

搭建高可用K8S集群
搭建高可用K8S集群
说明:高可用的K8S集群,需要用到虚拟IP漂移技术。虚拟IP跟多台主机的IP相映射,外界只需要访问虚拟IP,就可以访问到主机,而无需关注具体访问的是哪一台主机。虚拟IP技术,可参考 https://www.cnblogs.com/fasionchan/p/10417177.html 和 https://www.cnblogs.com/myseries/p/11409895.html。本文重点在实操。
一、主机和网络规划
K8S高可用集群,需要用到etcd存储,etcd是一个采用了raft一致性算法的分布式键值存储系统。因此至少需要3台主机作为master。主机的 存活数 和 失败容忍 可参考 https://www.cnblogs.com/ants/p/11489598.html#_label0 。我的主机和网络规划如下:
ens33 k8s-master01 172.20.111.73
ens33 k8s-master02 172.20.111.80
ens33 k8s-master03 172.20.111.86
k8s-vip 172.20.111.22
其中,虚拟IP是没有被其他主机使用的IP。这台IP不会绑定到任何主机上。
二、安装和配置 keepalived
需要在三台 k8s master主机上操作。
1. 安装keepalived
keepalived 是实现IP虚拟漂移的关键技术。需要在三台K8S master主机上安装。
yum install -y keepalived
2.配置keepalived 虚拟漂移
三台K8S master主机,都需要进行配置。
cat <<EOF > /etc/keepalived/keepalived.conf
! /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
script_user root
enable_script_security
router_id LVS_DEVEL
}
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 50
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
172.20.111.22
}
track_script {
check_apiserver
}
}
EOF
在上面的文件中替换自己相应的内容:
STATE 如果是主节点 则为MASTER 其他则为 BACKUP。我这里选择k8s-master01为MASTER;k8s-master02 、k8s-master03为BACKUP;
INTERFACE是网络接口,即服务器网卡的,我的服务器均为eth33;
ROUTER_ID 这个值只要在keepalived集群中保持一致即可,我使用的是默认值51;
PRIORITY 优先级,在master上比在备份服务器上高就行了。我的master设为100,备份服务50;
AUTH_PASS 这个值只要在keepalived集群中保持一致即可;123456
APISERVER_VIP 就是VIP的地址,我的为:172.20.111.22。
3.配置keepalived 健康检查
三台k8s master主机都要配置。
vi /etc/keepalived/check_apiserver.sh
### 添加内容
#!/bin/sh
errorExit() {
echo "*** $*" 1>&2
exit 1
}
curl --silent --max-time 2 --insecure https://localhost:16443/ -o /dev/null || errorExit "Error GET https://localhost:16443/"
if ip addr | grep -q 172.20.111.22; then
curl --silent --max-time 2 --insecure https://172.20.111.22:16443/ -o /dev/null || errorExit "Error GET https://172.20.111.22:16443/"
fi
APISERVER_VIP 就是VIP的地址,172.20.111.22;
APISERVER_DEST_PORT 这个是和apiserver交互的端口号,其实就是HAProxy绑定的端口号,因为HAProxy和k8s一起部署,这里做一个区分,我使用了16443,这个下面会说到。
4.启动keepalived,并设置开启自启动。
三台k8s master 主机都要启动
systemctl start keepalived #启动keepalived
systemctl enable keepalived #写入注册表,开启自启动
5.测试虚拟IP漂移
在master01上查看虚拟IP映射情况
ip addr show ens33
执行命令后,可以看到虚拟IP映射到了master01上。
ping 虚拟IP,如果虚拟IP能ping通,说明是可以工作的。
ping 172.20.111.22
关掉 master01,在执行 ping 172.20.111.22,如果发现还能ping通,说明已经漂移到其他master主机,在其他主机 执行ip addr show ens33,可查看具体漂移到哪台master主机。
(可以通过 systemctl status keepalived 查看服务状态,具体问题具体分析)
通过虚拟IP技术 keepalived,可以实现多台主机之间的高可用。用户只需要访问虚拟IP即可,而无需知道是具体是哪台主机做出的响应。
三、安装和配置haproxy
1. 安装haproxy(3台主机都要操作)
在安装haproxy之前,三台K8S master主机执行K8S集群搭建的 1到8步骤。这些步骤参考https://www.cnblogs.com/Fengyinyong/p/14682770.html
haproxy实现了负载均衡的作用,当通过虚拟IP访问K8S集群时,会访问到漂移到的具体K8S master 主机,再由该主机上的haproxy 将请求 负载均衡到三台K8S master主机。三台K8S master主机都要安装haproxy。
可以理解为,keepalived 负载实现高可用,只要由一台能工作,就可以通过虚拟IP访问到。haproxy负责实现负载均衡。
yum install -y haproxy
2.配置 haproxy(3台主机都要操作)
打开 /etc/haproxy/haproxy.cfg ,并替换成如下内容:
# /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
log /dev/log local0
log /dev/log local1 notice
daemon
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 1
timeout http-request 10s
timeout queue 20s
timeout connect 5s
timeout client 20s
timeout server 20s
timeout http-keep-alive 10s
timeout check 10s
#---------------------------------------------------------------------
# apiserver frontend which proxys to the masters
#---------------------------------------------------------------------
frontend apiserver
bind *:16443 # APISERVER_DEST_PORT
mode tcp
option tcplog
default_backend apiserver
#---------------------------------------------------------------------
# round robin balancing for apiserver
#---------------------------------------------------------------------
backend apiserver
option httpchk GET /healthz
http-check expect status 200
mode tcp
option ssl-hello-chk
balance roundrobin
server k8s-master01 172.20.111.73:6443 check # ${HOST1_ID} ${HOST1_ADDRESS}:${APISERVER_SRC_PORT}
server k8s-master02 172.20.111.80:6443 check
server k8s-master03 172.20.111.86:6443 check
APISERVER_DEST_PORT 这个值同上面的keepalived健康检查脚本里面的值一样,我这里使用16443;
${HOST1_ID} ${HOST1_ADDRESS}:${APISERVER_SRC_PORT} 其实就是你的k8s主节点的配置
3.启动,并设置开启自启动。
systemctl start haproxy
systemctl enable haproxy
此时用 systemctl status haproxy查看状态,会发现haproxy是启动的,但是收不到任何服务。那是因为我们完整搭建K8S集群。
如下所示:
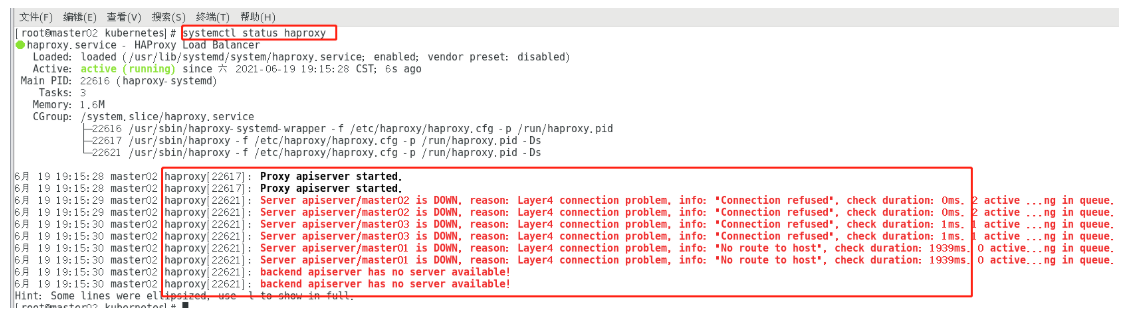
四 配置网络,搭建集群
这一步骤,不再赘述,这里只说不同点。参考 K8S单点集群搭建 https://www.cnblogs.com/Fengyinyong/p/14682770.html
1、不同点一:集群初始化
第一次和第二次初始化,采用的是虚拟IP+haproxy设置的16443端口。只在master01上执行。
第一次初始化
kubeadm init --control-plane-endpoint "172.20.111.22:16443" \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.20.0 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--upload-certs | tee kubeadm-init.log \
第二次初始化
kubeadm init --control-plane-endpoint "172.20.111.22:16443" \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.20.0 \
--service-cidr=10.1.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--apiserver-bind-port=6443 \
--ignore-preflight-errors=all \
--upload-certs | tee kubeadm-init.log
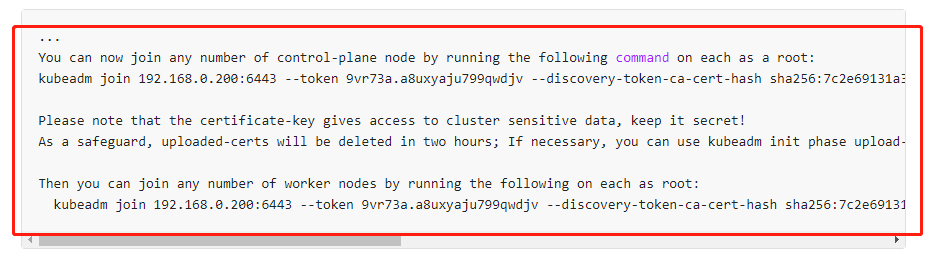
2、不同点二:master和node的加入集群指令
执行完初始化后,会输出两个加入集群的指令,一个是用于node集群加入的,一个是用于master集群加入的。其他 master 和 node 分别执行对应的指令
3、不同点三:三个k8s master都要执行默认指令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
第一个主master 在初始化的时候执行,其他master 在执行加入集群命令后 执行。
4、不同点四:指令token过期
master加入集群的指令token只有两个小时有效。失效后,需要重新生成。可参考官网 https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/#steps-for-the-first-control-plane-node


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!