
Python3 Srcapy 爬虫
最近一直在理论学习,没有时间写博客。今天来一波Python爬虫,为机器学习做数据准备。
爬虫配置环境 Anaconda3 + Spyder + Scrapy
Anaconda 安装就不绍了,网上很多。下面简单介绍一Scrapy的安装,重点介绍Scrapy编写爬虫
#Scrapy 安装 conda install scrapy
Scrapy安装好后,开始第一个项目:
#打开cmd终端或者Anaconda 自带的Anaconda Prompt,本人极力推荐后者 scrapy startproject project_name #project_name 是项目名称,不能带有路径比如H:/Python/project_name这种格式是不行 scrapy startproject zhufang #这是我写的项目名称
小说明:使用scrapy 创建好项目后,Spyder中无法识别到这个项目的(Pycharm可以识别到)。在这里可以先在Spyder中建立一个空项目,然后把scrapy建立好的项目整个文件夹拷贝到Spyder建立好的空文件夹下。实例如下:
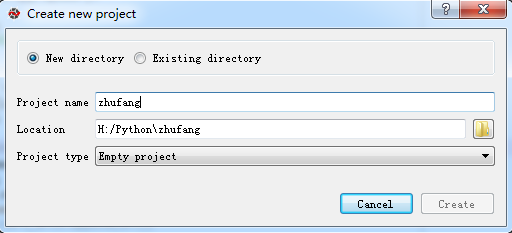
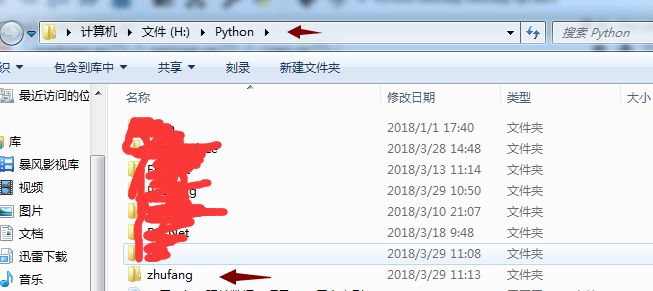
#打开Anaconda Prompt 执行以下命令 H: cd Python\zhufang scrapy startproject zhufang
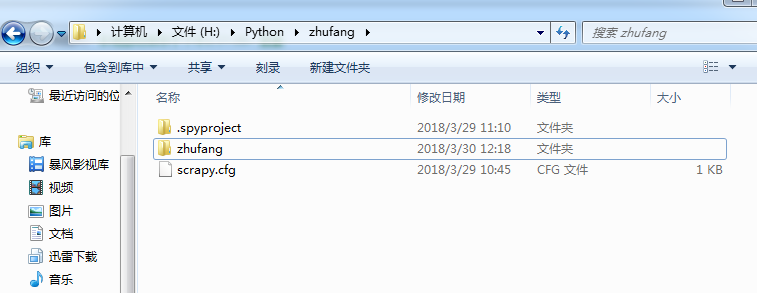
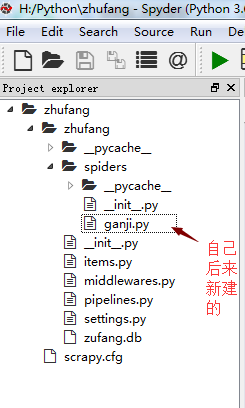
建立好项目后,在打开Spyder,找到项目,可以看到如下图所示的文件目录结构。其中的ganji.py 和zhufang.db是我自己后来建的。ganji.py 是主要核心部分,zhufang.db是数据库文件,使用python自带的sqlite3建立的。文件的其他说明我就不班门弄釜了,我在网上找到一个写的很全的文章,分享给大家 http://python.jobbole.com/86405/
我在写爬虫遇到一个最困惑的问题就是不知道爬虫的入口哪里,以及如何自动跳转到下一页面爬取。最后这个问题归结到了start_requests函数,将其重写,按照要爬取的目标网站的网址URL所遵循的规律写。下面附上本次爬虫经历的所有代码
# -*- coding: utf-8 -*- #ganji.py import scrapy from zhufang.items import ZhufangItem class GanJiSpyder(scrapy.Spider): name = "ganji"; URL = "http://dl.ganji.com/fang1/"; #下一页地址 #http://dl.ganji.com/fang1/o{pagenum}/ #url_change = "o1"; start_urls = []; start_page = 1; end_page = 10; #重写start_requests 爬虫的入口 def start_requests(self): pages = []; while self.start_page <= self.end_page: url = self.URL + 'o' + str(self.start_page); #self.start_urls.append(url); #请求url page = scrapy.Request(url); self.start_page = self.start_page + 1; pages.append(page); return pages; def parse(self,response): #print(response); price_list = response.xpath("//div[@class='f-list-item ershoufang-list']/dl[@class='f-list-item-wrap f-clear']/dd[@class='dd-item info']/div[@class='price']/span[1]/text()").extract(); title_list = response.xpath("//div[@class='f-list-item ershoufang-list']/dl[@class='f-list-item-wrap f-clear']/dd[@class='dd-item title']/a/text()").extract(); zf = ZhufangItem(); for t,p in zip(title_list,price_list): #将数据存入item中,与Items 文件中定义的字段对应 zf['title'] = t; zf['price'] = p; yield zf; #回调失败 # yield scrapy.Request(URL + url_change, callback = parse) #print("%s : %s" % (t,p));
# -*- coding: utf-8 -*- #piplines.py # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html #管道文件 将爬到的数据在这里清理 存入数据库 import sqlite3 class ZhufangPipeline(object): #重写爬虫开始函数 def open_spider(self,spider): #连接数据库 self.con = sqlite3.connect("zufang.db"); self.cu = self.con.cursor(); def process_item(self, item, spider): #print(spider.name); sql_insert = "insert into info (title,price) values('{}','{}')".format(item["title"],item["price"]); #print(sql_insert); self.cu.execute(sql_insert); self.con.commit(); return item #重写爬虫结束函数 def spider_close(self,spider): self.con.close();
#setting.py # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { #标记ZhufangPipeline 这个类 ,后面的值范围【1,1000】,根据值的大小依次顺序执行 'zhufang.pipelines.ZhufangPipeline': 300, }
# -*- coding: utf-8 -*- #items.py # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy #数据通过items文件中的ZhufangItem类才能传回到管道文件pipelines中 class ZhufangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() #pass #定义字段 title = scrapy.Field(); price = scrapy.Field();
最后,由于项目中有文件夹的嵌套,在模块引用的时候可能会出现问题,在这里也附上一个很好的文章 https://www.cnblogs.com/ArsenalfanInECNU/p/5346751.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号