MySQL 的开窗函数
开窗函数 (Window Function)提供了行集之间的计算能力,在现代的主流关系型数据库中,基本都提供了相似的功能,这些功能在一些业务开发的过程中很有用,本文将简要介绍这些常用的开窗函数
ROW_NUMBER()
ROW_NUMBER() 函数的使用语法如下:
ROW_NUMBER() OVER ([partition_definition] [order_definition])
其中,partition_definition 按照如下的语法,定义执行分组的列:
PARTITION BY <expression>,[{,<expression>}...]
而 order_definition 则表示分组后相应的排序规则,具体的语法如下:
ORDER BY <expression> [ASC|DESC],[{,<expression>}...]
这个是一个比较常用的开窗函数,一般在某些需要查询最新的数据的业务场景下时使用。
假设我们有如下的表结构:
CREATE TABLE course_info
(
course_id INT NOT NULL
PRIMARY KEY,
course_name VARCHAR(32) NULL, -- 课程名称
course_type INT NULL, -- 课程类型(主科、副科)
update_time DATETIME NULL -- 该条记录的最近一次更新时间
)
以及如下数据:
| course_id | course_name | course_type | update_time |
|---|---|---|---|
| 1 | 语文 | 1 | 2023-08-10 21:09:26 |
| 2 | 数学 | 1 | 2023-08-10 21:09:28 |
| 3 | 英语 | 1 | 2023-08-10 21:09:28 |
| 4 | 政治 | 2 | 2023-08-10 21:09:27 |
| 5 | 历史 | 2 | 2023-08-10 21:09:29 |
| 6 | 地理 | 2 | 2023-08-10 21:09:29 |
现在我们需要查询每种类型的最新的课程信息,如果不使用开窗函数,那么我们将不得不按照课程类型进行分组,然后执行一次关联查询以匹配最新的更新时间:
SELECT ci.*
FROM course_info ci
JOIN (SELECT course_type, MAX(update_time) AS update_time
FROM course_info
GROUP BY course_type) AS tmp
ON ci.course_type = tmp.course_type
AND ci.update_time = tmp.update_time
然而,如果使用 ROW_NUMBER(),我们只需要按照 course_type 进行分组,按照更新时间降序,然后取行号为 \(1\) 的即可:
SELECT *
FROM (SELECT *,
ROW_NUMBER() OVER (PARTITION BY course_type ORDER BY update_time DESC) AS rn
FROM course_info) AS tmp
WHERE rn = 1
二者的查询结果如下所示:
| course_id | course_name | course_type | update_time | rn |
|---|---|---|---|---|
| 2 | 数学 | 1 | 2023-08-10 21:09:28 | 1 |
| 5 | 历史 | 2 | 2023-08-10 21:09:29 | 1 |
这么一看似乎 ROW_NUMBER() 函数没有什么优势,然而,如果相关的需求变为:"查询每个类型的最新课程信息,对于类型相同的行,按照 id 降序取第一条数据"。在这种情况下,第一种方式就显得有些乏力了,而如果使用 ROW_NUMBER() 函数,我们只需要在 ORDER BY 后加上对应的排序规则即可简单的完成这一需求:
SELECT *
FROM (SELECT *,
ROW_NUMBER() OVER (PARTITION BY course_type ORDER BY update_time DESC, course_id DESC) AS rn
FROM course_info) AS tmp
WHERE rn = 1;
查询结果如下:
| course_id | course_name | course_type | update_time | rn |
|---|---|---|---|---|
| 3 | 英语 | 1 | 2023-08-10 21:09:28 | 1 |
| 6 | 地理 | 2 | 2023-08-10 21:09:29 | 1 |
需要注意的是,ROW_NUMBER() 函数的作用是为了给每个子集中的记录添加对应的行号,当无法通过排序字段来明显区分行号的优先级时,会按照原有查询的结果顺序依次为子集的每一行设置递增的行号
DENSE_RANK()
DENSE_RANK() 函数和 ROW_NUMBER() 函数十分类似,区别在于对于无法通过排序字段区分的记录行,它们的行号将会是一致的
DENSE_RANK() 函数的语法如下:
RANK() OVER (
PARTITION BY <expression>[{,<expression>...}]
ORDER BY <expression> [ASC|DESC], [{,<expression>...}]
)
这里的 PARTITION BY 和 ORDER BY 的语法和 ROW_NUMBER() 一致,在此不做过多赘述
这个函数的一个常见的处理业务就是查询所有排名第 \(n\) 的记录行,比如,现在有如下的表结构:
CREATE TABLE IF NOT EXISTS student_info (
id INT PRIMARY KEY NOT NULL ,
name VARCHAR(32) NOT NULL , -- 姓名
gender VARCHAR(6) NOT NULL , -- 性别
grade DECIMAL NOT NULL -- 成绩
)
以及如下数据:
| id | name | gender | grade |
|---|---|---|---|
| 1 | Jerry | Female | 81 |
| 2 | Tom | Female | 86 |
| 3 | Jackson | Female | 60 |
| 4 | Richard | Female | 81 |
| 5 | Knuth | Male | 86 |
| 6 | Marry | Male | 91 |
| 7 | Thompson | Male | 86 |
| 8 | Berry | Male | 91 |
现在我们希望查询成绩 grade 排名第二的学生姓名,如果不使用 DENSE_RANK() 函数,那么可以使用如下的关联查询进行处理:
SELECT si.name,
si.grade
FROM student_info si
WHERE EXISTS(SELECT 1
FROM (SELECT grade
FROM student_info si
GROUP BY grade
ORDER BY grade DESC
LIMIT 1 OFFSET 1) AS tmp
WHERE tmp.grade = si.grade)
然而,如果使用 DENSE_RANK() 函数的话,只需要按照对每个记录行按照分数分配行号再进行过滤即可:
SELECT tmp.name,
tmp.grade
FROM (
SELECT *,
DENSE_RANK() OVER (ORDER BY grade DESC) AS rk
FROM student_info si
) AS tmp
WHERE rk=2
二者的查询结果如下:
| name | grade |
|---|---|
| Tom | 86 |
| Knuth | 86 |
| Thompson | 86 |
这在一定程度上简化了 SQL 语句,同时也能够减少由于需求变更带来的代码改动,如果有一天需要按照性别分别取两者之间分数排名第二的学生姓名,对于第一种方式来讲,将作出更多的改动,而使用 DENSE_RANK() 函数,只需要额外加上 PARTITION BY 语句进行不同子集的划分即可,如下所示:
SELECT
tmp.name,
tmp.grade
FROM (
SELECT *,
DENSE_RANK() OVER (PARTITION BY gender ORDER BY grade DESC) AS rk
FROM student_info si
) AS tmp
WHERE rk=2 AND gender='Female'
对应的查询结果如下:
| name | grade |
|---|---|
| Jerry | 81 |
| Richard | 81 |
RANK()
RANK() 函数和 DENSE_RANK() 函数十分类似,区别在于 RANK() 函数会对排名相同的记录加上对应的间隙数量。以上文 DENSE_RANK() 的数据为例,通过 RANK() 函数对分数进行排名:
SELECT *,
RANK() OVER (ORDER BY grade DESC) AS rk
FROM student_info si
ORDER BY rk
对应的结果如下:
| id | name | gender | grade | rk |
|---|---|---|---|---|
| 6 | Marry | Male | 91 | 1 |
| 8 | Berry | Male | 91 | 1 |
| 2 | Tom | Female | 86 | 3 |
| 5 | Knuth | Male | 86 | 3 |
| 7 | Thompson | Male | 86 | 3 |
| 1 | Jerry | Female | 81 | 6 |
| 4 | Richard | Female | 81 | 6 |
| 3 | Jackson | Female | 60 | 8 |
可以看到,RANK() 对分数的排名会加上原有记录的间隙值,这种作用一般用于查询前 \(n\) 的相关业务,比如,如果只是希望查询分数最高的两个学生信息,可以这么做:
SELECT *
FROM (
SELECT *,
RANK() OVER (ORDER BY grade DESC) AS rk
FROM student_info si
) AS tmp
WHERE rk <= 2
ORDER BY rk
PERCENT_RANK()
PERCENT_RANK() 的目的是为了提供一个子集中百分比的排序函数,这个函数的返回值范围应当是 $0 \leq val \leq 1 $。
该函数的语法与 ROW_NUMBER() 一致,在此不做赘述
假设现在创建了如下数据库表,用于记录每个卖家在每月的销售额:
CREATE TABLE IF NOT EXISTS sale_info (
id INT PRIMARY KEY NOT NULL ,
sale_id INT NOT NULL , -- 卖家 id
amount INT NOT NULL , -- 卖家在当月的销售量
year DATE NOT NULL -- 当前的销售月份
)
相关的数据如下:
| id | sale_id | amount | year |
|---|---|---|---|
| 1 | 1 | 60 | 2023-01-01 |
| 2 | 1 | 200 | 2023-02-01 |
| 3 | 1 | 300 | 2023-03-01 |
| 4 | 2 | 100 | 2023-01-01 |
| 5 | 2 | 100 | 2023-02-01 |
| 6 | 2 | 50 | 2023-03-01 |
| 7 | 3 | 50 | 2023-01-01 |
| 8 | 3 | 500 | 2023-02-01 |
| 9 | 3 | 120 | 2023-03-01 |
| 10 | 4 | 110 | 2023-01-01 |
| 11 | 5 | 70 | 2023-01-01 |
现在希望查询在 "2023-01-01" 中销售额比例最大的卖家 id,使用 PERCENT_RANK() 可以执行如下查询:
SELECT year,
sale_id,
amount,
ROUND(PERCENT_RANK() OVER (PARTITION BY year ORDER BY amount DESC), 2) AS percent
FROM sale_info
WHERE year = DATE('2023-01-01')
ORDER BY percent
LIMIT 1
对应的执行结果如下:
| year | sale_id | amount | percent |
|---|---|---|---|
| 2023-01-01 | 4 | 110 | 1 |
如果使用传统分组的方式,则会显得比较麻烦:
SELECT si.*,
si.amount / tmp.sum_amount AS percent
FROM sale_info si
JOIN (SELECT year,
SUM(amount) AS sum_amount
FROM sale_info
GROUP BY year) AS tmp ON si.year=tmp.year
WHERE si.year='2023-01-01'
ORDER BY percent DESC
LIMIT 1
并且后续如果需要进一步分组,或者需要改变该占比的计算规则,第二种方式则会显得更加痛苦
CUME_DIST()
CUME_DIST() 的目的是为了统计某些记录行在某个自己中出现的比例,比如,要查询分数为 \(n\) 的行数在 ”男生“ 中所占的比例,在这种情况下就可以使用 CUME_DIST() 来降低 SQL 的编写难度。
CUME_DIST() 的语法和 ROW_NUMBER() 一致
以上文的学生成绩数据为例,如果希望查询分数为 \(86\) 在所有男生中所占的比例,可以执行如下的 SQL:
SELECT si.grade,
si.cume
FROM (SELECT *,
CUME_DIST() OVER (PARTITION BY gender ORDER BY grade) AS cume
FROM student_info si) AS si
WHERE si.gender = 'Male'
AND si.grade = 86
LIMIT 1
对应的查询结果如下:
| grade | cume |
|---|---|
| 86 | 0.5 |
即,在所有的男生中,分数为 \(86\) 的人数占到总人数的 \(50\%\)
NTILE()
NTILE() 函数的目的是为了将一个子集(窗口)记录尽可能地划分成为 num_buckets 个桶,同时返回每个记录行所在的桶编号。
NTILE() 的语法如下所示:
NTILE(num_buckets) OVER ([partition_definition] [order_definition])
其中 num_buckets 表示需要划分的桶的个数,partition_definition 和 order_definition 与 ROW_NUMBER() 函数一致
以上文 PERCENT_RANK() 中销售额数据表的数据为例,如果希望将 2023-01-01 的销售额降序放入到每个桶中,可以像下面这样做:
SELECT *
FROM (
SELECT si.*,
NTILE(2) OVER (PARTITION BY si.year ORDER BY amount DESC) AS bucket
FROM sale_info si
) AS tmp
WHERE tmp.year='2023-01-01'
对应的查询结果如下:
| id | sale_id | amount | year | bucket |
|---|---|---|---|---|
| 10 | 4 | 110 | 2023-01-01 | 1 |
| 4 | 2 | 100 | 2023-01-01 | 1 |
| 11 | 5 | 70 | 2023-01-01 | 1 |
| 1 | 1 | 60 | 2023-01-01 | 2 |
| 7 | 3 | 50 | 2023-01-01 | 2 |
LAG()
LAG() 函数的作用是返回子集中每一行记录的前置行数据,这个函数与 LEAD() 函数在某些情况下可能会很有效
LAG() 函数的语法如下:
LAG(expr[, offset[, default]])
OVER (
[partition_definition] [order_definition]
)
其中,expr 表示需要获取数据的列名或者表达式,这个参数是必需的;offset 表示距离子集中上一条记录的偏移量,即要获取子集中的前第 \(offset\) 行的数据,默认为 \(1\);default 表示如果无法获取到有效值时,默认显示的数据(默认为 NULL)
partition_definition 和 partition_definition 与 ROW_NUMBER() 函数一致
在某些需要递归查询的业务中会很有效,比如,现在有一个流程申请信息记录表:
CREATE TABLE IF NOT EXISTS apply_info (
id INT PRIMARY KEY NOT NULL ,
name VARCHAR(127) NOT NULL , -- 本次发起申请名称
apply_type VARCHAR(7) NOT NULL , -- 本次发起的申请的所属类型
business_key VARCHAR(32), -- 本次发起的申请的关联业务主键
create_time DATETIME NULL -- 该条记录的创建时间
);
其中数据如下:
| id | name | apply_type | business_key | create_time |
|---|---|---|---|---|
| 1 | 本息分配申请—1 | 0101 | APPLY000000001 | 2022-08-13 17:02:51 |
| 2 | 本息分配申请—2 | 0101 | APPLY000000002 | 2022-10-13 18:02:56 |
| 3 | 本息分配申请—3 | 0101 | APPLY000000003 | 2023-06-13 17:02:51 |
| 4 | 数据采集—1 | 0102 | APPLY000000004 | 2022-11-13 16:03:29 |
| 5 | 数据采集—2 | 0102 | APPLY000000005 | 2023-01-12 12:01:31 |
| 6 | 数据采集—3 | 0102 | APPLY000000006 | 2023-08-07 16:03:29 |
如果希望查询申请类型为 0101 的申请记录的历史列表,可以执行如下的查询:
SELECT ai.id,
ai.name,
ai.create_time,
LAG(id) OVER (PARTITION BY apply_type ORDER BY create_time) AS parent_id
FROM apply_info ai
WHERE ai.apply_type='0101'
对应的查询结果如下:
| id | name | create_time | parent_id |
|---|---|---|---|
| 1 | 本息分配申请—1 | 2022-08-13 17:02:51 | null |
| 2 | 本息分配申请—2 | 2022-10-13 18:02:56 | 1 |
| 3 | 本息分配申请—3 | 2023-06-13 17:02:51 | 2 |
这样便能很方便地得到申请的一部分历史明细
LEAD()
LEAD() 函数和 LAG() 函数十分类似,区别在于 LEAD() 函数是获取子集中每个指定偏移量之后的数据,以 LAG() 的数据集为例,同样可以使用 LEAD() 来完成这一工作,只是最终的结果会是倒序排列的:
SELECT ai.id,
ai.name,
ai.create_time,
LEAD(id) OVER (PARTITION BY apply_type ORDER BY create_time DESC) AS lead_rk
FROM apply_info ai
WHERE ai.apply_type='0101'
对应的查询结果如下:
| id | name | create_time | lead_rk |
|---|---|---|---|
| 3 | 本息分配申请—3 | 2023-06-13 17:02:51 | 2 |
| 2 | 本息分配申请—2 | 2022-10-13 18:02:56 | 1 |
| 1 | 本息分配申请—1 | 2022-08-13 17:02:51 | null |
FIRST_VALUE()
FIRST_VALUE() 函数的作用是返回子集中第一行的指定列数据,该函数的语法如下:
FIRST_VALUE(expr)
OVER (
[partition_definition] [order_definition] [frame_clause]
)
其中,expr 为要获取数据的列明或者表达式,partition_definition 和 partition_definition 与 ROW_NUMBER() 函数一致;
frame_clause 的语法如下:
frame_unit {<frame_start>|<frame_between>}
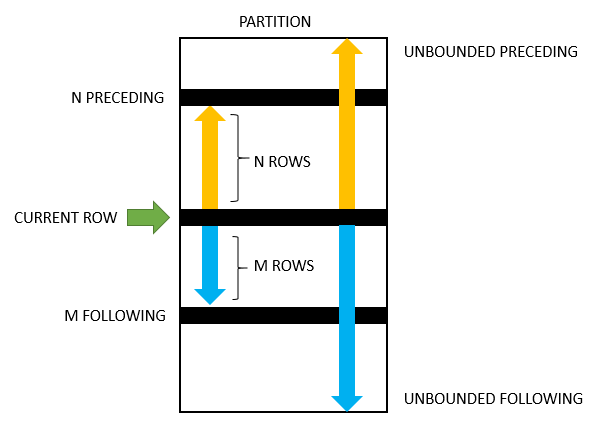
frame 是当前划分的子集中的又一个子集,为了重定义这个子集,便需要使用到 frame_clause,其中,frame_unit 用于指定当前行和 frame 行之间的关系,有以下几个选项:
ROWS:表示当前行和frame行之间的偏移量是行号之间的差异RANGE:表示当前行和frame行之间的偏移量是行值与当前行值之间的差异
frame_start 和 frame_between 用于定义 frame 的区间范围:
如果是使用 frame_start 的语法,那么可以使用如下的语句:
UNBOUNDED PRECEDING:表示frame的开始区间为该分区的第一行数据N PRECEDING:距离分区第一行的偏移量,其中,\(N\) 表示当前分区第一行的前 \(N\) 行,\(N\) 可以是数字也可以是表达式CURRENT ROW:对于以ROWS为frame_unit的情况,开始区间为当前行;如果为RANGE,则为当前行的对等点
对于 frame_between,需要遵循如下的语法:
BETWEEN frame_boundary_1 AND frame_boundary_2
其中,frame_boundary_1 和 frame_boundary_2 可以为以下几个之一:
frame_start:与frame_start描述的一致UNBOUNDED FOLLOWING:当前分区的最后一行N FOLLOWING:当前行之后的第 \(N\) 行
如果不指定 frame_clause 的话,MySQL 会默认执行以下的 frame_clause:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
关于 frame_clause 的边界情况如下图所示:
以上文中的 student_info 数据集为例,如果希望分别查询 Male 和 Female 中的最高分数,可以执行如下的查询:
SELECT
DISTINCT
si.gender,
FIRST_VALUE(si.grade) OVER (PARTITION BY gender ORDER BY grade DESC) AS higher_grade
FROM student_info si
对应的查询结果如下:
| gender | higher_grade |
|---|---|
| Female | 86 |
| Male | 91 |
LAST_VALUE()
LAST_VALUE() 和 FIRST_VALUE() 十分类似,区别在于 LAST_VALUE() 返回的是子集中的最后一条数据的指定列数据
以 FISRT_VALUE() 中用到的数据为例,如果我们希望分别查询 Male 和 Female 中的最低分,可以执行如下的查询:
SELECT DISTINCT si.gender,
LAST_VALUE(si.grade) OVER (PARTITION BY gender ORDER BY grade DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS lower_grade
FROM student_info si
NTH_VALUE()
NTH_VALUE() 的作用是获取指定 frame 中的第 \(N\) 个记录行的指定数据,对应的函数语法如下所示:
NTH_VALUE(expr, N)
OVER (
[partition_definition] [order_definition] [frame_clause]
)
依旧以上文的 student_info 的数据集为例,如果希望获取性别为 Female 中,排名第二的分数,可以执行如下的查询:
SELECT DISTINCT si.gender,
NTH_VALUE(si.grade, 2) OVER (PARTITION BY gender ORDER BY grade DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS lower_grade
FROM student_info si
WHERE si.gender='Female'
参考:
[1] https://www.mysqltutorial.org/mysql-window-functions/
[2] https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号