
基于代码的Pooling池化层的反向求导细节
前言
这个系列主要是对深度学习中常见的各种层的反向求导细节进行学习和介绍,并且辅以代码予以理解,本章介绍的是池化层,包括有max_pooling和avg_pooling,考虑到其stride的变化,其反向求导的细节也颇具有价值进行深究。如有谬误请联系指出,谢谢。
联系方式:
e-mail: FesianXu@gmail.com
QQ: 973926198
github: https://github.com/FesianXu
池化层的正向传播
在考虑池化层的反向传播之前,我们要明确池化层的正向传播的过程。池化分为最大池化(max-pooling)和平均池化(avg-pooling)两种,具体过程见Fig 1
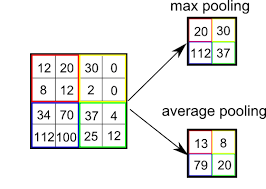
如果用代码去描述最大池化的过程,则如:
for(p=0; p<k; p++){
for(q=0; q<k; q++){
y_n(x,y) = max(y_n(x,y), y_n_1(x+p, y+q));
}
}
其中y_n(x,y)表示的是层的像素,y_n_1(x+p, y+q)表示的是层的像素, 是池化核的大小。
同理,平均池化可以描述为:
for(p=0; p<k; p++){
for(q=0; q<k; q++){
y_n(x,y) += (1/(k*k)) y_n_1(x+p, y+q)
}
}
那么对于最大池化而言,其反向传播可以用公式描述:
对于stride不等于池化核k的时候,情况会复杂些,我们下一节尝试用代码去理解这个过程。
池化层的反向传播
最大池化
首先,我们基于pytorch,写出如下代码:
import torch
import numpy as np
vara = np.array(
[
[1,3,4,2,5,2],
[4,2,5,6,8,3],
[5,3,7,8,9,3],
[8,4,3,6,0,2],
[7,10,3,6,3,5],
[4,7,2,4,7,8]
]
)
vara = vara.astype(np.float)
vara = torch.tensor(vara,requires_grad=True).float()
vara = vara.unsqueeze(0)
vara.retain_grad() # 保留梯度
pool = torch.nn.functional.max_pool2d(vara,kernel_size=(2,2),stride=2) # stride = k case
pool = torch.mean(pool)
pool.backward()
print(vara.grad)
我们会发现其输出为:
tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1111, 0.0000, 0.0000, 0.1111, 0.1111, 0.0000],
[0.0000, 0.0000, 0.0000, 0.1111, 0.1111, 0.0000],
[0.1111, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.1111, 0.0000, 0.1111, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1111]]])
其实很容易发现,对于最大池化的反向求导,只要纪录下前向传播的时候最大值的位置,将其置位1后,就有位置矩阵
tensor([[[0, 0, 0, 0, 0, 0],
[1, 0, 0, 1, 1, 0],
[0, 0, 0, 1, 1, 0],
[1, 0, 0, 0, 0, 0],
[0, 1, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 1]]], dtype=torch.uint8)
然后为了进行归一化,使得这个矩阵的大小不至于因为不同的特征图的尺寸变化而变化,我们用系数乘上位置矩阵,其中是区块的数量,比如在这个例子中,因为池化核为2,stride=2,因此一共有的区块为个,因此乘上即可。
当stride = 1时,我们的反向传播输出变为:
tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0400, 0.0000, 0.0400, 0.0400, 0.0800, 0.0000],
[0.0400, 0.0000, 0.0800, 0.0800, 0.1600, 0.0000],
[0.0400, 0.0000, 0.0000, 0.0800, 0.0000, 0.0000],
[0.0000, 0.1600, 0.0000, 0.0400, 0.0000, 0.0400],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0400, 0.0400]]])
其实在这个过程中,我们发现其要考虑到某个位置被多次计算,因为在stride < k时,某些位置将会存在重叠,那些位置要反复地累加,比如在stride=1这个情况下,我们的位置矩阵将会变为:
tensor([[[0, 0, 0, 0, 0, 0],
[1, 0, 1, 1, 2, 0],
[1, 0, 2, 2, 4, 0],
[1, 0, 0, 2, 0, 0],
[0, 4, 0, 1, 0, 1],
[0, 0, 0, 0, 1, 1]]], dtype=torch.uint8)
就是因为2,4这些位置,那个单元对于周边的范围的区块来说都是最大的,因此可能会被多次累积。
同样的,最后还是要进行归一化,其区块数变为。
平均池化
对于均值池化而言,代码如:
import torch
import numpy as np
vara = np.array(
[
[1,3,4,2,5,2],
[4,2,5,6,8,3],
[5,3,7,8,9,3],
[8,4,3,6,0,2],
[7,10,3,6,3,5],
[4,7,2,4,7,8]
]
)
vara = vara.astype(np.float)
vara = torch.tensor(vara,requires_grad=True).float()
vara = vara.unsqueeze(0)
vara.retain_grad() # 保留梯度
pool = torch.nn.functional.avg_pool2d(vara,kernel_size=(2,2),stride=2) # stride = k case
pool = torch.mean(pool)
pool.backward()
print(vara.grad)
其输出为:
tensor([[[0.0278, 0.0278, 0.0278, 0.0278, 0.0278, 0.0278],
[0.0278, 0.0278, 0.0278, 0.0278, 0.0278, 0.0278],
[0.0278, 0.0278, 0.0278, 0.0278, 0.0278, 0.0278],
[0.0278, 0.0278, 0.0278, 0.0278, 0.0278, 0.0278],
[0.0278, 0.0278, 0.0278, 0.0278, 0.0278, 0.0278],
[0.0278, 0.0278, 0.0278, 0.0278, 0.0278, 0.0278]]])
我们发现,对于均值池化而言,因为特征图每个元素都参与了贡献,而不像最大池化一样只有某个元素参与了贡献。因此对于均值池化而言,其每个元素的贡献力是一样的,因此其位置矩阵为全一矩阵,最后我们对其进行归一化就行了,这个时候其归一化系数为
其中表示区块数,表示的是每个区块中元素的数量,在这里,。
考虑到stride = 1 < k的情况,我们发现其输出变为了:
tensor([[[0.0100, 0.0200, 0.0200, 0.0200, 0.0200, 0.0100],
[0.0200, 0.0400, 0.0400, 0.0400, 0.0400, 0.0200],
[0.0200, 0.0400, 0.0400, 0.0400, 0.0400, 0.0200],
[0.0200, 0.0400, 0.0400, 0.0400, 0.0400, 0.0200],
[0.0200, 0.0400, 0.0400, 0.0400, 0.0400, 0.0200],
[0.0100, 0.0200, 0.0200, 0.0200, 0.0200, 0.0100]]])
其实这个时候和最大池化存在overlap的情况是一样的,考虑到某些元素会被多次考虑,那么对其进行累积,就得到了位置矩阵
tensor([[[1, 2, 2, 2, 2, 1],
[2, 4, 4, 4, 4, 2],
[2, 4, 4, 4, 4, 2],
[2, 4, 4, 4, 4, 2],
[2, 4, 4, 4, 4, 2],
[1, 2, 2, 2, 2, 1]]], dtype=torch.int32)
那么这个时候只要进行归一化即可,这个时候。
至此,我们对池化的前向和反向传播进行了细节上的探讨。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号