【最近公共祖先】 LCA 详解(倍增,trajan算法)
一、简单介绍 (Lowest Common Ancestors)
-
在一棵二叉搜索树中,任意两个结点的最近公共祖先,是指以这两个结点为后代的深度最大的那个结点。需要通过比较两个结点的值,来判断它们在二叉搜索树中的位置关系。如果两个结点的值都小于当前结点的值,那么它们一定在当前结点的左子树中;如果两个结点的值都大于当前结点的值,那么它们一定在当前结点的右子树中;如果一个结点的值小于当前结点的值,另一个结点的值大于当前结点的值,那么当前结点就是它们的最近公共祖先。如果两个结点中有一个等于当前结点,那么当前结点也是它们的最近公共祖先。
-
对于有根树 \(T\) 的两个结点 \(u 、v\) ,最近公共祖先 LCA (T,u,v) 表示一个结点\(x\),满足 \(x\) 是 \(u\) 和 \(v\) 的祖先且 \(x\) 的深度尽可能大。在这里,一个节点也可以是它自己的祖先。
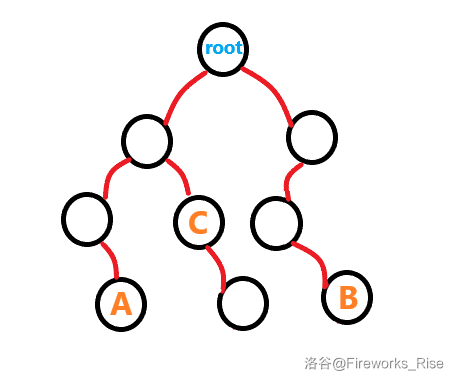
蒟蒻第一次画树,希望谅解
二、代码实现
离线算法(离线)
①.插入函数
用邻接表存读入的一棵树,代码实现较好理解,解决代码:
struct Edge {
int v,n;
}edge[N<<1]; //创建邻接表
int head[N],idx; //邻接表存储树
void connec(int x,int y) {
edge[++idx].v=y;
edge[idx].nxt=head[x];
head[x]=idx;1
}
②.并查集查找函数
这里也不用多讲,就是普通并查集查找的使用:
如需深入了解,可以参考本博客用户的并查集文章....
int fa[N]; //并查集数组
for(int i=1;i<=n;i++) fa[i]=i; //并查集初始化
int findp(int x) { //并查集查找根节点
if(x==fa[x]) return x;
return fa[x]=findp(fa[x]);
}
③.trajan 算法
-
\(vis_{i}\) 表示 \(i\) 号节点是否被访问过。
-
\(fa_{r}\) 表示 \(r\) 的祖先节点。
-
\(res_i\) 表示第 \(i\) 个询问的答案。
-
看回上面开头的图,打个比例,如果我们要寻找 \(A ,C\)的最近公共祖先,
按照 dfs 的先序遍历易知 \(A\) 肯定是先被查询标记到的,并且 \(fa_A\) 在返回的过程中,指向了父亲节点的序号。 -
提前进行对于每个询问点的处理。
typedef pair<int,int>pll; //第一个元素为节点编号,第二个元素为询问编号
vector <pll> vec[N]; //存储下来所有的询问 vec[x]:代表和x节点有关的询问,即第vec[x].second
for(int i=1;i<=m;i++) { //把 m次询问存下来
int x,y;
scanf("%d%d",&x,&y);
vec[x].push_back({y,i});
vec[y].push_back({x,i});
}
-
接下来,我们访问到 \(C\) 节点,这时 \(A,C\) 两个节点都被访问过了,我们只需找到关于询问 \(C\) 节点的所有询问,\(findp(y)\) 查询该节点(例子即 \(A\) )的祖先,即 \(A,C\) 的最近公共祖先。
-
注意,由于 \(root\) 的左节点还未返回,所以 \(fa_{root_lson}=root_lson\) 即自己还指向自己,自己为自己的父亲。
void trajan(int u) {
vis[u]=1; //标记访问过
for(int i=head[u];i;i=edge[i].nxt) {
int j=edge[i].v;
if(!vis[j]) {
trajan(j);
fa[j]=u;
}
}
for(int i=0;i<vec[u].size();i++) {
int y=vec[u][i].first;
int id_=vec[u][i].second;
if(vis[y]) res[id_]=findp(y);
}
}
Code
#include<bits/stdc++.h>
using namespace std;
const int N=5e5+10;
typedef pair<int,int>pll; //第一个元素为节点编号,第二个元素为询问编号
struct Edge {
int v,n;
}edge[N<<1];
int head[N],idx; //邻接表存储树
int fa[N]; //并查集数组
int n,m,root; //分别表示节点个数,询问个数,根节点标号
vector <pll> vec[N]; //存储下来所有的询问 vec[x]:代表和x节点有关的询问,即第vec[x].second
int res[N]; //结果,把第i次询问的结果放进res[i]里面
bool vis[N]; //标记数组
void connec(int x,int y) {
edge[++idx].v=y;
edge[idx].nxt=head[x];
head[x]=idx;
}
int findp(int x) { //并查集查找根节点
if(x==fa[x]) return x;
return fa[x]=findp(fa[x]);
}
void trajan(int u) {
vis[u]=1; //标记访问过
for(int i=head[u];i;i=edge[i].nxt) {
int j=edge[i].v;
if(!vis[j]) {
trajan(j);
fa[j]=u;
}
}
for(int i=0;i<vec[u].size();i++) {
int y=vec[u][i].first;
int id_=vec[u][i].second;
if(vis[y]) res[id_]=findp(y);
}
}
int main() {
scanf("%d%d%d",&n,&m,&root);
for(int i=1;i<n;i++) { //读入一棵树,用邻接表储存起来
int x,y;
scanf("%d%d",&x,&y);
connec(x,y);
connec(y,x);
}
for(int i=1;i<=n;i++) fa[i]=i; //并查集初始化
for(int i=1;i<=m;i++) { //把 m次询问存下来
int x,y;
scanf("%d%d",&x,&y);
vec[x].push_back({y,i});
vec[y].push_back({x,i});
}
trajan(root); //调用trajan算法
for(int i=1;i<=m;i++)
printf("%d\n",res[i]);
return 0;
}
算法小总结
-
tarjan 的算法是离线算法,其中用到并查集,关键是 dfs 的主循环比较重要。
-
时间复杂度 :时间复杂度为 \(O(n+Q)\) ,\(n\) 为数据规模,\(Q\) 为询问个数。
-
由于用了 vector 动态数组,所以在时间运行效率上会低一点,但可以优化空间,相较于下面讲述的倍增算法,相当于空间换时间。
倍增法(在线)
I.插入函数
无论如何,我们还是要用到邻接表,废话不多说:
void connec(int x,int y) {
edge[++idx].v=y;
edge[idx].nxt=head[x];
head[x]=idx;1
}
II.dfs 函数
\(dep_{u}\) 表示当前节点 \(u\) 到树根节点的深度(距离);
\(f_{u,k}\) 表示节点 \(u\) 向根节点跳 \(1^k\) 个节点(保持在树的范围之内)。
- 注意:在此的跳跃 \(for\) 从小到大。
void dfs(int u,int fa) {
dep[u]=dep[fa]+1;
for(int i=head[u];i;i=edge[i].nxt) { //遍历节点u的所有孩子
int j=edge[i].v;
if(j==fa) continue;
f[j][0]=u;
for(int k=1;(1<<k)<=dep[u];k++)
f[j][k]=f[f[j][k-1]][k-1]; //计算f数组 它最多到跟节点
dfs(j,u); //继续往下搜
}
}
III. LCA查找函数
①.为了 \(x\) 和 \(y\) 的跳跃距可以同步跳到他们的最近公共祖先,我们先让两个节点跳到同样的深度,程序为了实现简便,使 \(x\) 号节点在 \(y\) 号节点的深度之下。
if(dep[x]<dep[y]) swap(x,y);
②.如果 \(x=y\) , 所以 \(y\) 是 \(x\) 的祖先,直接返回 \(y\)。
if(x==y) return y;
③.否则 \(x\) 和 \(y\) 跳到其最近公共祖先的下一层。
if(f[x][i]!=f[y][i]) {
x=f[x][i];
y=f[y][i];
}
④.最后只用再跳一步即 \(2^0\) 就到它们的最近公共祖先。
return f[x][0];
- 注意:在此的跳跃 \(for\) 从大到小。
- 分析原因:我们此处的原理类似于二进制(
蒟蒻的理解) - 如 \(9\) 的二进制为 \((1001)_B\) ,如果我们从小到大选择,则会变成 \(0111\),值为 \(7\),最后导致错误。
- 同样的我们跳 \(9\) 个节点,先跳 \(8\) 个,再跳 \(1\) 个。
int lca(int x,int y) {
if(dep[x]<dep[y]) swap(x,y); //让x成为深度最大的那个节点
for(int i=19;i>=0;i--)
if(dep[f[x][i]]>=dep[y]) x=f[x][i]; //用倍增让x跳到和y同一层
if(x==y) return y;
for(int i=19;i>=0;i--) { //如果x跳过头了,就换一个小的i重跳
if(f[x][i]!=f[y][i]) { //目标x和y跳到其最近公共祖先的下一层
x=f[x][i];
y=f[y][i];
}
}
return f[x][0]; //返回答案
}
Code 2
#include<bits/stdc++.h>
using namespace std;
const int N=5e5+10;
struct Edge {
int v,nxt;
}edge[N<<1];
int n,m,x,y,root; //分别表示节点个数,询问个数,根节点编号
int head[N],idx; //邻接表储存数
int f[N][20]; //f(i,j)号节点往上跳2^j步的节点编号
int dep[N]; //节点i的深度 规定根节点的深度为 1
void connec(int x,int y) {
edge[++idx].v=y;
edge[idx].nxt=head[x];
head[x]=idx;
}
void dfs(int u,int fa) {
dep[u]=dep[fa]+1;
for(int i=head[u];i;i=edge[i].nxt) { //遍历节点u的所有孩子
int j=edge[i].v;
if(j==fa) continue;
f[j][0]=u;
for(int k=1;(1<<k)<=dep[u];k++)
f[j][k]=f[f[j][k-1]][k-1]; //计算f数组 它最多到跟节点
dfs(j,u); //继续往下搜
}
}
int lca(int x,int y) {
if(dep[x]<dep[y]) swap(x,y); //让x成为深度最大的那个节点
for(int i=19;i>=0;i--)
if(dep[f[x][i]]>=dep[y]) x=f[x][i]; //用倍增让x跳到和y同一层
if(x==y) return y;
for(int i=19;i>=0;i--) { //如果x跳过头了,就换一个小的i重跳
if(f[x][i]!=f[y][i]) { //目标x和y跳到其最近公共祖先的下一层
x=f[x][i];
y=f[y][i];
}
}
return f[x][0]; //返回答案
}
int main() {
scanf("%d%d%d",&n,&m,&root);
for(int i=1;i<n;i++) { //读入一棵树,用邻接表储存起来
scanf("%d%d",&x,&y);
connec(x,y);
connec(y,x);
}
dfs(root,0); //计算每个节点的深度
for(int i=1;i<=m;i++) {
scanf("%d%d",&x,&y);
int tmp=lca(x,y); //计算两个节点的lca
printf("%d\n",tmp);
}
return 0;
}
算法小总结
- 倍增算法是在线算法。
- 时间复杂度 :时间复杂度为 \(O(nlogn)\) ,\(n\) 为数据规模。
- 相较于刚刚所说的的trajan 算法,当然在运行效率上有很大优势。
- 建议多使用倍增算法,当忘了怎么打或爆空间下,才退而使用 trajan 算法。
总结
用途:
-
一、两个树上节点的最近公共祖先。
-
二、计算一个树上两个节点(\(u \Rightarrow v\))之间的最短距离。
-
三、判断在树上是否能通过一条简单路径(即在树上找一条路径且不重复走一条边),使其经过给定点集中的所有点。
-
四、再一棵带权树上,通过枚举中间公共节点,找出两点之间的路径的极(最大、小)权值和。
题库
此处有配套练习,可以先浅浅练练 ,建议可以参考一下我的题单 洛谷【最近公共祖先】 ID:970993

 浙公网安备 33010602011771号
浙公网安备 33010602011771号