Linux 系统监控工具 atop
系统监控是运维工作中重要的一环,本文以 atop 工具为例来介绍系统的重要监控项。
atop可以使用yum或apt包管理器进行安装。atop man page 中详细说明了 atop 中各监控项含义及atop命令用法。
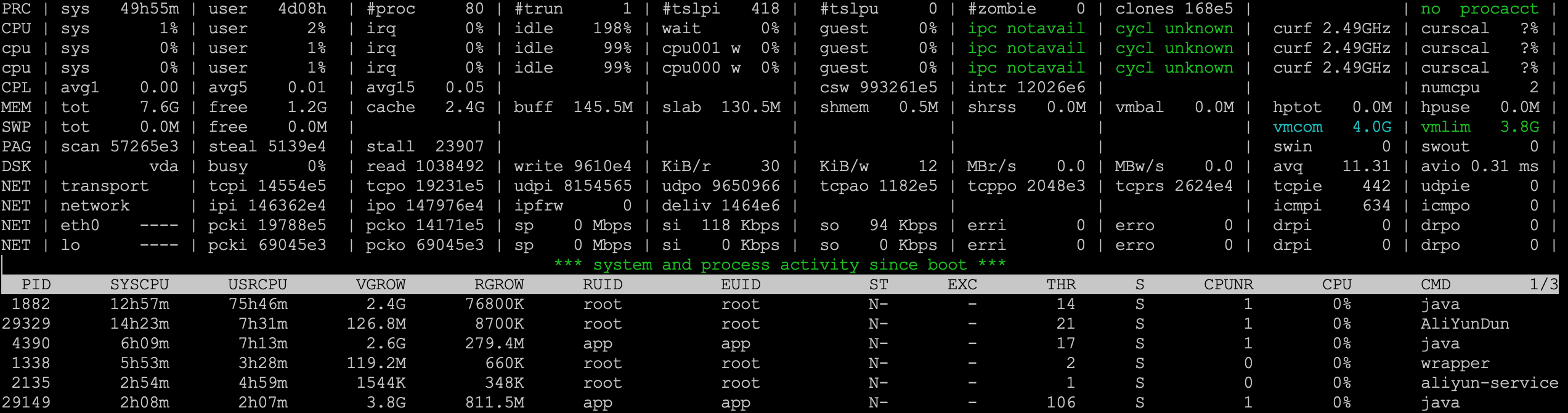
如上图所示, atop 的界面分为上半部分的系统监控项和下半部分的进程列表。
atop 每10s更新一次系统监控项以及在这段时间内状态发生变化的进程,按下A键可以查看全部进程。
系统状态
进程
第一行PRC显示总体进程状况:
- sys, user 表示 CPU 在内核态和用户态的运行时间比例
#proc为当前总进程数,#trun表示 running 状态线程数#tslpi表示 sleeping interruptible 状态的进线程数#tslpu表示 sleeping uninterruptible 状态线程数#zombie表示僵尸进程数
- clones 表示在监控周期(默认10s)内 clone() 系统调用次数
linux 中进程有两种 sleep 状态:
- interruptible sleep: 进程接收系统信号,可以被系统信号中断
- uninterruptible sleep: 进程不接收系统信号,不可被系统信号中断,包括kill -9 (SIGKILL 信号)。当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。
一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵尸进程。大量僵尸进程可能会占用进程描述符空间导致无法创建进程。
孤儿进程是容易与僵尸进程混淆的一类进程,孤儿进程是父进程终止的进程,它们会被 init 进程接管并不会产生危害。
CPU
在 atop 中每个 CPU 逻辑核心拥有一个 cpu 行表示自身状态, 最前面的 CPU 行则展示系统总览。
- sys 表示CPU在内核态工作时间比例
- user 表示 CPU 在用户态工作时间比例
- irq 表示 CPU 处理系统中断所消耗的时间比例
- idle 表示 CPU 空闲时间比例
CPL 行表示 CPU 负载(CPU Load):
- avg1, avg5, avg15: 过去 1min、5min和 15min 内的平均系统负载
- csw 表示监控周期内上下文切换的次数
- intr 表示监控周期内中断发生的次数
系统负载
CPU 负载或称为系统负载是一个容易被误解的监控项,它的定义为内核运行队列中 running 或 uninterruptible sleep 状态的进程的平均数与CPU计算能力的比值。
系统负载 1.0 说明CPU恰好满载,当系统负载大于1.0时会有进程因为等待CPU而阻塞。在多核系统中,系统负载等于CPU核心数表示恰好满载,如在上图所示双核系统中,load=2说明恰好满载。
上文已经说明,uninterruptible sleep 进程通常是在等待IO, 当网络异常或磁盘故障时会导致大量进程处于 uninterruptible sleep 状态从而导致 Load 急剧上升。
常见的服务器程序大多数为IO密集型程序,常见的CPU密集型任务包括:
- 大规模的排序计算, 如 mysql filesort
- 大量的正则表达式匹配
- 大量的 Hash Code 计算
- 大规模的加解密或压缩解压计算
当我们发现 CPU 使用率上升时,我们可以优先考虑是否在上述CPU密集型任务。
内存
MEM 行描述内存使用情况:
- tot: 物理内存总量
- free: 空闲内存总量
- cache: 文件缓存用量
- buff: 块设备缓存用量
- slab: 系统内核 slab 内存用量
- dirty: 需要写回磁盘的脏页用量,这部分内存使用已包含在cache中
这里出现了两个两个缓存: cache 和 buffer:
cache 是指 page cache, 是在文件系统级别的缓存。用于缓存从文件中读取的数据,下次读取文件时可以从内存中快速获取,不需要进行磁盘IO。
buffer 是磁盘等块设备的缓存,不经过文件系统直接对磁盘进行读写的数据会缓存在 buffer 中。
文件需要映射到物理磁盘的块上,这层映射关系由文件系统负责维护。没有文件系统支持的数据读写都会使用 buffer 缓存,比如文件系统元数据的缓存,以及 dd 等工具直接对磁盘进行读写时需要的缓存。
cache 和 buffer 两个缓存既会被用在读请求中,也会被用在写请求中。
PAG 行表示页缓存的使用情况:
- scan: 当可用内存不足时扫描的页数,这个值过高说明可用内存不足
- stall: 内核紧急将页加载到内存中的次数,这个值过高说明可用内存不足
- steal: 虚拟机相关指标
- swin: 从 Swap 分区将页加载到内存的次数
- swout: 将内存页写入 Swap 分区的次数
scan 和 steal 的解释比较难理解,附上 man page 中的原文:
This line contains the number of scanned pages ('scan') due to the fact that free memory drops below a particular threshold and the number times that the kernel tries to reclaim pages due to an urgent need ('stall')
SWP 行表示 Swap 分区使用状态:
- tot: Swap 分区总大小
- free: Swap 分区空闲空间大小
当物理内存不足时,内核会将进程内存中不常用的页逐出内存写入磁盘中的 Swap 分区,当进程需要读取这些页时再将它们从磁盘中加载到内存。
磁盘
DSK 列描述磁盘使用情况:
- vda: 该列为磁盘设备名,每个设备拥有一行
- busy: 设备处理IO请求的时间占比
- read: 监控周期内读请求数
- write: 监控周期内写请求数
- KiB/r: 每次读请求的平均数据量
- KiB/w: 每次写请求的平均数据量
- MBr/s: 每秒读取的数据量
- MBw/s: 每秒写入的数据量
- avq: io 队列的平均长度
- avio: 单次读写请求需要的毫秒数
网络
网络层通常包含 transport、network、 eth 和 lo 行, 分别表示传输层、网络层、以太网(数据链路层)和本地回环的监控指标。
- tcpi/udpi/ipi: 接收的 tcp/udp/ip 数据包
- tcpo/udpo/ipo : 发出的 tcp/udp/ip 数据包
- tcpao: 主动建立的tcp连接数(active open)
- tcppo: 被动建立的tcp连接数(passive open), 即通过 listen() 建立的连接数
- tcprs: tcp 重传次数
- tcpie: 读取时发生错误的次数
进程列表
进程列表有多个视图分别展示不同方面的数据:
- 默认视图(Generic information): 按G键回到默认视图
- 内存视图(Memory information): 按M键进入内存视图,显示进程的内存占用情况
- 命令行视图(Command Line information): 按C键进入命令行视图,显示进程启动时详细命令行参数
- 调度器视图(Scheduling information): 按S键进入视图,显示线程调度、CPU使用和运行统计
- 磁盘视图(Disk information): 按D键进入视图,显示进程的磁盘IO使用情况
- 网络视图(Network information): 按N键进入视图,显示进程的网络IO使用情况
atop 默认展示过去10s内状态发生变化的进程,按下A键可以查看全部进程。
默认视图
默认视图展示常用的监控项:
- PID: 进程ID
- SYSCPU: 在内核态下使用CPU时间
- USERCPU: 在用户态下使用CPU时间
- VGROW: 过去一个监控周期内进程的虚拟内存空间增长,包括malloc()分配内存、使用共享内存以及free()释放内存造成的空间变化
- RGROW: 过去一个监控周期内进程常驻内存空间(resident memory)增长, 即进程内存空间中驻留在物理内存中未被逐出到SWAP分区的部分。
- RUID, EUID, SUID: 启动进程的UID
- RUID: 登录时的用户ID
- EUID: Effective Uid。通常EUID=RUID, setuid 或 sudo 等指令能以另一个用户身份执行命令,这个被“代理”的用户即为 Effective User。
- EXC: 进程退出时的返回码
- THR: 进程中的线程数
- S: 进程状态,与ps命令的进程描述符相同
简单介绍一下进程状态
- R: Runing
- S: sleeping interruptible 等待某个事件
- D: sleeping non-interruptible 通常在等待IO
- Z: Zombie 僵尸进程
- E: 进程在上个监控周期内退出
- T: TASK_STOPPED 或 TASK_TRACED 状态
- TASK_STOPPED: 进程收到 SIGSTOP 信号进入暂停状态
- TASK_TRACED: 进程进入暂停状态等待跟踪它的进程,比如进程被 gdb 的断点暂停
内存视图

按M键可以进入内存视图查看进程的内存使用情况:
- MINFLT: 进程缺页小错误(minor page fault)的次数
- MAJFLT: 进程缺页大错误(major page fault)的次数
- VSIZE: 虚拟内存空间的总大小
- RSIZE: 常驻内存(resident memory)的总大小
- VGROW: 虚拟内存空间在上个监控周期的增长
- RGROW: 虚拟内存空间在上个监控周期的增长
- MEM: 物理内存使用占比
在 Linux 的内存管理系统中需要读取磁盘才能解决缺页中断称为大错误(Major Page Fault), 不需要读取磁盘可以解决的缺页中断被称为小错误(Minor Page Fault)。
一般情况下 MINFLT 是因为频繁分配/回收大内存块导致的,可以考虑使用内存池优化程序来减少缺页错误; MAJFLT 是由于物理内存不足导致。
调度视图

按S键可以进入调度视图(Scheduling View)查看进程运行和CPU情况:
- TRUN: running 状态的线程数
- TSLPI: sleeping interruptible 状态线程数
- TSLPU: 表示 sleeping uninterruptible 状态进程数
- PILI: 调度策略
- PRI,NICE: 优先级,PRI+NICE越低优先级越高
- CPU: CPU 使用时间占比
监控服务
除了查看当前的状态外,atop 还可以服务方式运行在后台监控并记录系统状态。
使用 service atop start 或 systemctl start atop 命令启动atop监控服务。
atop 默认将数据保存在/var/log/atop目录下,10 分钟采集一次,保留最近28天的数据。上述配置可以在 /etc/atop/atop.daily 文件中进行修改。
使用 atop -r <filename> 命令读取日志文件。按t键向前翻页,T键向后翻页,b键跳转到指定时间,时间格式为hh:mm。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号