【论文笔记】R-CNN系列之论文理解
【深度学习】总目录
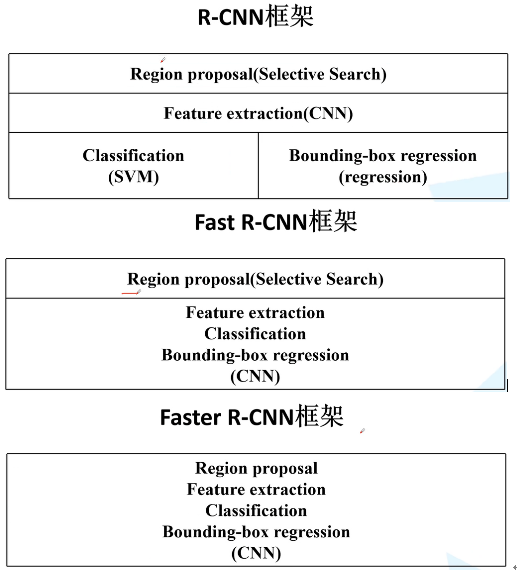
RCNN全称region with CNN features,即用CNN提取出Region Proposals中的featues。RCNN系列论文(R-CNN,Fast R-CNN,Faster R-CNN)是使用深度学习进行物体检测的鼻祖论文,其中Fast R-CNN 以及Faster R-CNN都是沿袭RCNN的思路。
- RCNN《Rich feature hierarchies for accurate object detection and semantic segmentation》R-CNN是RGB大神2014年提出的目标检测模型,采用CNN网络提取图像特征,对于VOC 2012上的最佳结果,该算法的平均精度(mAP)提高了30%以上。
- Fast R-CNN《Fast R-CNN》受SPPnet启发,RGB大神在2015年发表了Fast R-CNN,通过共享计算大幅提高目标检测速度。 在同样的最大规模网络上,Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。 在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。
- Faster R-CNN《Faster R-CNN: T owards Real-Time Object Detection with Region Proposal Networks》,2016年何恺明提出了RPN来提取候选框(取代了selective search),使得目标检测速率大大提高。
R-CNN
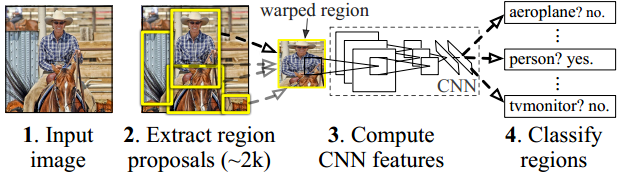
1. 用selective search在测试图片上提取2000个候选区域
2. 对候选区域缩放,经过标准卷积神经网络获得固定维度输出
3. 训练SVM分类器进行分类,边界回归
selective search
使用过分割方法将图像分成小区域。在此之后,观察现有的区域。之后以最高概率合并这两个区域。重复此步骤,直到所有图像合并为一个区域位置。注意,在此处的合并规则与RCNN是相同的,优先合并以下四种区域: 颜色(颜色直方图)相近的; 纹理(梯度直方图)相近的; 合并后总面积小的。最后,所有已经存在的区域都被输出,并生成候选区域。
Fast R-CNN
RCNN的缺点&Fast R-CNN的改进
- 训练分多步: region proposal也要单独用selective search的方式获得,要fine tuning一个预训练的网络,然后针对每个类别都训练一个SVM分类器,最后还要用regressors对bounding-box进行回归。
改进:在Fast-RCNN中,把bbox回归放进了网络内部,与分类合并成为了一个多任务模型,两个任务能够共享卷积特征,并相互促进。
- 训练费空间和时间: 图片中提取出来的特征要写入磁盘,再去训练SVM和回归。
改进:在Fast-RCNN中,把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
- 目标检测很慢: 一张图像内候选框之间大量重叠,提取特征操作冗余,用VGG16检测要47s一张图(在GPU上)。
改进:在Fast-RCNN中,将整张图片归一化送入神经网络,这些候选框还是经过SS提取,再经过一个ROI层统一映射到最后一层特征图上
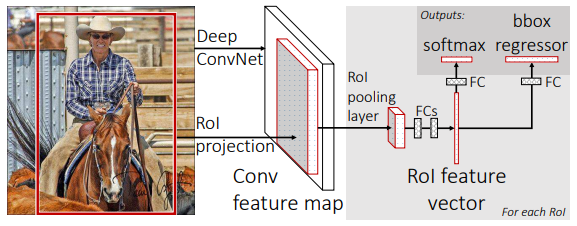
1. 将一整张图片经过卷积和池化的处理得到feature map
2. 对于每一个区域提议,pooling layer从中提取出固定长度的vector
3. 将特征向量喂入全连接层,分为两个同级输出层:一个经过softmax层输出概率,一个输出bbox的位置。
Faster R-CNN
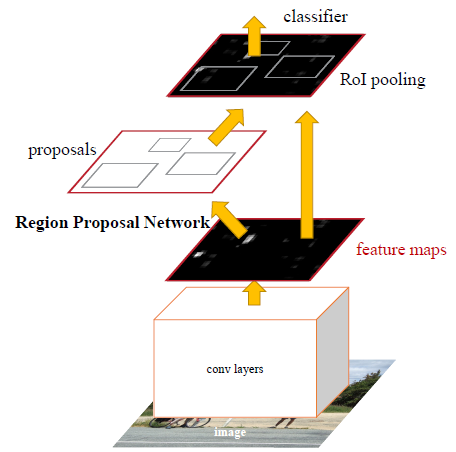
1. 将图像输入网络得到相应的特征图
2. 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
3. 将每个特征矩阵通过ROI pooling层缩放到7*7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
其中1、3两步就是Fast R-CNN,所以Faster R-CNN = RPN + Fast R-CNN
Region Proposal Networks区域生成网络(RPN)
在卷积后的feature map上滑动,每一个位置生成1*256的向量,再经过全连接层生成2k个目标概率和4k个边界框回归参数。其中,k对应的是k个anchor box,2k是指每个anchor box是前景和背景的概率,每个anchor box还会产生4个边界框回归参数,因此k个anchor box产生4k个参数。256是指特征图的深度(channel),如果使用的是VGG16,那深度为512。
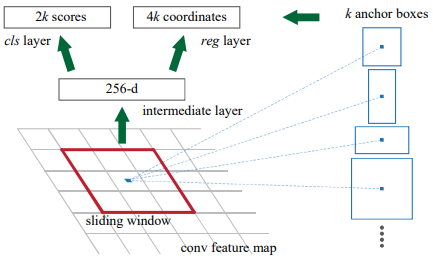
(1)计算出3*3滑动窗口中心点对应原始图像上的中心点:假设输入的原图为w*h,特征图为W*H,那么x方向上的步距为sx=w/W,y方向上的步距为sy=h/H,特征图(2,2)位置的点对应原图(2*sx,2*sy)。
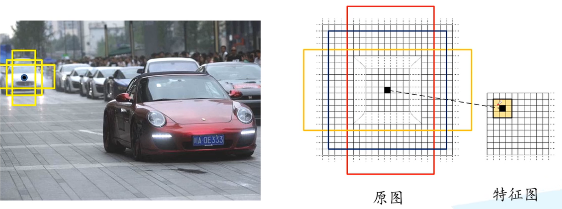
(2)计算出k个anchor box:默认情况下,我们使用3个尺度和3个比例,在每个滑动点产生9个可能的候选窗口:三种面积{1282,2562,5122}×三种比例{1:1,1:2,2:1}。这些候选窗口称为anchors。512*512的候选窗口比VGG的感受野228还要大,用小的感受野去预测大的目标的边界框是有可能的,比如看到物体的一部分也能猜到物体的位置。(感受野就是特征图上3*3的区域对应卷积池化之前原图上的区域)
(3)筛选anchor :对于一张1000*600*3的图像,经过特征提取网络后大概是60*40的大小,在每个位置上滑动,生成9个anchor,一共是60*40*9(20k)个anchor,忽略跨越边界的anchor后,剩下6k个anchor。RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IOU设为0.7,这样剩下2k个候选框。
随机采样256个anchor计算损失函数,正负样本比为1:1,如果正样本少于128个,用负样本填充。(和之前的分类不同,分类将整张图作为输入,而目标识别将anchor作为输入,所以对anchor的正负样本的比例有一定的要求)。
我们分配正标签前景给两类anchor:(1)与某个ground truth有最高的IoU重叠的anchor(也许不到0.7)(2)与任意ground truth有大于0.7的IoU交叠的anchor。注意:一个ground truth可能分配正标签给多个anchor。
我们分配负标签(背景)给与所有ground truth的IoU比率都低于0.3的anchor。非正非负的anchor对训练目标没有任何作用,由此输出维度为(2*9)18,一共18维。
Multi-task loss多任务损失函数
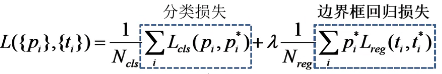
其中,pi为第i个anchor的预测值,pi*是真实标签,ti是预测框的回归参数,ti*是真实框的回归参数,Ncls表示一个mini-batch中的所有样本数量为256,Nreg表示anchor位置的个数(约2400)。
- RPN分类损失
根据原文的理解,全连接层输出2k个score,即k个anchor,每个anchor有两个概率,背景概率和前景概率,Lcls应该是Softmax+Cross Entropy(softmax输出,所有输出概率和为1)。但是这是一个关于背景和目标的分类问题,是二分类问题。二分类问题我们可以输出一通道,做sigmoid后用二值交叉熵损失Binary Cross Entropy计算损失:
Lcls = -[pi* logpi + (1-pi*) log(1-pi)]
此时分类的全连接层输出k个score
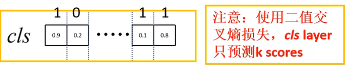
上图中 Lcls = (-log0.9)+(-log0.2)+...+(-log0.1)+(-log0.2)。
- Faster RCNN分类损失
在Fast R-CNN中预测值的shape=[num_anchors, num_classes],其中num_classes=k+1,表示属于k类和背景的概率 p=(p0,p1,..,pk),是用softmax得到的概率分布。标签值的shape=[num_anchors,],每个值在[0, k]之间。
Lcls = -log pi
其中,pi表示第i个anchor预测为真实标签的概率。比如口罩识别,有face和face_mask两类,输出预测值shape为[num_anchors, 3],当某个样本真实标签为1时,取出预测值对应样本对应于1类别的概率。
- 边界框回归损失

其中,pi*当为正样本是为1,当为负样本时为0。ti表示第i个anchor的回归参数,ti*表示第i个anchor对应的GTBox的回归参数。
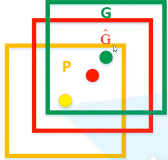
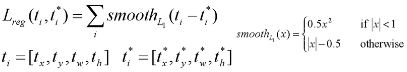 下图中,黄框为候选框,Px,Py,Pw,Ph分别为候选框的中心x,y坐标,以及宽高。红框是预测的边界框,绿框是GTBox。(也是说预测的回归参数是以固定候选框为基准的偏移缩放量)。ti*是已知G(Gx,Gy,Gw,Gh)和P(Px,Py,Pw,Ph),反推得到的。
下图中,黄框为候选框,Px,Py,Pw,Ph分别为候选框的中心x,y坐标,以及宽高。红框是预测的边界框,绿框是GTBox。(也是说预测的回归参数是以固定候选框为基准的偏移缩放量)。ti*是已知G(Gx,Gy,Gw,Gh)和P(Px,Py,Pw,Ph),反推得到的。
ROI pooling layer
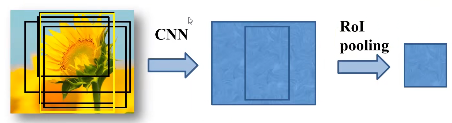
将区域提议对应的feature map转换成小的固定大小(H*W)的feature map,不限制输入map的尺寸。
ROI pooling layer的输入有两项:
(1)提取特征的网络的最后一个feature map;
(2)一个表示图片中所有ROI的N*5的矩阵,其中N表示 ROI的数目,5表示图像index,和坐标参数(x,y,h,w) 。坐标的参考系不是针对feature map这张图的,而是针对原图的。
如何实现?
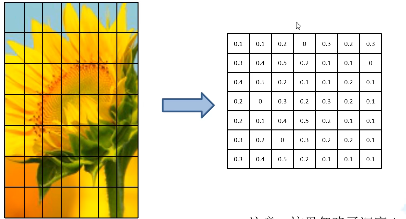
比如左边这个特征矩阵(此处忽略了深度),将它划分为7*7的49等份,对其中每一个区域最大池化得到7*7的特征矩阵。无论输入是多少,都可以缩放到7*7的尺寸。
参考文献:
1. Faster RCNN理论合集(视频)
3. R-CNN中的SVM理解
5. Python3《机器学习实战》学习笔记(八):支持向量机原理篇之手撕线性SVM
6. RCNN 论文阅读记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号