C语言中去除不必要的内存引用可以有效地提高性能
在C语言中,我们经常会存在对某个内存地址进行引用的操作,也就是如下列代码所示的,对指针进行取内容:
int vars[10];
int var = *(vars+3); //这里就是对数组vars的第三个元素进行引用
这种内存引用操作对应的汇编代码通常如:
mov (%rax), %rdx;
# 把地址位于%rax的内存值进行取出。
mov 12(%rax), %rdx;
# 把地址位于%rax+12的内存值进行取出。
我们注意到这种操作涉及到了CPU从数据总线中向内存中取值,通常速度远远慢于CPU本身的计算操作,也慢于CPU取出内部寄存器值的操作,很多时候,一个程序的计算瓶颈就在这些去内存的操作中,因此要尽量避免不必要的内存引用。以下举个代码例子进行进一步说明。
// code_1.c
#include <stdio.h>
void foo(float vars[], int length, float *sum){
int i = 0;
for (i = 0; i < length; i++){
*sum = *sum * vars[i];
}
}
int main(){
float sum = 1;
float vars[] = {0.3,0.4,0.13,0.65,0.23,0.87,0.2,1.34};
int cycle = 0;
for (cycle = 0; cycle < 100000000; cycle++){
foo(vars, 8, &sum);
sum = 1;
}
return 0;
}
// code_2.c
#include <stdio.h>
void foo(float vars[], int length, float *sum){
int i = 0;
int tmp = *sum;
for (i = 0; i < length; i++){
tmp = tmp * vars[i];
}
*sum = tmp;
}
int main(){
float sum = 1;
float vars[] = {0.3,0.4,0.13,0.65,0.23,0.87,0.2,1.34};
int cycle = 0;
for (cycle = 0; cycle < 100000000; cycle++){
foo(vars, 8, &sum);
sum = 1;
}
return 0;
}
code_1.c和code_2.c的差别很小,就是在于函数foo()中关于sum这个指针的指向的内容的更新方式,第一种方式是每一个循环中都进行更新,显然其需要更多但是却没必要的内存引用,第二种通过一个临时变量的形式,避免了多次频繁无用地访问内存。观察其两者的汇编,就会发现和我们之前分析的是一致的。
我们采用-O1优化选项,命令如:
gcc -O1 -S code_1.c
gcc -O1 -S code_2.c
汇编结果如下所示(以下汇编只是截取部分关键信息)
# code_1.s
.L3:
movss (%rdx), %xmm0
mulss (%rax), %xmm0
movss %xmm0, (%rdx)
addq %4, %rax
cmpq %rcx, %rax
jne .L3
而第二个则简单很多
# code_1.s
.L3:
mulss (%rax), %xmm0
addq %4, %rax
cmpq %rcx, %rax
jne .L3
我们发现,第一个代码比起第二个代码多出很多内存引用操作,其需要从内存中取出乘数 movss (%rdx), %xmm0,计算完之后,有需要更新,将其写回内存, movss %xmm0, (%rdx)。导致其性能逊于后者。在笔者的服务器上,两者的性能具体对比为:
code 1跑了0.54s,而code 2跑了0.37s。

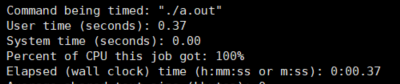
同时我们发现,编译器很难对此进行优化,在-O1优化等级下,其表现和我们分析的并没有区别(某些编译器优化会导致代码分析和实际的汇编有所区别),其还没有能够智能到对这种进行优化,因此需要程序员对此进行显式地优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号