CDQ分治 从树状数组问题到Mokia
\(CDQ\) 分治再续
这一次是给出两个常见的问题,由于某种原因,我们可以使用 \(CDQ\) 有效的解决这一系列的问题。
\(I.\) 一维 \ 树状数组 \(1\) 问题
题目大意 : 给出一个序列 (\(N\)个数字) ,操作包括单点修改,区间查询。
再次提一下 \(CDQ\) 分治的主要思想:
- 求左边区间的贡献
- 求右边区间的贡献
- 求左半边对右半边的贡献
在求偏序的时候,以上三点的顺序是可以打乱的。不过在这道题目中,必须遵循一定的顺序,需要注意。
在我们使用树状数组或者线段树解决这道问题的时候,基于的是前缀和和分治的思想,这里稍微有点不同。我们想,一个修改必定会影响它后面的查询,当我们把原数组也视作修改的时候,
整个就变成了哪个修改会影响哪个查询的问题。
再想一下 \(CDQ\) 分治的思想,我们可不可以求左半边对右半边的贡献呢? 先假设一个区间 \(l,r\),假如 \(l\) 到 \(mid\) 的操作都是在 \(mid+1\) 到 \(r\) 前面做的(也就是左半边所有的时间都小于右半边的时间),那么 \(l\) 到 \(mid\) 的修改必定会影响到 \(mid+1\) 到 \(r\) 的查询。
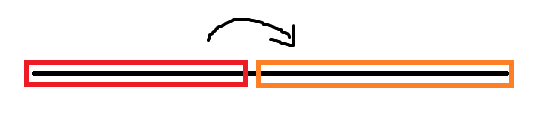
而我们把所有的查询 \(L,R\) 的值变为 \(1,R\) 的值减去 \(1,L-1\) 的值,那么所有的查询的起点都是 \(1\)。这个时候我们判断是否有贡献的时候,我们就拿右端点 (修改的只有一个点,也视其为右端点) 来判断,修改的右端点小于查询的右端点,那么肯定是对查询有贡献的。(黑色的是加的,红色的是减去的,剩下的黄色就是目标区间)

那是左半边所有的修改都会影响到右半边所有的贡献吗? 并不是。

(注意,\(time\) 为操作的时间,\(point\) 为右端点的位置,\(mode\) 为查询 (\(Q\)) 或者修改 (\(C\))。以下的 \(n\) 为操作的总数,包括把查询拆分和原序列)
我们对左半边和右半边的区间的右端点进行排序以后,左半边的时间还是要小于右半边最低的时间。我们可以很容易想到, \(1\) 号 的 右端点是 \(1\),它对右半边的所有查询都会产生贡献。而 \(2\) 号的右端点是 \(3\)右半边,它只能对
右半边的 \(2,3,4\) 号有贡献。也就是说,我们只需要每一次比较 \(left\) 是否小于 \(right\) (其中 \(left\) 为 \(1\) 到 \(mid\),\(right\) 为 \(mid+1\) 到 \(r\)),如果小于,那么当前的 \(left\) 号会对 \(right\) 到 \(r\) 都有贡献,
所以 \(inc(sum,val[left])\)。如果不是,我们就直接计算 \(1\) 到 \(left-1\) 对 \(right\) 的贡献,就是 \(inc(ans[id[right]],sum)\)。
上述的方法是要求左半边和右半边的右端点有序,且左半边的最大时间小于等于右半边的最小时间的。我们可以采用先 \(CDQ(l,mid)\ CDQ(mid+1,right)\) 的方法,每一次算完当前的贡献,就排好序,这样子就可以保证啦。既然是 \(CDQ\),那么可以直接归并排序,常数小。
然后解释一下为什么 \(CDQ\) 要分治。对于一个点 \(i\),它经过 \(\log\ n\) 层的分治以后,必然会与每一个右区间算贡献。一开始右区间有 \(\frac{n}{2}\) 个数字,然后变为 \(\frac{n}{4}\ \frac{n}{8}.etc\)。时间复杂度涉及到递归,这里作出大致的推测 : \(\log\ n\) 层,每一层的总和是 \(n\),那就是 \(n \log\ n\)。实际上应该是 \(O(f(n) \log\ n)\),我表示并不会主定理。
最后注意一下时间相同,先修改,再查询(虽然不知道为什么时间会相同)。
function judge(i,j:longint):boolean;
begin
if place[i]<>place[j] then // place 是右端点
begin
if place[i]<place[j] then exit(True);
exit(False);
end;
if mode[i]<mode[j] then exit(True); // 查询的 mode 是 2,修改的 mode 是 1
exit(False);
end;
procedure CDQ(l,r:longint);
var
left,right,i,mid:longint; // left 是左半边开始第一个节点,right 是右半边第一个节点,两者都用于归并排序
sum:int64; // '现在'左半边的贡献
begin
if l=r then exit;
mid:=(l+r) >> 1;
CDQ(l,mid); // 先往下
CDQ(mid+1,r);
sum:=0; left:=l; right:=mid+1;
for i:=l to r do
if (left<right)and(judge(left,right)) or (right>r) then // 在左边
begin
if mode[left]=1 then inc(sum[id[left]]); // 修改的 id 是修改的值,而查询的 id 是此查询是第几个查询
copy[1,i]:=mode[left]; copy[2,i]:=place[left]; copy[3,i]:=id[left]; inc(left); // 归并排序
end
else
begin
if mode[right]=2 then dec(ans[id[right]],sum);
if mode[right]=3 then inc(ans[id[right]],sum);
copy[1,i]:=mode[right]; copy[2,i]:=place[right]; copy[3,i]:=id[right]; inc(right);
end;
for i:=l to r do
begin mode[i]:=copy[1,i]; place[i]:=copy[2,i]; id[i]:=copy[3,i]; end;
end;
\(II.\) 二维 \ \(Mokia\)
题目大意 : 给出一个空的二维矩阵 (\(N\) 行 \(N\) 列),操作包括单点修改,矩阵查询。
这是一个比较简单的二维树状数组的题目,至少在看到 \(N\) 的数据范围之前是怎么认为的。
数据范围 : \(N \leq 2 \times 10^6\)。而树套树 (我指的是树状数组或者线段树) 怎么也只能 \(N \leq 10^4\)。
这就展现了 \(CDQ\) 比较好的以一面 哪个修改会影响哪个查询,就不用考虑 \(N\) 的大小,不用考虑模拟矩阵。
第一步,我们把查询看做是一个二维前缀和的查询。也就是说,我们对于 \(x,y,x1,y1\) 的查询,看做全部以 \(1\) 开始的矩阵,如下图 : (黑色的是加的,红色的是减去的,剩下的黄色就是目标矩阵)
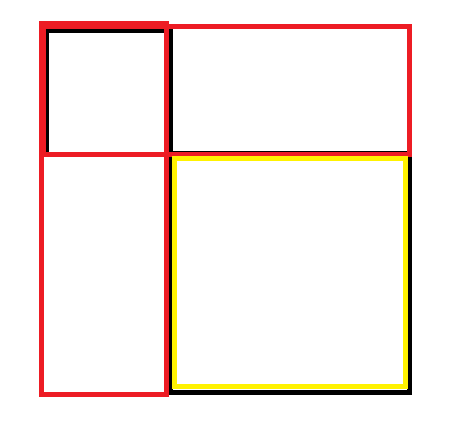
现在问题从原来的一个右端点变成了两个右端点,但是贡献还是相同的,且有一个。假如两个点 \(x_i,y_i\),\(x_i\) 已经满足 \(\leq x_j\),那么我们就只需要看 \(y_i\) 对 \(y_j\) 怎么样。这时候我们用一个树状数组(权域)来维护一下,
每一次左半边有修改的时候更新一下树状数组,每当右半边有点可以满足当前的左半边的点的时候 (\(left,right\)),就统计右边的点的第二个右端点 (\(right_y\)) 的前面有多少个左半边的点 (\(1_y~left_y\)) 的第二个右端点。
我们可以思考一下,如果我们先对所有的第一个右端点 (\(x\)) 进行了排序,那么每一次往下,我们只需要对时间进行归并排序即可,这样子跟上文的 从下往上,对右端点进行排序 是一样的。
procedure CDQ(l,r:longint);
var
left,right,i,mid:longint; // left 是左半边开始第一个节点,right 是右半边第一个节点,两者都用于归并排序
begin
if l=r then exit;
mid:=(l+r) >> 1;
left:=l; right:=mid+1;
for i:=l to r do
begin
if (time[i]<=mid)and(mode[i]=1) then // 计算左半边的产生的贡献
Insert(point[2,i],value[i]); // value[i] 是修改的值,Insert 是树状数组的 Add
if (time[i]>mid)and(mode[i]=2) then // 计算右半边拥有的贡献
inc(ans[id[i]],Query(point[2,i])*value[i]); // 查询的 value[i] 只有 1 和 -1,用来表示加还是减
if (time[i]<=mid) then // 以下都是归并排序
begin
copy[1,left]:=time[i]; copy[2,left]:=point[1,i]; copy[3,left]:=point[2,i];
copy[4,left]:=value[i]; copy[5,left]:=id[i]; copy[6,left]:=mode[i]; inc(left);
end
else
begin
copy[1,right]:=time[i]; copy[2,right]:=point[1,i]; copy[3,right]:=point[2,i];
copy[4,right]:=value[i]; copy[5,right]:=id[i]; copy[6,right]:=mode[i]; inc(right);
end;
end;
for i:=l to r do // 算完贡献以后按照 time 排序
begin
time[i]:=copy[1,i]; point[1,i]:=copy[2,i]; point[2,i]:=copy[3,i];
value[i]:=copy[4,i]; id[i]:=copy[5,i]; mode[i]:=copy[6,i];
end;
CDQ(l,mid);
CDQ(mid+1,r);
end;
最后总结 \(CDQ\) 分治需要注意的地方:
\(I.\ CDQ\)分治会按照各个参数的顺序而改变递归的顺序。
\(II.\ CDQ\)分治的时间复杂度并不是非常的好,常数巨大,但是可以做那些二维以上的题目,不用考虑 \(N\) 的大小。 (但是询问太多还是会炸)
$III.\ $有些人是直接 \(Sort\) 的,而不是归并排序,所以 \(CDQ\) 分治的三个步骤可以打乱。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号