
个人一些排查经验分享-持续更新
分享一:
elk收集日志多样化,对指定多行的数据按照一行来进行收集,因此我们在filebeat里面配置multiline参数。但是这个多行的数据超过500行会出现丢弃数据的现象,这是因为filebeat的某个参数导致的,这里面我们配置一下
filebeat有个配置max_lines,默认值为500。查看了我们的日志文件,发现需要合并的日志行数超过了500行。
max_lines
The maximum number of lines that can be combined into one event.
If the multiline message contains more than max_lines, any additional lines are discarded. The default is 500.
所以我们增加一下这个配置
multiline.max_lines: 10000
分享二:
filebeat采集多行日志的时候会把日志分开来采集,这样传递到logstash的时候就无法正确解析了,所以用把多行日志统一采集。
这时候可以使用:multiline配置选项。
multiline:适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。这个配置的下面包含如下配置:
pattern:多行日志开始的那一行匹配的pattern
negate:是否需要对pattern条件转置使用,不翻转设为true,反转设置为false
match:匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
max_lines:合并的最多行数(包含匹配pattern的那一行)
timeout:到了timeout之后,即使没有匹配一个新的pattern(发生一个新的事件),也把已经匹配的日志事件发送出去
样例展示:
multiline:
pattern: '^\['
negate: true
match: after
分享三:
在sudoers文件里面已经配置普通用户不能使用su命令,但是并不是很安全。因为普通用户还可以通过sudo -i 或 sudo -s进入root模式,所以我们可以这样子做
apuserALL=(ALL:ALL) ALL,!/bin/bash
分享四:
查看网卡使用mii-tool命令后结果是这样的
mii-tool eth0
SIOCGMIIPHY on 'eth0' failed: Resource temporarily unavailable
大概率就是网口坏掉了,换一个。当然驱动方面问题也有可能。
分享五:
PHP执行权限导致"FastCGI sent in stderr: "Primary script unknown"
在近期一次上线web应用部署过程中,相同的配置在测试环境中并没有出现任何问题。部署在生产环境3台服务器上时,一直出现“file not found”,查看nginx服务器的error日志出现了如下错误:
020/07/05 16:32:05 [error] 28033#0: *3 FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, client: 192.0.61.175, server: baogebiji.com, request: "POST /www/getClientInfoList.php HTTP/1.1", upstream: "fastcgi://unix:/dev/shm/php-cgi.sock:", host: "192.0.61.176", referrer: "http://192.0.61.176/www"
生产环境的部署脚本及配置文件均一摸一样,出现这样的问题感觉到很恐慌。
一、测试php是否正常可以进行
在网站根迷路下,部署test.php文件,访问网站,发现是没有问题的。
二、检查网站运行权限
1、检查nginx.conf文件,nginx运行的用户为app200。
2,检查网站目录,均为app200。
3,检查php运行权限。
查看php的配置文件看看权限
$ cat /usr/local/php/etc/php-fpm.conf
;;;;;;;;;;;;;;;;;;;;;
; FPM Configuration ;
;;;;;;;;;;;;;;;;;;;;;
;;;;;;;;;;;;;;;;;;
; Global Options ;
;;;;;;;;;;;;;;;;;;
[global]
pid = run/php-fpm.pid
error_log = log/php-fpm.log
log_level = warning
emergency_restart_threshold = 30
emergency_restart_interval = 60s
process_control_timeout = 5s
daemonize = yes
;;;;;;;;;;;;;;;;;;;;
; Pool Definitions ;
;;;;;;;;;;;;;;;;;;;;
[www]
listen = /dev/shm/php-cgi.sock
listen.backlog = -1
listen.allowed_clients = 127.0.0.1
listen.owner = www
listen.group = www
listen.mode = 0666
user = www
group = www
发现user和group均使用www用户,修改以上www用户为app200后,重启systemctl restart php-fpm。故障解除。
总结:
出现该问题的原因事后回忆,因默认安装使用的均为www用户。在应用提出希望使用app200用户可以拥有更新网站的权限后,将nginx及网站权限调整为app200,php-fpm运行权限为www,网站二级目录没有访问权限导致。
分享六:
启动sshd服务后,是正常的,但是客户端并不能连接上sshd服务器端。通过查看日志,显示如下:
Could not load host key: /etc/ssh/ssh_host_rsa_key
从提示信息看是sshd守护进程不能加载主机密钥文件,因为找不到这些密钥文件(配置文件/etc/ssh/sshd_config中已定义密钥文件名与路径)。 一般openssh服务正常安装后,主机会自动生成相应的主机密钥文件,但这里因未知原因并没有完成这一步动作,导致无法远程ssh连接。
所以解决方法就是重新生成主机密钥文件
[root@aefe8007a17d ~]# ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
[root@aefe8007a17d ~]# ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key
[root@aefe8007a17d ~]# ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key
再次登录发现正常了,远程主机也可以连接。
分享七:
redis 队列延迟 问题 , 该如何解决?
阻塞读在队列没有数据的时候,
会立即进入休眠状态,
一旦数据到来,
则立刻醒过来。消息的延迟几乎为零。
分享八:
安装zabbix的过程中,MySQL导库时报错ERROR 1050 at line 1761: table dbversion already exists
这种问题一般是MySQL的进程出现问题,重启一下MySQL就可以了。
再不行了就在导入表的那一行加上if not exists
分享九:
awk -v n=0 '!n++' /etc/passwd为什么只打印一行?
等价于awk -v n=0 '!n++{print $0}' /etc/passwd。读取第一行的时候,n=0,n++加完之后等于1,但本次返回0,所以在处理第一行的时候,!n++为!0,为true,所以输出第一行。而第二行以及第N行,n不在等于0,!n++为false,所以不在输出
*分享十:
使用rpm的方式把gitlab安装好之后,访问出现了502的错误。其中这种问题原因有很多,下面介绍其中一种方法:
先试用gitlab-rake gitlab:check检查是否有错误
发现如下所示:
[root@master1 gitlab-shell]# gitlab-rake gitlab:check
gitlab-shell self-check failed
Try fixing it:
Make sure GitLab is running;
Check the gitlab-shell configuration file:
sudo -u git -H editor /opt/gitlab/embedded/service/gitlab-shell/config.yml
Please fix the error above and rerun the checks.
那现在我们去修改/opt/gitlab/embedded/service/gitlab-shell/config.yml文件内容,
把其中的gitlab_url这个配置好,配置和/etc/gitlab/gitlab.rb这里面的external_url一样即可。这是一种临时解决的方法。
分享十一:
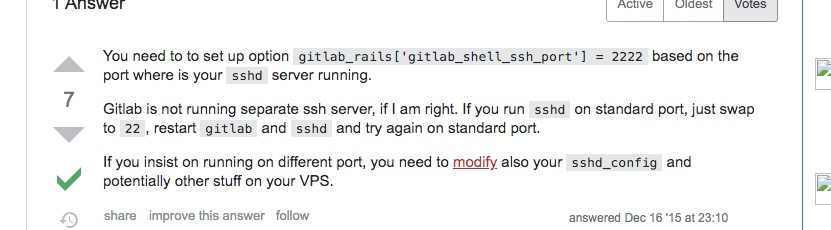
gitlab更换ssh端口。
这个我们直接修改配置文件/etc/gitlab/gitlab.rb,把其中的gitlab_rails['gitlab_shell_ssh_port'] = xxx,把其中的端口改成自己指定的端口即可。然后执行gitlab-ctl reconfigure。这个时候我们在web里面查看仓库地址可以看到拉取的ssh仓库地址的端口已经发生了变化。不过gitlab默认提供的端口是22端口。而像我们这样修改了其他的端口。那么还需要把sshd的配置文件里面把这个端口开启才行。
分享十二:
误删除/dev目录下的文件导致ssh不能成功连接,使用ssh -v查看到详细的报错信息如下所示:
[root@node1 ~]# ssh -v root@node2
OpenSSH_7.4p1, OpenSSL 1.0.2k-fips 26 Jan 2017
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: /etc/ssh/ssh_config line 58: Applying options for *
debug1: Connecting to node2 [192.168.50.132] port 22.
debug1: Connection established.
debug1: permanently_set_uid: 0/0
debug1: identity file /root/.ssh/id_rsa type 1
debug1: key_load_public: No such file or directory
debug1: identity file /root/.ssh/id_rsa-cert type -1
debug1: key_load_public: No such file or directory
把/dev目录下的内容删除了,这是因为urandom这些文件不存在了。所以我们需要恢复生成一下才可以。
mknod -m 0666 /dev/urandom c 1 9
有了这一个,立马就能连接ssh了。顺便这里把random也恢复一下
mknod -m 0666 /dev/random c 1 8
分享十三:
误删除/dev/null文件,如何恢复?
mknod -m 0666 /dev/null c 1 3
分享十四:
撤销MySQL的权限。有的MySQL的权限末尾带有with grant option,如何撤销这种权限呢?
REVOKE GRANT OPTION ON `xxx`.* from 'xxx'@'xxx';
分享十五:
nginx的日志如果更换名字,还能写进去日志吗?
因为linux文件系统中,改名并不会影响已经打开文件的写入操作,内核inode不变,所以依然能写进去日志。因此对于nginx的日志文件,做切割时,要备份旧的nginx的日志文件,因此我们要用mv而不是cp命令
分享十六:
bash是在子shell里执行,为什么结果在当前sehll显示?
举个稍微简单的例子
#!/bin/bash
echo aaaaa
对于这个脚本a.sh,在终端1中执行的时候,a.sh进程fork自当前终端的bash进程,所以a.sh进程继承了其父bash进程打开的文件描述符,所以a.sh的标准输出fd=1也关联到了这个终端上,echo进程是a.sh进程的子进程,所以再次继承fd=1关联到当前终端上,所以echo输出的内容才会显示在当前终端
分享十七:
keepalived启动后没有生成pid配置文件,是什么原因?
pid文件没有生成的原因是keepalived依然存在,stop keepalived没有用。keepalived的主进程被杀死了,子进程依然存在,没有被杀死。所以把keepalived杀死就可以了。pid文件没有这个问题原因就在这里,但是这个问题解决,还有一个就是为什么只杀死主进程,子进程没有被杀死呢?原因是sytsemd文件中的killMode的模式问题,一个有四个。control-group 、process、mixed、none。keepalived的默认是process,这个就表示只杀死主进程,子进程不被systemd杀死,因此最后改成control-group,意思是当前控制组里面的所有子进程,都会被杀掉。这样子就可以了。
分享十八:
执行脚本报错,脚本很简单,也没有常规性的错误,报“: bad interpreter: No such file or directory”错。一看这错,我就问他是不是在windows下编写的脚本,然后在上传到linux服务器的……果然。
原因:在DOS/Windows里,文本文件的换行符为rn,而在nix系统里则为n,所以DOS/Windows里编辑过的文本文件到了nix里,每一行都多了个^M。
解决:
1)重新在linux下编写脚本;
2)vi :% s/r//g :% s/^M//g (^M输入用Ctrl+v, Ctrl+m)
附:sh -x 脚本文件名 ,可以单步执行并回显结果,有助于排查复杂脚本问题。
分享十九:
问题:某天发现某台机器df -h已用磁盘空间为90G,而du -sh /*显示所有使用空间加起来才30G。
原因:可能某人直接用rm删除某个正在写的文件,导致文件删了但磁盘空间没释放的问题
解决:
1)最简单重启系统或者重启相关服务。
2)干掉进程
/usr/sbin/lsof|grep deleted
ora 25575 data 33u REG 65,65 4294983680 /oradata/DATAPRE/UNDOTBS009.dbf (deleted)
从lsof的输出中,我们可以发现pid为25575的进程持有着以文件描述号(fd)为 33打开的文件/oradata/DATAPRE/UNDOTBS009.dbf。在我们找到了这个文件之后可以通过结束进程的方式来释放被占用的空 间:echo > /proc/25575/fd/33
3)删除正在写的文件一般用 cat /dev/null > file
分享二十:
问题:在tmp目录下有大量包含picture_*的临时文件,每天晚上2:30对一天前的文件进行清理。之前在crontab下跑如下脚本,但是发现脚本效率很低,每次执行时负载猛涨,影响到其他服务。
#!/bin/sh
find /tmp -name “picture_*” -mtime +1 -exec rm -f {} ;
原因:目录下有大量文件,用find很耗资源。
解决:
#!/bin/sh
cd /tmp
time=`date -d “2 day ago” “+%b %d”`
ls -l|grep “picture” |grep “$time”|awk ‘{print $NF}’|xargs rm -rf
分享二十一
问题:某天研发某同事说网站前端环境http无法启动,我上去看了下。报如下错:
/etc/init.d/httpd start
Starting httpd: [Sat Jan 29 17:49:00 2011] [warn] module antibot_module is already loaded, skipping
Use proxy forward as remote ip : true.
Antibot exclude pattern : .*.[(js|css|jpg|gif|png)]
Antibot seed check pattern : login
(98)Address already in use: make_sock: could not bind to address [::]:7080
(98)Address already in use: make_sock: could not bind to address 0.0.0.0:7080
no listening sockets available, shutting down
Unable to open log [FAILED]
原因:
1)端口被占用:表面看是7080端口被占用,于是netstat -npl|grep 7080看了下发现7080没有占用;
2)在配置文件中重复写了端口,如果在以下两个文件同时写了Listen 7080
/etc/httpd/conf/http.conf
/etc/httpd/conf.d/t.10086.cn.conf
解决:
注释掉/etc/httpd/conf.d/t.10086.cn.conf的Listen 7080,重启,OK。
分享二十一
问题:报too many open file错误
解决:终极解决方案
echo “” >> /etc/security/limits.conf
echo “* soft nproc 65535″ >> /etc/security/limits.conf
echo “* hard nproc 65535″ >> /etc/security/limits.conf
echo “* soft nofile 65535″ >> /etc/security/limits.conf
echo “* hard nofile 65535″ >> /etc/security/limits.conf
echo “” >> /root/.bash_profile
echo “ulimit-n 65535″ >> /root/.bash_profile
echo “ulimit -u 65535″ >> /root/.bash_profile
最后重启机器 或者执行 ulimit -u 655345 && ulimit -n 65535
分享二十二:
背景
需要定期清理的索引的后缀日期格式为YYYY.MM.DD,如:project-index-2017.10.01
思路
通过_cat/indices接口可以获取当前ES全部索引信息,取第三列为索引名。过滤出索引名中带有的日期字符串,然后进行日期比较,早于10天前的日期便可通过日期模糊匹配索引来删除。
shell脚本定期清理es集群索引
#!/bin/bash
###################################
#删除早于十天的ES集群的索引
###################################
function delete_indices() {
comp_date=`date -d "10 day ago" +"%Y-%m-%d"`
date1="$1 00:00:00"
date2="$comp_date 00:00:00"
t1=`date -d "$date1" +%s`
t2=`date -d "$date2" +%s`
if [ $t1 -le $t2 ]; then
echo "$1时间早于$comp_date,进行索引删除"
#转换一下格式,将类似2017-10-01格式转化为2017.10.01
format_date=`echo $1| sed 's/-/\./g'`
curl -XDELETE http://es-cluster-ip:9200/*$format_date
fi
}
curl -XGET http://es-cluster-ip:9200/_cat/indices | awk -F" " '{print $3}' | awk -F"-" '{print $NF}' | egrep "[0-9]*\.[0-9]*\.[0-9]*" | sort | uniq | sed 's/\./-/g' | while read LINE
do
#调用索引删除函数
delete_indices $LINE
done
分享二十三:
redis做主从配置时,从库一直连接不上,从库日志显示:
1597:S 18 Sep 2020 18:54:02.725 * Connecting to MASTER 192.168.50.130:6379
1597:S 18 Sep 2020 18:54:02.726 * MASTER <-> REPLICA sync started
1597:S 18 Sep 2020 18:54:02.726 * Non blocking connect for SYNC fired the event.
1597:S 18 Sep 2020 18:54:02.727 * Master replied to PING, replication can continue...
1597:S 18 Sep 2020 18:54:02.728 * Partial resynchronization not possible (no cached master)
1597:S 18 Sep 2020 18:54:02.729 * Full resync from master: 3e2541925b253fc097625f75c350832f306ef6e4:0
1597:S 18 Sep 2020 18:54:02.815 # I/O error reading bulk count from MASTER: Resource temporarily unavailable
按照这个思路去百度或者谷歌上面搜索解决方法,大部分诸如这篇文件所讲的那样:https://blog.csdn.net/csd753111111/article/details/100428725,需要设置client-output-buffer-size的值,但是在这里这些方法依然没有作用。这里我们需要考虑几点可能出现IO错误的情况:
1、可能是磁盘错误,当然这种几率非常小。
2、就像上面所说的是buffer方面的情况,那么就按照上面链接所讲的设置一下
3、可能是权限方面造成的。
不过按照上面检查或许没有思路,我们不妨看看master节点的日志,master日志显示如下:
Failed opening the RDB file dump.rdb (in server root dir /) for saving: Permission denied
这条日志很怪,我的rdb文件为什么会报权限错误呢?所以赶紧看看这个rdb文件的权限属性问题。
[root@localhost rdb]# ll
total 4
-rw-r--r-- 1 root root 175 Sep 18 19:37 dump.rdb
这就很怪了,不明白为什么是root用户呢?redis服务启动后是以redis用户运行的,那么rdb文件同样也是redis用户的属性才对。看来有问题。所以解决方法就是把rdb文件属性改成redis即可。改完之后,主从正常。IO错误问题就消失了
分享二十四:
机器A配置了iptables防火墙,允许访问特定的主机,也允许特定的主机访问此主机A,但是主机A不能访问外网,现在要实现主机A能够访问外网,比如百度等。
iptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
添加上去这样的一条规则即可,把规则放在REJECT部分的上面,ACCEPT的下面。
分享二十五:
想要查看rpm包的组件,但是rpm又不能使用tar命令解压,所以我们可以这样设置
rpm2cpio xxx.rpm | cpio -div
分享二十六:
做harbor的https的时候,如果在./install.sh安装的时候报这个错

编辑prepare大约在498行,做如下修改

原文链接https://github.com/goharbor/harbor/issues/2920
这个是在1.5.3版本会出现,1.7.5版本以上会修复该问题
分享二十七:
如果在登录的时候报错:

这是因为系统默认安装了golang-docker-credential-helpers,卸载以后就好了apt purge golang-docker-credential-helpers
分享二十八:
生产中kvm物理主机直接宕机了,上面跑了好几台虚拟主机。然后启动的时候报错是这样的

其实这就是虚拟主机作用域的问题,大家可以看到default默认的作用域是rhel6.5.0,但是这个同学现在是以rhel6.6.0来启动的,所以就报了这样的错误。其实解决起来还是比较容易的,就是在这个主机的配置文件里面,把配置文件里面的一行,
分享二十九:
最近某位同学想这样来使用变量,如下所示:
for (( i=1;i <= 2;i++ ));do
read -p "Please input server$i IP: " IP$i
done
for (( i=1;i <= 2;i++ ));do
echo ${IP${i}}
done
上面这个脚本是有问题的,先来看看他的思路就是连续输入2次ip地址,分别赋值给IP1、IP2、IP3....。然后再取出这些IP1、IP2值。但事实上这个脚本拿不出来结果。所以我们需要了解一下下面这个概念,shell如何设置拼接的变量。echo ${!val} 也就是在获取变量的时候,加一个!叹号。
所以上面的需要修改一下,比如:
for (( i=1;i <= 2;i++ ));do
read -p "Please input server$i IP: " IP$i
done
for (( i=1;i <= 2;i++ ));do
bb=IP$i
echo ${!bb}
done
当然,也可以用数组的方式实现上面的思想,大家可以踊跃发挥
分享三十
reposync --repoid=extras-aliyun --download-metadata -p /var/www/html/centos/7/centos7作yum自建仓库 好几次了 都没同步到元数据
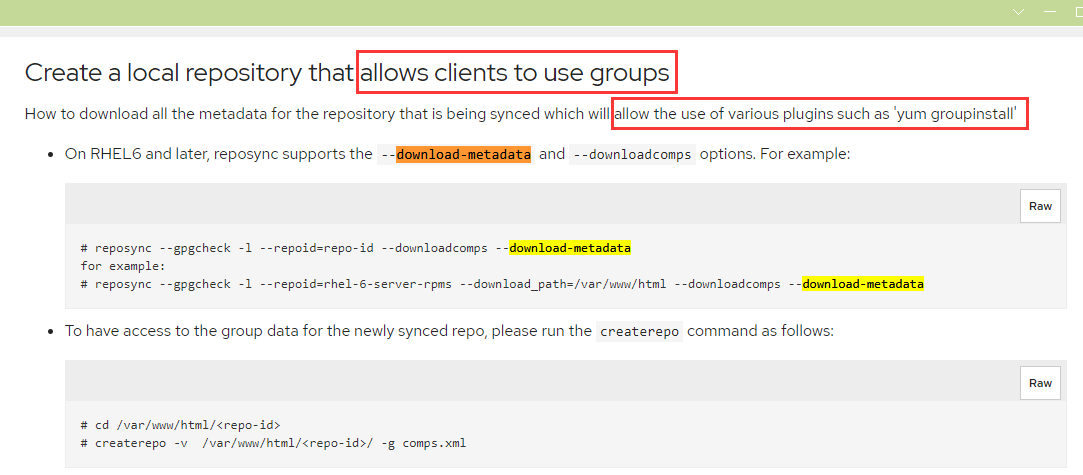
这个--download-metadata的效果是yum的客户端能使用yum groupinstall这个命令,不是下载repodata用的。repodata需要自己使用createrepo命令自己创建。
可以看看这个博客https://www.cnblogs.com/vilenx/p/12533361.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号