

K8S核心概念
K8S基础概念
说明:(此文为个人学习笔记)阅读本文需要知道 docker,以及docker 自带的 swarm + compose集群编排;熟悉linux,会基本的指令操作。
一、什么是K8S
1.K8S 是容器编排引擎。(docker-compose 是docker 自带的容器编排工具,docker swarm是docker 自带的 docker 集群工具)。
2.K8S的功能=docker-compose的功能+docker-swarm的功能。
二、为什么要使用k8s
swarm的优点(业务量不是非常大,且业务简单的情况):
1.架构简单,部署运维成本低
docker swarm 集群模式由于原生态集成到docker-engine中,所以首先学习成本低,对于使用docker-engine 1.12版本及以上可以平滑过渡,service服务可以满足动态增减容器个数,同时具备自身的负载均衡,swarm管理者多台设定保
证了机器在出错后有一个良好的容灾机制
2.部署非常简单:swarm 命令搞定集群
3.启动速度快:swarm集群只会有两层交互,容器启动是毫秒级
swarm的缺点:
1.无法提供精细化管理容器:swarm API兼容docker API,所以使得swarm无法提供集群的更加精细的管理
2.网络问题。
不支持主机与主机之间通信,容器与容器之间的互联,以及容器对外端口暴露(通过service 来暴露端口,而不是容器)。在网络方面,默认docker容器是通过桥接与NAT和主机外网络通信,这样就出现2个问题,一个是因为是NAT,外部主机无法主动访问到容器内(除了端口映射),另外默认桥接IP是一样的,这样会出现不同主机的容器有相同的IP的情况。这样两容器更加不能通信。同时网络性能方面,有人测试经过桥接的网络性能只有主机网络性能的70%。当然以上问题可以通过其他工具解决,比如用 Flannel 或者 OVS网桥。
3.容器可靠性差,容器宕机了,无法重启。
在容器可靠性方面,相较于Kubernetes的Replication Controllers可以监控并维持容器的生命,swarm在启动时刻可以控制容器启动,在启动后,如果容器或者容器主机崩溃,swarm没有机制来保证容器的运行。
K8S的优点(业务量非常大,且业务非常复杂的情况):
1.提供精细化容器管理
2.健康的监控机制:Replication Controllers可以监控并维持容器的生命
3.能够应对复杂的网络环境。
kubernetes默认使用Flannel作为overlay网络。Flannel是CoreOS 团队针对 Kubernetes 设计的一个覆盖网络(OverlayNetwork)工具,其目的在于帮助每一个使用 Kuberentes 的CoreOS 主机拥有一个完整的子网。
K8S的缺点:
1.配置,学习成本高。搭建集群复杂麻烦。
2.启动很慢。因为有5层交互。
三、K8S 的集群概念
(一).节点:master与node
K8S集群的节点中有两个角色,一个角色是master,用于管理集群。另一个是Node,负责容器的运行,相当于swarm中的worker节点。他们的关系如下:
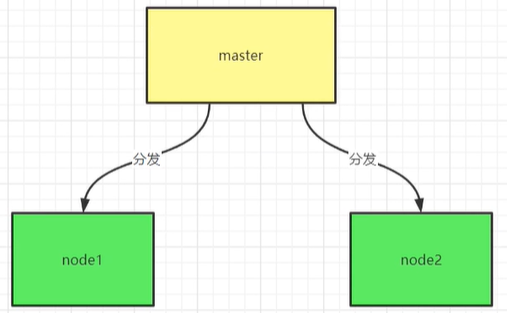
集群中的master 节点主机,负责管理 node 节点主机。node 节点负责运行docker 容器。
(二).K8S的三个工具:kubeadm,kubectl,kubelet
kubeadm:用于管理K8S集群,加入集群,脱离集群等。
kubectl:客户端,用来操作K8S。
kubelet:用来启动容器,操作docker的。
三者的关系如下:
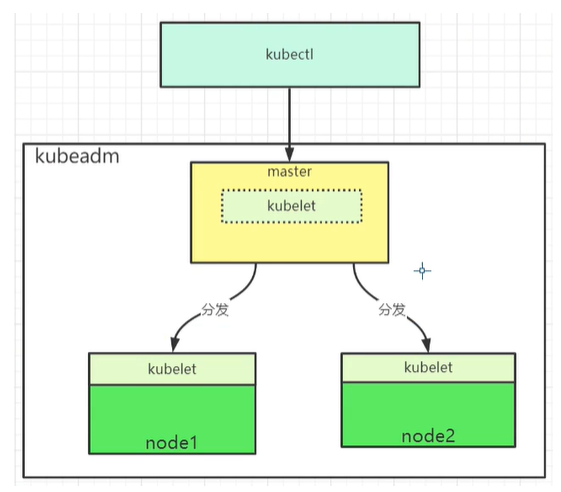
1.节点角色分配:kubeadm 定义 master节点、node节点,首先kubeadm 初始化一个master节点,然后再将其他节点加入到master,作为node节点由它管理(相当于swarm定义manager节点、worker节点,其工作方式与swarm类似)。
2.操作K8S集群:通过kubectl发送指令到master节点,master节点会将指令转发到每个节点上的kubelet,kubelet 再去启动相应的docker 容器。
四、K8S的几个核心概念-资源
1、Pod:K8S的最小管理单元
pod 是k8s的最小管理单元,容器运行在pod,一个容器可运行多个pod。pod 和 容器的关系如下:

kubectl run 运行容器pod,可 kubectl run -h 查看用法。
2.Deployment:副本集部署,弹性伸缩
通常,在一个节点上运行kubectl run,只在该节点上运行一个pod,pod里面运行指定镜像的容器。然而在K8S集群中,我们需要在多个主机,同时运行同一个pod。也就是master在创建pod的时候,让pod在多个node 工作节点运行,这也叫副本集。其中一个node宕机了,还有其他node的pod在工作。当宕机的node重启后,或者加入新的node节点时,会根据pod配置的数量决定是否也在该节点启动pod,这叫弹性伸缩。这时就需要用到Deployment。 kubectl create deployment -h 可查看其创建方式。(kubectl create -h 可查看创建其他资源的命令)
1. 副本集:创建pod,同时复制多个,随机部署到节点上。
2. 弹性伸缩:当节点宕机,或者新加入节点时,根据该pod副本集配置数量决定是否在该节点运行pod。
3.Service:对外暴露服务。
K8S创建的pod或者是deployment,是不能够被外界直接访问的(主机ip+端口访问)。需要对pod或deployment 进行服务暴露。Service 就是用来暴露服务的。 kubectl create service -h 查看使用方式。如 kubectl expose pod nginx-pod --port=80 --target-port=80 --type=NodePort # 暴露nginx pod(暴露给外界进行访问) ,type=NodePort才可以被访问。
4.K8S 运行Pod原理
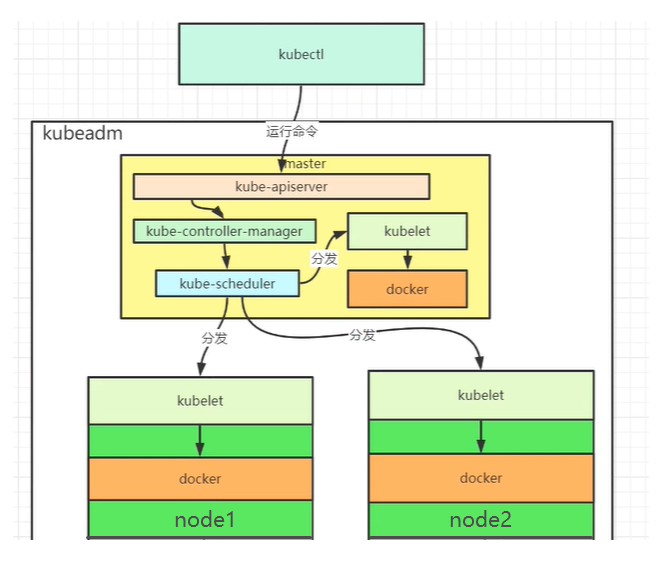
从图中可以看出,master的组件比较多,node的组件比较少。也可以在 master 和 node 节点,通过docker images 查看各自的K8S组件。
首先kubectl 发起run命令,run命令发送到kube-apiserver组件。kube-apiserver 接收到run 命令后,将命令转发到kube-controller-manager组件。这个组件是专门用来创建pod 以及pod 副本集Deployment的。kube-controller-manager创建pod 以及副本集后, 会委托任务调度组件 kube-scheduler将命令分发到各个节点,任务分发是随机的。kubelet 接收到 kube-scheduler分发的命令之后,操作docker运行docker的容器。至此,一个完整的pod 生命周期搞定。
(副本集 deployment,可理解为将一个pod,复制多分,随机分发到各个node,在各个node 运行该pod)
5.k8s 访问原理
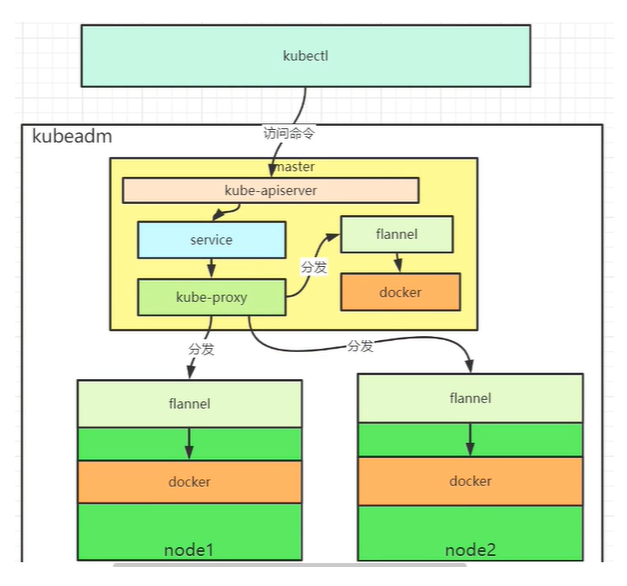
首先master 节点的kubectl 开始访问,输入IP,端口号,命令。kube-apiserver 接收到访问命令后,将请求转发到service。service接收到命令后,会委托kube-proxy,这个组件是用来做负载均衡的。kube-proxy 将请求负载到具体node之后,由网络flannel 支持负载。flannel 收到之后,开始访问具体的容器。etcd 是用来配置pod的,所有的pod,都存储在etcd 里面。
查看docker 网络:docker network ls。
(可以搭建高可用的K8S集群,即多个master节点)

