

数据处理笔记---Linux系统Hadoop配置准备工作
一、更改服务器名称和修改host
修改位于etc/hostname文件,添加自己命名主机名。
修改位于etc/host文件,设置主机地址并设置别名为主机名。如:192.168.75.129 master
修改/etc/sysconfig/network文件
1 NETWORKING=yes 2 HOSTNAME=master
二、产生密钥, 配置 ssh master 的免密登录(学习为方便所有配置为免密)
1 ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa //(可以产生/root/.ssh目录) 2 cd /root/.ssh //如果没有在root下建立 .ssh 目录 3 ssh-keygen -t rsa //四次回车 4 cat id_rsa.pub >> authorized_keys 5 cat authorized_keys 6 cd .. 7 chmod 700 .ssh 8 chmod 700 .ssh/* 9 ssh master //检测是否正常 10 exit
三、 hadoop安装和配置
下载hadoop2.7.3到tmp,解压到/usr/
下载地址:http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
改名/usr/hadoop-2.7.7 为 hadoop
修改/etc/profile配置Hadoop环境路径
以下为我自己的环境路径以供参考
1 export B=/usr/hbase 2 export H=/usr/hadoop 3 export I=/usr/hive 4 export J=/usr/jdk 5 export M=/usr/mysql 6 export PATH=$PATH:$B: $H:$I:$J:$M:$B/bin:$H/bin:$H/sbin:$I/bin:$J/bin:$M/bin
修改完成后刷新profile
1 source /etc/profile
检查路径
1 echo $PATH
四、hadoop配置
(一)、修改Hadoop-env.sh文件
将Hadoop-env.sh文件中的JAVA_HOME修改为自己的jdk地址
(二)、在master和slaves文件中添加主机名
(三)、修改core-site.xml
1 <configuration> 2 <property> 3 <name>fs.default.name</name> 4 <value>hdfs://主机名:9000</value> 5 </property> 6 7 <property> 8 <name>fs.defaultFS</name> 9 <value>hdfs://主机名:9000</value> 10 </property> 11 12 <property> 13 <name>hadoop.tmp.dir</name> 14 <value>/usr/hadoop/tmp</value> //自己Hadoop地址 15 </property> 16 <property> 17 <name>dfs.permissions</name> 18 <value>false</value> 19 </property> 20 <property> 21 <name>fs.permissions.umask-mode</name> 22 <value>077</value> 23 </property> 24 </configuration>
(四)修改hdfs-site.xml文件
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>1</value> 5 </property> 6 7 <property> 8 <name>dfs.name.dir</name> 9 <value>/usr/hadoop/hdfs/name</value> //自己Hadoop路径 10 </property> 11 12 <property> 13 <name>dfs.data.dir</name> 14 <value>/usr/hadoop/hdfs/data</value> //自己Hadoop路径 15 </property> 16 <property> 17 <name>dfs.webhdfs.enabled</name> 18 <value>true</value> 19 </property> 20 <property> 21 <name>dfs.permissions</name> 22 <value>false</value> 23 </property> 24 </configuration>
(五)、修改 mapred-site.xml文件(该文件原始名有tem需要手动删去)
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property> 6 </configuration>
(六)、修改 Yarn-site.xml文件
1 <configuration> 2 <property> 3 <name>yarn.resourcemanager.hostname</name> 4 <value>主机名</value> 5 </property> 6 7 <property> 8 <name>yarn.nodemanager.aux-services</name> 9 <value>mapreduce_shuffle</value> 10 </property> 11 </configuration>
五、格式化Hadoop
如果不执行格式化开启后会缺少datanode进程
1 hadoop namenode –format
六、启动Hadoop
1 start-all.sh
启动后用jps查看进程
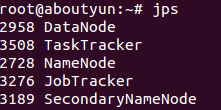
七、Hadoop常用命令
1 hadoop fs –help 2 hadoop fs –ls / 显示根文件夹 3 hadoop fs -ls -R / 显示根下所有文件夹 4 hadoop fs -mkdir /w 创建w文件夹 5 hadoop fs –put /opt/b.txt /w 把/opt/b.txt 存放于hadoop的w文件夹下 6 hadoop fs -get /w/b.txt b1.txt 把hadoop的w下b1.txt取回改名为b1.txt 7 hadoop fs -get -f /w/b.txt 把hadoop的w下b1.txt取回 ,-f代表替换已经存在的文件 8 Hadoop fs -touchz /w.txt 创建空文件 9 hadoop fs -cat /w.txt 显示文件内容 10 hadoop fs -appendToFile /opt/short.txt /w.txt 把short.txt内容追加到w.txt 11 hadoop fs -rm /w.txt 删除w.txt文件 12 hadoop fs –rmdir /opt 删除/opt文件夹 13 hadoop fs -rmr / 删除根目录下所有文件
配置正确但进程缺少datanode(格式化次数太多)
1.停止 stop-all.sh
2.删除/usr/hadoop/hdfs下的data和node文件夹
3.重新格式化 hadoop namenode –format
5.再启动 start-all.sh

