
训练集,测试集,检验集的区别与交叉检验
前言
在机器学习中,不可避免要接触到训练集,测试集以及检验集,这些数据集各有各的作用,为机器学习算法的泛化保驾护航,这里结合《Deep Learning》中的关于训练集,测试集和检验集的讨论,浅谈所见所学。
如有谬误,请联系指正。转载请注明出处。
联系方式:
e-mail: FesianXu@163.com
QQ: 973926198
github: https://github.com/FesianXu
训练集和测试集
机器学习模型需要训练去更新模型中的各个参数,因此需要提供训练集(Training Set)作为训练样本,假设此训练集由数据生成分布
检验集
超参数
在讨论检验集之前,有必要先提到超参数(hyperparameter)这个概念。超参数不能或者难以通过机器学习算法学习得出,一般由专家经过经验或者实验选定,如广义线性回归中的多项式次数,控制权值衰减的
这里我们假想一个场景:
我们有多个待选的权值衰减因子
λ ,分别是λ1,⋯,λn ,这些λ 的不同选择代表了一个模型的不同超参数状态,其中有一个可能性能比较优的超参数,为了得到这个较为优的超参数,我们需要在多个[训练集,测试集]元组上训练测试,寻找最小的泛化误差,直到找到合适的超参数为止。
由于监督数据的获取困难,一般来说没有那么多数据用来划分这个元组,因此一般的做法是:
将数据集按一定比例划分为训练集(大类)和测试集(Test set),其中测试集只在最后的测试泛化误差的时候才能被模型观察到,而在训练集(大类)中又将其按一定比例划分为训练集(Training Set)和检验集(validation set),其中训练集用于模型训练,检验集用于寻找最佳的超参数。一般模型会在训练集上训练多次,在检验集上检验多次,直到得到满意的检验误差,然后才能交给测试集得出泛化误差。

交叉检验(Cross Validation)
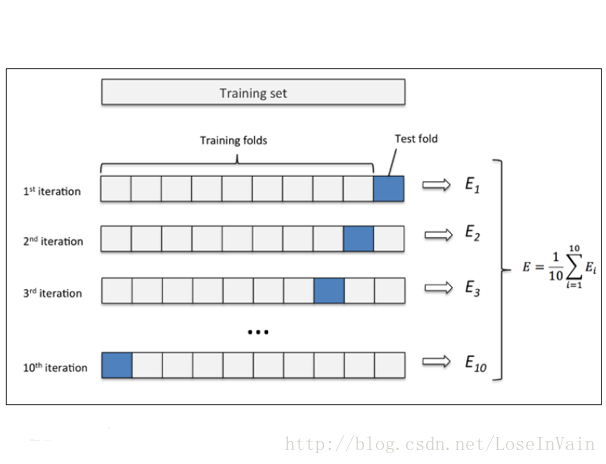
在实际应用中,因为数据集的数量限制,常常采用交叉检验作为检验手段1,其中k折交叉检验(k-folds cross validation)最为常用,其中
其中
总结
在这篇文章里,主要介绍了训练集,检验集,测试集之间的关系,以及引进检验集的目的:就是为了多次比较,得出较好的超参数,进行模型选择。
- 当给定数据集
D 对于简单的训练/测试或训练/验证分割而言太小难以产生泛化误差的准确估计时(因为在小的测试集上,L 可能具有过高的方差),常常采用交叉验证。 ↩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号