

MySQL数据库
阅读目录
- 数据库介绍
- MySql数据库
- pymysql模块
- SQLAlchemy-ORM
1.数据库概念
数据库即存放数据的仓库,只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的。
所谓“数据库”是以一定的数据模型组织、描述和储存在一起、能与多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。
2.什么是数据库管理系统(DataBase Management System 简称DBMS)
数据库:db(即文件夹)
数据库管理系统:如mysql(是一个软件)
数据库服务器:一台计算机(对内存要求比较高)
总结:
数据库服务器-:运行数据库管理软件
数据库管理软件:用于管理数据库的软件,管理-数据库
数据库:用于存储数据的地方,即文件夹,用来组织文件/表
表:即文件,用来存放多行内容/多条记录
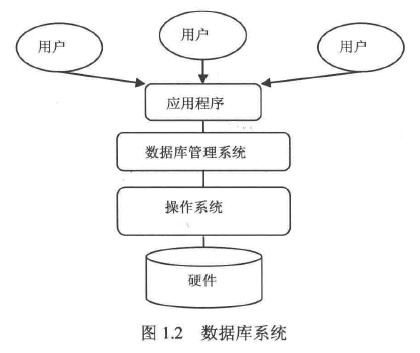
3.关系型数据库
关系数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。简单来说,关系模式就是二维表格模型。
如:
-
MariaDB(MySQL的代替品,英文维基百科从MySQL转向MariaDB)
-
Percona Server(MySQL的代替品·)
优点:
(1)容易理解,二维表的结构非常贴近现实世界,二维表格,容易理解。
(2)使用方便,通用的sql语句使得操作关系型数据库非常方便。
(3)易于维护,数据库的ACID属性,大大降低了数据冗余和数据不一致的概率。
缺点:
(1)因为数据和数据是有关系的,底层是运行了大量的算法
(2)大量算法会降低系统的效率,会降低性能
(3)面对海量数据的增删改查的时候会显的无能为力
(4)海量数据对数据进行维护变得非常的无力
4.非关系型数据库
非关系型数据库,又被称为NoSQL(Not Only SQL ),意为不仅仅是SQL( Structured QueryLanguage,结构化查询语言),NoSQL主要是指非关系型、分布式、不提供ACID (数据库事务处理的四个基本要素)的数据库设计模式。
NoSQL提出了另一种理念,以键值来存储,且结构不稳定,每一个元组都可以有不一样的字段,这种就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,为了获取用户的不同信息,不需要像关系型数据库中,需要进行多表查询。仅仅需要根据key来取出对应的value值即可。
如:
-
-
BigTable(Google)
-
-
-
Apache Cassandra(为Facebook所使用):高度可扩展
-
分类:
(1)面向高性能并发读写的key-value数据库
主要特点是具有极高的并发读写性能,例如Redis、Tokyo Cabint等。
(2)面向海量数据访问的面向文档数据库
特点是,可以在海量的数据库快速的查询数据。例如MongoDB以及CouchDB.
(3)面向可拓展的分布式数据库
解决的主要问题是传统数据库的扩展性上的缺陷。
缺点
但是由于Nosql约束少,所以也不能够像sql那样提供where字段属性的查询。因此适合存储较为简单的数据。有一些不能够持久化数据,所以需要和关系型数据库结合。
5.关系型数据库与非关系型数据库对比
存储上:
Sql通常以数据库表的形式存储,例如存储用户信息,SQL中增加外部关系的话,需要在原表中增加一个外键,来关联外部数据表。
NoSql采用key-value的形式存储
事务
SQL中如果多张表需要同批次被更新,即如果其中一张表跟新失败的话,其他表也不会更新成功。这种场景可以通过事务来控制,可以在所有命令完成之后,再统一提交事务。
在Nosql中没有事务这个概念,每一个数据集都是原子级别的。
数据表 VS 数据集
关系型是表格型的,存储在数据表的行和列中。彼此关联,容易提取。而非关系型是大块存储在一起。
预定义结构 VS 动态结构
在sql中,必须定义好地段和表结构之后,才能够添加数据,例如定义表的主键、索引、外键等。表结构可以在定义之后更新,但是如果有比较大的结构变更,就会变的比较复杂。
在Nosql数据库中,数据可以在任何时候任何地方添加。不需要预先定义。
存储规范 VS 存储代码
关系型数据库为了规范性,把数据分配成为最小的逻辑表来存储避免重复,获得精简的空间利用。但是多个表之间的关系限制,多表管理就有点复杂。
非关系型是平面数据集合中,数据经常可以重复,单个数据库很少被分开,而是存储成为一个整体,这种整块读取数据效率更高。
纵向拓展 VS 横向拓展
为了支持更多的并发量,SQL数据采用纵向扩展,提高处理能力,通过提高计算机性能来提高处理能力。
NoSql通过横向拓展,非关系型数据库天然是分布式的,所以可以通过集群来实现负载均衡。
其他方面
关系型是结构化查询语言,NoSql是采用更简单而且精确的数据访问方式;SQl数据库大多比较昂贵,而NoSql大多是开源的。
Mysql数据库
1.mysql
MySQL是一个跨平台开放源代码的关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一。
2.安装配置
下载地址:https://dev.mysql.com/downloads/mysql/
windows安装(压缩版直接解压):
初始化
服务端:bin目录下 mysqld --initialize-insecure
默认用户名 root
密码 空
注意:初始化之前需要删除默认的data文件,再创建data文件否则会初始化失败
启动服务器端:
bin目录下 mysqld
客户端连接:
bin目录下 mysql -u root -p
发送指令:
show databases;
create database db1
增加环境变量:
D:\Mysql\mysql-8.0.13-winx64\bin
安装Windows服务:
D:\Mysql\mysql-8.0.13-winx64\bin\mysqld --install 增加服务到windows
D:\Mysql\mysql-8.0.13-winx64\bin\mysqld --remove 删除服务
启动服务
net start MySQL
net stop MySQL
linux安装(略):
3.启动服务端和客户端
配置环境变量:

服务端:
对应安装版服务端已自动启动,无需手动启动
压缩版需要增加服务到windows服务中,再启动
安装Windows服务:
mysqld --install 增加服务到windows

删除windows服务:
mysqld --remove 删除服务

启动服务和停止服务:
net start MYSQL 启动服务
net stop MYSQL 停止服务

客户端:
客户端连接数据命令:(使用root用户,密码空)
mysql -u root -p

查看数据库:show databases;
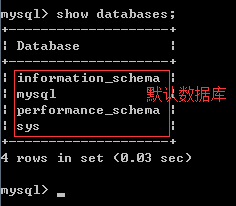
查看默认数据库mysql中的数据表:
use mysql;
show tables;

4.初识sql语句
SQL : 结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型:
- DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
- DML语句 数据库操作语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE
- DQL语句 数据库查询语言:SELECT语句
- DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE、COMMIT、ROLLBACK等语句
1.数据存储引擎概念
数据库存储引擎是数据库底层软件组件,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据操作。不同的存储引擎提供不通存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。现在许多不通的数据库管理系统都支持多种不同的数据引擎。Mysql的核心就是存储引擎。
2.mysql存储引擎分类:
mysql支持的数据引擎有:InnoDB、MyISAM、Memory、Merge、Archive、Federated、CSV、BLACKHOLE等。
InnoDB存储引擎:
事务型数据库的首选类型,支持事务安全表(ACID),支持行锁和外键。Mysql 5.5.5之后,InnoDB作为默认存储引擎。
主要特点:


MyISAM存储引擎:
MyISAM基于ISAM的存储引擎,并对其进行扩展,它是在Web、数据存储和其他应用环境下最常用的存储引擎之一。具有较高的插入、查询速度,但不支持事务。
主要特点:

使用MyISAM引擎创建的数据库,将生成3个文件,文件的名字以表的名字开始,扩展名指出文件类型:frm 文件存储表定义,数据文件的扩展名为.MYD(MYData),索引文件的扩展名为.MYI(MYIndex)。
Memory存储引擎:
将表中的数据存储到内存中,为查询和引用其他表数据提供快速访问。
主要特点:

几种存储引擎对比

如何使用数据引擎?
show engines; 语句查看系统所支持的引擎类型和默认使用的引擎类型。

show variables like "default_storage_engine"; 查询默认存储引擎

创建数据表时指定存储引擎和修改已存在表的存储引擎:
mysql> create table ai(id bigint(12),name varchar(200)) ENGINE=MyISAM; mysql> create table country(id int(4),cname varchar(50)) ENGINE=InnoDB; 也可以使用alter table语句,修改一个已经存在的表的存储引擎。 mysql> alter table ai engine = innodb;
配置文件中指定存储引擎:
#my.ini文件 [mysqld] default-storage-engine=INNODB
数据类型大致分为数字、字符、时间类型:
1.数字:
(1)tinyint[(m)] [unsigned] [zerofill]
小整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-128 ~ 127.
无符号:
0 ~ 255
(2)int[(m)][unsigned][zerofill]
整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-2147483648 ~ 2147483647
无符号:
0 ~ 4294967295
特别的:整数类型中的m仅用于显示,对存储范围无限制。例如: int(5),当插入数据2时,select 时数据显示为: 00002
(3)bigint[(m)][unsigned][zerofill]
大整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-9223372036854775808 ~ 9223372036854775807
无符号:
0 ~ 18446744073709551615
(4)FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
无符号:
-3.402823466E+38 to -1.175494351E-38,
0
1.175494351E-38 to 3.402823466E+38
有符号:
0
1.175494351E-38 to 3.402823466E+38
**** 数值越大,越不准确 ****
(5)DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 不太准确
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
无符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
0
2.2250738585072014E-308 to 1.7976931348623157E+308
有符号:
0
2.2250738585072014E-308 to 1.7976931348623157E+308
**** 数值越大,越不准确 ****
(6)decimal[(m[,d])] [unsigned] [zerofill] 精准
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
特别的:对于精确数值计算时需要用此类型
decaimal能够存储精确值的原因在于其内部按照字符串存储。
decimal(10,5) 表示整数部分加小数部分总位数为10位,小数点后有5位。
2.文本与字符串:
char(m) 速度快
char数据类型用于表示固定长度的字符串,可以包含最多达255个字符。其中m代表字符串的长度。
PS: 即使数据小于m长度,也会占用m长度
varchar(m) 节省空间
最大长度为m位,实际数据有多少为存多少位
varchars数据类型用于变长的字符串,可以包含最多达255个字符。其中m代表该数据类型所允许保存的字符串的最大长度,
只要长度小于该最大值的字符串都可以被保存在该数据类型中。
注:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出
varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡
ps:创建数据表定长列 往前放
text 数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。
mediumtext 16,777,215 (2**24 − 1) characters.
longtext 4,294,967,295 or 4GB (2**32 − 1) characters.
注意:
上传文件,文件存硬盘,db存路径
3.时间类型:
DATE
YYYY-MM-DD(1000-01-01/9999-12-31)
TIME
HH:MM:SS('-838:59:59'/'838:59:59')
YEAR
YYYY(1901/2155)
DATETIME
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y)
TIMESTAMP
YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
4.enum 枚举类型
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small');
5.set 集合类型
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
1.客户端登录数据库
mysql [-h localhost或IP] -u 用户名 -p [-P] [数据库名] [-e sql语句]
-h 主机名,可以使用该参数指定主机名或IP,如果不知道默认是localhost
-u 用户名
-p 密码 如果该参数后面有一段字段,则该字段字符将作为用户的密码直接登录,如果后面没有内容,则登录的时候会提示输入密码
注意:带密码登录时候,密码必须跟在-p后面,不能有空格
-P 端口号 该参数后面写mysql服务器的端口号 默认3306
数据库名 可以在命令的最后指定数据库名
-e 执行sql语句 如果指定了该参数,将在登录后执行-e后面的命令或sql语句
#使用root账户登录
mysql -u root -p
#使用其他账户登录
mysql -u 用户名 -p

2.创建用户
创建用户:
create user '用户名'@‘% | IP | localhost’ [identified by [password] 'passowrd';
create user 'felix'@'192.168.1.1' identified by '123456'; 创建用户为felix,密码为123456,只能以host 192.168.1.1 IP登录数据库
create user 'felix'@'192.168.1.%' identified by '123456';
create user 'felix'@'%' identified by '123456';
1.root用户修改密码
a.使用MySQLadmin命令在命令设置新密码
mysqladmin -u 用户名 -h localhost -p password 新密码
b.修改MySQL数据库的user表(不建议)
update mysql.user set Password=password('新密码') where user='root' and
host='localhost';
c.使用set语句修改root用户的密码
set password=password('新密码');
2.root用户修改普通用户的密码
a.使用set语句修改普通用户的密码
set password for '用户名'@'host' =password('新密码');
b.使用uodate语句修改普通用户密码
update mysql.user set password=password('新密码') where user='用户名'
and host='localhost | % | IP';
c.grant语句修改普通用户密码
grant usage on *.* to '用户名'@'%' identified by '新密码';
3.普通用户修改密码
set password=password('新密码');
4.root密码丢失解决办法
a.windows
(1)停止mysql服务
net stop MYSQL
(2)mysqld --skip-grant-tables 启动MySQL服务
(3)root免密码登录重置密码
mysql -u root
set password=password('新密码')
(4)加载权限表
flush privileges;
b.linux
使用MYSQLd_safe来启动MySQL服务,也可以使用 /etc/init.d/MySQL来启动。
mysqld_safe --skip-grant-tables user=mysql
/etc/init.d/mysql start=mysqld --skip-grant-tables
3.授权
授权:
grant select,insert,update on db1.t1 to 'felix'@'%' 授权felix使用数据库db1下的t1表,权限为查询、插入、更改
grant select,insert,update on db1.* to 'felix'@'%'
grant all privileges on db1.t1 to 'felix'@'%'; 所有权限除授权外
grant all privileges on *.* to '用户名'@'%' identified by '123456'; 所有权限除授权外

注意:修改用户密码或者授权后用flush privileges及时刷新权限。
flush privileges 命令本质上的作用是将当前user和privilige表中的用户信息/权限设置从mysql库(MySQL数据库的内置库)中提取到内存里。
MySQL用户数据和权限有修改后,希望在"不重启MySQL服务"的情况下直接生效,那么就需要执行这个命令。通常是在修改ROOT帐号的设置后,
怕重启后无法再登录进来,那么直接flush之后就可以看权限设置是否生效。而不必冒太大风险。
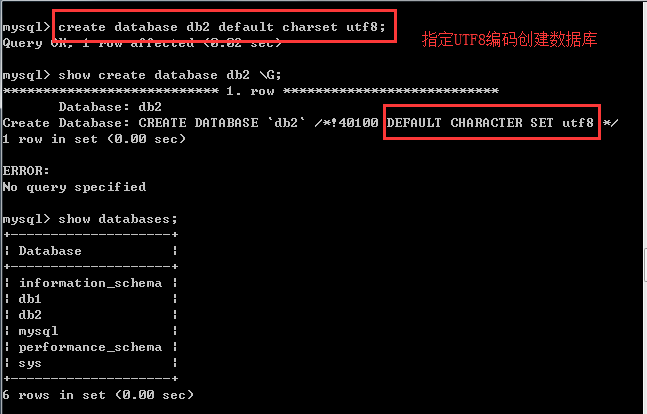
#创建数据库 create database 数据库名; 以默认编码方式创建数据库 create database 数据库名 default charset utf8; 以utf8编码方式创建数据库 #查看创建的数据库信息 show create database 数据库名 \G; #查看数据库 show databases; #使用数据库 use 数据库名; #删除数据库 drop database 数据库名;
默认编码创建数据库:

指定utf8编码方式创建数据库:
删除数据库:
1.增
#语法: create table 表名( 字段名1 类型[(宽度) 约束条件] [默认值], 字段名2 类型[(宽度) 约束条件] [默认值], 字段名3 类型[(宽度) 约束条件] [默认值] ); #注意: 1. 在同一张表中,字段名是不能相同,不区分大小写 2. 宽度和约束条件可选 3. 字段名和类型是必须的
数据表的完整性约束见链接:https://www.cnblogs.com/Felix-DoubleKing/p/10027022.html
create table 表名1(
pid int(11) auto_increment not null,
nid int(11) not null,
dept char(30) not null,
primary key (pid,nid)
) engine=innodb default charset utf8;
create table 表名2(
nid int(11) auto_increment primary key,
name char(25),
mid int(11) not null,
dept_id int(11)
constraint fk_deptid_did foreign key (dept_id,xx) references 表名1(pid,nid)
) engine=innodb default charset utf8;
2.删
可以一次删除一个或多个没有被其他表关联的数据表
drop table 表名1,表名2,,,表n;
注意:若两个表之间有关联(外键)时,删除父表会报错,应该先删除字表里的外键后再删除父表
3.改
(1)修改数据表名称
语法:
alter table 原表名 rename 新表名;
mysql> show tables; +---------------+ | Tables_in_db2 | +---------------+ | table_name1 | +---------------+ 1 row in set (0.00 sec) mysql> alter table table_name1 rename test; Query OK, 0 rows affected (0.03 sec) mysql> show tables; +---------------+ | Tables_in_db2 | +---------------+ | test | +---------------+ 1 row in set (0.00 sec)
(2)修改字段的数据类型
语法:
alter table 表名 modify 字段名 数据类型
mysql> desc test; +-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(25) | NO | | NULL | | +-------+----------+------+-----+---------+----------------+ 2 rows in set (0.00 sec) mysql> alter table test modify name text; Query OK, 0 rows affected (0.13 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc test; +-------+---------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | text | YES | | NULL | | +-------+---------+------+-----+---------+----------------+ 2 rows in set (0.00 sec)
(3)修改数据表里的字段名
alter table 表名 change 旧字段名 新字段名 新数据类型;
mysql> alter table test change name age int(3); Query OK, 0 rows affected (0.13 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc test; +-------+---------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | age | int(3) | YES | | NULL | | +-------+---------+------+-----+---------+----------------+ 2 rows in set (0.00 sec)
(4)新增加字段
alter table test add 新字段名 数据类型 [约束条件] [first | after 已存在字段名];
默认增加到最后,使用first或after 已存在字段名 可以放在指定位置
mysql> alter table test add name char(25); Query OK, 0 rows affected (0.12 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc test; +-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | age | int(3) | YES | | NULL | | | name | char(25) | YES | | NULL | | +-------+----------+------+-----+---------+----------------+ mysql> alter table test add gender char(3) after age; Query OK, 0 rows affected (0.13 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc test; +--------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | age | int(3) | YES | | NULL | | | gender | char(3) | YES | | NULL | | | name | char(25) | YES | | NULL | | +--------+----------+------+-----+---------+----------------+
(5)删除字段
alter table 表名 drop 字段名;
mysql> alter table test drop gender; Query OK, 0 rows affected (0.11 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc test; +-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | age | int(3) | YES | | NULL | | | name | char(25) | YES | | NULL | | +-------+----------+------+-----+---------+----------------+
(6)修改字段的排列位置
alter table 表名 modify 字段1 数据类型 first | after 字段2;
mysql> alter table test modify name char(25) after id; Query OK, 0 rows affected (0.13 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc test; +-------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | char(25) | YES | | NULL | | | age | int(3) | YES | | NULL | | +-------+----------+------+-----+---------+----------------+
(7)修改数据表的存储引擎
alter table 表名 engine=更改后的存储引擎;
mysql> alter table test engine=myisam; Query OK, 0 rows affected (0.08 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show create table test \G; *************************** 1. row *************************** Table: test Create Table: CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` char(25) DEFAULT NULL, `age` int(3) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8
(8)删除表的外键约束
alter table 表名 drop foreign key 外键约束名;
(9)修改表的自增默认值和自增步长
修改自增默认值:
desc 表名;
show create 表名 \G;查看表列名、数据类型、约束条件、存储引擎、下一条记录自增项的值和编码
alter table 表名 auto_increment=20; 修改自增的ID,即下一条数据的ID 从20开始
修改自增的步长:
基于会话级别:
show session variables like 'auto_inc%'; 查看当前会话的全局变量
set session auto_increment_increment=2; 设置会话级别自增步长(当前客户端生效)
set session auto_increment_offset=10; 设置起始值
基于全局级别:
show global variables like 'auto_inc%'; 查看全局变量
set global auto_increment_increment=2; 设置全局自增步长(所有客户端生效,重启客户端不受影响)
set global auto_increment_offset=10; 设置起始值


mysql> show session variables like 'auto_inc%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set, 1 warning (0.00 sec) mysql> set session auto_increment_increment=2; Query OK, 0 rows affected (0.00 sec) mysql> show session variables like 'auto_inc%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 2 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set, 1 warning (0.01 sec) mysql> set session auto_increment_offset=10; Query OK, 0 rows affected (0.00 sec) mysql> show session variables like 'auto_inc%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 2 | | auto_increment_offset | 10 | +--------------------------+-------+ 2 rows in set, 1 warning (0.01 sec)
4.查看数据表
(1)查看表基本结构语句
describe/desc语句可以查看表的字段信息,其中包括:字段名、字段数据类型、是否为主键、是否默认值等。
语法:
describe/desc 表名;
mysql> desc student; +----------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+----------+------+-----+---------+----------------+ | sid | int(11) | NO | PRI | NULL | auto_increment | | sname | char(12) | YES | | NULL | | | gender | char(3) | YES | | NULL | | | class_id | int(11) | YES | MUL | NULL | | +----------+----------+------+-----+---------+----------------+ 4 rows in set (0.00 sec)
(2)查看表信息结构语句 show create table
可以用来显示创建表时的create table语句,还可以查看存储引擎和字符编码。
语法:
show create table 表名 [\G]; 不加\G 参数,结构会有点混乱
mysql> show create table student \G; *************************** 1. row *************************** Table: student Create Table: CREATE TABLE `student` ( `sid` int(11) NOT NULL AUTO_INCREMENT, `sname` char(12) DEFAULT NULL, `gender` char(3) DEFAULT NULL, `class_id` int(11) DEFAULT NULL, PRIMARY KEY (`sid`), KEY `fk_student_class` (`class_id`), CONSTRAINT `fk_student_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`ci d`) ) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8 1 row in set (0.00 sec)
七.数据的增删改操作
a.增加一条记录
insert into 表名 (列名1,列名2...) values (列名1的值1,列名2的值1...);
insert into tb1(name,age) values ('feli','18');
b.增加多条记录
insert into 表名 (列名1,列名2...) values (列名1的值1,列名2的值1...),(列名1的值2,列名2的值2...),(列名1的值n,列名2的值n...);
insert into tb1(name,age) values ('feli','18'),('lisa','5');
c.将查询结果插入到表中
insert into 表名1 (列名1,列名2...) select (列名1,列名2...) from 表名2 [where] [条件]
insert into tb2(name,age) select name,age from tb1;
insert into tb2(name,age) select name,age from tb1 where id > 2;
2.删
语法1:delete from 表名 [where 条件];
delete from tb2;
delete from tb2 where id=2;
delete from tb2 where id>2;
delete from tb2 where id<2;
delete from tb2 where id=2 or name='felix';
delete from tb2 where id=2 and name='felix';
注意:如果不使用where条件 将会删除所有的数据行等同于truncate
truncate table 表名; 清空所有数据,自增项ID从1开始
3.改
语法: update 表名 set 列名1=值1,列名2=值2... where 条件; update tb2 set name='felix',age=18 where id=2; update tb2 set name='felix' where id>2 and name='xx'; update tb2 set name='felix',age=18 where id>2 and name='xx'; 注意:如果不使用where条件 将会更改所有的数据行
八、数据的查询
1.基本语法
语法:
select
{* | 字段列表}
from 表1,表2...
[where 条件]
[group by 条件]
[having <expression> ]
[order by 字段名]
[limit [<offset>,] <row count>]
SELECT 字段1,字段2... FROM 表名
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
{* | 字段列表} 星号通配符表示表里所有字段;多个字段用逗号分开,最后一个不加逗号
from 表1,表2... 可以是单个表或者多个表
where子句是可选项 限定查询条件
group by 字段 如何显示查询出的字段,并按照该字段分组
order by 字段 按照什么样的顺序显示查询出的结果 asc 升序 desc 降序 limit [offset,] <row count> 显示查询出来的条数限制
2.单表查询
(1)查询所有字段
select * from 表名;
select 列名1,列名2... from 表名;
(2)查询指定字段
select 列名 from 表名
(3)查询指定记录
select 字段名1,字段名2... from 表名 where 查询条件;
where子句中条件判断符:
=、>、>=、<、<=
<>、!= 不等于
between 位于两值之间
(4)带in关键字的查询
select 字段名1,字段名2... from 表名 where 字段名 in (m,n)
select 字段名1,字段名2... from 表名 where 字段名 not in (m,n)
(5)带between and范围的查询
select 字段名1,字段名2... from 表名 where 字段名 between 值1 and 值2;
(6)带like的字符匹配查询
通配符 % 匹配人员长度的字符,甚至包括零字符
通配符 _ 匹配一个长度的字符
以a开头:
select * from tb1 where name like 'a%'; a后面任意个字符
select * from tb1 where name like 'a_'; a后面只能有1个字符
包含a的:
select * from tb1 where name like '%a%'; 只有有a的
以a结尾的:
select * from tb1 where name like 'a%';
(7)查询空值
select 字段名1,字段名2... from 表名 where 字段名 is null:
(8)带and的多条件查询
查询必须同时满足多个条件,多个条件之间用and分开
select 字段名1,字段名2... from 表名 where 字段名1=值1 and 字段名2<值2 and 字段名3 is null;
(9)带or的多条件查询
查询只需要满足一个条件,多个条件之间用or分开
select 字段名1,字段名2... from 表名 where 字段名1=值1 or 字段名2<值2 or 字段名3 is null;
(10)查询结果不重复
语法:select distinct 字段名1,字段名2... from 表名;
(11)对查询结果排序
单列排序:
select 字段名1 from 表名 order by 字段名1;
多列排序:
select 字段名1,字段名2 from 表名 order by 字段名1,字段名2;
指定排序顺序:asc 升序排列 desc 降序排列
select 字段名1 from 表名 order by 字段名1 desc;
select 字段名1,字段名2 from 表名 order by 字段名1 asc,字段名2 desc; 优先以字段1排列,如有重复以字段名2降序排列
(12)分组查询
group by 字段名 [having 条件]
a.创建分组 group by 关键字通常和集合函数一起使用,如 count()、max()、min()、sum()、avg()
select count(id),max(id),part_id from tb1 group by part_id;
select part_id,count(id) from user group by part_id;
mysql> select part_id,count(id) from user group by part_id;
+---------+-----------+
| part_id | count(id) |
+---------+-----------+
| 1 | 1 |
| 2 | 4 |
| 3 | 1 |
| 4 | 4 |
+---------+-----------+
4 rows in set (0.00 sec)
b.使用having过滤分组 group by 和having一起限定显示记录所需满足的条件,只有满足条件的分组才会被显示
select part_id,count(id) from user group by part_id having count(id)=4;
如果对于聚合函数结果进行二次筛选时,必须适应having,功能类似于where,但是不能用where。
having在数据分组之后进行过滤来选择分组,而where在分组之前用来筛选记录。
select part_id,count(id) from user group by part_id having count(id)=4;
mysql> select part_id,count(id) from user group by part_id having count(id)=4;
+---------+-----------+
| part_id | count(id) |
+---------+-----------+
| 2 | 4 |
| 4 | 4 |
+---------+-----------+
2 rows in set (0.00 sec)
c.使用with rollup关键字后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的综合,即统计记录数量。
select part_id,count(id) from user group by part_id having count(id)=4 with rollup;
d.多字段分组
select * from 表名 group by 字段名1,字段名2;
e.group by 和 order by 一起使用
select 0_num,sum(quantity * item_price) as orderTotal from orderitems
group bu o_num
having sum(quantity * item_price)>=100
order by orderTotal;
(13)使用limit现在查询结果数量
limit [位置偏移量,] 行数 位置偏移量代表从哪行开始
select * from tb1 order by id desc limit 10; 查询后10个数据
select * from tb1 limit(m,n); m代表从哪条开始 n代表取n条
select * from tb1 limit 0,10;
select * from tb1 limit 10,10;
select * from tb1 limit 10 offset 20; 从20开始 取10条
实例:分页
page = int(input('>>>'))
(page - 1) * 10
select * from tb limit 0,10;
select * from tb12;
select name,id from tb12 where id != 2;
select name,id from tb12 where id <> 2;
select name,id from tb12 where id in (1,2,12);
select name,id from tb12 where id not in (1,2,12);
select name,id from tb12 where id between 5 and 12;
select name,id from tb12 where id in (select id from tb11);
select name,id from tb12 where id > 2 or name='felix';
select name as ename,id from tb12 where id > 2 or name='felix';
select name,id,1 from tb12 where id > 2 or name='felix';
(14) 主查询字段可以为子查询字段的结果
select
student_id,
(select num from score as s2 where s2.student_id=s1.student_id and course_id=1) as 生物,
(select num from score as s2 where s2.student_id=s1.student_id and course_id=2) as 物理,
(select num from score as s2 where s2.student_id=s1.student_id and course_id=3) as 体育,
(select num from score as s2 where s2.student_id=s1.student_id and course_id=4) as 美术
from score as s1 group by student_id;
+------------+------+------+------+------+
| student_id | 生物 | 物理 | 体育 | 美术 |
+------------+------+------+------+------+
| 1 | 10 | 9 | NULL | 66 |
| 2 | 8 | NULL | 68 | 99 |
| 3 | 77 | 66 | 87 | 99 |
| 4 | 79 | 11 | 67 | 100 |
| 5 | 79 | 11 | 67 | 100 |
| 6 | 9 | 100 | 67 | 100 |
| 7 | 9 | 100 | 67 | 88 |
| 8 | 9 | 100 | 67 | 88 |
| 9 | 91 | 88 | 67 | 22 |
| 10 | 90 | 77 | 43 | 87 |
| 11 | 90 | 77 | 43 | 87 |
| 12 | 90 | 77 | 43 | 87 |
| 13 | NULL | NULL | 87 | NULL |
+------------+------+------+------+------+
13 rows in set (0.00 sec)
(15) case when 条件 then ... else ... end [as 新字段名]
select student_id,course_id,num,case when num <60 then 0 else 1 end as yiled_mark from score;
mysql> select student_id,course_id,num,case when num <60 then 0 else 1 end as yi
led_mark from score;
+------------+-----------+-----+------------+
| student_id | course_id | num | yiled_mark |
+------------+-----------+-----+------------+
| 1 | 1 | 10 | 0 |
| 1 | 2 | 9 | 0 |
| 1 | 4 | 66 | 1 |
| 2 | 1 | 8 | 0 |
| 2 | 3 | 68 | 1 |
| 2 | 4 | 99 | 1 |
mysql> select
-> course_id,
-> avg(num),
-> sum(case when num < 60 then 0 else 1 end) as s0,
-> sum(1) as s1,
-> (sum(case when num < 60 then 0 else 1 end) / sum(1) ) as s111
-> from score group by course_id order by avg(num) desc;
+-----------+----------+------+------+--------+
| course_id | avg(num) | s0 | s1 | s111 |
+-----------+----------+------+------+--------+
| 4 | 85.2500 | 11 | 12 | 0.9167 |
| 2 | 65.0909 | 8 | 11 | 0.7273 |
| 3 | 64.4167 | 9 | 12 | 0.7500 |
| 1 | 53.4167 | 7 | 12 | 0.5833 |
+-----------+----------+------+------+--------+
3.连表(多表)操作
(1)inner join 也称内连接,只返回两个表中联结字段相等的行 即返回结果为两个表的交集。
select * from user inner join part on user.part_id = part.id;

(2)left join 返回包括左表中的所有记录和右表中联结字段相等的记录
select * from user left join part on user.part_id = part.id;

(3)right join 返回包括右表中的所有记录和左表中联结字段相等的记录 与left join类似
select * from user right join part on user.part_id = part.id;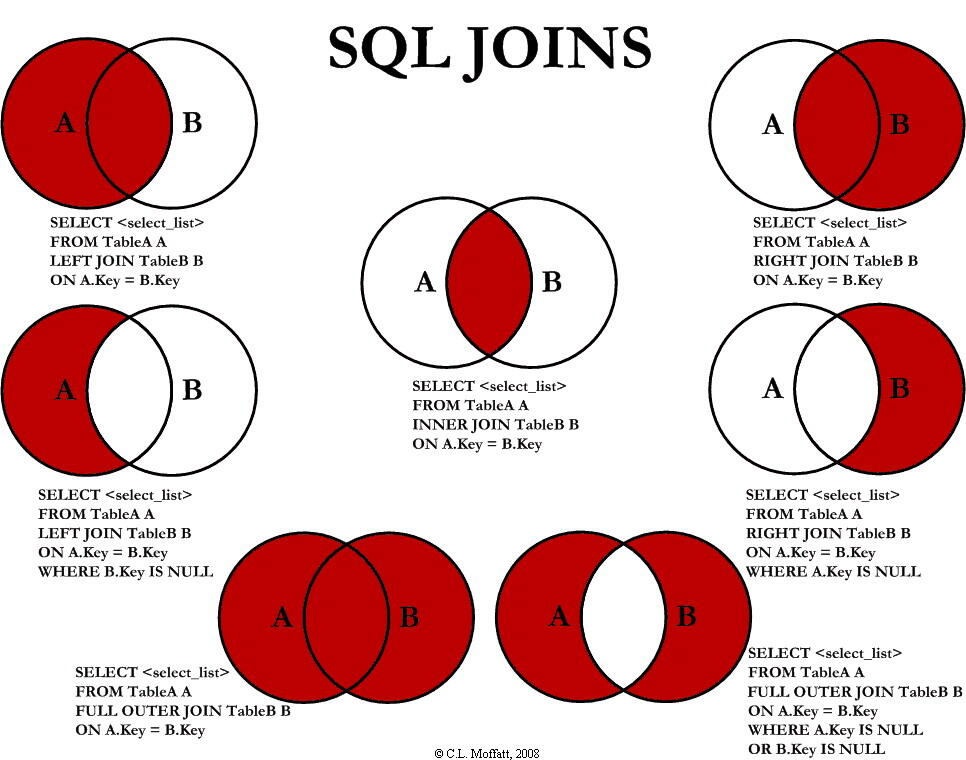
inner join 和 left join区别:
inner join 连接两个表后,只会显示满足条件的结果,不会有空值的情况出现。

left join 连接后的结果,根据查询条件会有空值的情况。
select * from student
left JOIN
(SELECT student_id,count(course_id) from score where score.course_id=001 or score.course_id=002 GROUP BY student_id HAVING count(course_id)=2) as B
on student.sid = B.student_id
查询结果:

多张张连接查询:
select score.sid,student.sid from score
left join student on score.student_id = student.sid
left join course on score.course_id = course.cid
left join class on student.class_id = class.cid
left join teacher on course.teacher_id=teacher.tid
mysql练习题:https://www.cnblogs.com/Felix-DoubleKing/p/10093969.html
1.视图含义
视图(view)是一个虚拟表,是从数据库中一个表或多个表导出来的表,是一个逻辑表,本身并不包含数据。作为一个select语句保存在数据库中。通过视图,可以展现基表的部分数据;视图数据来自定义视图的查询中使用的表,使用视图动态生成。
2.视图作用
相对直接从数据表中读取数据,视图有以下优点:
- 简单化 简化程序员的操作-经常被使用的查询创建为视图
- 安全性 通过视图用户只能查询和修改他们能所见到的数据,其他数据即看不见也取不到
- 逻辑数据独立性 视图可帮助用户屏蔽真是表结构变化带来的影响
3.创建视图
create [or replace] [algorithm = { undefined | merge | temptable }] view view_name [(column_list)] as select_statement [with [cascaded | local] check option] create 表示创建新视图 replace 表示替换已经创建的视图 algorithm 表示视图选择的语法,可选 undefined 自动选择算法 merge 表示将使用视图语句和视图定义合并起来,使视图定义的某一部分取代语句对应的部分 temptable 将视图的结果存入临时表 view_name 表示视图的名称 column_list 为属性列 select_statement 表示select 语句 with [cascaded | local] check option 表示视图在更新时保证在视图的权限范围之内,可选参数 cascaded为默认值,表示更新视图时要满足所有相关视图和表的条件 local表示更新视图时满足该视图本身定义的条件即可
简单版:create view 视图名称 as SQL语句; 查看视图 desc 视图名称;视图定义的字段、数据类型、是否为空、是否为主/外键、默认值等信息 show table status like '视图名称';查看存储引擎、创建时间等信息 show create view 视图名称; 查看视图详细定义
#创建视图 CREATE VIEW v1 AS SELECT sid,sname FROM student WHERE sid > 10; #使用视图 select * from v1;
mysql> create view v_F_players(编号,名字,性别,电话) -> as -> select PLAYERNO,NAME,SEX,PHONENO from PLAYERS -> where SEX='F' -> with check option; Query OK, 0 rows affected (0.00 sec) mysql> desc v_F_players; +--------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+----------+------+-----+---------+-------+ | 编号 | int(11) | NO | | NULL | | | 名字 | char(15) | NO | | NULL | | | 性别 | char(1) | NO | | NULL | | | 电话 | char(13) | YES | | NULL | | +--------+----------+------+-----+---------+-------+ 4 rows in set (0.00 sec) mysql> select * from v_F_players; +--------+-----------+--------+------------+ | 编号 | 名字 | 性别 | 电话 | +--------+-----------+--------+------------+ | 8 | Newcastle | F | 070-458458 | | 27 | Collins | F | 079-234857 | | 28 | Collins | F | 010-659599 | | 104 | Moorman | F | 079-987571 | | 112 | Bailey | F | 010-548745 | +--------+-----------+--------+------------+ 5 rows in set (0.02 sec)
mysql> create view v_match -> as -> select a.PLAYERNO,a.NAME,MATCHNO,WON,LOST,c.TEAMNO,c.DIVISION -> from -> PLAYERS a,MATCHES b,TEAMS c -> where a.PLAYERNO=b.PLAYERNO and b.TEAMNO=c.TEAMNO; Query OK, 0 rows affected (0.03 sec) mysql> select * from v_match; +----------+-----------+---------+-----+------+--------+----------+ | PLAYERNO | NAME | MATCHNO | WON | LOST | TEAMNO | DIVISION | +----------+-----------+---------+-----+------+--------+----------+ | 6 | Parmenter | 1 | 3 | 1 | 1 | first | | 44 | Baker | 4 | 3 | 2 | 1 | first | | 83 | Hope | 5 | 0 | 3 | 1 | first | | 112 | Bailey | 12 | 1 | 3 | 2 | second | | 8 | Newcastle | 13 | 0 | 3 | 2 | second | +----------+-----------+---------+-----+------+--------+----------+ 5 rows in set (0.04 sec)
4.修改视图
方法1:create or replace view 视图名称 as SQL语句; 方法2:alter view 视图名称 as SQL语句;
CREATE or replace VIEW v1 AS SELECT sid,sname FROM student WHERE sid > 8; alter view v1 as SELECT sid,sname FROM student WHERE sid > 8;
5.删除视图
drop view [if exists] view_name [,view_name] ... [restrict | cascade]
drop view 视图名称;
1.概念
触发器是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性。
即当对某张表做:增删改操作时,可以使用触发器自定义关联行为。
触发行为:增、删、改
2.语法
#语法
create trigger trigger_name trigger_time trigger_event on tb_name for each row trigger_stmt
trigger_name:触发器的名称
tirgger_time:触发时机,为BEFORE或者AFTER
trigger_event:触发事件,为INSERT、DELETE或者UPDATE
tb_name:表示建立触发器的表名称,就是在哪张表上建立触发器
FOR EACH ROW 表示任何一条记录上的操作满足触发事件都会触发该触发器
trigger_stmt:触发器的程序体,可以是一条SQL语句或者是用BEGIN和END包含的多条语句
所以可以说MySQL创建以下六种触发器:
BEFORE INSERT, BEFORE DELETE, BEFORE UPDATE
AFTER INSERT, AFTER DELETE, AFTER UPDATE
#创建有多个执行语句的触发器
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件
ON 表名 FOR EACH ROW
BEGIN
执行语句列表
END
其中,BEGIN与END之间的执行语句列表参数表示需要执行的多个语句,不同语句用分号隔开
tips:一般情况下,mysql默认是以 ; 作为结束执行语句,与触发器中需要的分行起冲突
为解决此问题可用DELIMITER,如:DELIMITER //,可以将结束符号变成//
当触发器创建完成后,可以用DELIMITER ;来将结束符号变成;
如下:
DELIMITER // #将语句的分隔符改为// BEGIN sql1; sql2; ... sqln END // DELIMITER // #将语句的分隔符改回原来的分号";"
mysql> DELIMITER //
mysql> CREATE TRIGGER demo BEFORE DELETE
-> ON users FOR EACH ROW
-> BEGIN
-> INSERT INTO logs VALUES(NOW());
-> INSERT INTO logs VALUES(NOW());
-> END
-> //
Query OK, 0 rows affected (0.06 sec)
mysql> DELIMITER ;
new和old的使用:

3.查看触发器
show triggers;
show triggers \G;
#查看触发器信息
show triggers;
show triggers \G;
mysql> show triggers;
+---------+--------+---------+--------------------------------------------------
-----------------------------------------------------+--------+-----------------
-------+------------------------------------------------------------------------
-------------------------------------------------------------------+------------
----+----------------------+----------------------+--------------------+
| Trigger | Event | Table | Statement
| Timing | Created
| sql_mode
| Definer
| character_set_client | collation_connection | Database Collation |
+---------+--------+---------+--------------------------------------------------
-----------------------------------------------------+--------+-----------------
-------+------------------------------------------------------------------------
-------------------------------------------------------------------+------------
----+----------------------+----------------------+--------------------+
| t3 | INSERT | student | BEGIN
INSERT into teacher(tname) values(NEW.sname);
INSERT into teacher(tname) values(NEW.sname);
END | BEFORE | 2018-12-12 12:51:41.20 | ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,N
O_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_EN
GINE_SUBSTITUTION | root@localhost | gbk | gbk_chinese_ci
| utf8_general_ci |
+---------+--------+---------+--------------------------------------------------
-----------------------------------------------------+--------+-----------------
-------+------------------------------------------------------------------------
-------------------------------------------------------------------+------------
----+----------------------+----------------------+--------------------+
1 row in set (0.00 sec)
mysql>
mysql> show triggers \G;
*************************** 1. row ***************************
Trigger: t3
Event: INSERT
Table: student
Statement: BEGIN
INSERT into teacher(tname) values(NEW.sname);
INSERT into teacher(tname) values(NEW.sname);
END
Timing: BEFORE
Created: 2018-12-12 12:51:41.20
sql_mode: ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_
ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
Definer: root@localhost
character_set_client: gbk
collation_connection: gbk_chinese_ci
Database Collation: utf8_general_ci
1 row in set (0.00 sec)
ERROR:
No query specified
mysql>
4.触发器的使用
触发程序是与表有关的的命名数据库对象,当表上出现特定事件时,将激活该对象,在某些触发程序的用法中可用以检查插入到表中的值,或对更新设计的值进行计算。
#创建触发器
mysql> delimiter //
mysql> create trigger t1 BEFORE INSERT on student for EACH ROW
-> BEGIN
-> INSERT into teacher(tname) values(NEW.sname);
-> INSERT into teacher(tname) values(NEW.sname);
-> END //
Query OK, 0 rows affected (0.03 sec)
mysql>
#在student表插入数据
insert into student(gender,class_id,sname) values('男',1,'felix'),('女',1,'alina');
#查看student表
mysql> select * from student;
+-----+--------+----------+--------+
| sid | gender | class_id | sname |
+-----+--------+----------+--------+
| 1 | 男 | 1 | 理解 |
| 2 | 女 | 1 | 钢蛋 |
| 3 | 男 | 1 | 张三 |
| 4 | 男 | 1 | 张一 |
| 5 | 女 | 1 | 张二 |
| 6 | 男 | 1 | 张四 |
| 7 | 女 | 2 | 铁锤 |
| 8 | 男 | 2 | 李三 |
| 9 | 男 | 2 | 李一 |
| 10 | 女 | 2 | 李二 |
| 11 | 男 | 2 | 李四 |
| 12 | 女 | 3 | 如花 |
| 13 | 男 | 3 | 刘三 |
| 14 | 男 | 3 | 刘一 |
| 15 | 女 | 3 | 刘二 |
| 16 | 男 | 3 | 刘四 |
| 17 | 男 | 2 | 王二狗 |
| 22 | 男 | 1 | felix |
| 23 | 女 | 1 | alina |
+-----+--------+----------+--------+
19 rows in set (0.00 sec)
mysql>
#查看teacher表
mysql> select * from teacher;
+-----+------------+
| tid | tname |
+-----+------------+
| 1 | 张磊老师 |
| 2 | 李平老师 |
| 3 | 刘海燕老师 |
| 4 | 朱云海老师 |
| 5 | 李杰老师 |
| 30 | felix |
| 31 | felix |
| 32 | alina |
| 33 | alina |
+-----+------------+
9 rows in set (0.00 sec)
1 delimiter // 2 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW 3 BEGIN 4 5 IF NEW. NAME == 'felix' THEN 6 INSERT INTO tb2 (NAME) 7 VALUES 8 ('aa') 9 END 10 END// 11 delimiter ;
1 delimiter // 2 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW 3 BEGIN 4 IF NEW. num = 666 THEN 5 INSERT INTO tb2 (NAME) 6 VALUES 7 ('666'), 8 ('666') ; 9 ELSEIF NEW. num = 555 THEN 10 INSERT INTO tb2 (NAME) 11 VALUES 12 ('555'), 13 ('555') ; 14 END IF; 15 END// 16 delimiter ;
5.删除触发器
#语法 drop trigger [数据库名.]触发器名称; 可以省略数据库名
1 #创建用户表 users 2 3 CREATE TABLE `users` ( 4 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 5 `name` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL, 6 `add_time` int(11) DEFAULT NULL, 7 PRIMARY KEY (`id`), 8 KEY `name` (`name`(250)) USING BTREE 9 ) ENGINE=MyISAM AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8; 10 11 #创建日志logs表 12 CREATE TABLE `logs` ( 13 `Id` int(11) NOT NULL AUTO_INCREMENT, 14 `log` varchar(255) DEFAULT NULL COMMENT '日志说明', 15 PRIMARY KEY (`Id`) 16 ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='日志表'; 17 18 需求是:当在users中插入一条数据,就会在logs中生成一条日志信息。 19 20 #创建触发器: 21 DELIMITER // 22 CREATE TRIGGER user_log AFTER INSERT ON users FOR EACH ROW 23 BEGIN 24 DECLARE s1 VARCHAR(40)character set utf8; 25 DECLARE s2 VARCHAR(20) character set utf8;#后面发现中文字符编码出现乱码,这里设置字符集 26 SET s2 = " is created"; 27 SET s1 = CONCAT(NEW.name,s2); #函数CONCAT可以将字符串连接 28 INSERT INTO logs(log) values(s1); 29 END // 30 DELIMITER ; 31 32 33 #插入数据 34 insert into users (id,name,add_time) VALUES (1,'felix','20181212'); 35 36 #查看users表 37 mysql> select * from users; 38 +----+-------+----------+ 39 | id | name | add_time | 40 +----+-------+----------+ 41 | 1 | felix | 20181212 | 42 +----+-------+----------+ 43 1 row in set (0.01 sec) 44 45 mysql> 46 47 #查看logs表 48 mysql> select * from logs; 49 +----+------------------+ 50 | Id | log | 51 +----+------------------+ 52 | 1 | felix is created | 53 +----+------------------+ 54 1 row in set (0.00 sec) 55 56 mysql>
1.函数概念
函数存储着一系列sql语句,调用函数就是一次性执行这些语句。所以函数可以降低语句重复。【但注意的是函数注重返回值,不注重执行过程,所以一些语句无法执行。所以函数并不是单纯的sql语句集合。】
2.分类
- 内置函数
1 1、字符串函数 2 ascii(str) 3 返回字符串str的第一个字符的ascii值(str是空串时返回0) 4 mysql> select ascii('2'); 5 -> 50 6 mysql> select ascii(2); 7 -> 50 8 mysql> select ascii('dete'); 9 -> 100 10 11 12 ord(str) 13 如果字符串str句首是单字节返回与ascii()函数返回的相同值。 14 15 如果是一个多字节字符,以格式返回((first byte ascii code)*256+(second byte ascii code))[*256+third byte asciicode...] 16 mysql> select ord('2'); 17 -> 50 18 19 conv(n,from_base,to_base) 20 对数字n进制转换,并转换为字串返回(任何参数为null时返回null,进制范围为2-36进制,当to_base是负数时n作为有符号数否则作无符号数,conv以64位点精度工作) 21 mysql> select conv("a",16,2); 22 -> '1010' 23 mysql> select conv("6e",18,8); 24 -> '172' 25 mysql> select conv(-17,10,-18); 26 -> '-h' 27 mysql> select conv(10+"10"+'10'+0xa,10,10); 28 -> '40' 29 30 bin(n) 31 把n转为二进制值并以字串返回(n是bigint数字,等价于conv(n,10,2)) 32 mysql> select bin(12); 33 -> '1100' 34 35 oct(n) 36 把n转为八进制值并以字串返回(n是bigint数字,等价于conv(n,10,8)) 37 mysql> select oct(12); 38 -> '14' 39 40 hex(n) 41 把n转为十六进制并以字串返回(n是bigint数字,等价于conv(n,10,16)) 42 mysql> select hex(255); 43 -> 'ff' 44 45 char(n,...) 46 返回由参数n,...对应的ascii代码字符组成的一个字串(参数是n,...是数字序列,null值被跳过) 47 mysql> select char(77,121,83,81,'76'); 48 -> 'mysql' 49 mysql> select char(77,77.3,'77.3'); 50 -> 'mmm' 51 52 concat(str1,str2,...) 53 把参数连成一个长字符串并返回(任何参数是null时返回null) 54 mysql> select concat('my', 's', 'ql'); 55 -> 'mysql' 56 mysql> select concat('my', null, 'ql'); 57 -> null 58 mysql> select concat(14.3); 59 -> '14.3' 60 61 length(str) 62 octet_length(str) 63 char_length(str) 64 character_length(str) 65 返回字符串str的长度(对于多字节字符char_length仅计算一次) 66 mysql> select length('text'); 67 -> 4 68 mysql> select octet_length('text'); 69 -> 4 70 71 locate(substr,str) 72 position(substr in str) 73 返回字符串substr在字符串str第一次出现的位置(str不包含substr时返回0) 74 mysql> select locate('bar', 'foobarbar'); 75 -> 4 76 mysql> select locate('xbar', 'foobar'); 77 -> 0 78 79 locate(substr,str,pos) 80 返回字符串substr在字符串str的第pos个位置起第一次出现的位置(str不包含substr时返回0) 81 mysql> select locate('bar', 'foobarbar',5); 82 -> 7 83 84 instr(str,substr) 85 返回字符串substr在字符串str第一次出现的位置(str不包含substr时返回0) 86 mysql> select instr('foobarbar', 'bar'); 87 -> 4 88 mysql> select instr('xbar', 'foobar'); 89 -> 0 90 91 lpad(str,len,padstr) 92 用字符串padstr填补str左端直到字串长度为len并返回 93 mysql> select lpad('hi',4,'??'); 94 -> '??hi' 95 96 rpad(str,len,padstr) 97 用字符串padstr填补str右端直到字串长度为len并返回 98 mysql> select rpad('hi',5,'?'); 99 -> 'hi???' 100 101 left(str,len) 102 返回字符串str的左端len个字符 103 mysql> select left('foobarbar', 5); 104 -> 'fooba' 105 106 right(str,len) 107 返回字符串str的右端len个字符 108 mysql> select right('foobarbar', 4); 109 -> 'rbar' 110 111 substring(str,pos,len) 112 substring(str from pos for len) 113 mid(str,pos,len) 114 返回字符串str的位置pos起len个字符mysql> select substring('quadratically',5,6); 115 -> 'ratica' 116 117 substring(str,pos) 118 substring(str from pos) 119 返回字符串str的位置pos起的一个子串 120 mysql> select substring('quadratically',5); 121 -> 'ratically' 122 mysql> select substring('foobarbar' from 4); 123 -> 'barbar' 124 125 substring_index(str,delim,count) 126 返回从字符串str的第count个出现的分隔符delim之后的子串 127 (count为正数时返回左端,否则返回右端子串) 128 mysql> select substring_index('www.mysql.com', '.', 2); 129 -> 'www.mysql' 130 mysql> select substring_index('www.mysql.com', '.', -2); 131 -> 'mysql.com' 132 133 ltrim(str) 134 返回删除了左空格的字符串str 135 mysql> select ltrim(' barbar'); 136 -> 'barbar' 137 138 rtrim(str) 139 返回删除了右空格的字符串str 140 mysql> select rtrim('barbar '); 141 -> 'barbar' 142 143 trim([[both | leading | trailing] [remstr] from] str) 144 返回前缀或后缀remstr被删除了的字符串str(位置参数默认both,remstr默认值为空格) 145 mysql> select trim(' bar '); 146 -> 'bar' 147 mysql> select trim(leading 'x' from 'xxxbarxxx'); 148 -> 'barxxx' 149 mysql> select trim(both 'x' from 'xxxbarxxx'); 150 -> 'bar' 151 mysql> select trim(trailing 'xyz' from 'barxxyz'); 152 -> 'barx' 153 154 soundex(str) 155 返回str的一个同音字符串(听起来“大致相同”字符串有相同的 156 同音字符串,非数字字母字符被忽略,在a-z外的字母被当作元音) 157 mysql> select soundex('hello'); 158 -> 'h400' 159 mysql> select soundex('quadratically'); 160 -> 'q36324' 161 162 space(n) 163 返回由n个空格字符组成的一个字符串 164 mysql> select space(6); 165 -> ' ' 166 167 replace(str,from_str,to_str) 168 用字符串to_str替换字符串str中的子串from_str并返回 169 mysql> select replace('www.mysql.com', 'w', 'ww'); 170 -> 'wwwwww.mysql.com' 171 172 repeat(str,count) 173 返回由count个字符串str连成的一个字符串(任何参数为null时 174 返回null,count<=0时返回一个空字符串) 175 mysql> select repeat('mysql', 3); 176 -> 'mysqlmysqlmysql' 177 178 reverse(str) 179 颠倒字符串str的字符顺序并返回 180 mysql> select reverse('abc'); 181 -> 'cba' 182 183 insert(str,pos,len,newstr) 184 把字符串str由位置pos起len个字符长的子串替换为字符串 185 newstr并返回 186 mysql> select insert('quadratic', 3, 4, 'what'); 187 -> 'quwhattic' 188 189 elt(n,str1,str2,str3,...) 190 返回第n个字符串(n小于1或大于参数个数返回null) 191 mysql> select elt(1, 'ej', 'heja', 'hej', 'foo'); 192 -> 'ej' 193 mysql> select elt(4, 'ej', 'heja', 'hej', 'foo'); 194 -> 'foo' 195 196 field(str,str1,str2,str3,...) 197 返回str等于其后的第n个字符串的序号(如果str没找到返回0) 198 mysql> select field('ej', 'hej', 'ej', 'heja', 'hej', 199 'foo'); 200 -> 2 201 mysql> select field('fo', 'hej', 'ej', 'heja', 'hej', 202 'foo'); 203 -> 0 204 205 find_in_set(str,strlist) 206 返回str在字符串集strlist中的序号(任何参数是null则返回 207 null,如果str没找到返回0,参数1包含","时工作异常) 208 mysql> select find_in_set('b','a,b,c,d'); 209 -> 2 210 211 make_set(bits,str1,str2,...) 212 把参数1的数字转为二进制,假如某个位置的二进制位等于1,对应 213 位置的字串选入字串集并返回(null串不添加到结果中) 214 mysql> select make_set(1,'a','b','c'); 215 -> 'a' 216 mysql> select make_set(1 | 4,'hello','nice','world'); 217 -> 'hello,world' 218 mysql> select make_set(0,'a','b','c'); 219 -> '' 220 221 export_set(bits,on,off,[separator,[number_of_bits]]) 222 按bits排列字符串集,只有当位等于1时插入字串on,否则插入 223 off(separator默认值",",number_of_bits参数使用时长度不足补0 224 而过长截断) 225 mysql> select export_set(5,'y','n',',',4) 226 -> y,n,y,n 227 228 lcase(str) 229 lower(str) 230 返回小写的字符串str 231 mysql> select lcase('quadratically'); 232 -> 'quadratically' 233 234 ucase(str) 235 upper(str) 236 返回大写的字符串str 237 mysql> select ucase('quadratically'); 238 -> 'quadratically' 239 240 load_file(file_name) 241 读入文件并且作为一个字符串返回文件内容(文件无法找到,路径 242 不完整,没有权限,长度大于max_allowed_packet会返回null) 243 mysql> update table_name set blob_column=load_file 244 ("/tmp/picture") where id=1; 245 246 2、数学函数 247 abs(n) 248 返回n的绝对值 249 mysql> select abs(2); 250 -> 2 251 mysql> select abs(-32); 252 -> 32 253 254 sign(n) 255 返回参数的符号(为-1、0或1) 256 mysql> select sign(-32); 257 -> -1 258 mysql> select sign(0); 259 -> 0 260 mysql> select sign(234); 261 -> 1 262 263 mod(n,m) 264 取模运算,返回n被m除的余数(同%操作符) 265 mysql> select mod(234, 10); 266 -> 4 267 mysql> select 234 % 10; 268 -> 4 269 mysql> select mod(29,9); 270 -> 2 271 272 floor(n) 273 返回不大于n的最大整数值 274 mysql> select floor(1.23); 275 -> 1 276 mysql> select floor(-1.23); 277 -> -2 278 279 ceiling(n) 280 返回不小于n的最小整数值 281 mysql> select ceiling(1.23); 282 -> 2 283 mysql> select ceiling(-1.23); 284 -> -1 285 286 round(n,d) 287 返回n的四舍五入值,保留d位小数(d的默认值为0) 288 mysql> select round(-1.23); 289 -> -1 290 mysql> select round(-1.58); 291 -> -2 292 mysql> select round(1.58); 293 -> 2 294 mysql> select round(1.298, 1); 295 -> 1.3 296 mysql> select round(1.298, 0); 297 -> 1 298 299 exp(n) 300 返回值e的n次方(自然对数的底) 301 mysql> select exp(2); 302 -> 7.389056 303 mysql> select exp(-2); 304 -> 0.135335 305 306 log(n) 307 返回n的自然对数 308 mysql> select log(2); 309 -> 0.693147 310 mysql> select log(-2); 311 -> null 312 313 log10(n) 314 返回n以10为底的对数 315 mysql> select log10(2); 316 -> 0.301030 317 mysql> select log10(100); 318 -> 2.000000 319 mysql> select log10(-100); 320 -> null 321 322 pow(x,y) 323 power(x,y) 324 返回值x的y次幂 325 mysql> select pow(2,2); 326 -> 4.000000 327 mysql> select pow(2,-2); 328 -> 0.250000 329 330 sqrt(n) 331 返回非负数n的平方根 332 mysql> select sqrt(4); 333 -> 2.000000 334 mysql> select sqrt(20); 335 -> 4.472136 336 337 pi() 338 返回圆周率 339 mysql> select pi(); 340 -> 3.141593 341 342 cos(n) 343 返回n的余弦值 344 mysql> select cos(pi()); 345 -> -1.000000 346 347 sin(n) 348 返回n的正弦值 349 mysql> select sin(pi()); 350 -> 0.000000 351 352 tan(n) 353 返回n的正切值 354 mysql> select tan(pi()+1); 355 -> 1.557408 356 357 acos(n) 358 返回n反余弦(n是余弦值,在-1到1的范围,否则返回null) 359 mysql> select acos(1); 360 -> 0.000000 361 mysql> select acos(1.0001); 362 -> null 363 mysql> select acos(0); 364 -> 1.570796 365 366 asin(n) 367 返回n反正弦值 368 mysql> select asin(0.2); 369 -> 0.201358 370 mysql> select asin('foo'); 371 -> 0.000000 372 373 atan(n) 374 返回n的反正切值 375 mysql> select atan(2); 376 -> 1.107149 377 mysql> select atan(-2); 378 -> -1.107149 379 atan2(x,y) 380 返回2个变量x和y的反正切(类似y/x的反正切,符号决定象限) 381 mysql> select atan(-2,2); 382 -> -0.785398 383 mysql> select atan(pi(),0); 384 -> 1.570796 385 386 cot(n) 387 返回x的余切 388 mysql> select cot(12); 389 -> -1.57267341 390 mysql> select cot(0); 391 -> null 392 393 rand() 394 rand(n) 395 返回在范围0到1.0内的随机浮点值(可以使用数字n作为初始值) 396 397 mysql> select rand(); 398 -> 0.5925 399 mysql> select rand(20); 400 -> 0.1811 401 mysql> select rand(20); 402 -> 0.1811 403 mysql> select rand(); 404 -> 0.2079 405 mysql> select rand(); 406 -> 0.7888 407 408 degrees(n) 409 把n从弧度变换为角度并返回 410 mysql> select degrees(pi()); 411 -> 180.000000 412 413 radians(n) 414 把n从角度变换为弧度并返回 415 mysql> select radians(90); 416 -> 1.570796 417 418 truncate(n,d) 419 保留数字n的d位小数并返回 420 mysql> select truncate(1.223,1); 421 -> 1.2 422 mysql> select truncate(1.999,1); 423 -> 1.9 424 mysql> select truncate(1.999,0); 425 -> 1 426 427 least(x,y,...) 428 返回最小值(如果返回值被用在整数(实数或大小敏感字串)上下文或所有参数都是整数(实数或大小敏感字串)则他们作为整数(实数或大小敏感字串)比较,否则按忽略大小写的字符串被比较) 429 mysql> select least(2,0); 430 -> 0 431 mysql> select least(34.0,3.0,5.0,767.0); 432 -> 3.0 433 mysql> select least("b","a","c"); 434 -> "a" 435 436 greatest(x,y,...) 437 返回最大值(其余同least()) 438 mysql> select greatest(2,0); 439 -> 2 440 mysql> select greatest(34.0,3.0,5.0,767.0); 441 -> 767.0 442 mysql> select greatest("b","a","c"); 443 -> "c" 444 445 3、时期时间函数 446 dayofweek(date) 447 返回日期date是星期几(1=星期天,2=星期一,……7=星期六,odbc标准) 448 mysql> select dayofweek('1998-02-03'); 449 -> 3 450 451 weekday(date) 452 返回日期date是星期几(0=星期一,1=星期二,……6= 星期天)。 453 454 mysql> select weekday('1997-10-04 22:23:00'); 455 -> 5 456 mysql> select weekday('1997-11-05'); 457 -> 2 458 459 dayofmonth(date) 460 返回date是一月中的第几日(在1到31范围内) 461 mysql> select dayofmonth('1998-02-03'); 462 -> 3 463 464 dayofyear(date) 465 返回date是一年中的第几日(在1到366范围内) 466 mysql> select dayofyear('1998-02-03'); 467 -> 34 468 469 month(date) 470 返回date中的月份数值 471 mysql> select month('1998-02-03'); 472 -> 2 473 474 dayname(date) 475 返回date是星期几(按英文名返回) 476 mysql> select dayname("1998-02-05"); 477 -> 'thursday' 478 479 monthname(date) 480 返回date是几月(按英文名返回) 481 mysql> select monthname("1998-02-05"); 482 -> 'february' 483 484 quarter(date) 485 返回date是一年的第几个季度 486 mysql> select quarter('98-04-01'); 487 -> 2 488 489 week(date,first) 490 返回date是一年的第几周(first默认值0,first取值1表示周一是 491 周的开始,0从周日开始) 492 mysql> select week('1998-02-20'); 493 -> 7 494 mysql> select week('1998-02-20',0); 495 -> 7 496 mysql> select week('1998-02-20',1); 497 -> 8 498 499 year(date) 500 返回date的年份(范围在1000到9999) 501 mysql> select year('98-02-03'); 502 -> 1998 503 504 hour(time) 505 返回time的小时数(范围是0到23) 506 mysql> select hour('10:05:03'); 507 -> 10 508 509 minute(time) 510 返回time的分钟数(范围是0到59) 511 mysql> select minute('98-02-03 10:05:03'); 512 -> 5 513 514 second(time) 515 返回time的秒数(范围是0到59) 516 mysql> select second('10:05:03'); 517 -> 3 518 519 period_add(p,n) 520 增加n个月到时期p并返回(p的格式yymm或yyyymm) 521 mysql> select period_add(9801,2); 522 -> 199803 523 524 period_diff(p1,p2) 525 返回在时期p1和p2之间月数(p1和p2的格式yymm或yyyymm) 526 mysql> select period_diff(9802,199703); 527 -> 11 528 529 date_add(date,interval expr type) 530 date_sub(date,interval expr type) 531 adddate(date,interval expr type) 532 subdate(date,interval expr type) 533 对日期时间进行加减法运算 534 (adddate()和subdate()是date_add()和date_sub()的同义词,也 535 可以用运算符+和-而不是函数 536 date是一个datetime或date值,expr对date进行加减法的一个表 537 达式字符串type指明表达式expr应该如何被解释 538 [type值 含义 期望的expr格式]: 539 second 秒 seconds 540 minute 分钟 minutes 541 hour 时间 hours 542 day 天 days 543 month 月 months 544 year 年 years 545 minute_second 分钟和秒 "minutes:seconds" 546 hour_minute 小时和分钟 "hours:minutes" 547 day_hour 天和小时 "days hours" 548 year_month 年和月 "years-months" 549 hour_second 小时, 分钟, "hours:minutes:seconds" 550 day_minute 天, 小时, 分钟 "days hours:minutes" 551 day_second 天, 小时, 分钟, 秒 "days 552 hours:minutes:seconds" 553 expr中允许任何标点做分隔符,如果所有是date值时结果是一个 554 date值,否则结果是一个datetime值) 555 如果type关键词不完整,则mysql从右端取值,day_second因为缺 556 少小时分钟等于minute_second) 557 如果增加month、year_month或year,天数大于结果月份的最大天 558 数则使用最大天数) 559 mysql> select "1997-12-31 23:59:59" + interval 1 second; 560 561 -> 1998-01-01 00:00:00 562 mysql> select interval 1 day + "1997-12-31"; 563 -> 1998-01-01 564 mysql> select "1998-01-01" - interval 1 second; 565 -> 1997-12-31 23:59:59 566 mysql> select date_add("1997-12-31 23:59:59",interval 1 567 second); 568 -> 1998-01-01 00:00:00 569 mysql> select date_add("1997-12-31 23:59:59",interval 1 570 day); 571 -> 1998-01-01 23:59:59 572 mysql> select date_add("1997-12-31 23:59:59",interval 573 "1:1" minute_second); 574 -> 1998-01-01 00:01:00 575 mysql> select date_sub("1998-01-01 00:00:00",interval "1 576 1:1:1" day_second); 577 -> 1997-12-30 22:58:59 578 mysql> select date_add("1998-01-01 00:00:00", interval "-1 579 10" day_hour); 580 -> 1997-12-30 14:00:00 581 mysql> select date_sub("1998-01-02", interval 31 day); 582 -> 1997-12-02 583 mysql> select extract(year from "1999-07-02"); 584 -> 1999 585 mysql> select extract(year_month from "1999-07-02 586 01:02:03"); 587 -> 199907 588 mysql> select extract(day_minute from "1999-07-02 589 01:02:03"); 590 -> 20102 591 592 to_days(date) 593 返回日期date是西元0年至今多少天(不计算1582年以前) 594 mysql> select to_days(950501); 595 -> 728779 596 mysql> select to_days('1997-10-07'); 597 -> 729669 598 599 from_days(n) 600 给出西元0年至今多少天返回date值(不计算1582年以前) 601 mysql> select from_days(729669); 602 -> '1997-10-07' 603 604 date_format(date,format) 605 根据format字符串格式化date值 606 (在format字符串中可用标志符: 607 %m 月名字(january……december) 608 %w 星期名字(sunday……saturday) 609 %d 有英语前缀的月份的日期(1st, 2nd, 3rd, 等等。) 610 %y 年, 数字, 4 位 611 %y 年, 数字, 2 位 612 %a 缩写的星期名字(sun……sat) 613 %d 月份中的天数, 数字(00……31) 614 %e 月份中的天数, 数字(0……31) 615 %m 月, 数字(01……12) 616 %c 月, 数字(1……12) 617 %b 缩写的月份名字(jan……dec) 618 %j 一年中的天数(001……366) 619 %h 小时(00……23) 620 %k 小时(0……23) 621 %h 小时(01……12) 622 %i 小时(01……12) 623 %l 小时(1……12) 624 %i 分钟, 数字(00……59) 625 %r 时间,12 小时(hh:mm:ss [ap]m) 626 %t 时间,24 小时(hh:mm:ss) 627 %s 秒(00……59) 628 %s 秒(00……59) 629 %p am或pm 630 %w 一个星期中的天数(0=sunday ……6=saturday ) 631 %u 星期(0……52), 这里星期天是星期的第一天 632 %u 星期(0……52), 这里星期一是星期的第一天 633 %% 字符% ) 634 mysql> select date_format('1997-10-04 22:23:00','%w %m % 635 y'); 636 -> 'saturday october 1997' 637 mysql> select date_format('1997-10-04 22:23:00','%h:%i:% 638 s'); 639 -> '22:23:00' 640 mysql> select date_format('1997-10-04 22:23:00','%d %y %a 641 %d %m %b %j'); 642 -> '4th 97 sat 04 10 oct 277' 643 mysql> select date_format('1997-10-04 22:23:00','%h %k %i 644 %r %t %s %w'); 645 -> '22 22 10 10:23:00 pm 22:23:00 00 6' 646 647 time_format(time,format) 648 和date_format()类似,但time_format只处理小时、分钟和秒(其 649 余符号产生一个null值或0) 650 651 curdate() 652 current_date() 653 以'yyyy-mm-dd'或yyyymmdd格式返回当前日期值(根据返回值所 654 处上下文是字符串或数字) 655 mysql> select curdate(); 656 -> '1997-12-15' 657 mysql> select curdate() + 0; 658 -> 19971215 659 660 curtime() 661 current_time() 662 以'hh:mm:ss'或hhmmss格式返回当前时间值(根据返回值所处上 663 下文是字符串或数字) 664 mysql> select curtime(); 665 -> '23:50:26' 666 mysql> select curtime() + 0; 667 -> 235026 668 669 now() 670 sysdate() 671 current_timestamp() 672 以'yyyy-mm-dd hh:mm:ss'或yyyymmddhhmmss格式返回当前日期 673 时间(根据返回值所处上下文是字符串或数字) 674 mysql> select now(); 675 -> '1997-12-15 23:50:26' 676 mysql> select now() + 0; 677 -> 19971215235026 678 679 unix_timestamp() 680 unix_timestamp(date) 681 返回一个unix时间戳(从'1970-01-01 00:00:00'gmt开始的秒 682 数,date默认值为当前时间) 683 mysql> select unix_timestamp(); 684 -> 882226357 685 mysql> select unix_timestamp('1997-10-04 22:23:00'); 686 -> 875996580 687 688 from_unixtime(unix_timestamp) 689 以'yyyy-mm-dd hh:mm:ss'或yyyymmddhhmmss格式返回时间戳的 690 值(根据返回值所处上下文是字符串或数字) 691 mysql> select from_unixtime(875996580); 692 -> '1997-10-04 22:23:00' 693 mysql> select from_unixtime(875996580) + 0; 694 -> 19971004222300 695 696 from_unixtime(unix_timestamp,format) 697 以format字符串格式返回时间戳的值 698 mysql> select from_unixtime(unix_timestamp(),'%y %d %m % 699 h:%i:%s %x'); 700 -> '1997 23rd december 03:43:30 x' 701 702 sec_to_time(seconds) 703 以'hh:mm:ss'或hhmmss格式返回秒数转成的time值(根据返回值所处上下文是字符串或数字) 704 mysql> select sec_to_time(2378); 705 -> '00:39:38' 706 mysql> select sec_to_time(2378) + 0; 707 -> 3938 708 709 time_to_sec(time) 710 返回time值有多少秒 711 mysql> select time_to_sec('22:23:00'); 712 -> 80580 713 mysql> select time_to_sec('00:39:38'); 714 -> 2378 715 716 转换函数 717 cast 718 用法:cast(字段 as 数据类型) [当然是否可以成功转换,还要看数据类型强制转化时注意的问题] 719 实例:select cast(a as unsigned) as b from cardserver where order by b desc; 720 convert: 721 用法:convert(字段,数据类型) 722 实例:select convert(a ,unsigned) as b from cardserver where order by b desc; 723 724
更多内置函数见官网:
- 自定义函数
3.创建自定义函数
create function 函数名([参数列表]) returns 数据类型 begin sql语句; return 值; end;
参数列表的格式是: 变量名 数据类型
1 -- 最简单的仅有一条sql的函数 2 create function myselect2() returns int return 666; 3 select myselect2(); -- 调用函数 4 5 -- 6 create function myselect3() returns int 7 begin 8 declare c int; 9 select id from class where cname="python" into c; 10 return c; 11 end; 12 select myselect3(); 13 -- 带传参的函数 14 create function myselect5(name varchar(15)) returns int 15 begin 16 declare c int; 17 select id from class where cname=name into c; 18 return c; 19 end; 20 select myselect5("python");
delimiter // create FUNCTION myfunc1() RETURNS int BEGIN DECLARE n int ; select sid from student where sid=1 into n; RETURN n; end // delimiter ; 调用函数: select myfunc1() 执行结果: mysql> select myfunc1(); +-----------+ | myfunc1() | +-----------+ | 1 | +-----------+ 1 row in set (0.00 sec)
#创建函数 delimiter // create FUNCTION myfunc2(num int ) RETURNS int BEGIN DECLARE n int ; select sid from student where sid=num into n; RETURN n; end // delimiter ; #调用函数 select myfunc2(12); 执行结果: mysql> select myfunc2(12); +-------------+ | myfunc2(12) | +-------------+ | 12 | +-------------+ 1 row in set (0.00 sec)
1 #创建函数 2 delimiter // 3 create FUNCTION myfunc3(num int ) 4 RETURNS char(255) 5 BEGIN 6 DECLARE n char(255) ; 7 select sname from student where sid=num into n; 8 RETURN n; 9 end // 10 delimiter ; 11 12 #调用函数 13 select myfunc3(10); 14 15 执行结果: 16 mysql> select myfunc3(10); 17 +-------------+ 18 | myfunc3(10) | 19 +-------------+ 20 | 李二 | 21 +-------------+ 22 1 row in set (0.00 sec)
1 #创建函数 2 delimiter // 3 CREATE FUNCTION formatDate(fdate datetime) 4 RETURNS VARCHAR(255) 5 BEGIN 6 DECLARE x VARCHAR(255) DEFAULT ''; 7 set x = DATE_FORMAT(fdate,'%Y年%m月%d日%h时%i分%s秒'); 8 RETURN x; 9 end // 10 delimiter ; 11 12 #调用函数 13 select formatDate(now()); 14 15 执行结果: 16 mysql> select formatDate(now()); 17 +----------------------------+ 18 | formatDate(now()) | 19 +----------------------------+ 20 | 2018年12月12日02时38分06秒 | 21 +----------------------------+ 22 1 row in set (0.00 sec)
4.函数的调用
- 直接使用函数名()就可以调用【但返回的是一个结果,sql中不使用select的话任何结果都无法显示出来】
- 如果想要传入参数可以使用函数名(参数)
- 调用方式:
1 #无传入参数调用 2 select 函数名(); 3 4 #有参数传入调用 5 select 函数名(参数); 6 7 select * from class where id=myselect5("python");
5.函数的查看
查看函数创建语句:show create function 函数名; 查看所有函数:show function status [like 'pattern'];
6.函数的修改
- 函数的修改只能修改一些如comment的选项,不能修改内部的sql语句和参数列表。
- alter function 函数名 选项;
7.函数的删除
drop function 函数名;
1.概念
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
2.创建存储过程
CREATE PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
说明:
sp_name 表示存储过程的名称
proc_parameter 为指定存储过程的参数列表,列表形式如下
[in | out | inout] param_name type
in 表示输入参数 参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值
out 表示输出参数 该值可在存储过程内部被改变,并可返回,类似于函数的return 用于标识存储过程的执行结果
inout 表即可输入也可输出 调用时指定,并且可被改变和返回
param_name 表示参数名称
type 表示参数的数据类型
characteristic:可选参数,指定存储过程的特性,有以下取值:
COMMENT 'string' 注释信息,描述存储过程
| LANGUAGE SQL 说明routine_body部分是有SQL语句组成
| [NOT] DETERMINISTIC 指明存储过程执行的结果是否确定
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } 指明子程序使用SQL语句的限制
| SQL SECURITY { DEFINER | INVOKER } 指明谁有权限来执行
routine_body 是SQL代码的内容,可以用begin...end来表示代码的开始和结束
3.调用存储过程
call sp_name( [parameter[,...]] ); sp_name为存储过程名称,parameter为存储过程的参数。
exp:
#创建存储过程Countproc1
delimiter //
create procedure Countproc1 ( in sid int,out num int)
begin
select count(*) into num from fruits where s_id = sid;
end //
delimiter;
#调用存储过程
call Countproc1(101,@num);
#查看返回结果:
select @num;
4.查看存储过程信息
(1)查看存储过程和函数状态
show {procedure | function } status [like 'pattern']
show procedure status like 'C%'\G;
(2)查看存储过程和函数定义
show create {procedure | function } sp_name;
show create procedure countpric \G;
5.修改存储过程和函数
alter {procedure | function } sp_name [characteristic...]
说明:characteristic参数取值如下
sp_name 表示存储过程或函数的名称;characteristic指定存储过程或函数的特性
contains sql 表示子程序包含的SQL语句,但不包含读或写数据的语句。
no sql 表示子程序中不包含SQL语句
reads sql data 表示子程序中包含读数据的语句
modifies sql data 表示子程序包含写数据的语句
sql security {definer | invoker} 指明谁有权限来执行
definer 表示只有定义者自己才能够执行
invoker 表示调用者可以执行
comment 'string' 表示注释信息
6.删除存储过程和函数
drop {procedure | function } [if exists] sp_name
7.变量的使用(7-10也适用于自定义函数)
变量可以在子程序中声明并使用,这些变量的作用范围是在begin...end程序总。
a.定义变量
declare 变量名 数据类型 [default value];
declare myparam int default 100;
b.为变量赋值
set 变量名=expr[,var_name=expr]... set @变量名=expr; @变量名 表示为用户变量赋值 即一个客户端定义的变量不能被其他客户端看到或使用,当客户端退出时变量自动释放。 select col_name[,...] into var_name[,...] table_expr; 为一个或多个变量赋值
#声明变量fruitname和fruitprice,通过select...into语句查询指定记录并赋值给变量 declare fruitname char(50); declare fruitprice decimal(8,2); select f_name,f_price into fruitname,fruitprice from fruits where f_id='a1';
8.定义条件和处理程序
特点条件需要特点处理,这些条件可以联系到错误,以及子程序中的一般流程控制。定义条件是事先定义程序执行过程中遇到的问题,处理程序定义了遇到问题应采取的处理方式,来保证存储过程或函数在遇到警告或错误时能继续执行,这样可以增强存储过程处理问题的能力,避免程序异常停止运行。
(1)定义条件语法
declare condition_name condition for [condition_type] [condition_type]: sqlstate [value] sqlstate_value | mysql_err_code 说明: condition_name 表示条件名称 condition_type 表示条件的类型 sqlstate_value和mysql_err_code 都可以表示mysql的错误, sqlstate_value为长度5的字符串类型错误代码,mysql_err_code为数值类型的错误代码 如:ERROR 1142 (42000) sqlstate_value的值为42000,mysql_err_code的值为1142
exp:
方法1:使用sqlstate_value declare command_not_allowed condition for sqlstate '42000'; 方法2:使用mysql_err_code declare command_not_allowed condition for 1148;
(2)定义处理程序
declare handler_type handler for condition_value[,...] sp_statement
handler_type:
continue | exit | undo
condition_value:
sqlstate [value] sqlstate_value
| condition_name
| sqlwarning
| not found
| sqlexception
| mysql_err_code
说明:
handler_type为错误处理方式,参数取3个值:continue(错误不处理继续执行)、exit(遇到错误马上退出)和undo(遇到错误后撤回之前的操作)
condition_type 表示错误类型,有以下取值:
sqlstate[value] sqlstate_value:包含5个字符的字符串错误值;
condition_name 表示declare condition定义的错误条件名称;
sqlwarning 匹配所有以01开头的sqlstate错误代码;
not found 匹配所有没有被sqlwarning或not found捕获的sqlstate错误代码
mysql_err_code 匹配数值类型错误代码
sp_statement 参数为程序语句段,表示在遇到定义的错误时,需要执行的存储过程或函数。
1 方法1:捕获sqlstate_value 2 declare continue handler for sqlstate '42s02' set @info='no_such_table'; 3 捕获sqlstate_value值,如果遇到qlstate_value的值为42s02,执行continue操作,并且输出no_such_table信息 4 5 方法2:捕获mysql_err_code 6 declare continue handler for 1146 set @info='no_such_table'; 7 捕获mysql_err_code的值,如果遇到值为1146,执行continue操作,并且输出no_such_table信息 8 9 方法3:先定义条件,然后调用 10 declare no_such_table condition for 1146; 11 declare continue handler for no_such_table set @info='no_such_table'; 12 13 先定义条件,然后再调用条件,先定义no_such_table条件,遇到1146错误就执行continue操作 14 15 方法4:使用sqlwarning 16 declare exit handler for sqlwarning set @info='error'; 17 18 使用sqlwarning捕获所有以01开头的sqlstate_value值,然后执行exit操作,并且输出error信息 19 20 方法5:使用not found 21 declare exit handler for not found set @info='no_such_table'; 22 使用not found捕获所有以02开头的sqlstate_value值,然后执行exit操作,并且输出no_such_table信息 23 24 方法6:使用sqlexception 25 declare exit handler for sqlexception set @info='error'; 26 使用sqlexception捕获所有没有被sqlwarning或者not found捕获的sqlstate_value值,然后执行exit操作,并且输出error信息
exp:
mysql>create table test.t(s1 int,primary key (s1)); delimiter // create procedure handlerdemo() begin declare continue handler for sqlstate '23000' set @x2 = 1; set @x = 1; insert into test values (1); set @x = 2; insert into test values (1); set @x = 3; end // delimiter ; #调用存储过程 mysql> call handlerdemo(); Query OK, 0 rows affected (0.03 sec) #查看调用过程结果 mysql> select @x; +------+ | @x | +------+ | 3 | +------+ 1 row in set (0.00 sec) 说明:@x是一个用户变量,执行结果@x等于3,这表明mysql被执行到程序的末尾,如果declare continue handler for sqlstate '23000' set @x2 = 1; 这一行不存在,第二个insert 因为primary key强制而失败之后,mysql可能采取默认(exit)路径,并且select @x可能返回2.
9.光标(游标)的使用
使用光标的原因: 查询语句可能返回多条记录,如果数据量非常大,需要在存储过程和存储函数中使用光标来逐条读取查询结果集中的记录。
1 (1)声明光标 2 declare cursor_name cursor for select_statement; cursor_name表示光标名称,select_statement 表示select语句内容 3 4 (2)打开光标 5 open cursor_name; 打开之前声明的光标 6 7 (3)使用光标 8 fetch cursor_name into var_name [,var_name] ... (参数名称); 9 cursor_name 表示光标名称 10 var_name 表示将光标中的select 语句查询出的信息存入该参数中,var_name必须在声明光标之前就定义好 11 12 (4)关闭光标 13 close cursor_name; 关闭光标
10.流程控制的使用
流程控制语句用来根据条件控制语句的执行。
控制流程的语句有:if语句、case语句、loop语句、leave语句、inerate语句、repeat语句和while 语句。每个流程中可能包含一单独语句或者是使用begin...end构造的复合语句,构造可以被嵌套。
1 (1)if语句 2 if expr_condition then statement_list 3 [elseif expr_condition then statement_list] ... 4 [else statement_list] 5 end if 6 7 statement_list 可以包含一个或多个sql语句 8 exp: 9 if val is null 10 then select 'val is null'; val为空输出val is null 11 else select 'val is not null'; 12 end if; 13 14 (2)case语句 15 #第一种格式 16 case case_expr 17 when when_value then statement_list 18 [when when_value then statement_list] ... 19 [else statement_list] 20 end case 21 22 说明:case_expr表示条件判断表达式,决定哪个when子句会被执行; 23 when_value参数表示表达式可能的值,如果与case_expr表达式结果相符,则执行相应then后面的语句 24 exp; 25 case val 26 when 1 then select 'val is 1'; 27 when 2 then select 'val is 2'; 28 else select 'val is not 1 or 2'; 29 end case; 30 31 #第二种格式 32 case 33 when expr_condition then statemendt_list 34 [when expr_condition then statemendt_list] ... 35 [else statement_list] 36 end case 37 38 说明:when语句会被逐个执行,直到某个expr_condition条件为真,则执行then后面的语句,如果都没有匹配,则执行else子句的语句 39 exp: 40 case 41 when val is null then select 'val is null'; 42 when val < 0 then select 'val is less than 0'; 43 when val > 0 then select 'val is greater than 0'; 44 else select 'val is 0'; 45 end case; 46 47 (3)loop语句 48 loop循环语句用来重复执行某些语句,只创建循环操作的过程,并不进行条件判断。loop内的语句一直重复执行直到循环被退出,跳出 49 循环过程,使用leave子句。 50 [loop_label:] loop 51 statement_list 52 end loop [loop_label] 53 54 说明:loop_label表示Loop语句的标注名称,可以省略,statement_list表示要循环执行的语句。 55 exp:使用loop语句进行循环操作,id值小于等于10之前,将重复执行循环过程。 56 declare id int default 0; 57 add_loop:loop 58 set id = id + 1; 59 if id >= 10 then leave add_loop; 60 end if; 61 end loop add_loop; 62 63 (3)leave语句 64 leave用来退出任何被标记的流程控制构造 65 leave label; 66 67 exp: 68 add_num:loop 69 set @count = @count + 1; 70 if @count = 50 then leave add_num; 71 end loop add_num; 72 73 (5)inerate语句 再次循环 将执行顺序转到语句段开头处,只出现在loop、repeat和while语句内。 74 inerate label; 75 76 exp: 77 create procedure do_iterate() 78 begin 79 declare p1 int default 0; 80 my_loop:loop 81 set p1 = p1 + 1; 82 if p1 < 10 then iterate my_loop; 83 elseif p1 > 20 then leave my_loop; 84 end if; 85 select 'p1 is between 10 and 20'; 86 end loop my_loop; 87 end 88 89 (6)repeat 语句 90 repeat语句创建一个带条件判断的循环过程,每次语句执行完毕之后,会对条件表达式进行判断,条件为真,循环结束;否则重复执行循环中的语句。 91 92 [repeat_label:] repeat 93 statement_list 94 until expr_condition 95 end repeat [repeat_label] 96 说明:repeat 语句内的语句或语句群被重复,直至expr_condition为真。 97 98 exp: 99 declare id int default 0; 100 repeat 101 set id = id + 1; 102 until id >= 10 103 end repeat; 104 105 (7)while语句 106 创建一个带条件判断的循环过程,与repeat不同,while在执行语句时先对指定的条件进行判断,结果为真,则执行循环内的语句,否则退出循环。 107 108 [while_label:] while expr_condition do 109 statement_list 110 end while [while_label] 111 112 exp: 113 declare i int default 0; 114 while i < 10 do; 115 set i = i + 1; 116 end while;
11.实例
1 delimiter // 2 create PROCEDURE p1() 3 BEGIN 4 select * from student; 5 insert into teacher (tname) VALUES('felix'); 6 end // 7 delimiter ; 8 9 调用: 10 call p1() #mysql调用 11 cursor.callproc('p1') #pymysql调用
1 delimiter // 2 create procedure p2( 3 in n1 int, 4 in n2 int 5 ) 6 BEGIN 7 select * from student where sid > n1; 8 END // 9 delimiter ; 10 11 call p2(12,2) 12 cursor.callproc('p2',(12,2))
1 delimiter // 2 create procedure p3( 3 in n1 int, 4 inout n2 int 5 ) 6 BEGIN 7 set n2 = 123123; 8 select * from student where sid > n1; 9 END // 10 delimiter ; 11 12 set @v1 = 10; 创建session级别的变量v1 13 call p2(12,@v1) 14 select @v1; #获取变量v1的值 15 16 cursor.callproc('p3', (18, 2)) 17 conn.commit() 18 r1 = cursor.fetchall() 19 print(r1) 20 cursor.execute('select @_p3_0,@_p3_1') 21 r2 = cursor.fetchall() 22 print(r2) 23 执行结果: 24 [{'sid': 22, 'gender': '男', 'class_id': 1, 'sname': 'felix'}, {'sid': 23, 'gender': '女', 'class_id': 1, 'sname': 'alina'}] 25 [{'@_p3_0': 18, '@_p3_1': 123123}] 26 27 #以上python代码在mysql中实质为以下代码 28 set @_p3_0 = 12 #代表n1 29 ser @_p3_1 = 2 #代表n2 30 call p3(@_p3_0,@_p3_1) 31 select @_p3_0,@_p3_1 32 33 #为什么又结果集又有out伪造的返回值? 34 out值 用于标识存储过程的执行结果
1 delimiter \\ 2 create PROCEDURE p5( 3 OUT p_return_code tinyint 4 ) 5 BEGIN 6 DECLARE exit handler for sqlexception 7 BEGIN 8 -- ERROR 错误时会执行的代码 9 set p_return_code = 1; 10 rollback; 11 END; 12 13 START TRANSACTION; 14 DELETE from tb1; 15 insert into tb2(name)values('seven'); 16 COMMIT; 17 18 -- SUCCESS 正确时会执行的代码 19 set p_return_code = 2; 20 21 END\\ 22 delimiter ;
1 delimiter // 2 create procedure p6() 3 begin 4 declare row_id int; -- 自定义变量1 5 declare row_num int; -- 自定义变量2 6 declare done INT DEFAULT FALSE; #设定是否有无数据标识符 done 为false 7 declare temp int; #自定义变量temp 8 9 declare my_cursor CURSOR FOR select id,num from A;#创建游标 从A表循环取值id,num 10 declare CONTINUE HANDLER FOR NOT FOUND SET done = TRUE; #没有数据,done为True 11 12 open my_cursor;#打开游标 13 xxoo: LOOP #xxoo为循环名称,开始循环 14 fetch my_cursor into row_id,row_num; #取每行的值赋值给row_id,row_num 15 if done then #如果donw为true 离开(跳出)循环,类似于break 16 leave xxoo; 17 END IF; 18 19 set temp = row_id + row_num; #设置变量temp值为row_id + row_num 20 insert into B(number) values(temp); 21 end loop xxoo; 22 close my_cursor; 23 end // 24 delimter ; 25 26 mysql> truncate table b; 27 Query OK, 0 rows affected (0.04 sec) 28 29 mysql> insert into a(num) values(99),(98),(97),(96),(95); 30 Query OK, 5 rows affected (0.01 sec) 31 Records: 5 Duplicates: 0 Warnings: 0 32 33 mysql> select * from a; 34 +----+-----+ 35 | id | num | 36 +----+-----+ 37 | 1 | 99 | 38 | 2 | 98 | 39 | 3 | 97 | 40 | 4 | 96 | 41 | 5 | 95 | 42 +----+-----+ 43 5 rows in set (0.00 sec) 44 mysql> select * from b; 45 Empty set (0.00 sec) 46 47 mysql> call p6(); 48 Query OK, 0 rows affected (0.02 sec) 49 mysql> select * from b; 50 +-----+--------+ 51 | sid | number | 52 +-----+--------+ 53 | 1 | 100 | 54 | 2 | 100 | 55 | 3 | 100 | 56 | 4 | 100 | 57 | 5 | 100 | 58 +-----+--------+ 59 5 rows in set (0.00 sec)
1 delimiter // 2 create procedure p7( 3 in tpl varchar(255), 4 in arg int 5 ) 6 begin 7 # 1. 预检测某个东西 SQL语句合法性 8 # 2. SQL =格式化 tpl + arg 9 # 3. 执行SQL语句 10 set @xo = arg; 11 PREPARE xxx FROM 'select * from student where sid > ?'; 12 EXECUTE xxx USING @xo; 13 DEALLOCATE prepare xxx; 14 end // 15 delimter ; 16 17 #调用 18 call p7("select * from tb where id > ?",9) 19 20 delimiter \\ 21 CREATE PROCEDURE p8 ( 22 in nid int 23 ) 24 BEGIN 25 set @nid = nid; 26 PREPARE prod FROM 'select * from student where sid > ?'; 27 EXECUTE prod USING @nid; 28 DEALLOCATE prepare prod; 29 END\\ 30 delimiter ;
1.索引含义和特点
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可提高数据的查询速度。是一个单独的、存储在磁盘上的数据库结构,它们包含着对数据表里所有记录的引用指针。
2.索引种类
索引是在存储引擎中实现的,因此每种存储引擎都不一定完全相同,并且每种存储引擎也不一定支持所有的索引类型。
mysql中索引类型有两种:btree和hash,myisam和innodb只支持btree索引,memory存储引擎可以支持hash和btree
3.索引的优缺点
优点:
- 通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
- 加快数据查询速度,这是创建索引最主要原因。
- 在实现数据的参考完整性方面,可以加速表和表之前的连接。
- 在使用分组和排序子句中进行查询时,可以减少查询中分组和排序的时间。
缺点:
- 创建索引和维护索引要耗费时间,并随着数据量的增加所耗费的时间也会增加。
- 索引需要占用一定的物理磁盘空间,如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸。
- 当对数据进行增删改的时候,索引页要动态的维护,降低了数据的维护速度。
4.索引分类
普通索引:基本索引类型,允许插入重复值和空值
唯一索引:值必须唯一允许空值,主键索引是一种特殊的唯一索引,不允许有空值
单列索引:一个索引只包含单个列,一个表中可以有多个单列索引
组合索引:在表的多个字段组合上创建的所有,只有在查询条件中使用这些字段最左边的字段时,索引才会被使用。遵循最左前缀匹配原则。
- 联合主键索引
- 联合唯一索引
- 联合普通索引
全文索引:fulltext 在定义索引的列上支持值的全文查找,只有在myisam存储引擎支持。
空间索引:是对空间数据类型字段建立的索引,4种空间数据类型:geometry、point、linestring和polygon
其他索引名词:
覆盖索引(在索引列上直接获取数据),select name from user where name='test2999999';
索引合并
- 主键索引:加速查找、不能为空、不能重复
- 唯一索引:加速查找、不能重复
- 联合索引(多列)
- 联合主键索引
- 联合唯一索引
- 联合普通索引
5.索引设计原则
数据库表中添加索引后确实会让查询速度起飞,但前提必须是正确的使用索引来查询,如果以错误的方式使用,则即使建立索引也会不奏效。即使建立索引,索引也不会生效:
- 索引并发越多越好,一个表中有大量的索引不仅占用磁盘空间,也会影响insert、delete、update等语句的性能,因为当数据更改的同时,索引页会进行调整和更新。
- 避免对经常更新的表进行过多的索引,并且索引中的列尽可能的少,且要避免不必要的字段
- 数据量小的表最好不要使用索引
- 在条件表达式经常用到的不同值较多的列建立索引,在不同值很少的列上不要建立索引。比如性别 男女
- 当唯一性是某种数据本身的特征时,指定唯一索引。
- 在频繁进行排序或分组的列上建立索引,如果待排序的列有多个可以在这些列上建立组合索引。
1 - like '%xx' 2 select * from tb1 where name like '%cn'; 3 - 使用函数 4 select * from tb1 where reverse(name) = 'wupeiqi'; 5 - or 6 select * from tb1 where nid = 1 or email = 'seven@live.com'; 7 特别的:当or条件中有未建立索引的列才失效,以下会走索引 8 select * from tb1 where nid = 1 or name = 'seven'; 9 select * from tb1 where nid = 1 or email = 'seven@live.com' and name = 'alex' 10 - 类型不一致 11 如果列是字符串类型,传入条件是必须用引号引起来,不然... 12 select * from tb1 where name = 999; 13 - != 14 select * from tb1 where name != 'alex' 15 特别的:如果是主键,则还是会走索引 16 select * from tb1 where nid != 123 17 - > 18 select * from tb1 where name > 'alex' 19 特别的:如果是主键或索引是整数类型,则还是会走索引 20 select * from tb1 where nid > 123 21 select * from tb1 where num > 123 22 - order by 23 select email from tb1 order by name desc; 24 当根据索引排序时候,选择的映射如果不是索引,则不走索引 25 特别的:如果对主键排序,则还是走索引: 26 select * from tb1 order by nid desc; 27 28 - 组合索引最左前缀 29 如果组合索引为:(name,email) 30 name and email -- 使用索引 31 name -- 使用索引 32 email -- 不使用索引 33 34 其他注意事项 35 - 避免使用select * 36 - count(1)或count(列) 代替 count(*) 37 - 创建表时尽量时 char 代替 varchar 38 - 表的字段顺序固定长度的字段优先 39 - 组合索引代替多个单列索引(经常使用多个条件查询时) 40 - 尽量使用短索引 41 - 使用连接(JOIN)来代替子查询(Sub-Queries) 42 - 连表时注意条件类型需一致 43 - 索引散列值(重复少)不适合建索引,例:性别不适合
6.创建索引
create table table_name [col_name date_type] [unique | fulltext | spatial] [index | key] [index_name] (col_name[length]) [asc | desc] 说明: unique、fulltext和spatial 为可选参数,分别表示唯一索引、全文索引、空间索引 index和key 两者作用相同 都是创建索引 col_name 为需要创建索引的字段列 index_name 索引名称,默认值为col_name,length为可选参数,表索引长度(只有字符串类型的才能制定索引长度)
1 exp:创建普通索引 2 create table book( 3 bookid int not null, 4 bookname varchar(255) not null, 5 authors varchar(255) not null, 6 info varchar(255) not null, 7 comment varchar(255) not null, 8 year_publication year not null, 9 index (year_publication) ); 10 11 exp:创建唯一索引 12 create table t1( 13 id int not null, 14 name char(30) not null, 15 unique index UniqIdx(id) ); 16 17 exp:创建单列索引 18 create table t2( 19 id int not null, 20 name char(50) null, 21 index SingeleIdx(name(20)) ); 22 23 exp:创建组合索引 24 create table t3 ( 25 id int not null, 26 name char (30) not null, 27 age int not null, 28 index MultiIdx(id,name,age(100)) ); 29 30 exp:创建全文索引 31 create table t4 ( 32 id int not null, 33 name char(30) not null, 34 age int not null, 35 info varchar(255), 36 fulltext index FullTxtIdx(info)) engine=myisam; 37 38 exp:创建空间索引 39 create table t5 ( 40 g geometry not null, 41 spatial index spatIdx(g) ) engine=myisam;
1 a.使用alter table 语句创建索引 2 alter table table_name add [unique | fulltext | spatial] [index | key] 3 [index_name] (col_name[length],...) [asc | desc] 4 5 alter table book add index BkNameIdx (bookname(30)); 6 7 alter table book add fulltext index infoFultextIdx(info); 8 9 b.使用create index 创建索引 10 create [unique | fulltext | spatial] index index_name on table_name (col_name[length],...) [asc | desc] 11 12 #创建普通索引 13 create index idx_bookname on book(bookname); 14 15 #创建唯一索引 16 create unique index idx_id on book(bookid); 17 18 #创建组合索引 19 create index idx_bookname_author on book(bookname(20),author(20)); 20 21 #创建空间索引 注意表的存储引擎为myisam 22 create table t7(g geometry not null) engine=myisam; 23 24 create spatial index spatIdx on book(g);
7.查看索引
show index from 表名\G;
1 mysql> show index from hjx_data\G; 2 *************************** 1. row *************************** 3 Table: hjx_data 4 Non_unique: 0 5 Key_name: PRIMARY 6 Seq_in_index: 1 7 Column_name: row_id 8 Collation: A 9 Cardinality: 3146 10 Sub_part: NULL 11 Packed: NULL 12 Null: 13 Index_type: BTREE 14 Comment: 15 Index_comment: 16 *************************** 2. row *************************** 17 Table: hjx_data 18 Non_unique: 1 19 Key_name: idx_dt 20 Seq_in_index: 1 21 Column_name: dt 22 Collation: A 23 Cardinality: 167 24 Sub_part: NULL 25 Packed: NULL 26 Null: 27 Index_type: BTREE 28 Comment: 29 Index_comment: 30 2 rows in set (0.00 sec) 31 32 mysql> show create table hjx_data\G; 33 *************************** 1. row *************************** 34 Table: hjx_data 35 Create Table: CREATE TABLE `hjx_data` ( 36 `row_id` int(4) NOT NULL AUTO_INCREMENT, 37 `id` char(5) NOT NULL, 38 `st` tinyint(1) NOT NULL, 39 `yw` float(4,1) DEFAULT NULL, 40 `sw` float(4,1) DEFAULT NULL, 41 `ys` float(4,1) DEFAULT NULL, 42 `ss` float(4,1) DEFAULT NULL, 43 `dt` datetime(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6), 44 PRIMARY KEY (`row_id`), 45 KEY `idx_dt` (`dt`) 46 ) ENGINE=InnoDB AUTO_INCREMENT=3250 DEFAULT CHARSET=utf8 47 1 row in set (0.00 sec) 48 49 ERROR: 50 No query specified
8.删除索引
(1)使用alter table 删除索引
alter table table_name drop index index_name;
(2)使用drop index语句删除索引
drop index index_name on table_name;

