
Python 装饰器解析(一)
装饰器用于在源码中“标记”函数,以增强函数的行为。
我们先来看下面的例子,现有一个求和函数add,现在要求统计函数执行的时长
def add(a, b):
print(a+b)最low的做法:
def add(a, b):
start = time.time()
print(a + b)
time.sleep(2)#模拟耗时操作
long = time.time() - start
print(f'共耗时{long}秒。')这样做可以实现需求,但是对原函数做了修改,不仅增加了耦合性,扩展和复用也变得难以实现。
假如再增加一个记录日志的功能以及对程序中所有的函数都进行时长统计,想想就可怕。
那好办啊,我们可以这样写:
def timer(func,*args):
start = time.time()
func(*args)
time.sleep(2)#模拟耗时操作
long = time.time() - start
print(f'共耗时{long}秒。')
timer(add,1,2)这样没有改变原函数吧?是的,但是改变了函数调用方式,每个调用add的地方都需要修改,这么做只是转嫁了矛盾而已。
又不能修改原函数,又不能改变调用方式,那该怎么办呢?装饰器是时候登场了。
在写装饰器之前先了解两个概念:高阶函数和闭包
高阶函数:接受函数为入参,或者把函数作为结果返回的函数。后者称之为嵌套函数。
闭包:指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。概念比较晦涩,简单来说就是嵌套函数引用了外层函数的变量。
嵌套函数和闭包可以理解为是同时存在的,上面的timer已经是高阶函数了,它接受函数作为入参,我们把它改造为嵌套函数实现装饰器:
def timer(func):
def wrapper(*args, **kwargs):
start = time.time()
func(*args, **kwargs) #此处拿到了被装饰的函数func
time.sleep(2)#模拟耗时操作
long = time.time() - start
print(f'共耗时{long}秒。')
return wrapper #返回内层函数的引用
@timer
def add(a, b):
print(a+b)
add(1, 2) #正常调用addtimer被我们改造成了装饰器,它接受被装饰函数为入参,返回内部嵌套函数的引用(注意:此处并未执行函数),内部嵌套函数wrapper持有被装饰函数的引用即func。
“@”是Python的语法糖,它的作用类似于:
add = timer(add) #此处返回的是timer.<locals>.wrapper函数引用
add(1, 2)装饰器的加载到执行的流程:
模块加载 ->> 遇到@,执行timer函数,传入add函数 ->> 生成timer.<locals>.wrapper函数并命名为add,其实是覆盖了原同名函数 ->> 调用add(1, 2) ->> 去执行timer.<locals>.wrapper(1, 2) ->> wrapper内部持有原add函数引用(func),调用func(1, 2) ->>继续执行完wrapper函数
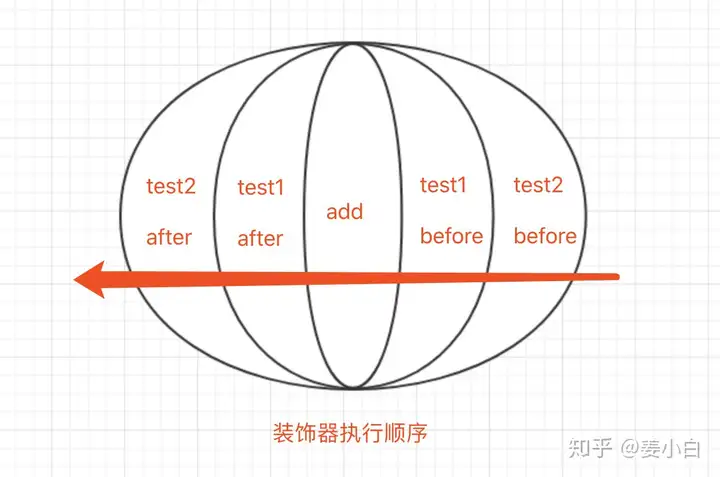
问:如果存在多个装饰器,执行顺序是什么样的呢?看下面的代码
def test1(func):
def wrapper(*args, **kwargs):
print('before test1 ...')
func(*args, **kwargs)
print('after test1 ...')
return wrapper #返回内层函数的引用
def test2(func):
def wrapper(*args, **kwargs):
print('before test2 ...')
func(*args, **kwargs)
print('after test2 ...')
return wrapper #返回内层函数的引用
@test2
@test1
def add(a, b):
print(a+b)
add(1, 2) #正常调用add
输出:
before test2 ...
before test1 ...
3
after test1 ...
after test2 ...如果把add函数比喻为圆心,test1为近心端,test2为远心端,那么执行的过程就好比一颗子弹从远心端沿着直径的轨迹穿过圆心再从远心端穿出。
再形象一点,可以把装饰器想象成洋葱,由近及远对函数进行层层包裹,执行的时候就是拿一把刀从一侧开始切,直到切到另一侧结束。
理解了装饰器之后,我们可以思考一下,带参数的装饰器该怎么写呢?
我们知道装饰器最终返回的是嵌套函数的引用,只要记住这点,装饰器就任由我们发挥了。写一个带参数的装饰器:
def auth(permission):
def _auth(func):
def wrapper(*args, **kwargs):
print(f"验证权限[{permission}]...")
func(*args, **kwargs)
print("执行完毕...")
return wrapper
return _auth
@auth("add")
def add(a, b):
"""
求和运算
"""
print(a + b)
add(1, 2) # 正常调用add
输出:
验证权限[add]...
3
执行完毕...有些同学要问了,经过装饰器之后的函数还是原来的函数吗?原来的函数肯定还存在的,只不过真正调用的是装饰后生成的新函数。
那岂不是打破了“不能修改原函数”的规则?
是的,看下面的示例:
print(add)
print(add.__name__)
print(add.__doc__)
输出:
<function auth.<locals>._auth.<locals>.wrapper at 0x10c871400>
wrapper
None为了消除装饰器对原函数的影响,我们需要伪装成原函数,拥有原函数的属性,看起来就像是同一个人一样。
functools为我们提供了便捷的方式,只需这样:
def auth(permission):
def _auth(func):
@functools.wraps(func) # 注意此处
def wrapper(*args, **kwargs):
print(f"验证权限[{permission}]...")
func(*args, **kwargs)
print("执行完毕...")
return wrapper
return _auth
@auth("add")
def add(a, b):
"""
求和运算
"""
print(a + b)
print(add)
print(add.__name__)
print(add.__doc__)
输出:
<function add at 0x10997c488>
add
求和运算functools.wraps对我们的装饰器函数进行了装饰之后,add表面上看起来还是add。
functools.wraps内部通过partial和update_wrapper对函数进行再加工,将原始被装饰函数(add)的属性拷贝给装饰器函数(wrapper)。内部实现原理我们下文分解。
总结:
1、装饰器原则:1)不能修改原函数 2)不能修改调用方式
2、装饰器通过嵌套函数和闭包实现
3、装饰器执行顺序:洋葱法则
4、装饰器通过语法糖“@”修饰
5、谨记装饰器返回的是持有被装饰函数引用的闭包函数的引用这条原则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号