Http 编码格式简介
Http 格式简介
Http 是用于在客户端和服务端之间进行通信的一种消息格式,一般由以下几个部分组成:
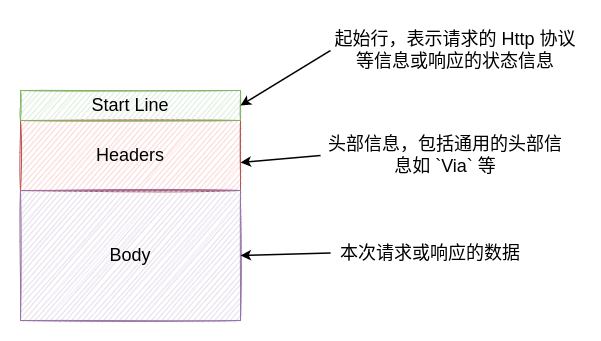
-
起始行:这部分在 Http 响应中也被称为状态行,针对不同的 Http 类型,其中包含的内容也不一致
request总共包括三个元素:Http 请求方式、请求目标和 Http 版本- Http 请求方式:即本次请求的需要执行的动作,如:
GET、POST、PUT等 - 请求目标:即需要到将请求发送到 “何处”,这里可以是一个绝对路径,或者是一个 URL
- Http 版本:定义当前 Http 请求的协议版本,如 Http/1.1、Http/2 等
- Http 请求方式:即本次请求的需要执行的动作,如:
response的起始行同样包括三个元素:协议版本、状态码和状态文本- 协议版本:及当前 Http 的版本,如 Http/1.1
- 状态码:表示对之前请求的处理情况,如 404 表示请求的 URL 不存在,具体的状态码可以查看 Http 响应码
- 状态文本:用于帮助理解响应的文本信息
-
头部信息:一些关于本次 Http 消息的附加消息,如:本次消息体数据的编码格式、消息体数据的长度等。具体的结构是通过 ":" 分隔的不区分大小写的格式,最终这些头部信息将会组成一行
一般存在以下几种头部信息:
- 通用头部信息:适用于整个 Http 消息的头部信息
- 请求头信息:如:
user-agent表示是何处发出的请求、accept-language等 - 响应头信息:提供有关服务器响应的相关信息,如:
accept-range等 - 表现层头信息:描述消息数据的原始格式和应用编码等信息,如
content-type等
-
数据主体(Body):这一部分表示本次请求或响应带有的实际数据,针对请求和响应,这部分内容也不一致:
- 请求的数据主体:一般只有使用
POST方式请求时才会带有这部分的数据,
- 请求的数据主体:一般只有使用
Http 编码
头部信息的编码
按照 规范 ,头部的字符应当都是 ASCII 格式的字符串,对于非 ASCII 格式的字符,需要转换成为 % + "对应字符编码的十六进制" 的形式
比如说,如果需要下载一个包含中文名的文件(如 “数据导出.xlsx”),那么在对应的响应头部信息中关于这个文件的描述应该转换成为如下的形式:
Content-Disposition: attachment; filename=%E6%95%B0%E6%8D%AE%E5%AF%BC%E5%87%BA.xlsx
请求和响应数据主体的编码
按照规范,如果没有在头部信息指定编码的格式,如 Content-Type:application/json;charset=utf8 中的 charset 即为指定的数据主体的编码格式,如果没有指在头部指定这个编码,那么默认将会使用 ISO-8859-1 作为数据主体的编码格式,具体可以参见:Http 1.1 规范 3.7.1
特别地,如果是使用 Servlet 容器处理请求时,针对 XML 格式的响应默认会使用 UTF-8 编码格式
GET 请求的默认编码
GET 请求一般不会携带数据体部分,因此主要的处理就是请求的 URL 的编码处理(特别是请求参数的编码),这部分编码整个 URL 的字符都使用 US-ASCII 字符,对于不是 ASCII 字符的参数,要求在发送请求时自动将这个字符转换成 % + “字符的十六进制编码” 的格式,一般我们在浏览器内输入带有中文参数的 URL 时,浏览器都会自动将其进行转码的处理,因此该请求能被正常处理
对于 “字符的十六进制编码”,由于现有的大部分应用都推荐使用 UTF-8 作为默认的编码格式,因此直接将字符转为对应的 UTF-8 编码的二进制并转换为对应的十六进制在大部分的应用上都是可行的。另外,由于 ISO--8859-1 和 ASCII 编码的 0x20 到 0x7e 一致,因此它们经常互换使用
POST 请求的默认编码
对于请求的 URL 部分编码和 GET 的编码格式一致,但由于一般 POST 请求会携带一个数据主体部分,因此这部分的编码需要特殊指定,一般会在请求的头部信息 Content-Type 中指定数据体的编码格式
如果没有在 Content-Type 中指定编码格式,那么服务端应当按照 ISO-8859-1 的编码格式对数据体参数进行编码处理。但是这种情况有个例外,就是当 POST 请求的类型为 application/x-www-form-urlencoded(即表单提交)的情况下,服务端应当按照 US-ASCII 的格式对数据体部分进行对应的编码处理
Tomcat 对编码格式的处理
针对 GET 请求的编码处理
按照前文提到的规范,如果没有指定对 URL 的编码,那么将默认使用 ISO-8859-1 的编码格式对 URL 进行解码(包括请求参数等 '%' 后接着的部分),对于 Tomcat 服务器来讲,可以在对应的 server.xml 配置文件中配置 URLEncoding 来指定对应的 URL 编码格式,如下所示:
<Connector port="8090" URIEncoding="UTF-8"/>
对于 Spring Boot 的项目来讲,由于它已经默认内嵌了 Tomcat 作为默认的 web 服务器,并且默认 URL 的编码格式为 UTF-8,如果希望改变对应的编码格式,可以在 application.yml 配置文件中做如下的配置:
server:
tomcat:
uri-encoding: UTF-8 # 设置 Tomcat 的 URL 编码格式为 UTF-8
针对 POST 请求的编码处理
对于 POST 请求来讲,与 GET 请求的最大区别在于它一般会包含一个数据主体部分,其余部分的编码处理和 GET 请求一致。对于数据主体部分的编码,一般由发送请求的客户端在头部信息中指定编码格式。如果发送请求的客户端没有指定编码格式,那么将会默认使用 US-ASCII 的格式处理数据主体的内容
除此之外,Servlet 规范要求将 application/x-www-form-urlencoded 的 % 编码格式在默认情况下需要转换为 ISO-8859-1 的格式,这与现代的浏览器默认使用 UTF-8 的编码格式不兼容。然而,Servlet 规范要求 Servlet 容器对于 application/x-www-form-urlencoded 编码格式的 % 序列能够转换为任意配置的编码格式,因此,可以通过将请求字符编码设置为 UTF-8 格式来实现对 x-www-form-urlencoded 格式的编码处理,为了达到这一目的,可以通过添加对应的 Filter 来实现将数据主体的 % 编码转换为对应的 UTF-8 编码的字符:
import org.springframework.stereotype.Component;
import javax.servlet.*;
import java.io.IOException;
/**
* @author lxh
*/
@Component
public class BodyCharsetFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
request.setCharacterEncoding("UTF-8"); // 设置数据主体的编码格式为 UTF-8(针对 x-www-form-urlencoded 默认格式)
chain.doFilter(request, response); // 过滤链的后续处理
}
}
参考:
[1] https://cwiki.apache.org/confluence/display/TOMCAT/Character+Encoding

 浙公网安备 33010602011771号
浙公网安备 33010602011771号