用 Redis 做一个可靠的延迟队列
抢先体验
本文的完整代码实现在hdt3213/delayqueue,可以直接使用 go get 安装:
go get github.com/hdt3213/delayqueue
使用起来非常简单:
package main
import (
"github.com/go-redis/redis/v8"
"github.com/hdt3213/delayqueue"
"strconv"
"time"
)
func main() {
// 创建 redis 连接,可以复用已有连接
redisCli := redis.NewClient(&redis.Options{
Addr: "127.0.0.1:6379",
})
// 创建延时队列, NewQueue 的三个参数分别为:
// queueName: 队列名称,是队列的唯一标识。名称相同的 DelayQueue 对象会操作同一个队列
// redisCli: redis 连接
// callback: 处理消息的回调函数, callback 返回 true 表示成功消费,返回 false 会重新投递消息
queue := delayqueue.NewQueue("example-queue", redisCli, func(payload string) bool {
return true
}).WithConcurrent(4) // 设置消费者的并发数
// 发送延时消息
for i := 0; i < 10; i++ {
// SendDelayMsg 的参数为: 消息内容,延时时长,可选项
// 与它类似的 SendScheduleMsg 可以在指定时间点投递消息
err := queue.SendDelayMsg(strconv.Itoa(i), time.Hour, delayqueue.WithRetryCount(3))
if err != nil {
panic(err)
}
}
// 启动消费协程
// DelayQueue 可以在多台服务器上同时启动多个消费协程消费同一个队列,每条消息最多会被一个消费者拉取到
done := queue.StartConsume()
// 阻塞等待消费协程退出。在 StartConsume 和 <-done 中间可以做点别的事情,比如整个 http.ListenAndServe 啥的
<-done
}
背景
我们在工作中经常遇到等待一段时间后再执行某些任务的需求,比如:
- 若订单创建 15 分钟后仍未支付,需要关闭订单并释放库存。
- 用户设置了一个 “下午 2 点提醒我去做核酸” 的待办事项。
- 当回调失败后等待 30 秒然后重试, 第二次失败后等待 1 分钟再次重试, 第三次失败后等待 10 分钟……
这些业务对延时任务通常有下列几条要求:
- 数据要持久化,服务崩溃或重启不能丢失任务。
- 支持重试以尽量保证成功。生产环境不可避免的会出现超时或处理失败等情况,需要重试机制来保证成功率。
- 定时尽量精确。用户设置了下午 2 点的提醒,肯定无法容忍 2 点 5 分才收到推送。
- 任务量可能会很大。
一些常见的延时任务实现方案存在着或大或小缺陷,不适合在生产环境使用:
- 定时扫表
- redis 的过期监听
- 非持久化的时间轮
最简单的定时扫表是将要执行的任务和执行时间写入数据库中,然后每隔一段时间去扫描一次数据库中已到预定时间但未开始执行的任务。
这种方案简单可靠,但是存在两个问题:一是受限于数据库有限的吞吐量通常几分钟才会扫一次表,这使得定时任务可能比预定时间晚几分钟执行;二是在数据量较大时可能出现数据库变慢甚至宕机的问题。
也有很多同学使用 Redis 的过期通知来实现定时任务,这种方案存在两个问题:
一是不保证精度,通知可能比过期时间晚几分钟后才发出。
Redis 自动过期的实现方式是:定时任务离线扫描并删除部分过期键;在访问键时惰性检查是否过期并删除过期键。也就是说 Redis 中有一些键已经过期却未被删除,自然也不会发送通知。实验表明过期通知晚于设定时间数分钟发出的情况也十分常见(见参考资料:请勿过度依赖Redis的过期监听)。
Redis 官方手册的 keyspace-notifications: timing-of-expired-events 一节中已经明确指出:
Basically expired events are generated when the Redis server deletes the key and not when the time to live theoretically reaches the value of zero
二是键空间通知采用的是发送即忘(fire and forget)策略。如果因为连接断开或服务重启等原因错过了过期通知,那么服务恢复后也没有重试的机会了。
基于上述两点原因,笔者强烈建议不要在生产环境使用 Redis 的过期通知实现定时任务。
也有一些同学使用时间轮或者 java utils 的 DelayQueue 等内存数据结构来实现定时任务,这些方案的问题在于服务重启后任务会丢失,不够可靠。
笔者认为最合适的解决方案是使用 Pulsa、RocketMQ 等专业消息队列的延时投递功能,但是引入新的中间件通常存在各种技术或非技术方面的麻烦。
Redis 作为广泛使用的中间件自然是降低接入成本的首选,社区中也不乏 Redisson DelayedQueue 等优秀的延时队列实现。
遗憾的是 Go 语言社区并没有类似的库, 所以我们打算使用类似的思路实现一个延迟队列,希望能够帮到有需要的同学。
实现原理
使用 Redis 实现延时队列的核心是将待执行的任务放入一个有序集合(SortedSet)结构中,将消息 ID 作为集合的 member、 执行时间转换为时间戳作为 score。
定时调用 zrangebyscore 命令将已到执行时间的消息从 SortedSet 移动到 List 或者 Stream 结构中,消费者从 List 或者 Stream 中拉取消息即可。
我们将延时消息首先放入名为 pending 的 SortedSet 中,等待到达执行时间:
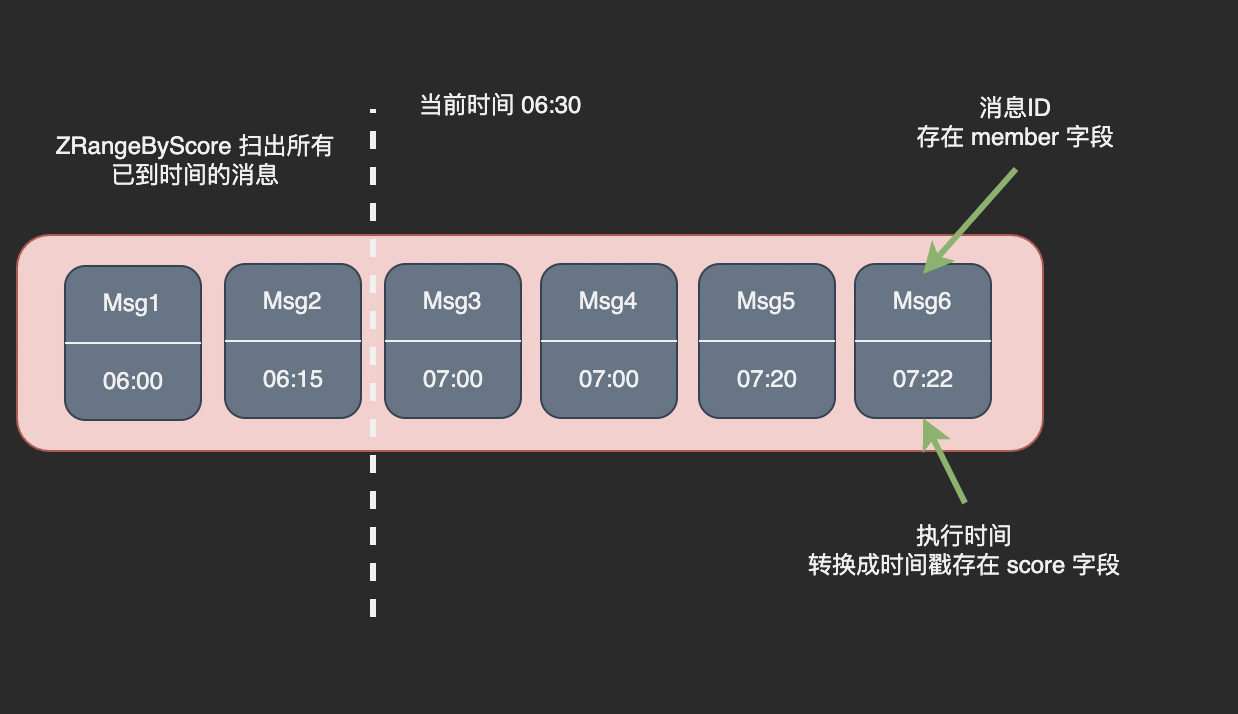
上图中的时间有所夸张,实际情况下我们通常每秒扫描一次。执行时间和实际误差不超过1s, 不会出现超过预定时间 30 分钟才执行的情况。
我们定义了一个名为 ready 的 List 数据结构,用于存放已到投递时间的消息。 每秒扫描一次 pending 并将其中中已到投递时间的消息转移到 ready 中:
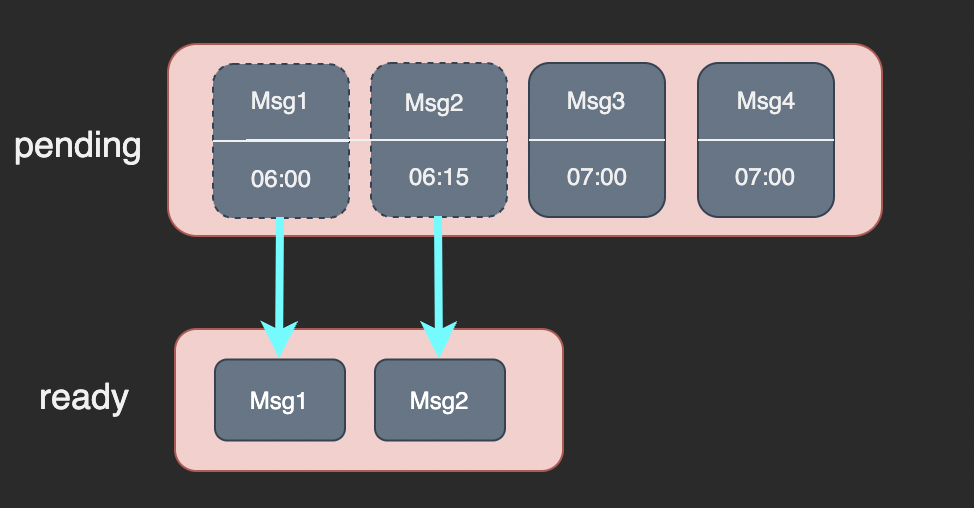
随后消费者从 ready 中取出消息进行处理。因为消费者拉取和处理消息的过程中可能出现超时或错误需要重试,所以我们不能直接从 ready 中删除被拉取的消息。
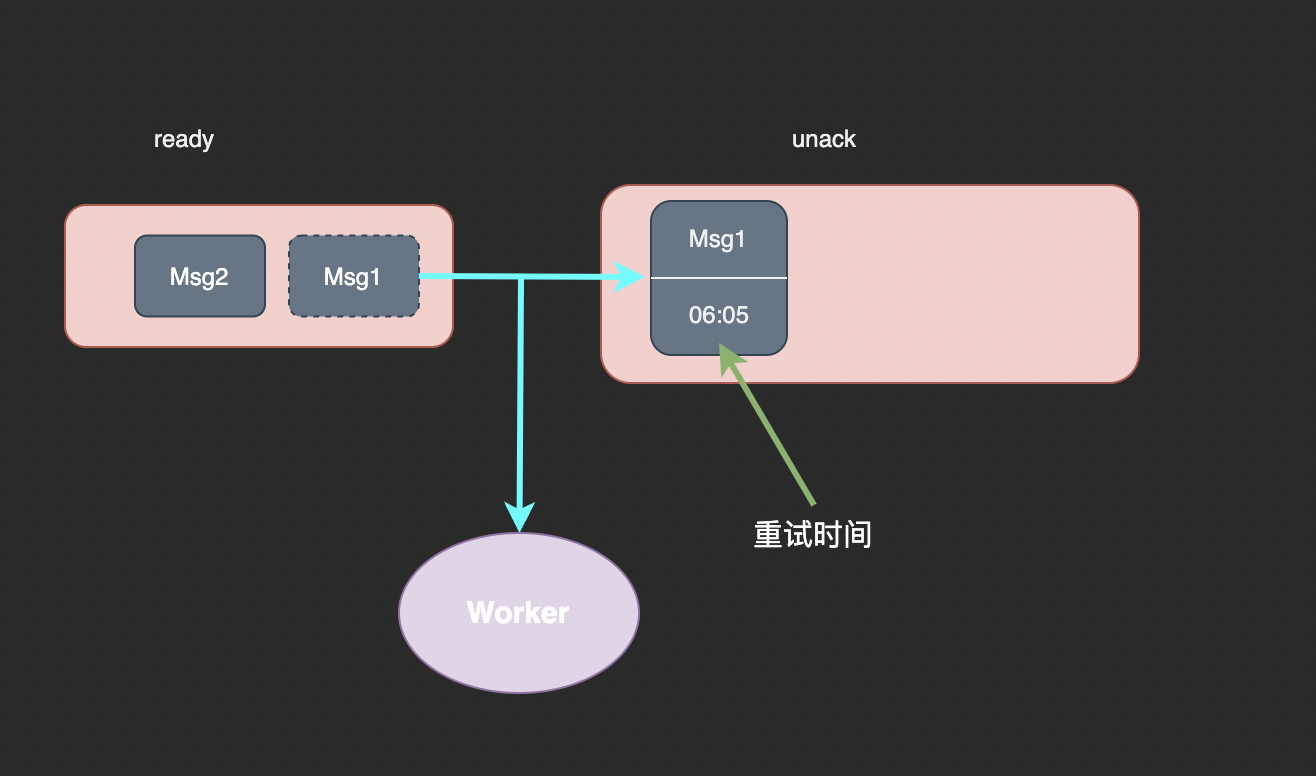
为此我们定义了一个 unack 结构来存储处理中的消息。unack 是与 pending 类似的有序集合结构,它的 member 是消息 ID、score 是重试时间。若已经到了重试时间还未确认成功处理,我们会认为这条消息处理失败了需要重试。
我们实现了 ready to unack 操作,它将 read 中最新一条消息取出放入 unack 中并将消息发送给消费者,这个操作与 RpopLpush 命令非常类似:
我们会定期扫描有序集合 unack,将其中未到重试次数上限的消息转移到 retry 中,已到重试次数上限的转移到 garbage 中等待后续清理。
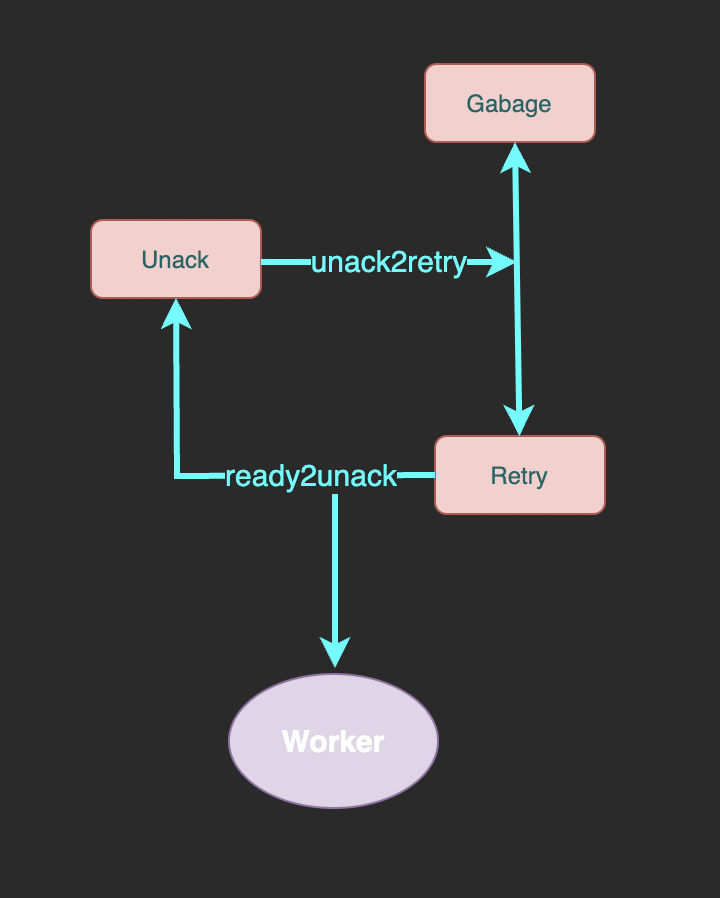
合起来看整个队列的流程是这样的:
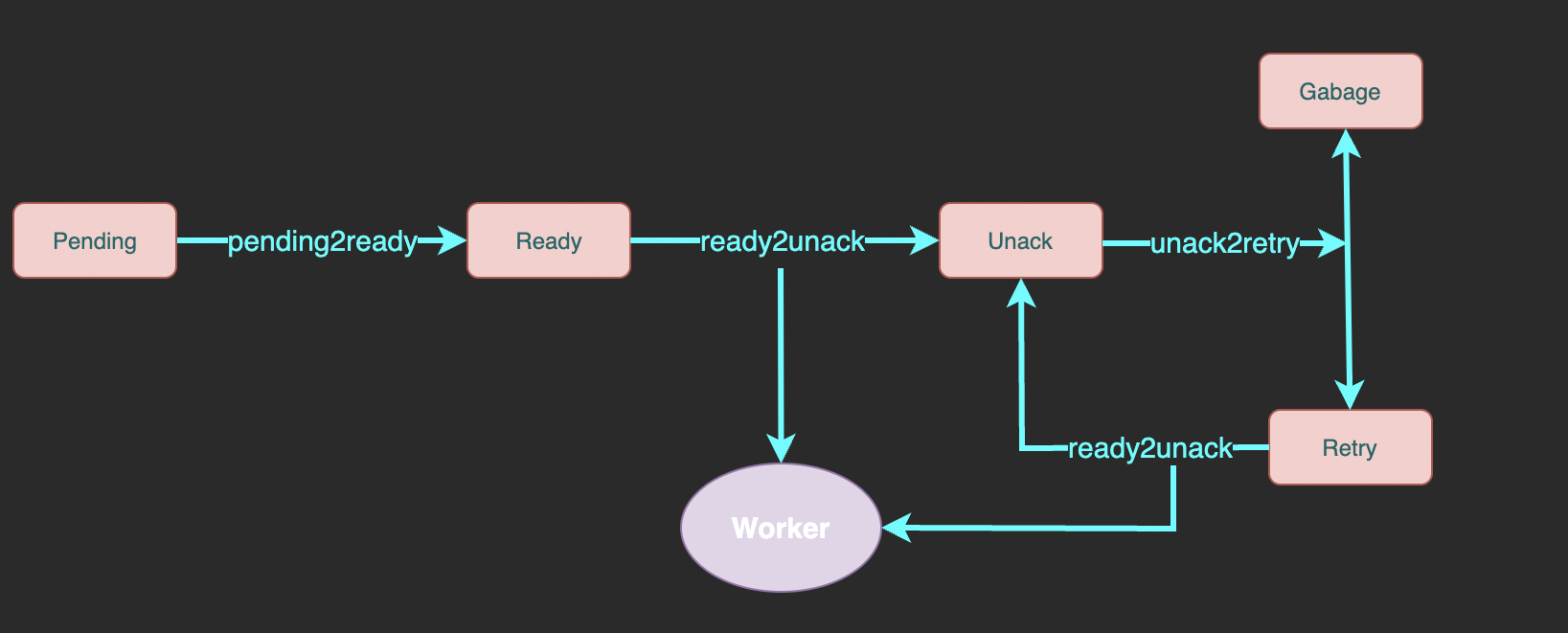
整个消息队列中一共有 7 个 Redis 数据结构:
- pending: 有序集合类型,存储未到投递时间的消息。 member 为消息 ID、score 为投递时间。
- ready: 列表类型,存储已到投递时间的消息。element 为消息 ID。
- unack: 有序集合类型, 存储已投递但未确认成功消费的消息 ID。 member 为消息 ID、score 为处理超时时间, 超出这个时间还未 ack 的消息会被重试。
- retry: 列表类型,存储处理超时后等待重试的消息 ID。element 为消息 ID。
- garbage: 集合类型,用于暂存已达重试上限的消息 ID。后面介绍 unack2retry 时会介绍为什么需要 garbage 结构。
- msgKey: 为了避免两条内容完全相同的消息造成意外的影响,我们将每条消息放到一个字符串类型的键中,并分配一个 UUID 作为它的唯一标识。其它数据结构中只存储 UUID 而不存储完整的消息内容。每个 msg 拥有一个独立的 key 而不是将所有消息放到一个哈希表中是为了利用 TTL 机制避免泄漏。
- retryCountKey: 哈希表类型,键为消息 ID, 值为剩余的重试次数。
如上文所述整个消息队列中一共涉及 6 个操作:
- send: 发送一条新消息。首先存储消息内容和重试次数,并将消息 ID 放入 pending 中。
- pending2ready: 将已到投递时间的消息从 pending 移动到 ready 中
- ready2unack: 将一条等待投递的消息从 ready (或 retry) 移动到 unack 中,并把消息发送给消费者。
- unack2retry: 将 unack 中未到重试次数上限的消息转移到 retry 中,已到重试次数上限的转移到 garbage 中等待后续清理。
- ack: 从 unack 中删除处理成功的消息并清理它的 msgKey 和 retryCount 数据。
- garbageCollect: 清理已到最大重试次数的消息。
我们希望 delayqueue 可以在分布式系统中正常使用,也就是说可以在多台服务器上同时向一个队列投递消息或者消费同一个队列中的消息。
多台服务器上并行工作要求 pending2ready、ready2unack、unack2retry 三个关键操作必须是原子性的,否则同一条消息可能同时出现在两个数据结构中或者被消费多次。
Redis 支持事务和 lua 脚本两种原子性机制,由于这三个操作中存在循环、判断等难以用事务实现的逻辑,所以我们选择 lua 脚本来实现它们。
send 由两个步骤组成:第一步写入 msgKey 和 retryCount,第二步将消息 ID 放入 pending 中。在消息进入 pending 前其它线程不会访问到这条消息,因此无需保证两个步骤的原子性,可以直接使用 Redis 命令实现。 ack 和 garbageCollect 首先将消息从队列中移除,然后清理 msgKey 和 retryCount, 同理不需要使用 lua 脚本。
在多台服务器上并发运行时,上面提到的 pending2ready、ready2unack、unack2retry 三个关键操作实际执行顺序基本不可能是简单的 1、2、3、1、2、3 ,而是像 1、2、2、1、3、2 这样毫无规律的序列。所以需要将它们设计为没有前后依赖关系,允许乱序执行的三个操作,只要保证一个操作不会被另一个操作打断(即原子性)队列就可以正常运行。
源码分析
希望了解 DelayQueue 具体实现的同学可以继续阅读下面的源码分析部分。
pending2ReadyScript
pending2ReadyScript 使用 zrangebyscore 扫描已到投递时间的消息ID并把它们移动到 ready 中:
-- keys: pendingKey, readyKey
-- argv: currentTime
local msgs = redis.call('ZRangeByScore', KEYS[1], '0', ARGV[1]) -- 从 pending key 中找出已到投递时间的消息
if (#msgs == 0) then return end
local args2 = {'LPush', KEYS[2]} -- 将他们放入 ready key 中
for _,v in ipairs(msgs) do
table.insert(args2, v)
end
redis.call(unpack(args2))
redis.call('ZRemRangeByScore', KEYS[1], '0', ARGV[1]) -- 从 pending key 中删除已投递的消息
ready2UnackScript
ready2UnackScript 从 ready 或者 retry 中取出一条消息发送给消费者并放入 unack 中,类似于 RPopLPush:
-- keys: readyKey/retryKey, unackKey
-- argv: retryTime
local msg = redis.call('RPop', KEYS[1])
if (not msg) then return end
redis.call('ZAdd', KEYS[2], ARGV[1], msg)
return msg
unack2RetryScript
unack2RetryScript 从 retry 中找出所有处理超时消息,剩余重试次数大于0的移动到 retry 中, 已到最大重试次数的移动到 garbage 中:
-- keys: unackKey, retryCountKey, retryKey, garbageKey
-- argv: currentTime
local msgs = redis.call('ZRangeByScore', KEYS[1], '0', ARGV[1]) -- 找到已到重试时间的消息
if (#msgs == 0) then return end
local retryCounts = redis.call('HMGet', KEYS[2], unpack(msgs)) -- 查询剩余重试次数
for i,v in ipairs(retryCounts) do
local k = msgs[i]
if tonumber(v) > 0 then -- 剩余次数大于 0
redis.call("HIncrBy", KEYS[2], k, -1) -- 减少剩余重试次数
redis.call("LPush", KEYS[3], k) -- 添加到 retry key 中
else -- 剩余重试次数为 0
redis.call("HDel", KEYS[2], k) -- 删除重试次数记录
redis.call("SAdd", KEYS[4], k) -- 添加到垃圾桶,等待后续删除
end
end
redis.call('ZRemRangeByScore', KEYS[1], '0', ARGV[1]) -- 将已处理的消息从 unack key 中删除
因为 redis 要求 lua 脚本必须在执行前在 KEYS 参数中声明自己要访问的 key, 而我们将每个 msg 有一个独立的 key,我们在执行 unack2RetryScript 之前是不知道哪些 msg key 需要被删除。所以 lua 脚本只将需要删除的消息记在 garbage key 中,脚本执行完后再通过 del 命令将他们删除:
func (q *DelayQueue) garbageCollect() error {
ctx := context.Background()
msgIds, err := q.redisCli.SMembers(ctx, q.garbageKey).Result()
if err != nil {
return fmt.Errorf("smembers failed: %v", err)
}
if len(msgIds) == 0 {
return nil
}
// allow concurrent clean
msgKeys := make([]string, 0, len(msgIds))
for _, idStr := range msgIds {
msgKeys = append(msgKeys, q.genMsgKey(idStr))
}
err = q.redisCli.Del(ctx, msgKeys...).Err()
if err != nil && err != redis.Nil {
return fmt.Errorf("del msgs failed: %v", err)
}
err = q.redisCli.SRem(ctx, q.garbageKey, msgIds).Err()
if err != nil && err != redis.Nil {
return fmt.Errorf("remove from garbage key failed: %v", err)
}
return nil
}
之前提到的 lua 脚本都是原子性执行的,不会有其它命令插入其中。 gc 函数由 3 条 redis 命令组成,在执行过程中可能会有其它命令插入执行过程中,不过考虑到一条消息进入垃圾回收流程之后不会复活所以不需要保证 3 条命令原子性。
ack
ack 只需要将消息彻底删除即可:
func (q *DelayQueue) ack(idStr string) error {
ctx := context.Background()
err := q.redisCli.ZRem(ctx, q.unAckKey, idStr).Err()
if err != nil {
return fmt.Errorf("remove from unack failed: %v", err)
}
// msg key has ttl, ignore result of delete
_ = q.redisCli.Del(ctx, q.genMsgKey(idStr)).Err()
q.redisCli.HDel(ctx, q.retryCountKey, idStr)
return nil
}
否定确认只需要将 unack key 中消息的重试时间改为现在,随后执行的 unack2RetryScript 会立即将它移动到 retry key
func (q *DelayQueue) nack(idStr string) error {
ctx := context.Background()
// update retry time as now, unack2Retry will move it to retry immediately
err := q.redisCli.ZAdd(ctx, q.unAckKey, &redis.Z{
Member: idStr,
Score: float64(time.Now().Unix()),
}).Err()
if err != nil {
return fmt.Errorf("negative ack failed: %v", err)
}
return nil
}
consume
消息队列的核心逻辑是每秒执行一次的 consume 函数,它负责调用上述脚本将消息转移到正确的集合中并回调 consumer 来消费消息:
func (q *DelayQueue) consume() error {
// 执行 pending2ready,将已到时间的消息转移到 ready
err := q.pending2Ready()
if err != nil {
return err
}
// 循环调用 ready2Unack 拉取消息进行消费
ids := make([]string, 0, q.fetchLimit)
for {
idStr, err := q.ready2Unack()
if err == redis.Nil { // consumed all
break
}
if err != nil {
return err
}
ids = append(ids, idStr)
if q.fetchLimit > 0 && len(ids) >= int(q.fetchLimit) {
break
}
}
if len(ids) > 0 {
q.batchCallback(ids)
}
// 将 nack 或超时的消息放入重试队列
err = q.unack2Retry()
if err != nil {
return err
}
// 清理已达到最大重试次数的消息
err = q.garbageCollect()
if err != nil {
return err
}
// 消费重试队列
ids = make([]string, 0, q.fetchLimit)
for {
idStr, err := q.retry2Unack()
if err == redis.Nil { // consumed all
break
}
if err != nil {
return err
}
ids = append(ids, idStr)
if q.fetchLimit > 0 && len(ids) >= int(q.fetchLimit) {
break
}
}
if len(ids) > 0 {
q.batchCallback(ids)
}
return nil
}
至此一个简单可靠的延时队列就做好了,现在就开始试用吧😘😋
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号