【图像处理笔记】图像分割之形态学分水岭
0 引言
迄今为止,我们讨论了基于三个主要概念的分割:边缘检测、阈值处理和区域提取。每种方法都有优点[例如全局阈值处理具有速度优势]和缺点[例如在基于边缘的分割中,需要进行后处理(如边缘连接)]。本节讨论的基于形态学分水岭概念的方法。分水岭分割体现了其他三种方法的许多概念,因此往往会产生更稳定的分割结果,包括连通的分割边界。

1 原理
分水岭方法是一种基于拓扑理论的数学形态学的分割方法,基本思想是把图像看作测地学上的拓扑地貌,将像素点的灰度值视为海拔高度,整个图像就像一张高低起伏的地形图。每个局部极小值及其影响区域称为集水盆,集水盆的边界则形成分水岭。算法的实现过程可以理解为洪水淹没的过程:最低点首先被淹没,然后水逐渐淹没整个山谷;水位升高到一定高度就会溢出,于是在溢出位置修建堤坝;不断提高水位,重复上述过程,直到所有的点全部被淹没;所建立的一系列堤坝就成为分隔各个盆地的分水岭。

分水岭的计算过程是一个迭代标注过程,通过寻找集水盆和分水岭对图像进行分割。经典的分水岭算法分为排序过程和淹没过程两个步骤,首先对每个像素的灰度级从低到高排序,然后在从低到高的淹没过程中,对每一个局部极小值在 h 阶高度的影响域进行判断及标注。
2 cv::watershed的使用
2.1 相关函数
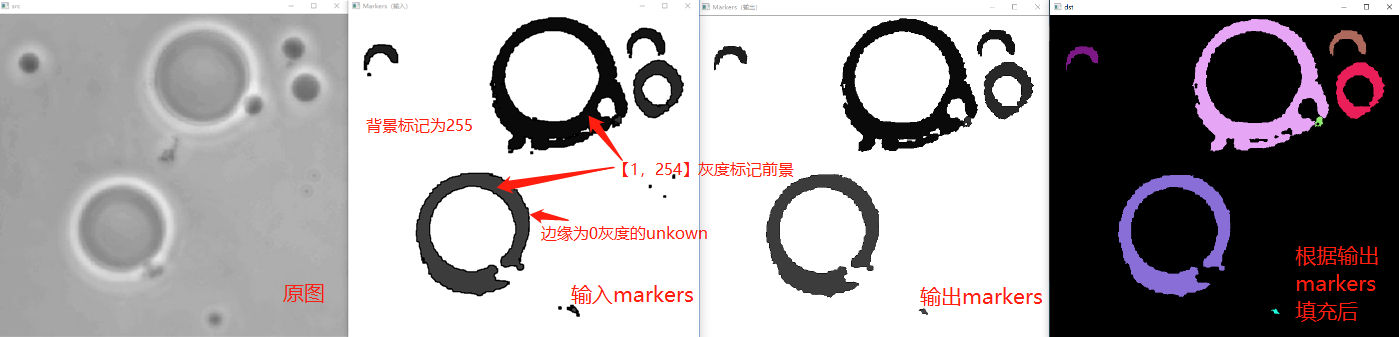
OpenCV提供了函数watershed实现基于标记的分水岭算法。输入图像一般是原图,或者梯度图,由于噪声和梯度的局部不规则性会导致过度分割,控制过度分割的一种方法依据是标记。标记图像为CV_32S 类型,我们预先把一些区域标注好,图像中每个非零像素代表一个标签。对图像中部分像素做标记,表明它的所属区域是已知的。这些标注了的区域称之为种子点。watershed 算法会把这些标记的区域慢慢膨胀填充整个图像。
void watershed( InputArray image, // 输入8位3通道图像。 InputOutputArray markers //输入/输出标记的 32 位单通道图像(地图)。 与 image 具有相同的大小。 );
OpenCV中,函数distanceTransform()用于计算图像中每一个非零点像素与其最近的零点像素之间的距离,输出的是保存每一个非零点与最近零点的距离信息。图像上越亮的点,代表了离零点的距离越远。可以根据距离变换的这个性质,经过简单的运算,用于细化字符的轮廓和查找物体质心(中心)。
void distanceTransform( InputArray src, //输入图像,8-bit 单通道灰度图像 OutputArray dst, //保存了每一个点与最近的零点的距离信息,点越亮离零点越远。 int distanceType,//距离的类型 int maskSize, //距离变换遮罩的大小,通常取 3, 5 int dstType=CV_32F); //输出图像类型
2.2 标记的生成
标记由3部分组成:确定前景、确定背景和未知区域。分为两步:
(1)通过 阈值分割+形态学【例1】,距离变换【例2】,鼠标交互等方法得到这三个区域。
(2)通过 connectedComponents【例1】或 drawContours【例2】标记区域,其中未知区域用0标记,其他区域用大于0的整数标记。
例1 阈值分割+形态学得到三区域→connectedComponents标记区域→分水岭
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main() {
Mat src;
Mat img = imread("./16.tif");
cvtColor(img, src, COLOR_BGR2GRAY);
imshow("src", src);
// 阈值处理
Mat thresh;
threshold(src, thresh, 0, 255, THRESH_OTSU);
// 生成确定背景区域
Mat background;
Mat ele = getStructuringElement(MORPH_RECT, Size(3, 3));
dilate(thresh, background, ele, cv::Point(-1, -1), 2);
bitwise_not(background, background);
// 生成确定前景区域,并利用连通区域标记
Mat foreground;
morphologyEx(thresh, foreground, MORPH_OPEN, ele, cv::Point(-1, -1), 2);
int n = connectedComponents(foreground, foreground, 8, CV_32S);// 此时确定前景大于0,其余为0
// 生成标记图
Mat markers = foreground;
markers.setTo(255, background);// 将确定背景设为255,其余为0的不动,即为unkown
Mat markers8u;
markers.convertTo(markers8u, CV_8U, 10);//灰度值*10使得差异变得明显
imshow("Markers(输入)", markers8u);
// 分水岭算法标注目标的轮廓
watershed(img, markers);// 轮廓由-1表示
markers.convertTo(markers8u, CV_8U, 10);//灰度值*10使得差异变得明显
imshow("Markers(输出)", markers8u);
// 后处理(颜色填充)
Mat mark;
markers.convertTo(mark, CV_8U);//转换后-1变成0
bitwise_not(mark, mark);
vector<Vec3b> colors;
for (size_t i = 0; i < n; i++)
{
int b = theRNG().uniform(0, 256);
int g = theRNG().uniform(0, 256);
int r = theRNG().uniform(0, 256);
colors.push_back(Vec3b((uchar)b, (uchar)g, (uchar)r));
}
Mat dst = Mat::zeros(markers.size(), CV_8UC3);
for (int i = 0; i < markers.rows; i++)
{
for (int j = 0; j < markers.cols; j++)
{
int index = markers.at<int>(i, j);
if (index > 0 && index <= static_cast<int>(n))
dst.at<Vec3b>(i, j) = colors[index - 1];
}
}
imshow("dst", dst);
waitKey(0);
return 0;
}
例2 梯度+距离变换得到三区域→drawContours标记区域→分水岭
分水岭分割的主要应用之一是,从背景中提取出接近一致的(团状)目标。由变化较小的灰度表征区域有较小的梯度之。因此,在实践中,我们常常看到分水岭分割应用到梯度图像,而不是应用到图像本身。在这一表述中,汇水盆地的区域极小值与对应感兴趣目标的梯度的极小值密切相关。
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
int main() {
Mat src_bgr = imread("./18.png");
imshow("src", src_bgr);
Mat mask, src_gray;
cvtColor(src_bgr, src_gray, COLOR_BGR2GRAY);
// 1.梯度+距离变换得到前景区域
Mat blurImg;
blur(src_gray, blurImg, Size(7, 7));
Mat gx, gy, gxy;
Sobel(blurImg, gx, CV_16S, 1, 0, 3);
Sobel(blurImg, gy, CV_16S, 0, 1, 3);
convertScaleAbs(gx, gx);
convertScaleAbs(gy, gy);
gxy = gx + gy;
Mat binImg;
threshold(gxy, binImg, 110, 255, THRESH_BINARY);
Mat ele = getStructuringElement(MORPH_RECT, Size(3, 3));
morphologyEx(binImg, binImg, MORPH_OPEN, ele);
morphologyEx(binImg, binImg, MORPH_CLOSE, ele);
floodFill(binImg, Point(0, 0), Scalar(255));
bitwise_not(binImg, binImg);
Mat dist, binImg1;
distanceTransform(binImg, dist, DIST_L2, 3);
normalize(dist, dist, 0, 1.0, NORM_MINMAX);
imshow("dist", dist);
threshold(dist, binImg1, 0.4, 1.0, THRESH_BINARY);
binImg1.convertTo(binImg1, CV_8U, 255);
imshow("binImg1", binImg1);
// 2.确定背景区域
Mat markers = Mat::zeros(binImg1.size(), CV_32S);
circle(markers, Point(5, 5), 3, Scalar(255), -1);
inRange(src_gray, Scalar(0), Scalar(15), mask);
// 3.生成标记图
vector<vector<Point>> contours;
findContours(binImg1, contours, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
for (size_t i = 0; i < contours.size(); i++)
{
drawContours(markers, contours, static_cast<int>(i), Scalar(static_cast<int>(i) + 1), -1);
}
markers.setTo(255, mask);
Mat markers8u;
markers.convertTo(markers8u, CV_8U, 10);
imshow("Markers1", markers8u);
// 4.分水岭
watershed(src_bgr, markers);
// 5.后处理
Mat mark;
markers.convertTo(mark, CV_8U);
bitwise_not(mark, mark);
markers.convertTo(markers8u, CV_8U, 10);
imshow("Markers2", markers8u);
vector<Vec3b> colors;
for (size_t i = 0; i < contours.size(); i++)
{
int b = theRNG().uniform(0, 256);
int g = theRNG().uniform(0, 256);
int r = theRNG().uniform(0, 256);
colors.push_back(Vec3b((uchar)b, (uchar)g, (uchar)r));
}
Mat dst = Mat::zeros(markers.size(), CV_8UC3);
for (int i = 0; i < markers.rows; i++)
{
for (int j = 0; j < markers.cols; j++)
{
int index = markers.at<int>(i, j);
if (index > 0 && index <= static_cast<int>(contours.size()))
dst.at<Vec3b>(i, j) = colors[index - 1];
}
}
imshow("dst", dst);
waitKey(0);
return 0;
}


3 watershed源码
3.1 大致流程
1. 对输入的标记图mask的边界(1像素)置为-1,即边界不处理
2. 初始阶段:遍历mask中所有点,将标记为0且四邻域中有标记大于0的点(也就是标记点外面的一圈点)进队。有256个队列,进哪个队列呢?分两种情况:(1)四邻域中只有一个标记大于0的点,计算该点和这个邻域点的梯度(差值),若梯度为250,就进第250个队列。由于输入的原图是三通道的,算梯度要算三个通道的梯度,选最大的;(2)四邻域中不止一个标记大于0的点,选择梯度最小的点进队。
3. 经过上一步,得到256个队列,有些队列是空的,有些不是。定位到第一个非空的队列,遍历队列中的点。比较这个点的四邻域,分三种情况:(1)四邻域中有一个以上的邻域标记大于0(且它们标记不同),该点为分水岭;(2)四邻域中只有一个邻域标记大于0,那该点和这个邻域点标记相同,即被这个邻域点扩充(3)邻域中没有大于0的标记点,这是不可能的。因为标记点要么是初始种子点,要么是初始阶段延伸的种子点的邻接点,即该点一定存在一个邻接点是标记点
4. 在上一步中,情况(1)的分水岭点被pop出队列,且在mask中被标记为-1;情况(2)的点为新标记点,被pop出队列,同时查看其四邻域点,有没有没处理的点。没处理的点被push进队列(相当于又往外一圈),进哪个队列呢?和上面一样,根据梯度t。再次进入第3步,直到所有队列为空。有所不同的是,初始阶段从第0个队列开始找非空队列,而之后从min(t, active_queue)开始。也就是说,如果第二圈的点梯度都很大,就从第active_queue开始找非空队列。如果第二圈的梯度都很小,那就从最小的梯队开始找非空队列。
3.2 源码注解
注解来自OpenCV 源码中分水岭算法 watershed 函数源码注解,对比OpenCV 2.4.9,OpenCV 4.5中Mat取代了CvMat,cv::Mat是一个类(Class),而CvMat是一个Struct,获取元素的写法不同,如下:
Mat test = (Mat_<int>(3, 3) << 1, 2, 3, 4, 5, 6, 7, 8, 9 );
int* p = test.ptr<int>();//获取元素的写法不同,之前是test->data.i
int istep = test.step/sizeof(int);// 步长 = 一行字节数 / sizeof(像素数据类型)
for (int i = 0; i < test.rows; i++) {// 逐行扫描
for (int j = 0; j < test.rows; j++) {// 逐列扫描
if (p[j] == 5) {
//四邻域
cout << p[j-1] << endl;//左
cout << p[j+1] << endl;//右
cout << p[j-istep] << endl;//上
cout << p[j+istep] << endl;//下
}
}
p += istep;
}
源码注解
#include "precomp.hpp"
// 结点,用于存储原始图img中像素的偏移量和输出图mask中像素的偏移量
typedef struct CvWSNode
{
struct CvWSNode* next;
int mask_ofs;
int img_ofs;
}
CvWSNode;
// 队列,用于存储结点 CvWSNode
typedef struct CvWSQueue
{
CvWSNode* first;
CvWSNode* last;
}
CvWSQueue;
// 分配空间
static CvWSNode*
icvAllocWSNodes( CvMemStorage* storage )
{
CvWSNode* n = 0;
int i, count = (storage->block_size - sizeof(CvMemBlock))/sizeof(*n) - 1;
n = (CvWSNode*)cvMemStorageAlloc( storage, count*sizeof(*n) );
for( i = 0; i < count-1; i++ )
n[i].next = n + i + 1;
n[count-1].next = 0;
return n;
}
CV_IMPL void
cvWatershed( const CvArr* srcarr, CvArr* dstarr )
{
const int IN_QUEUE = -2; // 加入到队列q中的点定义为 -2
const int WSHED = -1; // “分水岭”在mask中定义为 -1
const int NQ = 256; // 队列的数量 256,其实是对应灰度的数量
cv::Ptr<CvMemStorage> storage;
CvMat sstub, *src;
CvMat dstub, *dst;
CvSize size;
CvWSNode* free_node = 0, *node;
CvWSQueue q[NQ]; // 长度为256的CvWSQueue数组,注意数组中每个元素都是一个队列,队列中每个元素是一个节点
int active_queue; // 指明当前处理的队列,q[active_queue]
int i, j;
int db, dg, dr;
int* mask; // 指向标记图像的指针
uchar* img; // 指向原始图像的指针
int mstep, istep; // mstep是mask对应的一行像素数(不是字节数),istep是img对应的一行像素数
int subs_tab[513];
// MAX(a,b) = b + MAX(a-b,0) 取最大值
#define ws_max(a,b) ((b) + subs_tab[(a)-(b)+NQ])
// MIN(a,b) = a - MAX(a-b,0) 取最小值
#define ws_min(a,b) ((a) - subs_tab[(a)-(b)+NQ])
// 进队操作
#define ws_push(idx,mofs,iofs) \
{ \
if( !free_node ) \
free_node = icvAllocWSNodes( storage );\
node = free_node; \
free_node = free_node->next;\
node->next = 0; \
node->mask_ofs = mofs; \
node->img_ofs = iofs; \
if( q[idx].last ) \
q[idx].last->next=node; \
else \
q[idx].first = node; \
q[idx].last = node; \
}
// 出队操作
#define ws_pop(idx,mofs,iofs) \
{ \
node = q[idx].first; \
q[idx].first = node->next; \
if( !node->next ) \
q[idx].last = 0; \
node->next = free_node; \
free_node = node; \
mofs = node->mask_ofs; \
iofs = node->img_ofs; \
}
// 求出 ptr1 和 ptr2 指向的像素 r,g,b 差值的最大值
#define c_diff(ptr1,ptr2,diff) \
{ \
db = abs((ptr1)[0] - (ptr2)[0]);\
dg = abs((ptr1)[1] - (ptr2)[1]);\
dr = abs((ptr1)[2] - (ptr2)[2]);\
diff = ws_max(db,dg); \
diff = ws_max(diff,dr); \
assert( 0 <= diff && diff <= 255 ); \
}
src = cvGetMat( srcarr, &sstub );
dst = cvGetMat( dstarr, &dstub );
// 对参数做检查,要求图像src的类型是8UC3,dst的类型是32SC1,src和dst size相同
if( CV_MAT_TYPE(src->type) != CV_8UC3 )
CV_Error( CV_StsUnsupportedFormat, "Only 8-bit, 3-channel input images are supported" );
if( CV_MAT_TYPE(dst->type) != CV_32SC1 )
CV_Error( CV_StsUnsupportedFormat,
"Only 32-bit, 1-channel output images are supported" );
if( !CV_ARE_SIZES_EQ( src, dst ))
CV_Error( CV_StsUnmatchedSizes, "The input and output images must have the same size" );
size = cvGetMatSize(src); // 获取图像的size
storage = cvCreateMemStorage();
// 步长 = 一行字节数 / sizeof(像素数据类型)
istep = src->step; // img是uchar型, sizeof(uchar) = 1,所以忽略除数
img = src->data.ptr; // 获取 uchar类型指针
mstep = dst->step / sizeof(mask[0]); // mask是int(32SC1)型,sizeof(mask[0]) = 4
mask = dst->data.i; // 获取 int类型指针
memset( q, 0, NQ*sizeof(q[0]) ); // 初始化队列q
for( i = 0; i < 256; i++ )
subs_tab[i] = 0;
for( i = 256; i <= 512; i++ )
subs_tab[i] = i - 256;
// draw a pixel-wide border of dummy "watershed" (i.e. boundary) pixels
// 把图像四个边的像素画成分水岭
// mask的首行和末行画成分水岭
for( j = 0; j < size.width; j++ )
mask[j] = mask[j + mstep*(size.height-1)] = WSHED;
// initial phase: put all the neighbor pixels of each marker to the ordered queue -
// determine the initial boundaries of the basins
// 初始阶段:把每个标记的所有邻居像素放到有序队列中去,以确定聚水盆的初始边界
// 即每个标记(种子,全为正值,1,2,3...)都是一个初始聚水盆,标记的周围一圈的邻居像素就是聚水盆的初始边界
// 这里用的是一种逆向思维,不是找标记点,而是判断每一个点是否为标记点的邻居,若是,则该点也被扩充为与标记点同类型的标记点
// 若是多个标记点的邻居,选择梯度最小的标记点的类型,作为该点的标记点类型
for( i = 1; i < size.height-1; i++ )
{
img += istep; mask += mstep; // 逐行扫描
mask[0] = mask[size.width-1] = WSHED; // 每一行的首列和末列画成分水岭,加上前面的首行和末行,mask被分水岭方框围起来
for( j = 1; j < size.width-1; j++ ) // 逐列
{
int* m = mask + j; // mask的每个像素
if( m[0] < 0 ) m[0] = 0; // 该点若为负值,先置为零(初始状态下除了四边是分水岭(-1)其余点不应该存在负值?)
if( m[0] == 0 && (m[-1] > 0 || m[1] > 0 || m[-mstep] > 0 || m[mstep] > 0) ) // 若该点为非标记点(0),且四邻域存在标记点(>0)
{
// 求出原图中该点到有标记点的四邻域中,梯度值最小(idx)方向的点,将该点和对应的最小梯度值放入q[idex]队列中
// 两个像素的r,g,b 三个通道中相差最大的值作为像素间的梯度值
uchar* ptr = img + j*3;
int idx = 256, t;
if( m[-1] > 0 )
c_diff( ptr, ptr - 3, idx );
if( m[1] > 0 )
{
c_diff( ptr, ptr + 3, t );
idx = ws_min( idx, t );
}
if( m[-mstep] > 0 )
{
c_diff( ptr, ptr - istep, t );
idx = ws_min( idx, t );
}
if( m[mstep] > 0 )
{
c_diff( ptr, ptr + istep, t );
idx = ws_min( idx, t );
}
assert( 0 <= idx && idx <= 255 );
ws_push( idx, i*mstep + j, i*istep + j*3 ); // 将该点在img和mask中的坐标(一维表示)存储在q[idx]队列中
m[0] = IN_QUEUE; // 在mask中标记该点已入队
}
}
}
// find the first non-empty queue
// 定位到第一个非空的队列
for( i = 0; i < NQ; i++ )
if( q[i].first )
break;
// if there is no markers, exit immediately
// 若i=256,说明数组q中所有队列为空
if( i == NQ )
return;
active_queue = i;
img = src->data.ptr;
mask = dst->data.i;
// recursively fill the basins
// 递归地填满聚水盆
for(;;)
{
int mofs, iofs; // 将二维图像线性化后图像像素的坐标 mask_offset 和 img_offset 的缩写
int lab = 0, t;
int* m;
uchar* ptr;
// 如果这个灰度上的队列处理完了,就继续找下一个非空队列
if( q[active_queue].first == 0 )
{
for( i = active_queue+1; i < NQ; i++ )
if( q[i].first )
break;
if( i == NQ )
break;
active_queue = i;
}
ws_pop( active_queue, mofs, iofs ); // 从q[active_queue]队列中取出一个结点数据
// 找到这个结点记录的img和mask中的像素点,比较该点在mask中的邻居点
// 邻居点中如果有标记点:该点与邻居点的标记类型不同,则该点为分水岭;该点与邻居点标记类型相同,则该点不变
// 如果有非标记点:将非标记点扩充为标记点
m = mask + mofs;
ptr = img + iofs;
t = m[-1];
if( t > 0 ) lab = t;
t = m[1];
if( t > 0 )
{
if( lab == 0 ) lab = t;
else if( t != lab ) lab = WSHED; // 如果该像素点的标记类型和邻居像素标记类型都 > 0 且不同,则为分水岭
}
t = m[-mstep];
if( t > 0 )
{
if( lab == 0 ) lab = t;
else if( t != lab ) lab = WSHED;
}
t = m[mstep];
if( t > 0 )
{
if( lab == 0 ) lab = t;
else if( t != lab ) lab = WSHED;
}
// 因为标记点要么是初始种子点,要么是初始阶段延伸的种子点的邻接点
// 该点一定存在一个邻接点是标记点,所以lab一定会赋值一次,不为 0
assert( lab != 0 );
// 若lab > 0 ,则该点被周围的标记点扩充;若lab = -1(WSHED),则该点定义为分水岭,继续下一个循环
m[0] = lab;
if( lab == WSHED )
continue;
// lab > 0 的情况,确定该点为标记点,且邻居点中存在未标记点的情况,将未标记点扩充为标记点
if( m[-1] == 0 )
{
c_diff( ptr, ptr - 3, t ); // 计算梯度t
ws_push( t, mofs - 1, iofs - 3 ); // 将m[-1]这一未标记的点扩充为标记点,进队
active_queue = ws_min( active_queue, t ); // 判断,若t < 当前处理的队列active_queue值,则下一次循环中处理q[t]队列,否则继续处理当前队列
m[-1] = IN_QUEUE;
}
if( m[1] == 0 )
{
c_diff( ptr, ptr + 3, t );
ws_push( t, mofs + 1, iofs + 3 );
active_queue = ws_min( active_queue, t );
m[1] = IN_QUEUE;
}
if( m[-mstep] == 0 )
{
c_diff( ptr, ptr - istep, t );
ws_push( t, mofs - mstep, iofs - istep );
active_queue = ws_min( active_queue, t );
m[-mstep] = IN_QUEUE;
}
if( m[mstep] == 0 )
{
c_diff( ptr, ptr + istep, t );
ws_push( t, mofs + mstep, iofs + istep );
active_queue = ws_min( active_queue, t );
m[mstep] = IN_QUEUE;
}
}
}
void cv::watershed( InputArray _src, InputOutputArray markers )
{
Mat src = _src.getMat();
CvMat c_src = _src.getMat(), c_markers = markers.getMat();
cvWatershed( &c_src, &c_markers );
}
参考
1. 冈萨雷斯《数字图像处理(第四版)》Chapter 10(所有图片可在链接中下载)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号