在TensorFlow中自定义梯度的两种方法
前言
在深度学习中,有时候我们需要对某些节点的梯度进行一些定制,特别是该节点操作不可导(比如阶梯除法如),如果实在需要对这个节点进行操作,而且希望其可以反向传播,那么就需要对其进行自定义反向传播时的梯度。在有些场景,如[2]中介绍到的梯度反转(gradient inverse)中,就必须在某层节点对反向传播的梯度进行反转,也就是需要更改正常的梯度传播过程,如下图的所示。
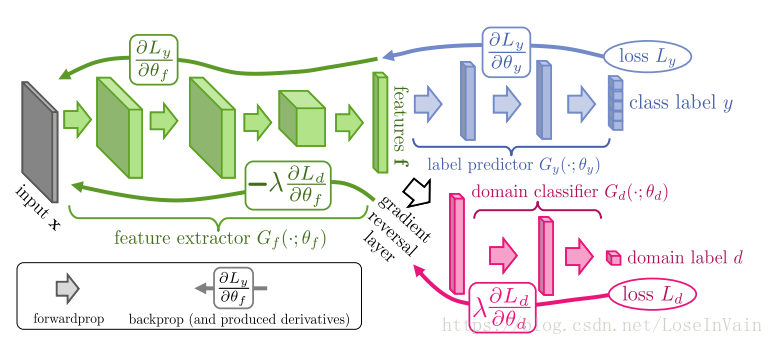
在tensorflow中有若干可以实现定制梯度的方法,这里介绍两种。
1. 重写梯度法
重写梯度法指的是通过tensorflow自带的机制,将某个节点的梯度重写(override),这种方法的适用性最广。我们这里举个例子[3].
符号函数的前向传播采用的是阶跃函数,如下图所示,我们知道阶跃函数不是连续可导的,因此我们在反向传播时,将其替代为一个可以连续求导的函数,于是梯度就是大于1和小于-1时为0,在-1和1之间时是1。
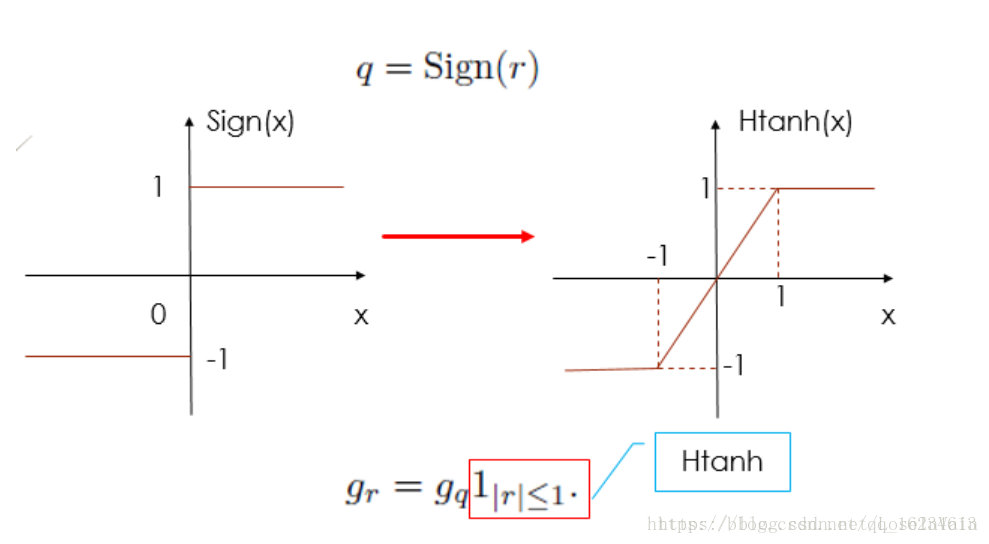
使用重写梯度的方法如下,主要是涉及到tf.RegisterGradient()和tf.get_default_graph().gradient_override_map(),前者注册新的梯度,后者重写图中具有名字name='Sign'的操作节点的梯度,用在新注册的QuantizeGrad替代。
#使用修饰器,建立梯度反向传播函数。其中op.input包含输入值、输出值,grad包含上层传来的梯度
@tf.RegisterGradient("QuantizeGrad")
def sign_grad(op, grad):
input = op.inputs[0] # 取出当前的输入
cond = (input>=-1)&(input<=1) # 大于1或者小于-1的值的位置
zeros = tf.zeros_like(grad) # 定义出0矩阵用于掩膜
return tf.where(cond, grad, zeros)
# 将大于1或者小于-1的上一层的梯度置为0
#使用with上下文管理器覆盖原始的sign梯度函数
def binary(input):
x = input
with tf.get_default_graph().gradient_override_map({"Sign":'QuantizeGrad'}):
#重写梯度
x = tf.sign(x)
return x
#使用
x = binary(x)
其中的def sign_grad(op, grad):是注册新的梯度的套路,其中的op是当前操作的输入值/张量等,而grad指的是从反向而言的上一层的梯度。
通常来说,在tensorflow中自定义梯度,函数tf.identity()是很重要的,其API手册如下:
tf.identity(
input,
name=None
)
其会返回一个形状和内容都和输入完全一样的输出,但是你可以自定义其反向传播时的梯度,因此在梯度反转等操作中特别有用。
这里再举个反向梯度[2]的例子,也就是梯度为而不是。
import tensorflow as tf
x1 = tf.Variable(1)
x2 = tf.Variable(3)
x3 = tf.Variable(6)
@tf.RegisterGradient('CustomGrad')
def CustomGrad(op, grad):
# tf.Print(grad)
return -grad
g = tf.get_default_graph()
oo = x1+x2
with g.gradient_override_map({"Identity": "CustomGrad"}):
output = tf.identity(oo)
grad_1 = tf.gradients(output, oo)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(grad_1))
因为-grad,所以这里的梯度输出是[-1]而不是[1]。有一个我们需要注意的是,在自定义函数def CustomGrad()中,返回的值得是一个张量,而不能返回一个参数,比如return 0,这样会报错,如:
AttributeError: 'int' object has no attribute 'name'
显然,这是因为tensorflow的内部操作需要取返回值的名字而int类型没有名字。
PS:def CustomGrad()这个函数签名是随便你取的。
2. stop_gradient法
对于自定义梯度,还有一种比较简洁的操作,就是利用tf.stop_gradient()函数,我们看下例子[1]:
t = g(x)
y = t + tf.stop_gradient(f(x) - t)
这里,我们本来的前向传递函数是f(x),但是想要在反向时传递的函数是g(x),因为在前向过程中,tf.stop_gradient()不起作用,因此+t和-t抵消掉了,只剩下f(x)前向传递;而在反向过程中,因为tf.stop_gradient()的作用,使得f(x)-t的梯度变为了0,从而只剩下g(x)在反向传递。
我们看下完整的例子:
import tensorflow as tf
x1 = tf.Variable(1)
x2 = tf.Variable(3)
x3 = tf.Variable(6)
f = x1+x2*x3
t = -f
y1 = t + tf.stop_gradient(f-t)
y2 = f
grad_1 = tf.gradients(y1, x1)
grad_2 = tf.gradients(y2, x1)
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(grad_1))
print(sess.run(grad_2))
第一个输出为[-1],第二个输出为[1],显然也实现了梯度的反转。
Reference
[1]. How Can I Define Only the Gradient for a Tensorflow Subgraph?
[2]. Ganin Y, Ustinova E, Ajakan H, et al. Domain-adversarial training of neural networks[J]. Journal of Machine Learning Research, 2017, 17(1):2096-2030.
[3]. tensorflow 实现自定义梯度反向传播
[4]. Custom Gradients in TensorFlow

 浙公网安备 33010602011771号
浙公网安备 33010602011771号