


模块
阅读目录
模块和包
常用模块
- 正则表达式
- re模块
- collections模块
- random模块
- time模块
- OS模块
- sys模块
- 序列化模块
- hashlib模块
- configparse模块
- logging模块
- struct模块
1.模块分为四个通用类别:
- 使用python编写的代码(.py文件)
- 已被编译为共享库或DLL的C或C++扩展
- 包好一组模块的包
- 使用C编写并链接到python解释器的内置模块
2.导入方法:
(1)import 模块名
import 模块名
模块名.变量名 和本文件中的变量名完全不冲突
import 模块名 as 重命名的模块名 : 提高代码的兼容性
import 模块1,模块2
(2)from 模块名 import 变量名
直接使用 变量名 就可以完成操作
如果本文件中有相同的变量名会发生冲突
from 模块名 import 变量名字 as 重命名变量名
from 模块名 import 变量名1,变量名2
from 模块名 import *
将模块中的所有变量名都放到内存中
如果本文件中有相同的变量名会发生冲突
from 模块名 import * 和 __all__ 是一对
没有这个变量,就会导入所有的名字
如果有all 只导入all列表中的名字
__name__
在模块中 有一个变量__name__,
当我们直接执行这个模块的时候,__name__ == '__main__'
当我们执行其他模块,在其他模块中引用这个模块的时候,这个模块中的__name__ == '模块的名字'
二、包
包是一种通过使用‘.模块名’来组织python模块名称空间的方式。
1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:
这是关于包才有的导入语法
2. 包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3. import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的
__init__.py,导入包本质就是在导入该文件
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,
否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间


import os os.makedirs('glance/api') os.makedirs('glance/cmd') os.makedirs('glance/db') l = [] l.append(open('glance/__init__.py','w')) l.append(open('glance/api/__init__.py','w')) l.append(open('glance/api/policy.py','w')) l.append(open('glance/api/versions.py','w')) l.append(open('glance/cmd/__init__.py','w')) l.append(open('glance/cmd/manage.py','w')) l.append(open('glance/db/models.py','w')) map(lambda f:f.close() ,l)
目录结构
glance/ #Top-level package
├── __init__.py #Initialize the glance package
├── api #Subpackage for api
│ ├── __init__.py
│ ├── policy.py
│ └── versions.py
├── cmd #Subpackage for cmd
│ ├── __init__.py
│ └── manage.py
└── db #Subpackage for db
├── __init__.py
└── models.py
#文件内容 #policy.py def get(): print('from policy.py') #versions.py def create_resource(conf): print('from version.py: ',conf) #manage.py def main(): print('from manage.py') #models.py def register_models(engine): print('from models.py: ',engine)
2.1 注意事项
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:
凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
2.2 import
我们在与包glance同级别的文件中测试
1 import glance.db.models
2 glance.db.models.register_models('mysql')
2.3 from ... import ...
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
我们在与包glance同级别的文件中测试
1 from glance.db import models
2 models.register_models('mysql')
3
4 from glance.db.models import register_models
5 register_models('mysql')
2.4 __init__.py文件
不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的__init__.py文件(我们可以在每个包的文件内
都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码。
2.5 from glance.api import *
在讲模块时,我们已经讨论过了从一个模块内导入所有*,此处我们研究从一个包导入所有*。
此处是想从包api中导入所有,实际上该语句只会导入包api下__init__.py文件中定义的名字,我们可以在这个文件中定义__all___:
#在__init__.py中定义
x=10
def func():
print('from api.__init.py')
__all__=['x','func','policy']
此时我们在于glance同级的文件中执行from glance.api import *就导入__all__中的内容(versions仍然不能导入)。
glance/
├── __init__.py
├── api
│ ├── __init__.py __all__ = ['policy','versions']
│ ├── policy.py
│ └── versions.py
├── cmd __all__ = ['manage']
│ ├── __init__.py
│ └── manage.py
└── db __all__ = ['models']
├── __init__.py
└── models.py
from glance.api import *
policy.get()
2.6 绝对导入和相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
例如:我们在glance/api/version.py中想要导入glance/cmd/manage.py
在glance/api/version.py
#绝对导入
from glance.cmd import manage
manage.main()
#相对导入
from ..cmd import manage
manage.main()
测试结果:注意一定要在于glance同级的文件中测试
1 from glance.api import versions
注意:在使用pycharm时,有的情况会为你多做一些事情,这是软件相关的东西,会影响你对模块导入的理解,因而在测试时,
一定要回到命令行去执行,模拟我们生产环境,你总不能拿着pycharm去上线代码吧!!!
特别需要注意的是:可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用import来导入
自定义包的子模块(没有在sys.path中),应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
比如我们想在glance/api/versions.py中导入glance/api/policy.py,有的同学一抽这俩模块是在同一个目录下,
十分开心的就去做了,它直接这么做
1 #在version.py中
2
3 import policy
4 policy.get()
没错,我们单独运行version.py是一点问题没有的,运行version.py的路径搜索就是从当前路径开始的,于是在导入
policy时能在当前目录下找到
但是你想啊,你子包中的模块version.py极有可能是被一个glance包同一级别的其他文件导入,比如我们在于glance
同级下的一个test.py文件中导入version.py,如下
from glance.api import versions
执行结果:
ImportError: No module named 'policy'
分析:
此时我们导入versions在versions.py中执行
import policy需要找从sys.path也就是从当前目录找policy.py,
这必然是找不到的
绝对导入
glance/
├── __init__.py from glance import api
from glance import cmd
from glance import db
├── api
│ ├── __init__.py from glance.api import policy
from glance.api import versions
│ ├── policy.py
│ └── versions.py
├── cmd from glance.cmd import manage
│ ├── __init__.py
│ └── manage.py
└── db from glance.db import models
├── __init__.py
└── models.py
相对导入
glance/
├── __init__.py from . import api #.表示当前目录
from . import cmd
from . import db
├── api
│ ├── __init__.py from . import policy
from . import versions
│ ├── policy.py
│ └── versions.py
├── cmd from . import manage
│ ├── __init__.py
│ └── manage.py from ..api import policy
#..表示上一级目录,想再manage中使用policy中的方法就需要回到上一级glance目录往下找api包,从api导入policy
└── db from . import models
├── __init__.py
└── models.py
2.7 单独导入包
单独导入包名称时不会导入包中所有包含的所有子模块,如
#在与glance同级的test.py中
import glance
glance.cmd.manage.main()
执行结果:
AttributeError: module 'glance' has no attribute 'cmd'
解决方法:
1 #glance/__init__.py
2 from . import cmd
3
4 #glance/cmd/__init__.py
5 from . import manage
执行:
1 #在于glance同级的test.py中
2 import glance
3 glance.cmd.manage.main()
千万别问:__all__不能解决吗,__all__是用于控制from...import *
import glance之后直接调用模块中的方法
glance/
├── __init__.py from .api import *
from .cmd import *
from .db import *
├── api
│ ├── __init__.py __all__ = ['policy','versions']
│ ├── policy.py
│ └── versions.py
├── cmd __all__ = ['manage']
│ ├── __init__.py
│ └── manage.py
└── db __all__ = ['models']
├── __init__.py
└── models.py
import glance
policy.get()
1.何为正则表达式?
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
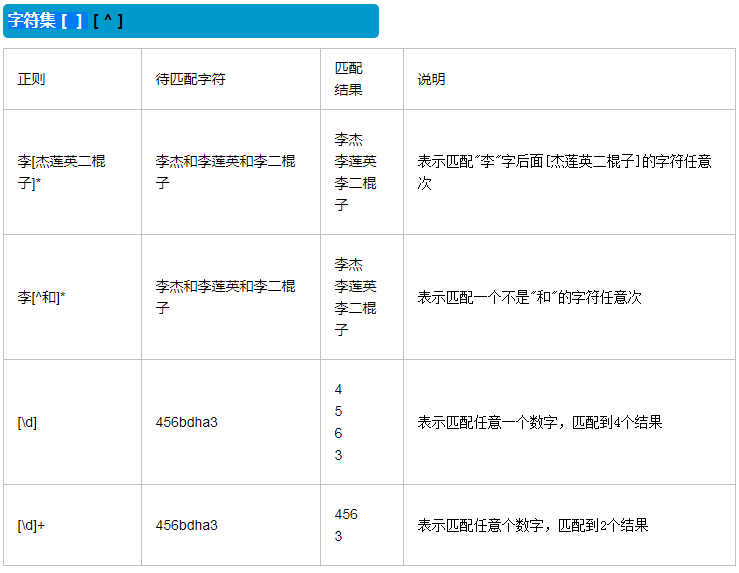
2.字符组 [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示字符分为很多类,比如数字、字母、标点等等。假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
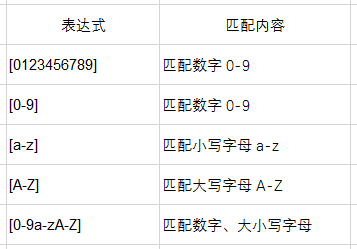
3.元字符
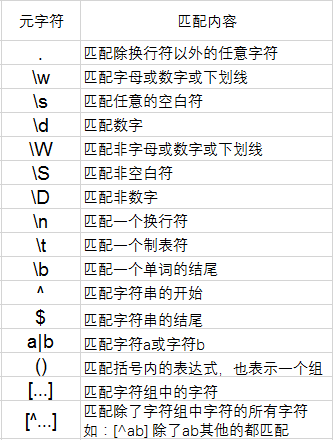
4.量词

量词必须紧跟在规则后面 如: [a-z]+\d+
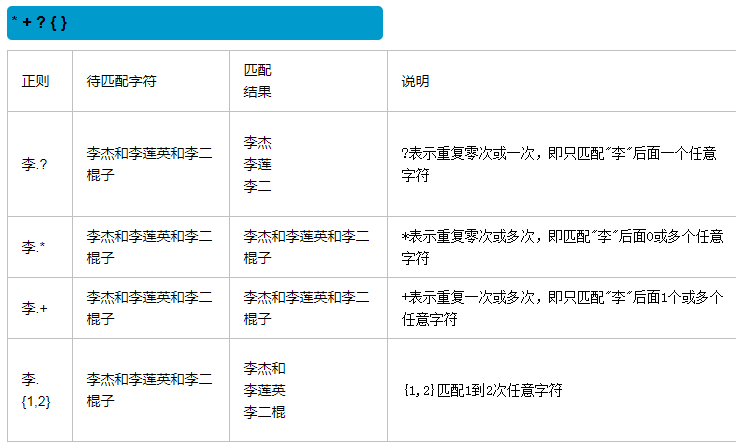
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
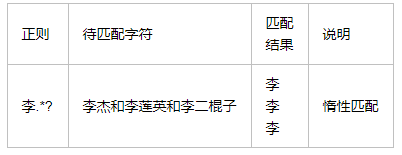
5.分组 ()与 或 |[^]
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部🈶️数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:

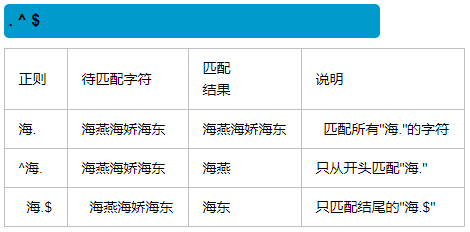
注:为了方便讲解,我们在正则表达式的两端添加了^ 和 $ ,它们分别定位到字符串的起始位置和结束位置,这样确保表达式不会只匹配字符串的某个子串,
如果要用表达式来提取数据,应去掉^和$。
括号的这种功能叫做分组(grouping),如果用量词限定出现次数的元素不是字符或者字符组,而是几个字符甚至表达式,就应该用括号将它们“分为一组”,
如希望字符串ab重复出现一次以上,就应该写成 (ab)+,此时(ab)成为一个整体,由量词 + 来限定;如果不用括号尔直接写ab+,受+限定的就只有b。
6.转义符
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。
所以如果匹配一次"\n",字符串中要写成'\\n',那么正则里就要写成"\\\\n",这样就太麻烦了。这个时候我们就用到了r'\n'这个概念,此时的正则是r'\\n'就可以了。

7.贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配

几个常用的非贪婪匹配
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 合在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
1.re.findall(string[, pos[, endpos]]) 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,
如果没有找到匹配的,则返回空列表。
import re
ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
2.re.search(pattern, string, flags=0) 扫描整个字符串并返回第一个成功的匹配。
参数 描述
pattern 匹配的正则表达式
string 要匹配的字符串。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志
ret = re.search('a', 'eva egon yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
3.re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配
print(ret)
#结果 : 'a'
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
4.re.split(pattern, string[, maxsplit=0, flags=0]) 方法按照能够匹配的子串将字符串分割后返回列表
pattern 匹配的正则表达式
string 要匹配的字符串。
maxsplit 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
5.re.sub(pattern, repl, string, count=0) 用于替换字符串中的匹配项。
参数:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
6.re.subn
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
7.re.compile(pattern[, flags]) 用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
参数:
pattern : 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为' . '并且包括换行符在内的任意字符(' . '不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和' # '后面的注释
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
8.re.finditer(pattern, string, flags=0) 和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
参数 描述
pattern 匹配的正则表达式
string 要匹配的字符串。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
9.flag可用参数
re.I 使匹配对大小写不敏感
re.L 做本地化识别(locale-aware)匹配
re.M 多行匹配,影响 ^ 和 $
re.S 使 . 匹配包括换行在内的所有字符
re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
五、collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 命名元组,生成可以使用名字来访问元素内容的tuple
from collections import namedtuple
Point = namedtuple('point',['x','y'])
p = Point(3,6)
print(p.x)
print(p.y)
print(p.x+p.y)
执行结果:
3
6
9
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
队列:
import queue q = queue.Queue() q.put(10) q.put(5) q.put(1) print(q) print(q.qsize()) print(q.get()) print(q.qsize()) print(q.get()) print(q.qsize()) print(q.get()) 执行结果: <queue.Queue object at 0x00000000026FAD30> 3 10 2 5 1 1
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,
插入和删除效率很低。
deque(双端队列)是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
from collections import deque dq = deque([1, 2, 3]) dq.append() # 从尾部插入一个元素 dq.appendleft() # 从左边插入一个元素 dq.pop() # 从尾部删除一个元素 dq.popleft() # 从左边删除一个元素 dq.insert(index, value) # 在索引处插入一个元素 deque(['y', 'a', 'b', 'c', 'x']) deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
3.Counter: 计数器,主要用来计数
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,
其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
4.OrderedDict: 有序字典
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
5.defaultdict: 带有默认值的字典
有如下值集合[11, 22, 33, 44, 55, 66, 77, 88, 99, 90...],将所有大于66的值保存至字典的第一个key中,将小于66的值保存至第二个key的值中。
即: {'k1': 大于66, 'k2': 小于66}
原生字典解决方法
values = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
my_dict = {}
for value in values:
if value > 66:
if my_dict.has_key('k1'):
my_dict['k1'].append(value)
else:
my_dict['k1'] = [value]
else:
if my_dict.has_key('k2'):
my_dict['k2'].append(value)
else:
my_dict['k2'] = [value]
defaultdict字典解决方法
from collections import defaultdict
values = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
my_dict = defaultdict(list)
for value in values:
if value > 66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
六、random模块
>>> import random #随机小数 >>> random.random() # 大于0且小于1之间的小数 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #随机整数 >>> random.randint(1,5) # 大于等于1且小于等于5之间的整数 >>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 >>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合 [[4, 5], '23'] #打乱列表顺序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打乱次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
七、time模块
import time
time.time()
表示时间的三种方式
1.时间戳时间-float时间:计算机看的
时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
time.time()
1538823009.6988952
2.格式化时间-字符串:给人看的
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
python中时间日期格式化符号:
EXP:
time.strftime("%Y-%m-%d %H:%M:%S")
'2018-10-06 19:01:16'
time.strftime("%Y-%m-%d %A %H:%M:%S" )
'2018-10-06 Saturday 19:02:32'
3.结构化时间-元组:计算用的
time.localtime()
time.struct_time(tm_year=2018, tm_mon=10, tm_mday=6, tm_hour=19, tm_min=17, tm_sec=32, tm_wday=5,
tm_yday=279, tm_isdst=0)
4.几种格式之间的转换
time.localtime() 本地时间戳
time.gmtime() UTC时间
(1)时间戳-->结构化时间
time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致
time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间
>>>time.gmtime(1500000000)
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
>>>time.localtime(1500000000)
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
(2)结构化时间-->时间戳
time.mktime(结构化时间)
>>>time_tuple = time.localtime(1500000000)
>>>time.mktime(time_tuple)
1500000000.0
(3)结构化时间-->字符串时间
time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 14:55:36'
>>>time.strftime("%Y-%m-%d",time.localtime(1500000000))
'2017-07-14'
(4)字符串时间-->结构化时间
time.strptime(时间字符串,字符串对应格式)
>>>time.strptime("2017-03-16","%Y-%m-%d")
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
>>>time.strptime("07/24/2017","%m/%d/%Y")
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
(5)结构化时间 --> %a %b %d %H:%M:%S %Y串
time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
>>>time.asctime(time.localtime(1500000000))
'Fri Jul 14 10:40:00 2017'
>>>time.asctime()
'Mon Jul 24 15:18:33 2017'
(6)时间戳 --> %a %b %d %H:%M:%S %Y串
time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
>>>time.ctime()
'Mon Jul 24 15:19:07 2017'
>>>time.ctime(1500000000)
'Fri Jul 14 10:40:00 2017'
import time true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S')) time_now=time.mktime(time.strptime('2018-09-12 11:00:00','%Y-%m-%d %H:%M:%S')) dif_time=time_now-true_time struct_time=time.gmtime(dif_time) print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1, struct_time.tm_mday-1,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec)) 执行结果: 过去了1年0月1天2小时30分钟0秒
八、OS模块
1.模块参数
1.os.remove('文件名') 删除文件,参数为python执行文件的同一目录下文件名,或者其他位置的文件名如D:\DCIM\103APPLE.jpg 2.os.rename('修改前的文件名','修改后的文件名') 文件重命名 3.os.path.join(path1[, path2[, ...]]) 将路径和文件夹连接,表示文件夹和文件夹所在的路径 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 如:D:\DCIM\103APPLE os.path.join(root, file) 将路径和文件名连接表示文件所在的路径 如:D:\DCIM\100APPLE\IMG_0022.JPG 4.os.path.getsize() 计算文件的大小,单位为字节,参数为字符串 os.path.getsize('D:\DCIM\100APPLE\IMG_0022.JPG') os.path.getsize(os.path.join(root, file)) 5.os.walk(top, topdown=True, onerror=None, followlinks=False) 遍历文件夹下的文件夹、子文件夹下的文件 6.os.makedirs('dirname1/dirname2') 可生成多层递归目录 7.os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 8.os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname 9.os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 10.os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 11.os.stat('path/filename') 获取文件/目录信息 12.os.system("bash command") 运行shell命令,直接显示 13.os.popen("bash command).read() 运行shell命令,获取执行结果 14.os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 15.os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.path 16.os.path.abspath(path) 返回path规范化的绝对路径 17.os.path.split(path) 将path分割成目录和文件名二元组返回 18.os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 19.os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 20.os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 21.os.path.isabs(path) 如果path是绝对路径,返回True 22.os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 23.os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 24.os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 25.os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 26.os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 27.os.path.getsize(path) 返回path的大小
2.os.walk详解
1.参数说明 (1)top 表示文件名,或者带文件路径的文件名,是一个字符串 如:'Y:\Finished project\\2015'或者'file' (2)topdown=True 或者未指定时,表示从上到下,就是从根目录到字目录 (3)onerror=None 表示遇到错误时的处理,默认忽略错误 (4)followlinks=False 默认遇到链接(快捷方式)不去访问链接的文件夹已经子文件夹、文件 注意:followlinks=True 遇到链接时就会去访问链接所在的目录了,就不在继续walk()原目录了 2.用法: 导入os模块 路径+文件夹+文件 用for循环去遍历路径、文件夹、文件 for root, dirs, files in os.walk('D:\DCIM'): print(root) print(dirs) print(files) root:返回结果为 所有文件所在的路径 ,类型为字符串 D:\DCIM D:\DCIM\100APPLE D:\DCIM\100APPLE\新建文件夹 dirs:返回结果为 所有文件夹包括子文件夹组成的列表 没有文件夹返回空列表 ['100APPLE', '101APPLE', '102APPLE', '103APPLE'] ['新建文件夹'] [] [] [] [] files:返回结果 文件组成的列表,没有文件为空列表
实例:
import os def total_docment(dir,filename): files_num = 0 docment_num = 0 sum = 0 prt_count = 0 for root, dirs, files in os.walk(dir,topdown=True): for dir_name in dirs: docment_num += 1 prt_count += 1 with open(filename,'a+',encoding='utf-8') as f: f.write(os.path.join(root, dir_name)+'\n') #print(os.path.join(root, dir_name)) print('#',end='') if prt_count % 100 == 0: print() for file_name in files: files_num += 1 prt_count += 1 with open(filename,'a+',encoding='utf-8') as f: f.write(os.path.join(root, file_name)+'\n') #print(os.path.join(root, file_name)) print('*',end='') sum += os.path.getsize(os.path.join(root, file_name)) if prt_count % 100 == 0: print() with open(filename, 'a+', encoding='utf-8') as f: f.write('目录{}下:共{}个文件夹,{}个文件,大小为{} 字节。'.format(dir,docment_num,files_num,sum)) print('目录{}下:共{}个文件夹,{}个文件,大小为{} 字节。'.format(dir,docment_num,files_num,sum)) total_docment('X:\\2016','D:\QA_2016.txt')
九、sys模块
1.常用方法
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.modules 返回系统导入的模块字段,key是模块名,value是模块
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
sys.modules.keys() 返回所有已经导入的模块名
sys.modules.values() 返回所有已经导入的模块
sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息
sys.exit(n) 退出程序,正常退出时exit(0)
sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
sys.version 获取Python解释程序的
sys.api_version 解释器的C的API版本
sys.version_info ‘final’表示最终,也有’candidate’表示候选,serial表示版本级别,是否有后继的发行
sys.displayhook(value) 如果value非空,这个函数会把他输出到sys.stdout,并且将他保存进__builtin__._.指在python的交互式解释器里,’_’ 代表上次你输入得到的结果,hook是钩子的意思,将上次的结果钩过来
sys.getdefaultencoding() 返回当前你所用的默认的字符编码格式
sys.getfilesystemencoding() 返回将Unicode文件名转换成系统文件名的编码的名字
sys.setdefaultencoding(name)用来设置当前默认的字符编码,如果name和任何一个可用的编码都不匹配,抛出 LookupError,这个函数只会被site模块的sitecustomize使用,一旦别site模块使用了,他会从sys模块移除
sys.builtin_module_names Python解释器导入的模块列表
sys.executable Python解释程序路径
sys.getwindowsversion() 获取Windows的版本
sys.copyright 记录python版权相关的东西
sys.byteorder 本地字节规则的指示器,big-endian平台的值是’big’,little-endian平台的值是’little’
sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix 返回平台独立的python文件安装的位置
sys.stderr 错误输出
sys.stdin 标准输入
sys.stdout 标准输出
sys.platform 返回操作系统平台名称
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.maxunicode 最大的Unicode值
sys.maxint 最大的Int值
sys.version 获取Python解释程序的版本信息
sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
2.重点方法实例
import sys sys.platform 查询系统所有操作系统 print(sys.platform) 执行结果: win32 sys.exit(0) sys.exit(1) print(sys.version) 执行结果: 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] print(sys.path) #记录了所有搜索模块的路径 执行结果: ['D:\\Python_learn\\Study\\10.6模块', 'D:\\Python_learn\\Study', 'D:\\Python_learn\\Study\\venv\\Scripts\\python37.zip', 'D:\\Python37\\DLLs', 'D:\\Python37\\lib', 'D:\\Python37', 'D:\\Python_learn\\Study\\venv', 'D:\\Python_learn\\Study\\venv\\lib\\site-packages', 'D:\\Python37\\lib\\site-packages', 'D:\\Python37\\lib\\site-packages\\win32', 'D:\\Python37\\lib\\site-packages\\win32\\lib', 'D:\\Python37\\lib\\site-packages\\Pythonwin', 'C:\\Program Files\\JetBrains\\PyCharm 2018.1.4\\helpers\\pycharm_matplotlib_backend'] sys.path.clear() #清楚所有搜索模块路径 sys.path.append(r'd:\123') #增加路径 sys.path.append(os.getcwd()) #增加当前路径 exp: import sys,os print(sys.argv) ret = sys.argv #执行脚本之前传递参数 print(ret[0]) #程序本身的路径 print(ret[1]) #执行脚本所传递的第一个参数 print(ret[2]) #执行脚本所传递的第二个参数 if ret[1] == 'felix' and ret[2] == '1231': print('登录成功!') else: print('登录失败!') sys.exit() #以上程序,只能在服务器终端运行,在pycharm运行 会报错 exp: import sys,qrcode from threading import Thread print(sys.modules) print(sys.modules['threading']) print(sys.modules['qrcode']) 执行结果: {'sys': <module 'sys' (built-in)>, 'builtins': <module 'builtins' (built-in)>, '_frozen_importlib': <module '_frozen_importlib' (frozen)>, '_imp': <module '_imp' (built-in)>, '_thread': <module '_thread' (built-in)>, '_warnings': <module '_warnings' (built-in)>, '_weakref': <module '_weakref' (built-in)>, 'zipimport': <module 'zipimport' (built-in)>, '_frozen_importlib_external': <module '_frozen_importlib_external' (frozen)>, '_io': <module 'io' (built-in)>, 'marshal': <module 'marshal' (built-in)>, 'nt': <module 'nt' (built-in)>, 'winreg': <module 'winreg' (built-in)>, 'encodings': <module 'encodings' from 'D:\\Python37\\lib\\encodings\\__init__.py'>, 'codecs': <module 'codecs' from 'D:\\Python37\\lib\\codecs.py'>, '_codecs': <module '_codecs' (built-in)>, 'encodings.aliases': <module 'encodings.aliases' from 'D:\\Python37\\lib\\encodings\\aliases.py'>, 'encodings.utf_8': <module 'encodings.utf_8' from 'D:\\Python37\\lib\\encodings\\utf_8.py'>, '_signal': <module '_signal' (built-in)>, '__main__': <module '__main__' from 'D:/Python_learn/Study/10.6模块/5.sys模块.py'>, 'encodings.latin_1': <module 'encodings.latin_1' from 'D:\\Python37\\lib\\encodings\\latin_1.py'>, 'io': <module 'io' from 'D:\\Python37\\lib\\io.py'>, 'abc': <module 'abc' from 'D:\\Python37\\lib\\abc.py'>, '_abc': <module '_abc' (built-in)>, 'site': <module 'site' from 'D:\\Python37\\lib\\site.py'>, 'os': <module 'os' from 'D:\\Python37\\lib\\os.py'>, 'stat': <module 'stat' from 'D:\\Python37\\lib\\stat.py'>, '_stat': <module '_stat' (built-in)>, 'ntpath': <module 'ntpath' from 'D:\\Python37\\lib\\ntpath.py'>, 'genericpath': <module 'genericpath' from 'D:\\Python37\\lib\\genericpath.py'>, 'os.path': <module 'ntpath' from 'D:\\Python37\\lib\\ntpath.py'>, '_collections_abc': <module '_collections_abc' from 'D:\\Python37\\lib\\_collections_abc.py'>, '_sitebuiltins': <module '_sitebuiltins' from 'D:\\Python37\\lib\\_sitebuiltins.py'>, '_bootlocale': <module '_bootlocale' from 'D:\\Python37\\lib\\_bootlocale.py'>, '_locale': <module '_locale' (built-in)>, 'encodings.gbk': <module 'encodings.gbk' from 'D:\\Python37\\lib\\encodings\\gbk.py'>, '_codecs_cn': <module '_codecs_cn' (built-in)>, '_multibytecodec': <module '_multibytecodec' (built-in)>, 'sitecustomize': <module 'sitecustomize' from 'C:\\Program Files\\JetBrains\\PyCharm 2018.1.4\\helpers\\pycharm_matplotlib_backend\\sitecustomize.py'>, 'qrcode': <module 'qrcode' from 'D:\\Python37\\lib\\site-packages\\qrcode\\__init__.py'>, 'qrcode.main': <module 'qrcode.main' from 'D:\\Python37\\lib\\site-packages\\qrcode\\main.py'>, 'qrcode.constants': <module 'qrcode.constants' from 'D:\\Python37\\lib\\site-packages\\qrcode\\constants.py'>, 'qrcode.exceptions': <module 'qrcode.exceptions' from 'D:\\Python37\\lib\\site-packages\\qrcode\\exceptions.py'>, 'qrcode.util': <module 'qrcode.util' from 'D:\\Python37\\lib\\site-packages\\qrcode\\util.py'>, 're': <module 're' from 'D:\\Python37\\lib\\re.py'>, 'enum': <module 'enum' from 'D:\\Python37\\lib\\enum.py'>, 'types': <module 'types' from 'D:\\Python37\\lib\\types.py'>, '_collections': <module '_collections' (built-in)>, 'sre_compile': <module 'sre_compile' from 'D:\\Python37\\lib\\sre_compile.py'>, '_sre': <module '_sre' (built-in)>, 'sre_parse': <module 'sre_parse' from 'D:\\Python37\\lib\\sre_parse.py'>, 'sre_constants': <module 'sre_constants' from 'D:\\Python37\\lib\\sre_constants.py'>, 'functools': <module 'functools' from 'D:\\Python37\\lib\\functools.py'>, '_functools': <module '_functools' (built-in)>, 'collections': <module 'collections' from 'D:\\Python37\\lib\\collections\\__init__.py'>, 'operator': <module 'operator' from 'D:\\Python37\\lib\\operator.py'>, '_operator': <module '_operator' (built-in)>, 'keyword': <module 'keyword' from 'D:\\Python37\\lib\\keyword.py'>, 'heapq': <module 'heapq' from 'D:\\Python37\\lib\\heapq.py'>, '_heapq': <module '_heapq' (built-in)>, 'itertools': <module 'itertools' (built-in)>, 'reprlib': <module 'reprlib' from 'D:\\Python37\\lib\\reprlib.py'>, 'copyreg': <module 'copyreg' from 'D:\\Python37\\lib\\copyreg.py'>, 'math': <module 'math' (built-in)>, 'six': <module 'six' from 'D:\\Python37\\lib\\site-packages\\six.py'>, '__future__': <module '__future__' from 'D:\\Python37\\lib\\__future__.py'>, 'struct': <module 'struct' from 'D:\\Python37\\lib\\struct.py'>, '_struct': <module '_struct' (built-in)>, 'six.moves': <module 'six.moves' (<six._SixMetaPathImporter object at 0x0000000002956390>)>, 'qrcode.base': <module 'qrcode.base' from 'D:\\Python37\\lib\\site-packages\\qrcode\\base.py'>, 'qrcode.LUT': <module 'qrcode.LUT' from 'D:\\Python37\\lib\\site-packages\\qrcode\\LUT.py'>, 'qrcode.image': <module 'qrcode.image' from 'D:\\Python37\\lib\\site-packages\\qrcode\\image\\__init__.py'>, 'qrcode.image.base': <module 'qrcode.image.base' from 'D:\\Python37\\lib\\site-packages\\qrcode\\image\\base.py'>, 'bisect': <module 'bisect' from 'D:\\Python37\\lib\\bisect.py'>, '_bisect': <module '_bisect' (built-in)>, 'threading': <module 'threading' from 'D:\\Python37\\lib\\threading.py'>, 'time': <module 'time' (built-in)>, 'traceback': <module 'traceback' from 'D:\\Python37\\lib\\traceback.py'>, 'linecache': <module 'linecache' from 'D:\\Python37\\lib\\linecache.py'>, 'tokenize': <module 'tokenize' from 'D:\\Python37\\lib\\tokenize.py'>, 'token': <module 'token' from 'D:\\Python37\\lib\\token.py'>, '_weakrefset': <module '_weakrefset' from 'D:\\Python37\\lib\\_weakrefset.py'>} <module 'threading' from 'D:\\Python37\\lib\\threading.py'> <module 'qrcode' from 'D:\\Python37\\lib\\site-packages\\qrcode\\__init__.py'> exp: import sys print('Please enter your name:') name=sys.stdin.readline()[:-1] print('Hi, %s!' %name) 执行结果: Please enter your name: felix Hi, felix!
十、序列化模块
1.何为序列化?反序列化?
网络传输或数据存储的时候需要将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
将字符串转换为数据类型的过程就叫反序列化。

使用json模块可序列化的数据类型:数字、字符串、列表、字典、元组(实际为列表)
通用的序列化格式,只有很少一部分数据类型能够通过json转化成字符串
(1)json和内存相关的操作
a.序列化方法 json.dumps()
b.反序列化方法 json.loads()
import json
dic = {'k1': 'v1', 'k2': 'v2'}
print(type(dic), dic)
# 序列化过程
str_d = json.dumps(dic)
print(type(str_d), str_d)
# 反序列化过程
dic_d = json.loads(str_d)
print(type(dic_d), dic_d)
执行结果:
<class 'dict'> {'k1': 'v1', 'k2': 'v2'}
<class 'str'> {"k1": "v1", "k2": "v2"}
<class 'dict'> {'k1': 'v1', 'k2': 'v2'}
(2)json和文件相关的操作
a.序列化过程
json.dump(数据,文件句柄 [,ensure_ascii=False])
b.反序列化过程
json.load(文件句柄)
实例:
import json
#序列化过程
dic = {'name': '姓名', 'k2': 'v2'}
f = open('json模块', 'w', encoding='utf-8')
json.dump(dic, f,ensure_ascii=True) #ensure_ascii参数默认为False,为True时以bytes类型显示
f.close()
#反序列化过程
f = open('json模块', 'r')
res = json.load(f)
f.close()
print(type(res), res)
执行结果:
<class 'dict'> {'name': '姓名', 'k2': 'v2'}
文件中存储的数据为:
{"name": "\u59d3\u540d", "k2": "v2"}
注意:
- 把转换后的数据写入文件时json.dump(dic, f,ensure_ascii=True) ensure_ascii默认为True时,如果数据内容为中文,打开文件会看到中文以bytes类型显示,ensure_ascii=False时,打开文件时就会以中文显示
- json可以分步进行dump,但是不能分步load,只能一次性load
执行上例序列化过程3次;再反序列化,就会报错,如下图。


那么怎么解决这个问题?
可以用for循环解决,分次序列化和反序列化。
#序列化过程 import json l = [{'k': '111'}, {'k2': '111'}, {'k3': '111'}] f = open('json模块', 'w') for dic in l: str_dic = json.dumps(dic) f.write(str_dic + '\n') f.close() #反序列化过程 import json f = open('json模块') l = [] for line in f: dic = json.loads(line.strip()) l.append(dic) print(dic) f.close() print(l)
pickle模块方法和json相同,但是pickle模块可序列化Python中任何数据类型,但是在使用中要注意以下几点
注意:
- pickle模块序列化(dumps)后为二进制内容
- 可以分步dump和分步load ,因为写入文件和读取文件都是以bytes类型
- 进行文件操作时,读取和写入都要加 b
import pickle
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) # 一串二进制内容
dic2 = pickle.loads(str_dic)
print(dic2) # 字典
执行结果:
b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01X\x02\x00\x00\x00v1q\x02X\x02\x00\x00\x00k2q\x03X\x02\x00\x00\x00v2q\x04X\x02\x00\x00\x00k3q\x05X\x02\x00\x00\x00v3q\x06u.'
{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
import pickle,time
struct_time = time.localtime(time.time())
print(struct_time)
f = open('pickle_file', 'wb')
pickle.dump(struct_time, f)
f.close()
f = open('pickle_file', 'rb')
struct_time2 = pickle.load(f)
print(struct_time)
print('{}-{}-{}'.format(struct_time.tm_year,struct_time.tm_mon,struct_time.tm_mday))
执行结果:
time.struct_time(tm_year=2018, tm_mon=11, tm_mday=25, tm_hour=20, tm_min=34, tm_sec=3, tm_wday=6, tm_yday=329, tm_isdst=0)
time.struct_time(tm_year=2018, tm_mon=11, tm_mday=25, tm_hour=20, tm_min=34, tm_sec=3, tm_wday=6, tm_yday=329, tm_isdst=0)
2018-11-25
shleve模块序列化和反序列化类似于文件操作和字典操作
# 序列化 import shelve f = shelve.open('shelve_file') # f['key'] = {'int': 10, 'float': 9.5, 'string': 'Sample data'} # 直接对文件句柄操作,就可以存入数据 f['key'] = [123,321,111] f.close() # 反序列化 f1 = shelve.open('shelve_file') existing = f1['key'] # 取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错 f1.close() print(existing) 执行结果: [123, 321, 111]
注意:writeback参数默认为False,即不保存所做的修改,writeback = True时,即可以保存所做的修改
#没有加writeback参数 import shelve f1 = shelve.open('shelve_file') print(f1['key']) f1['key']['new_value'] = 'this was not here before' print(f1['key']) f1.close() #执行结果: {'int': 10, 'float': 9.5, 'string': 'Sample data'} {'int': 10, 'float': 9.5, 'string': 'Sample data'} #加writeback参数 f2 = shelve.open('shelve_file', writeback=True) print(f2['key']) f2['key']['new_value'] = 'this was not here before' print(f2['key']) f2.close() 执行结果: {'int': 10, 'float': 9.5, 'string': 'Sample data'} {'int': 10, 'float': 9.5, 'string': 'Sample data', 'new_value': 'this was not here before'}
十一、hashlib模块
1.摘要算法说明
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
2.特点:
(1)不管算法多么不同,摘要的功能始终不变
(2)对于相同的字符串使用同一种算法进行摘要,得到的值总是不变的
3.摘要算法用途
(1)用于密码的密文存储
(2)文件的一致性验证:检验本地文件和远程或其他服务器上的文件是否一致
import hashlib # 提供摘要算法的模块 password_md5 = hashlib.md5() #设定算法为md5 password_md5.update(b'123456') #对字符串进行md5算法,字符串必须为bytes类型 #password_md5.update(bytes('123456',encoding='utf-8')) print(password_md5.hexdigest()) #对加密后的结果转换为16进制 执行结果: e10adc3949ba59abbe56e057f20f883e
import hashlib # 提供摘要算法的模块 password_md5 = hashlib.sha3_512() # 设定算法为md5 password_md5.update(b'123456') # 对字符串进行md5算法,字符串必须为bytes类型 # password_md5.update(bytes('123456',encoding='utf-8')) print(password_md5.hexdigest()) # 对加密后的结果转换为16进制
小结:越复杂的算法,加密后的结果长度越长; 随着算法复杂程度的增加,摘要的时间成本、空间成本都会增加。
# 用户的登录 import hashlib usr = input('username :') pwd = input('password : ') with open('userinfo') as f: for line in f: user, passwd, role = line.split('|') md5 = hashlib.md5() md5.update(bytes(pwd, encoding='utf-8')) md5_pwd = md5.hexdigest() if usr == user and md5_pwd == passwd: print('登录成功')
import hashlib md5 = hashlib.md5() md5.update(b'123') # 先对 123 加密 md5.update(b'456') # 再对 456 加密 print(md5.hexdigest()) 执行结果: e10adc3949ba59abbe56e057f20f883e #等价于直接对123456加密
4.防止被'破解'---撞库,加密时进行加盐
# 加盐 import hashlib # 提供摘要算法的模块 md5 = hashlib.md5(bytes('盐', encoding='utf-8')) # md5 = hashlib.md5() md5.update(b'123456') print(md5.hexdigest()) 执行结果: 970d52d48082f3fb0c59d5611d25ec1e
十二、configparser模块(配置文件模块)
该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。

如何用python生产以上格式配置文件?configparser模块
import configparser config = configparser.ConfigParser() config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9', 'ForwardX11':'yes' } config['bitbucket.org'] = {'User':'hg'} config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'} with open('example.ini', 'w') as configfile: config.write(configfile) 执行结果:生成以下内容配置文件(后缀名为.ini) [DEFAULT] serveraliveinterval = 45 compression = yes compressionlevel = 9 forwardx11 = yes [bitbucket.org] user = hg [topsecret.server.com] host port = 50022 forwardx11 = no

如何查找配置文件中的参数呢?
import configparser config = configparser.ConfigParser() config.read('example.ini') print(config.sections()) # ['bitbucket.org', 'topsecret.server.com'] print('bytebong.com' in config) # False print('bitbucket.org' in config) # True print(config['bitbucket.org']["user"]) # hg print(config['DEFAULT']['Compression']) #yes print(config['topsecret.server.com']['ForwardX11']) #no print(config['bitbucket.org']) #<Section: bitbucket.org> for key in config['bitbucket.org']: # 注意,有default会默认default的键 print(key) 执行结果: user serveraliveinterval compression compressionlevel forwardx11 print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键 执行结果: ['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11'] print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对 执行结果: [('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')] print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
增删改操作
import configparser config = configparser.ConfigParser() config.read('example.ini') config.add_section('yuan') config.remove_section('bitbucket.org') config.remove_option('topsecret.server.com',"forwardx11") config.set('topsecret.server.com','k1','11111') config.set('yuan','k2','22222') config.write(open('new2.ini', "w"))
十三、logging模块
logging模块
5中日志级别:
logging.debug('debug message') # 低级别的 # 排错信息
logging.info('info message') # 正常信息
logging.warning('warning message') # 警告信息
logging.error('error message') # 错误信息
logging.critical('critical message') # 高级别的 # 严重错误信息
两种配置方式:
1.basicconfig
2.log对象
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING
(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='/tmp/test.log',
filemode='w')
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
logger对象配置
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log',encoding='utf-8')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,
Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过
fh.setLevel(logging.Debug)单对文件流设置某个级别。
