在Graph上定义卷积操作,图卷积网络
5/19, '19 FesianXu
前言
我们曾在[1]中探讨了欧几里德结构数据(如图像,音视频,文本等)和非欧几里德结构数据(如Graph和Manifold等)之间的不同点,在本文中,我们探讨如何在非欧几里德数据,特别是Graph数据上定义出卷积操作,以便于实现深度神经学习。
如有谬误,请联系指正。转载请注明出处。
联系方式:
e-mail: FesianXu@163.com
QQ: 973926198
github: https://github.com/FesianXu
非欧几里德数据 嵌入 欧几里德空间
我们提到过欧几里德数据可以很容易嵌入到欧几里德空间中,无论是样本空间还是经过特征提取后的特征空间,这个特性可以方便后续的分类器设计。然后,遗憾的是,非欧几里德数据因为天然地具有不固定的领域元素数量或者连接数量等,不能直观地嵌入欧几里德空间,并且也很难在Spatial上定义出卷积操作出来,而这个卷积操作,在欧几里德数据上是很直观可以定义出来的,如:
(f⋆γ)(x)=∫Ωf(x−x′)γ(x′)dx′(1.1)
因此我们后续要想办法在非欧几里德数据,比如常见的Graph数据上定义出卷积操作。在进一步探讨之前,我们不妨先探讨下什么叫做 嵌入到欧几里德空间以及为什么要这样做。
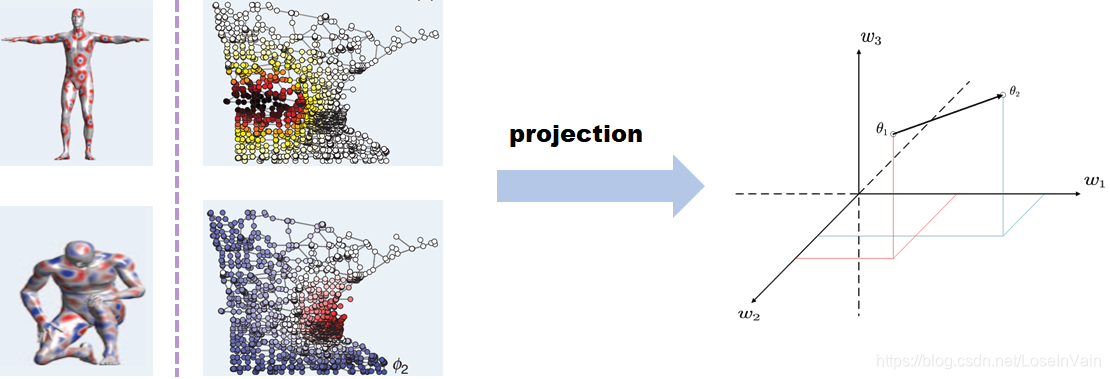
一般来说,欧几里德数据因为其排列整齐,天然可以嵌入到欧几里德空间内,并且进行欧几里德空间下定义的算子的度量,比如欧式距离等,然后可以进一步的进行样本之间的距离计算以及分类聚类等更为高级的操作。然而,非欧数据不能直接嵌入到其中,需要用特定的方法才能嵌入到欧几里德空间中,在Geometric Deep Learning中,这个特定方法就是指的是深度学习方法,整个框图如:
![proj]()
Fig 1. The Projection to the Euclidean Space
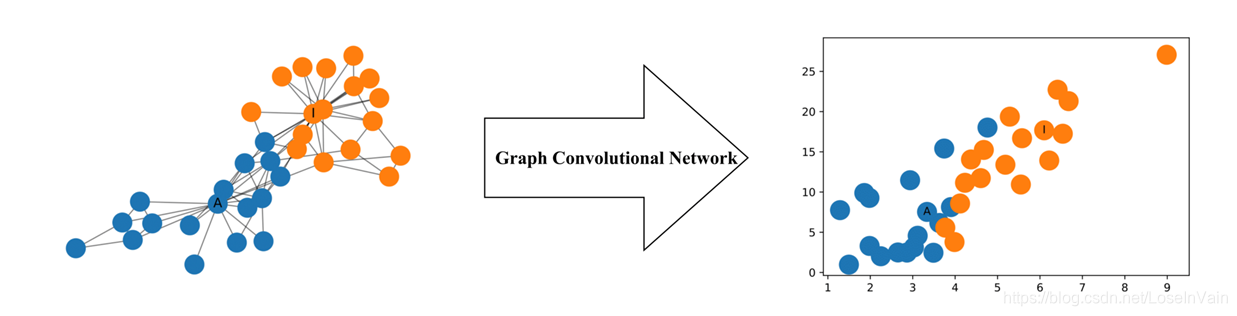
![graphgcn]()
Fig 2. Using the GCN to project the non-Euclidean data to Euclidean Space.
有了这个操作,即便是对于元素排列不整齐的Graph或者Manifold,也可在欧几里德空间进行样本之间的距离度量了,而且,这个过程还往往伴随着降维,减少计算量,方便可视化等优点。这个将会方便后续的分类器,聚类器等设计。
Graph Deep Learning
因为Graph数据是最为常见的非欧几里德数据,我们这里以图深度学习为例子。图深度学习的任务目标可以分为几种:
- 将有着不同拓扑结构,不同特征的图分类为几类。在这种情况是对整个Graph进行分类,每个Graph有一个标签。
- 对一个Graph的所有节点node进行分类。这种情况相当于是文献引用网络中对文献类型分类,社交网络对用户属性分类,每个节点有一个标签。
- 生成一个新的Graph。这个相当于是药物分子的生成等。
![在这里插入图片描述]()
Fig 3. Using GNN to discover the new medicines.
其中,最为常见的是第一类型,我们对此进行详细的任务定义如:
我们用G={A,F}表示一个图,其中A∈{0,1}n×n是对于图的邻接矩阵[2],而F∈Rn×d是节点的特征矩阵,其中n表示有n个节点,d表示每个节点有d个特征。给定一个有标签的graph样本集: D={(G1,y1),⋯,(Gn,yn)},其中yi∈Y是标签有限集合,并且对应于Gi∈G,那么我们的学习目标就是学习到一个映射f使得:
f:G→Y
在频域定义卷积
我们之前谈到在spatial域上难以直接定义graph的卷积操作,那么我们自然就想到如果能在频域定义出来卷积,那也是不错的,因此我们接下来想要探讨怎么在频域定义卷积。在此之前,我们需要了解下热传播模型的一点东西,因为图中节点的信息传递,一般来说是通过邻居节点进行传递的,这一点和物体将热量从高到低的传递非常相似,可以对此建立和热传递相似的模型。
在[3]的这篇答案中,作者对热传播和图节点信息传递进行了非常精彩的阐述,并且引出了 拉普拉斯矩阵(Laplacian Matrix) 对于节点之间关系的描述作用,值得各位读者参考。
总的来说,就是对拉普拉斯矩阵进行特征值分解,其每个特征向量可以看成是频域中正交的正交基底,其对应的特征值可以看成是频率,对拉普拉斯矩阵进行特征值分解的公式如下:
ΔΦk=ΦkΛk(2.1)
其中Δ是拉普拉斯矩阵,而Φk是前k个拉普拉斯特征向量组成的矩阵,而Λk是由对应特征值组成的对角矩阵。我们接下来先暂时忘记这个(2.1)公式,我们要对整个图的拓扑结构进行表示,那么通过邻接矩阵A就可以很容易的表示出来,其中,无向图的邻接矩阵是对称矩阵,而有向图的邻接矩阵则不一定,让我们举一个例子方便接下来的讨论,如Fig 4所示,这是个无向图的例子。其中我们之前谈到的拉普拉斯矩阵可以用公式(2.2)
L=D−A(2.2)
确定,其中D为度数矩阵,A为邻接矩阵,整个过程如Fig 4.所示。
![在这里插入图片描述]()
Fig 4. A sample of a graph.
总的来说,用拉普拉斯矩阵可以在某种程度上表示一个Graph的拓扑结构,这点和邻接矩阵相似。
注意到我们有对拉普拉斯矩阵L的特征值分解:
LU=UΛ(2.3)
其中U=[u0,⋯,un−1]∈Rn×n为正交矩阵,其每一列都是特征向量,而Λ=diag([λ0,⋯,λn−1])∈Rn×n是一个对角矩阵,其每个对角元素都是对应特征向量的特征值。对式子(2.3)进行变换,注意到正交矩阵的转置等于其逆,我们有:
L=UΛU−1=UΛUT(2.4)
因此,对于一个给定信号x∈Rn来说,其傅立叶变换可以定义为 x^=UTx∈Rn,其反傅立叶变换为 x=Ux^,我们用符号 ∗G 表示图傅立叶变换。那么对于信号x和卷积核y,我们有:
x∗Gy=U((UTx)⊙(UTy))(2.5)
其中⊙表示逐个元素的相乘。
那么对于一个卷积核gθ(⋅),我们有:
y=gθ(L)(x)=gθ(UΛUT)x=Ugθ(Λ)UTxwhere gθ(Λ)=diag(θ)=⎣⎢⎡θ1⋮0⋯⋱⋯0⋮θn−1⎦⎥⎤(2.6)
其中我们需要学习的参数就在diag(θ)中,一共有n个。
类似于一般欧几里德结构数据的傅立叶变换,在图傅立叶变换中,其每个基底(也就是特征向量)也可以可视化出来,如Fig 5所示:
![vis]()
Fig 5. 图傅立叶变换的基底可视化,每个红色区域的都是卷积核中心,可以类比为热传递中的热量中心。
![vis2]()
Fig 6. manifold傅立叶变换的基底可视化,每个红色区域的都是卷积核中心,可以类比为热传递中的热量中心,对于Manifold来说也有类似的性质。
ChebNet, 切比雪夫网络
上面介绍的网络有两个很大的问题:
- 它们不是在空间上具有局部性的,比如二维图像的卷积网络就具有局部性,也称之为局部连接,某个输出神经元只是和局部的输入神经元直接相连接。这个操作有利于减少计算量,参数量和提高泛化能力。
- 计算复杂度为O(n),和节点的数量成比例,不利于应用在大规模Graph上。
为了解决第一个问题,我们把gθ(Λ)写成:
gθ(Λ)=k=0∑KθkΛk,θ∈RK是一个多项式系数(3.1)
我们在图论中知道有个结论:
若节点 i和节点 j的最短路径dG(i,j)>K,那么有 (LK)i,j=0,其中 L 为拉普拉斯矩阵。
因此有:
(gθ(L)δi)j=(gθ(L))i,j=k∑=θk(Lk)i,j(3.2)
不难看出当k>K,其中K为预设的核大小 时, (Lk)i,j=0,因此式子(3.2)其实只有前K项不为0,因此是具有K-局部性的,这样我们就定义出了局部性,那么计算复杂度变成了O(K)。
注意到,在式子y=Ugθ(Λ)UTx中,因为U∈Rn×n,因此存在U,UT的矩阵相乘,其计算复杂度为O(n2),而且每次计算都要计算这个乘积,这个显然不是我们想看到的。
一种解决方法就是把gθ(L)参数化为一个可以从L递归地计算出来的多项式,用人话说就是可以k时刻的gθ(L)可以由k−1时刻的gθ(L)简单地通过多项式组合计算出来。在文章[5]中,使用了切比雪夫多项式展开作为这个近似的估计。该式子可表示为:
Tk(x)=2xTk−1(x)−Tk−2(x), where T0=1,T1=x(3.3)
因此我们最后有:
gθ(Λ)=k=0∑KθkTk(Λ~)(3.4)
式子(3.4)仍然是和Λ有关的值,我们希望直接和L相关,以便于计算,因此继续推导,有:
gθ(Λ)Ugθ(Λ)UT=k=0∑KθkΛk=k=0∑KθkUΛkUT(3.5)
注意到U是幂等矩阵,也就是有Uk=U,因此继续推导(3.5)有:
UΛkUT=(UΛUT)k=Lk⇒Ugθ(Λ)UT=k=0∑KθkLk(3.6)
同样的,采用切比雪夫多项式展开,有:
gθ(Λ)≈k=0∑KθkTk(L~)(3.7)
因此,最后对于第j个输出的特征图而言,我们有:
ys,j=i=1∑Fingθi,j(L)xs,i∈Rn(3.8)
其中xs,i是输入的特征图,s表示第s个样本。因此我们一共有Fin×Fout个向量,每个向量中有K个参数,因为θi,j∈RK,最后一共有Fin×Fout×K个可训练参数。其中的gθi,j(L)是采用了切比雪夫多项式展开,因此可以递归运算,以减少运算复杂度。
ChebNet一阶近似
根据我们之前的讨论,K阶的ChebNet可以表示为:
y=Ugθ(Λ)UTx=k=0∑KθkUΛkUTx(4.1)
我们从VGG网络的设计中知道,3*3的卷积核在足够多的的层数的叠加后,有足够的层次信息可以提供足够大的感知野[6]。因此,也许对于ChebNet的一阶近似就足够了,因此我们将K=1,有:
yK=1=θ0x+θ1Lx=θ(D−21AD−21)x(4.2)
在式子(4.2)中,我们假设了θ0=−θ1以进一步减少参数量,而且对拉普拉斯矩阵进行了归一化,这个归一化操作我们接下来会继续讨论,这里暂且给出归一化的公式为:
L=In−D−21AD−21(4.3)
其中,D是度数矩阵,Di,i=∑jAi,j。
另外,为了增加节点自身的连接(这个我们以后继续讲解),我们通常会对邻接矩阵A进行变化,有:
A~D~i,i=A+In=j∑A~i,j(4.4)
因此最终有ChebNet的一阶近似结果为:
gθ ∗Gx=θ(D~−21A~D~−21)x(4.5)
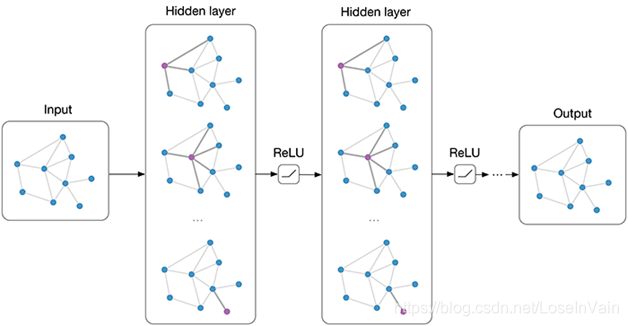
对(4.5)进行矩阵表达并且加入激活函数σ(⋅),有 Graph Convolution Network(GCN) 的表达[7],如:
H(l+1)=σ(D~−21A~D~−21H(l)W(l))(4.6)
其中的H(l)是l层的特征图,W(l)是l层的可学习参数。其中激活函数一般选择ReLU,即是σ(x)=max(0,x)。
![GCN]()
本篇文章就此结束,我们在下一篇文章将会继续介绍GCN在空间域上的理解,即是基于消息传递(Message Passing)中的解释,并且会举出一些例子来方便理解。
Reference
[1]. https://blog.csdn.net/LoseInVain/article/details/88373506
[2]. https://en.wikipedia.org/wiki/Adjacency_matrix
[3]. https://www.zhihu.com/question/54504471/answer/630639025
[4]. https://blog.csdn.net/wang15061955806/article/details/50902351
[5]. Defferrard M, Bresson X, Vandergheynst P. Convolutional neural networks on graphs with fast localized spectral filtering[C]//Advances in neural information processing systems. 2016: 3844-3852.
[6]. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[7]. Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[J]. arXiv preprint arXiv:1609.02907, 2016.




 浙公网安备 33010602011771号
浙公网安备 33010602011771号