inbounds i32, i32* %p1, i32 %p2
store i32 %shl, i32* %arrayidx1, align 4, !tbaa !2
%call = tail call i32 @test2(i32 %shl) #2
ret i32 %call
}
declare dso_local i32 @test2(i32) local_unnamed_addr #1
attributes #0 = { nounwind "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="none" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-features"="+a,+c,+m,+relax" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "frame-pointer"="none" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-features"="+a,+c,+m,+relax" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #2 = { nounwind }
!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{!"clang version 10.0.0 (https://github.com/crazyrabbit0424/llvm-project.git 905b002c139f039a32ab9bf1fad63d745d12423f)"}
!2 = !{!3, !3, i64 0}
!3 = !{!"int", !4, i64 0}是比较少见的依赖
!4 = !{!"omnipotent char", !5, i64 0}
!5 = !{!"Simple C/C++ TBAA"}
我们可以使用LLVM内置的debug命令将指令选择阶段的SelectionDAG信息保存下来并写入dot文件, 然后通过dot/xdot图形化显示出来.
[00:23:24] hansy@hansy:~$ ~/llvm-mono/llvm_install/bin/clang --target=riscv32 -O2 1.c -S -mllvm -view-dag-combine1-dags=true
Writing '/tmp/dag.test-c5e6fc.dot'... done.
Trying 'xdg-open' program... Remember to erase graph file: /tmp/dag.test-c5e6fc.dot
命令行中-view-dag-combine1-dags=true表示在第一次combine之前打印SelectionDAG(即lowering之后的graph), 类似的选项还有:
| command | accepted argument | method |
|---|---|---|
| -view-legalize-types-dags= | bool | print graph before legalize type |
| -view-legalize-dags= | bool | print graph before legalize |
| -view-dag-combine2-dags= | bool | print graph before second combine |
| -view-dag-combine-lt-dags= | bool | print graph after legalize type |
| -view-isel-dags= | bool | print graph before do instruction selection |
| -view-sched-dags= | bool | print graph before schedule dag |
| -view-sunit-dags= | bool | print graph after schedule dag |
| -filter-view-dags= | string | print graph on each stage only for basic block whose name matches the option |
| 以上文case为例, 打印的graph如下所示. | ||
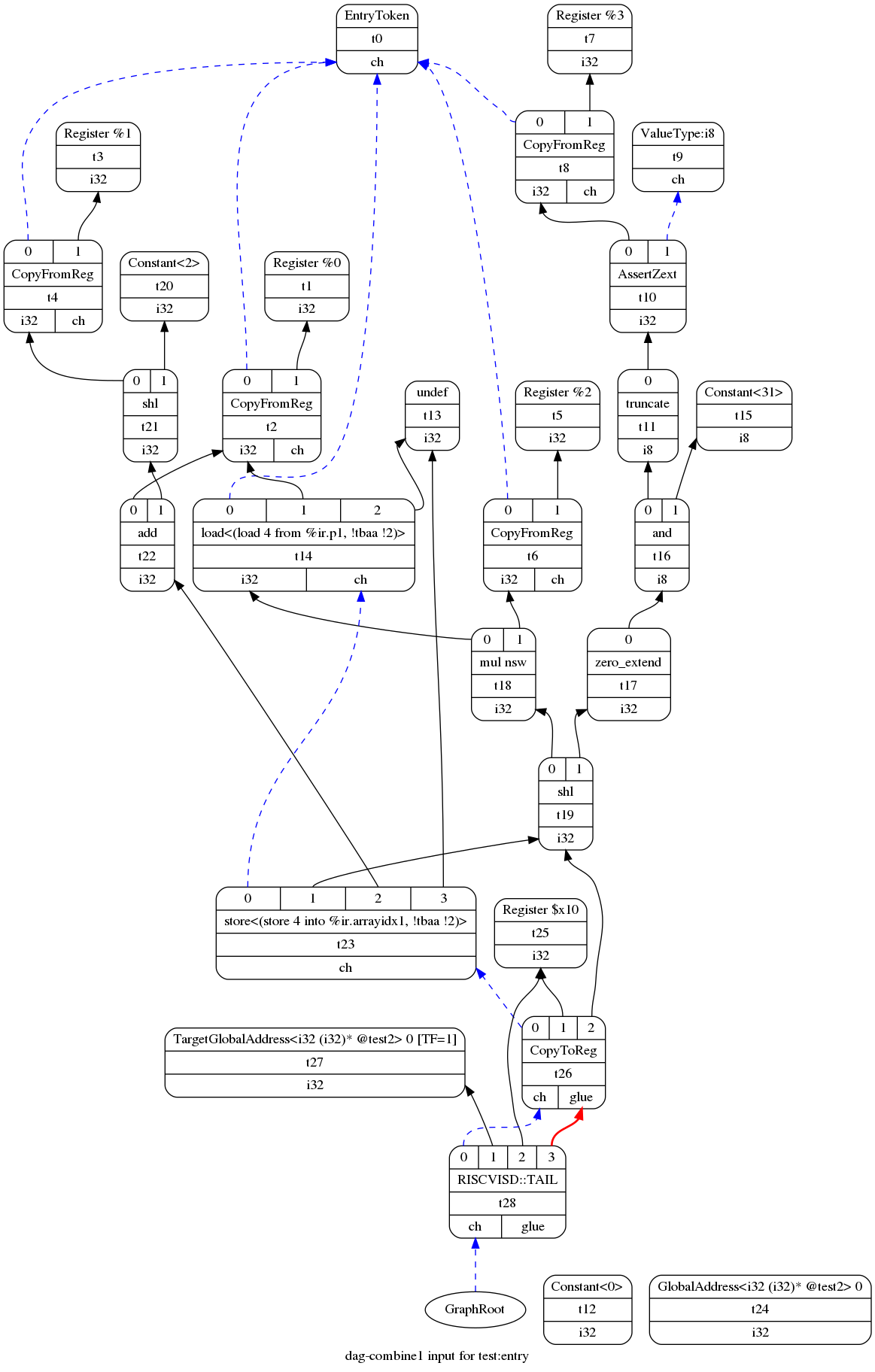 |
||
| 这里我们将文字打印也贴出来方便对照理解. |
Initial selection DAG: %bb.0 'test:entry'
SelectionDAG has 29 nodes:
t0: ch = EntryToken
t2: i32,ch = CopyFromReg t0, Register:i32 %0
t12: i32 = Constant<0>
t14: i32,ch = load<(load 4 from %ir.p1, !tbaa !2)> t0, t2, undef:i32
t6: i32,ch = CopyFromReg t0, Register:i32 %2
t18: i32 = mul nsw t14, t6
t8: i32,ch = CopyFromReg t0, Register:i32 %3
t10: i32 = AssertZext t8, ValueType:ch:i8
t11: i8 = truncate t10
t16: i8 = and t11, Constant:i8<31>
t17: i32 = zero_extend t16
t19: i32 = shl t18, t17
t24: i32 = GlobalAddress<i32 (i32)* @test2> 0
t4: i32,ch = CopyFromReg t0, Register:i32 %1
t21: i32 = shl t4, Constant:i32<2>
t22: i32 = add t2, t21
t23: ch = store<(store 4 into %ir.arrayidx1, !tbaa !2)> t14:1, t19, t22, undef:i32
t26: ch,glue = CopyToReg t23, Register:i32 $x10, t19
t28: ch,glue = RISCVISD::TAIL t26, TargetGlobalAddress:i32<i32 (i32)* @test2> 0 [TF=1], Register:i32 $x10, t26:1
我们将在后面详细解释图中每个符号的作用, 这里我们先简单介绍一下如何阅读这样的图.
图中每个大的方块是一个名为SDNode的节点, 代表一个操作数或操作符. 根据不同的类型每个方块又划分为三行或四行子方块.
其中表示操作数的节点包含三行, 从上到下依次代表节点类型枚举, 节点编号与节点的数据类型. 以左上角t3节点为例它代表一个数据类型为i32的寄存器操作数, 其节点编号为t3. 又比如最右侧的t15节点它代表一个数据类型为i8的常量, 其值为31, 节点编号t15.
表示操作符的节点包含四行, 其中最上层一行表示这个操作符所接受的输入操作数的序号, 后三行与表示操作数的节点类似, 注意操作符本身没有数据类型, 它的数据类型是指这个操作符输出的操作数的数据类型. 以t11节点为例, 它代表一个截断操作, 其输出一个i8类型的数据, truncate操作接受一个输入操作数.
节点间的箭头代表了节点的依赖关系, 图中一共有三类箭头, 黑色实线, 蓝色虚线以及红色实线, 它们分别代表三类依赖关系.
黑色实线代表数据依赖, 箭头指向的数据来源. 以t19节点为例, 节点左移操作接受两个输入操作数, 被移位数据是比较少见的依赖的操作数(序号为0)的来源是t18, 移位位数的操作数(序号为1)的来源是t16. 其结果被store操作(节点t23)与拷贝操作(节点t26)引用.
蓝色虚线代表一种特殊的依赖关系(chain dependence). 它指的是节点在调度时不能被移动到所依赖的节点之前. 以t23节点为例, store操作与load操作可能访问同一内存地址, 那么编译器需要保守处理将store指令放在load操作后. 然而store与load之间并没有直接的数据依赖关系(尽管在这个case中两者可以通过t18间接保证依赖, 但也可能出现完全没有依赖的情况), 因此编译器会为其添加一个额外的chain依赖. 为生成chain依赖, 编译器会为被依赖节点额外添加一个名为ch类型的输出操作数, 为依赖的来源节点额外添加一个输入操作数.
红色实线类似蓝色虚线, 但它代表一种更强的关系(glue), 它指的是被glue的节点在调度时不能被分开. chain依赖的节点之间相互顺序不能改变, 但是两者可以分开调度, 也可以合并在一起, 而glue依赖要求节点必须绑定在一起. glue通常比较少见, 在上文的case中t26与t28之间存在一条glue依赖, 原因是t28是tail call操作, t26是函数调用前设置传参. 根据RISCV calling convention函数传参寄存器为x10-x17, 为保证正确性需要将两个节点绑定到一起, 否则可能存在第三个节点被调度到两者之间并在后面寄存器分配时分配到x10导致传参被覆写.
DAG图的组成
LLVM使用SelectionDAG类(defined in include/llvm/CodeGen/SelectionDAG.h)表示一个架构无关的底层数据依赖图, 它将串联整个指令选择流程, 所以包含了许多成员与接口, 这里我们只截取与lowering相关的部分.
class SelectionDAG {
const TargetLowering *TLI = nullptr;
FunctionLoweringInfo * FLI = nullptr;
/// The starting token.
SDNode EntryNode;
/// The root of the entire DAG.
SDValue Root;
/// A linked list of nodes in the current DAG.
ilist<SDNode> AllNodes;
};
其中TargetLowering负责处理架构相关的lowering, FunctionLoweringInfo负责处理函数调用约定, 这两个成员后面会介绍. EntryNode与Root分别指向图的入口节点与根节点, 通过根节点即可遍历整个图. 注意到这里使用的是SDNode与SDValue, 而非IR中的Node与Value. 在解释两者区别前让我们先思考一个问题: 如果使用IR来表示上文中的DAG有什么困难(换言之为什么不使用IR来直接表示DAG)?
- 首先最直观的一点是IR中每个节点只能有一个输出(表示一个操作符/操作数的对象Node本身只有一个输出值), 而DAG中的节点通常有多个输出, 并且输出不一定是一个参与运算的值.
- 进一步的之所以产生多个输出的原因之一是DAG会包含非数据的依赖关系. 我们可以通过Value的成员UseList获取显示引用这个操作符/操作数的使用者, 但无法获取非数据依赖的引用关系.
也就是说DAG体现了节点间约束的关系, 而IR只能表示节点的数据流图. 为解决这个问题, 对应IR中的Value/Node/Use类型, LLVM重新设计了SDValue/SDNode/SDUse类型(all defined in include/llvm/CodeGen/SelectionDAGNodes.h).
// 类似于Value, SelectionDAG中每个操作数都使用一个SDValue对象来表示
// 但不同于Node, SDNode支持多个输出, 因此SDValue不光要指明值来源于哪个SDNode, 还要指明值来源于第几个输出
class SDValue {
SDNode *Node = nullptr; // 定义这个SDValue的SDNode
unsigned ResNo = 0; // 记录这个SDValue所属于SDNode的输出的序号
};
// 代表SelectionDAG中的一个节点, 一个节点包含了以下信息: 节点的操作类型, 输入操作数, 输出值
class SDNode : public FoldingSetNode, public ilist_node<SDNode> {
// 节点操作符的枚举, 枚举值可以为ISD::NodeType或[arch]ISD::NodeType
// 前者为架构无关的操作符, defined in include/llvm/CodeGen/ISDOpcodes.h
// 后者为架构相关的操作符, defined in lib/Target/[arch]/[arch]ISelLowering.h
int16_t NodeType;
// 节点序号标记, 注意这个值在Selection过程中根据不同场景含义会发生变化
int NodeId = -1;
// 被该节点使用的SDValue(即输入操作数)的链表, 根据参数顺序排列
SDUse *OperandList = nullptr;
// 节点输出值的类型, SDNode允许多个输出所以指向的是个数组
const EVT *ValueList;
SDUse *UseList = nullptr; // 引用该节点的链表
unsigned short NumOperands = 0; // 输入操作数个数
unsigned short NumValues; // 输出值个数
public:SelectionDAGISel::SelectBasicBlock
uint16_t PersistentId; // 节点唯一且不变的id, 用于debug打印
};
// 每个SDUse表示对一个SDNode的引用.
class SDUse {
SDValue Val; // 该SDUse实际引用的SDValue
SDNode *User = nullptr; // 指向引用该SDNode的节点(引用者)
SDUse **Prev = nullptr; // 双向链表记录所有引用该SDNode的SDUse
SDUse *Next = nullptr; // 双向链表记录所有引用该SDNode的SDUse
};
来看一个简单的例子, t4是一个add操作, 它接受一个寄存器拷贝t2及常量t3.
Initial selection DAG: %bb.0 'test:entry'
SelectionDAG has 8 nodes:
t0: ch = EntryToken
t2: i32,ch = CopyFromReg t0, Register:i32 %0
t4: i32 = add nsw t2, Constant:i32<1>
t6: ch,glue = CopyToReg t0, Register:i32 $x10, t4
t7: ch = RISCVISD::RET_FLAG t6, Register:i32 $x10, t6:1
其数据框图如下:
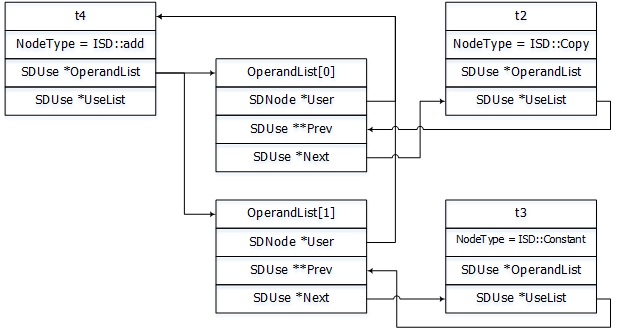
初始化SelectionDAG
LLVM使用SelectionDAGBuilder类来初始化SelectionDAG, SelectionDAGBuilder是以basic block为单位构建的. 这是基于对性能与复杂度的权衡, 在后面我们会看到由于SelectionDAG无法获取跨basic block的信息, 丢失了生成复杂指令的机会(另一个导致无法获取最优指令选择的因素是贪婪的树匹配方式只能保证局部最优).
在SelectionDAGISel::SelectAllBasicBlocks()中会对每个basic block调用SelectionDAGISel::SelectBasicBlock(), 后者会顺序的对每条指令调用SelectionDAGBuilder::visit()接口将IR节点转换为DAG节点, 转换完成后将DAG的root传递给SelectionDAGISel的CurDAG. 代码如下:
void SelectionDAGISel::SelectBasicBlock(BasicBlock::const_iterator Begin,
BasicBlock::const_iterator End,
bool &HadTailCall) {
// Allow creating illegal types during DAG building for the basic block.
CurDAG->NewNodesMustHaveLegalTypes = false;
// Lower the instructions. If a call is emitted as a tail call, cease emitting
// nodes for this block.
for (BasicBlock::const_iterator I = Begin; I != End && !SDB->HasTailCall; ++I) {
if (!ElidedArgCopyInstrs.count(&*I))
SDB->visit(*I);
}
// Make sure the root of the DAG is up-to-date.
CurDAG->setRoot(SDB->getControlRoot());
HadTailCall = SDB->HasTailCall;
SDB->resolveOrClearDbgInfo();
SDB->clear();
// Final step, emit the lowered DAG as machine code.
CodeGenAndEmitDAG();
}
void SelectionDAGBuilder::visit(const Instruction &I) {
// Set up outgoing PHI node register values before emitting the terminator.
if (I.isTerminator()) {
HandlePHINodesInSuccessorBlocks(I.getParent());
}
// Increase the SDNodeOrder if dealing with a non-debug instruction.
if (!isa<DbgInfoIntrinsic>(I))
++SDNodeOrder;
CurInst = &I;
visit(I.getOpcode(), I);
if (auto *FPMO = dyn_cast<FPMathOperator>(&I)) {
// Propagate the fast-math-flags of this IR instruction to the DAG node that
// maps to this instruction.
// TODO: We could handle all flags (nsw, etc) here.
// TODO: If an IR instruction maps to >1 node, only the final node will have
// flags set.
if (SDNode *Node = getNodeForIRValue(&I)) {
SDNodeFlags IncomingFlags;
IncomingFlags.copyFMF(*FPMO);
if (!Node->getFlags().isDefined())
Node->setFlags(IncomingFlags);
else
Node->intersectFlagsWith(IncomingFlags);
}
}
if (!I.isTerminator() && !HasTailCall &&
!isStatepoint(&I)) // statepoints handle their exp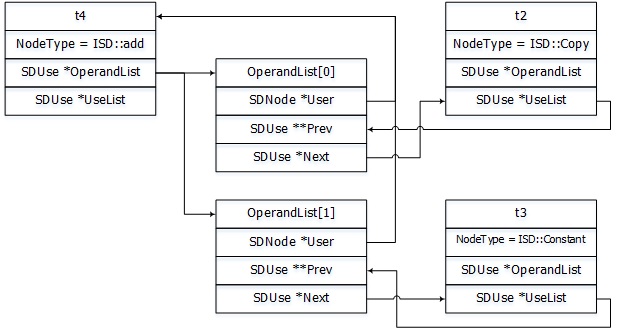
orts internally
CopyToExportRegsIfNeeded(&I);
CurInst = nullptr;
}
void SelectionDAGBuilder::visit(unsigned Opcode, const User &I) {
// Note: this doesn't use InstVisitor, because it has to work with
// ConstantExpr's in addition to instructions.
switch (Opcode) {
default: llvm_unreachable("Unknown instruction type encountered!");
// Build the switch statement using the Instruction.def file.
#define HANDLE_INST(NUM, OPCODE, CLASS) \
case Instruction::OPCODE: visit##OPCODE((const ./llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cppCLASS&)I); break;
#include "llvm/IR/Instruction.def"
}
}
注意到visit()对每个IR节点都会调用visit##OPCODE(), 其中OPCODE为节点的Opcode. 我们以Add为例, visitAdd()会拆解Add操作的操作数, 然后调用SelectionDAG::getNode()创建一个SDNode.
void visitAdd(const User &I) { visitBinary(I, ISD::ADD); }
void SelectionDAGBuilder::visitBinary(const User &I, unsigned Opcode) {
SDNodeFlags Flags;
if (auto *OFBinOp = dyn_cast<OverflowingBinaryOperator>(&I)) {
Flags.setNoSignedWrap(OFBinOp->hasNoSignedWrap());
Flags.setNoUnsignedWrap(OFBinOp->hasNoUnsignedWrap());
}
if (auto *ExactOp = dyn_cast<PossiblyExactOperator>(&I)) {
Flags.setExact(ExactOp->isExact());
}
if (isVectorReductionOp(&I)) {
Flags.setVectorReduction(true);
LLVM_DEBUG(dbgs() << "Detected a reduction operation:" << I << "\n");
}
SDValue Op1 = getValue(I.getOperand(0));
SDValue Op2 = getValue(I.getOperand(1));
SDValue BinNodeValue = DAG.getNode(Opcode, getCurSDLoc(), Op1.getValueType(),
Op1, Op2, Flags);
setValue(&I, BinNodeValue);
}
SDValue SelectionDAG::getNode(unsigned Opcode, const SDLoc &DL, EVT VT) {
FoldingSetNodeID ID;
AddNodeIDNode(ID, Opcode, getVTList(VT), None);
void *IP = nullptr;
if (SDNode *E = FindNodeOrInsertPos(ID, DL, IP))
return SDValue(E, 0);
auto *N = newSDNode<SDNode>(Opcode, DL.getIROrder(), DL.getDebugLoc(),
getVTList(VT));
CSEMap.InsertNode(N, IP);
InsertNode(N);
SDValue V = SDValue(N, 0);
NewSDValueDbgMsg(V, "Creating new node: ", this);
return V;
}
其它的IR节点也类似以上的方式lowering, 不再赘述. 这里我们再看两种特殊IR的lowering, 它们分别会涉及架构相关的lowering与跨basic block的信息传递.
第一种是Call.
void SelectionDAGBuilder::visitCall(const CallInst &I) {
......
SDValue Callee = getValue(I.getCalledValue());
if (I.countOperandBundles./llvm/lib/CodeGen/SelectionDAG/SelectionDAGBuilder.cppOfType(LLVMContext::OB_deopt))
LowerCallSiteWithDeoptBundle(&I, Callee, nullptr);
else
// Check if we can potentially perform a tail call. More detailed checking
// is be done within LowerCallTo, after more information about the call is
// known.
LowerCallTo(&I, Callee, I.isTailCall());
}
void SelectionDAGBuilder::LowerCallTo(ImmutableCallSite CS, SDValue Callee,
bool isTailCall,
const BasicBlock *EHPadBB) {
......
TargetLowering::CallLoweringInfo CLI(DAG);
CLI.setDebugLoc(getCurSDLoc())
.setChain(getRoot())
.setCallee(RetTy, FTy, Callee, std::move(Args), CS)
.setTailCall(isTailCall)SelectionDAGISel::SelectAllBasicBlocks
.setConvergent(CS.isConvergent());
std::pair<SDValue, SDValue> Result = lowerInvokable(CLI, EHPadBB);
......
}
std::pair<SDValue, SDValue>
SelectionDAGBuilder::lowerInvokable(TargetLowering::CallLoweringInfo &CLI,
const BasicBlock *EHPadBB) {
......
const TargetLowering &TLI = DAG.getTargetLoweringInfo();
std::pair<SDValue, SDValue> Result = TLI.LowerCallTo(CLI);
......
return Result;
}
这里省略了无关的代码, 注意到在lowerInvokable()会调用TargetLoweringInfo::LowerCallTo(), 即对于call/return等不同架构可能实现不一致的IR, 会通过TargetLoweringInfo的回调单独处理.
第二种是PHI.
void SelectionDAGBuilder::visitPHI(const PHINode &) {
llvm_unreachable("SelectionDAGBuilder shouldn't visit PHI nodes!");
}
注意到调用visitPHI()函数会直接报错, 那么
- 为什么PHI节点不应该被lowering?
- 如果PHI节点没有被lowering那么引用PHI节点的节点的operand该设置成什么呢?
对于第一点, 首先PHI是为满足程序SSA格式而创建的虚拟节点, 在DAG中我们无需保证SSA格式(由于调用约定的存在, 实际也无法保证), 因此lowering PHI是没有意义的.
对于第二点, 在SelectionDAGISel::SelectAllBasicBlocks()调用SelectionDAGISel::SelectBasicBlock()前会首先遍历每个basic block, 为每个basic block计算register liveout, 并保存到FunctionLoweringInfo.ValueMap中. 当引用PHI的节点在获取其Value时会首先检查这个map, 如果找到就调用SelectionDAGBuilder::getCopyFromRegs()创建一个从虚拟寄存器的拷贝节点.
void SelectionDAGISel::SelectAllBasicBlocks(const Function &Fn) {
......
for (const BasicBlock *LLVMBB : RPOT) {
if (OptLevel != CodeGenOpt::None) {
bool AllPredsVisited = true;
for (const_pred_iterator PI = pred_begin(LLVMBB), PE = pred_end(LLVMBB);
PI != PE; ++PI) {
if (!FuncInfo->VisitedBBs.count(*PI)) {
AllPredsVisited = false;
break;
}
}
if (AllPredsVisited) {
for (const PHINode &PN : LLVMBB->phis())
FuncInfo->ComputePHILiveOutRegInfo(&PN);
} else {
for (const PHINode &PN : LLVMBB->phis())
FuncInfo->InvalidatePHILiveOutRegInfo(&PN);
}
FuncInfo->VisitedBBs.insert(LLVMBB);
}
}
......SelectionDAGBuilder::getCopyFromRegs
}
void FunctionLoweringInfo::ComputePHILiveOutRegInfo(const PHINode *PN) {
Type *Ty = PN->getType();
if (!Ty->isIntegerTy() || Ty->isVectorTy())
return;
SmallVector<EVT, 1> ValueVTs;
ComputeValueVTs(*TLI, MF->getDataLayout(), Ty, ValueVTs);
assert(ValueVTs.size() == 1 &&
"PHIs with non-vector integer types should have a single VT.");
EVT IntVT = ValueVTs[0];
if (TLI->getNumRegisters(PN->getContext(), IntVT) != 1)
return;
IntVT = TLI->getTypeToTransformTo(PN->getContext(), IntVT);
unsigned BitWidth = IntVT.getSizeInBits();
unsigned DestReg = ValueMap[PN];
if (!Register::isVirtualRegister(DestReg))
return;
LiveOutRegInfo.grow(DestReg);
LiveOutInfo &DestLOI = LiveOutRegInfo[DestReg];
Value *V = PN->getIncomingValue(0);
if (isa<UndefValue>(V) || isa<ConstantExpr>(V)) {
DestLOI.NumSignBits = 1;
DestLOI.Known = KnownBits(BitWidth);
return;
}
if (ConstantInt *CI = dyn_cast<ConstantInt>(V)) {
APInt Val = CI->getValue().zextOrTrunc(BitWidth);
DestLOI.NumSignBits = Val.getNumSignBits();
DestLOI.Known.Zero = ~Val;
DestLOI.Known.One = Val;
} else {
assert(ValueMap.count(V) && "V should have been placed in ValueMap when its"
"CopyToReg node was created.");
unsigned SrcReg = ValueMap[V];
if (!Register::isVirtualRegister(SrcReg)) {
DestLOI.IsValid = false;
return;
}
const LiveOutInfo *SrcLOI = GetLiveOutRegInfo(SrcReg, BitWidth);
if (!SrcLOI) {
DestLOI.IsValid = false;
return;
}
DestLOI = *SrcLOI;
}
assert(DestLOI.Known.Zero.getBitWidth() == BitWidth &&
DestLOI.Known.One.getBitWidth() == BitWidth &&
"Masks should have the same bit width as the type.");
for (unsigned i = 1, e = PN->getNumIncomingValues(); i != e; ++i) {
Value *V = PN->getIncomingValue(i);
if (isa<UndefValue>(V) || isa<ConstantExpr>(V)) {
DestLOI.NumSignBits = 1;
DestLOI.Known = KnownBits(BitWidth);
return;
}
if (ConstantInt *CI = dyn_cast<ConstantInt>(V)) {
APInt Val = CI->getValue().zextOrTrunc(BitWidth);
DestLOI.NumSignBits = std::min(DestLOI.NumSignBits, Val.getNumSignBits());
DestLOI.Known.Zero &= ~Val;
DestLOI.Known.One &= Val;
continue;
}
assert(ValueMap.count(V) && "V should have been placed in ValueMap when "
"its CopyToReg node was created.");
unsigned SrcReg = ValueMap[V];
if (!Register::isVirtualRegister(SrcReg)) {
DestLOI.IsValid = false;
return;
}
const LiveOutInfo *SrcLOI = GetLiveOutRegInfo(SrcReg, BitWidth);
if (!SrcLOI) {
DestLOI.IsValid = false;
return;
}
DestLOI.NumSignBits = std::min(DestLOI.NumSignBits, SrcLOI->NumSignBits);
DestLOI.Known.Zero &= SrcLOI->Known.Zero;
DestLOI.Known.One &= SrcLOI->Known.One;
}
}
SDValue SelectionDAGBuilder::getValue(const Value *V) {
// If we already have an SDValue for this value, use it. It's important
// to do this first, so that we don't create a CopyFromReg if we already
// have a regular SDValue.
SDValue &N = NodeMap[V];
if (N.getNode()) return N;
// If there's a virtual register allocated and initialized for this
// value, use it.
if (SDValue copyFromReg = getCopyFromRegs(V, V->getType()))
return copyFromReg;
// Otherwise create a new SDValue and remember it.
SDValue Val = getValueImpl(V);
NodeMap[V] = Val;
resolveDanglingDebugInfo(V, Val);
return Val;
}
SDValue SelectionDAGBuilder::getCopyFromRegs(const Value *V, Type *Ty) {
DenseMap<const Value *, unsigned>::iterator It = FuncInfo.ValueMap.find(V);
SDValue Result;
if (It != FuncInfo.ValueMap.end()) {
unsigned InReg = It->second;
RegsForValue RFV(*DAG.getContext(), DAG.getTargetLoweringInfo(),
DAG.getDataLayout(), InReg, Ty,
None); // This is not an ABI copy.
SDValue Chain = DAG.getEntryNode();
Result = RFV.getCopyFromRegs(DAG, FuncInfo, getCurSDLoc(), Chain, nullptr,
V);SelectionDAGBuilder::getCopyFromRegs
resolveDanglingDebugInfo(V, Result);
}
return Result;
}
关于lowering的过程就介绍到这里, 总结:
- lowering的目的是将IR的数据结构转换为DAG, 方便之后指令选择做模式匹配. lowering的过程就是DAG建立的过程.
- lowering分为架构无关与架构相关的部分, 对于架构相关的部分通过TargetLoweringInfo实现.
- lowering是以baisic block为单位的, 跨basic block的信息通过FunctionLoweringInfo实现.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号