Unix IPC
本文主要是摘抄 APUE 中 IPC 部分的内容
IPC(Inter Process Communication)进程间通信,是指在进程之间进行通信的一种方式,本文将简要介绍一下在 Unix 中存在的一些 IPC 方式,以及如何选择合适的 IPC
管道
管道是 Unix 系统 IPC 的最古老的形式,所有的 Unix 都提供了此种通信机制。管道存在以下一些局限性:
- 在历史上,管道被认为是半双工的(即数据在同一时刻只能单向流动),即使现在有的管道提供了全双工的通信机制,但是为了移植性的考虑,不能假设管道是全双工的
- 管道只能在具有公共父进程的的两个进程之间使用。通常,一个管道是由一个进程创建,在进程调用
fork之后,这个管道就只能在父进程和创建的子进程之间使用了
尽管管道存在这些局限性,但是管道依旧是最常用的进程间通信的形式。管道是通过 pipe 系统调用创建的,函数原型如下:
#include <unistd.h>
int pipe(int fd[2]); // 若创建成功,则返回 0,否则返回 -1
其中,fd[2] 表示两个文件描述符:fd[0] 为读而打开,fd[1] 为写而打开,fd[1] 的输出是 fd[0] 的输入
如下图所示:
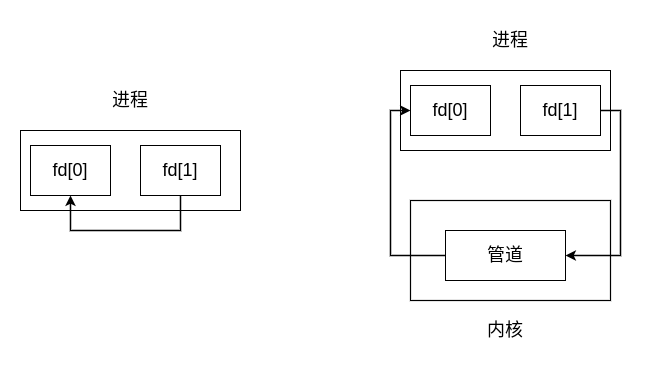
这种在单个进程之间使用的管道没有太大的实际用途,一般是通过父进程调用 pipe 创建一个管道,接着调用 fork 创建一个子进程,创建从父进程到子进程之间的管道,实现 IPC,这时的情况如下图所示:
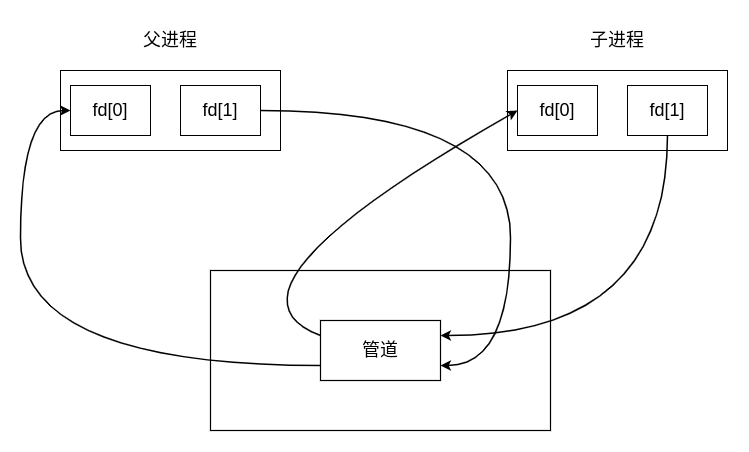
如果关闭父进程的 fd[0](读入),同时关闭子进程的 fd[1](写出),那么此时就可以实现从父进程向子进程发送数据。
当管道的一端被关闭之后,下面的两条规则将会起作用:
- 当读(read)一个写端被关闭的管道时,在所有的数据都被读取之后,
read将会返回 0,表示文件结束 - 当写(write)一个读端被关闭的管道时,则产生信号
SIGPIPE,如果忽略该信号或者捕捉该信号并从其处理程序返回,则write返回 -1,error 设置为EPIPE
#include <stdio.h>
#include <stdlib.h>
#include <stddef.h>
#include <unistd.h>
#include <string.h>
#define MAXLEN 4096
int main(int argc, char ** argv) {
int n;
int fd[2];
pid_t pid;
char line[MAXLEN];
char *content = "From Parent: Hello World\n";
if (pipe(fd) < 0) {
perror("pipe create error!");
exit(1);
}
if ((pid = fork()) < 0) {
perror("fork process error!");
exit(1);
} else if (pid > 0) {
close(fd[0]);
write(fd[1], content, strlen(content)); // 父进程写入数据内容到管道
} else {
close(fd[1]);
n = read(fd[0], line, MAXLEN);
write(STDOUT_FILENO, line, n); // 子进程读取管道内的内容并输出到标准输出
}
exit(0);
}
FIFO(命名管道)
FIFO 是一种文件类型,这种文件主要是用于进程间通信,创建 FIFO 和创建文件类似,而且确实是以文件的形式存在于 Unix 文件系统中,按照如下的系统调用可以创建 FIFO
#include <sys/stat.h>
int mkfifo(const char *path, mode_t mode);
int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 有以下几个用途:
- shell 命令使用 FIFO 将数据从一条管道传输到另一条管道,无需再创建临时文件
- 在客户端—服务段应用程序中,FIFO 作为汇聚点,在客户进程和服务器进程之间传递数据
非线性管道连接
一般情况下,使用传统的 Unix 管道符号 “|” 可以实现将一个程序的输出重定向为另一个程序的输入,但是这种操作有一定的局限性(只能线性连接两个进程),假设现在有一个这样的任务:程序 1 从文件中读取数据,现在希望将程序 1 的处理结果分别发送到程序 2 和程序 3 进行处理,此时的处理情况如下图所示:
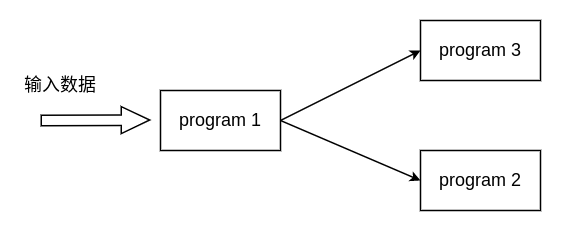
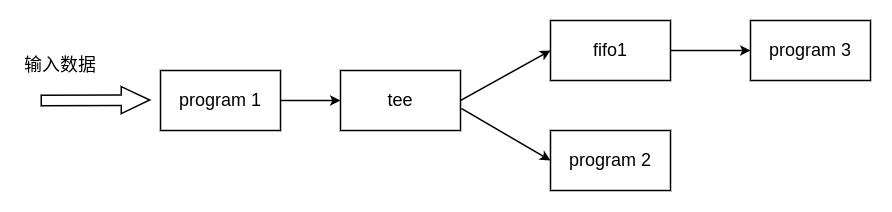
由于传统的管道只能线性连接进程,因此在这个情况下无法使用管道进行处理。但是使用 FIFO 就能够解决这个问题,因为 FIFO 具有名字,因此可以结合 tee 命令(从输入流读取数据写出到标准输出和文件)来实现非线性的连接,具体如下所示:
# 首先,创建一个 fifo 文件
mkfifo fifo1
# 将 fifo1 的数据流定向到 prog3
nohup prog3 < fifo1 &
# 将file 的内容读入到 prog1,然后通过管道连接到 tee,
# tee 会将输入流写入到 fifo1 和 prog2
prog1 < file | tee fifo1 | prog2
此时的情况如下所示:
客户端—服务器通信
假设现在有一个服务器进程,它将要和很多个客户端进程之间进行通信(在这里不讨论有关套接字的内容),如果客户端只是希望将数据写入到服务端进程的话,那么可以创建一个公用的 FIFO,将数据发送到 FIFO 中,如下图所示:
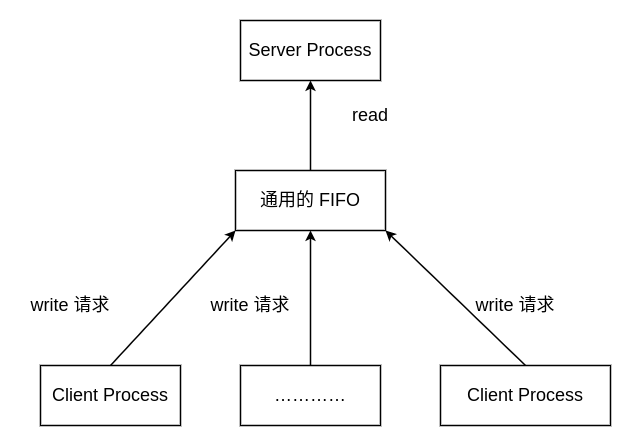
但是如果需要在客户端和服务端进程之间进行通信,也就是说涉及到写入和写出的通信的时候,那么这种方案就不能有效的处理,因为服务端不知道收到的数据来自哪一个客户端进程。
为了解决这个问题,客户端在发送消息给服务端时,在消息体中包含对应的进程 ID,服务端通过进程 ID 创建对应的 FIFO,具体如下图所示:
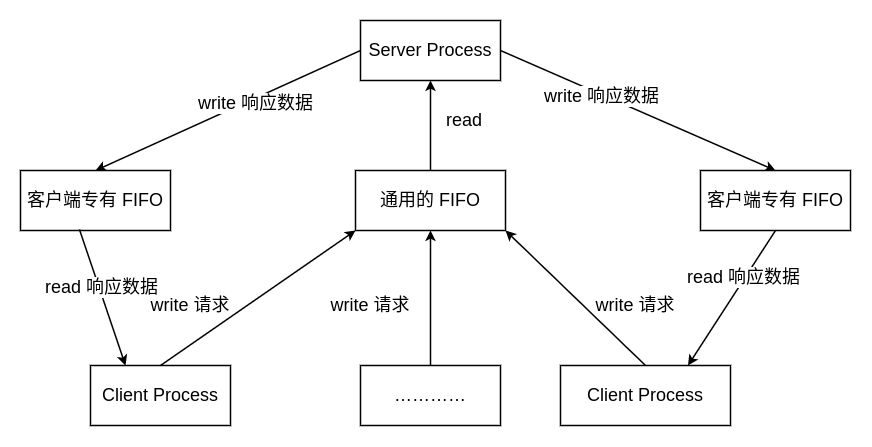
这种方式也存在一定的缺陷,比如,服务端无法得知客户端进程是否存活,因此会一直持有 FIFO
XSI IPC
XSI IPC 有三种形式的 IPC:消息队列、信号量以及共享内存
和上文提到的两种 IPC 不同,这些 IPC 结构都是通过一个非负整数来进行唯一标识,当整数溢出时,再恢复到 0 。
标识符是 XSI IPC 内部的命名,为了能够在多个合作进程上使用同一个 XSI IPC,需要提供一个外部的命名方案。因此,每个 XSI IPC 对象都和一个键(key)关联,将这个键作为该 IPC 的外部名
使用 XSI IPC 存在以下的一些优点:
- XSI IPC 是可靠的、流控制的并且是面向记录的
- XSI IPC 允许以一种非先进先出的方式进行消息的处理
但是 XSI IPC 存在以下的一些问题:
-
XSI IPC 结构的作用范围在整个系统,因此进程自身无法直接管理这些 IPC。例如,如果一个进程创建了一个消息队列,并且在之后放入了消息,那么在进程终止之后该消息队列会依旧存在。
进程可以通过
ipcrm命令来间接地删除 IPC -
XSI IPC 结构在文件系统中没有名字,因此不能像一般的访问文件的形式直接访问这些 IPC。
为了支持访问这些 IPC,系统提供了很多的系统调用,如:
msgget、semop、shmat等可以通过
ipcs来查看当前系统中存在的 IPC -
由于这些 XSI IPC 不使用文件描述符,因此 XSI IPC 也无法享受多路复用技术带来的优势,因此很难一次使用一个以上的 XSI IPC 结构
消息队列
消息队列存在于内核中,由内核进行管理。
如果需要创建一个消息队列,首先需要通过一个键(key)来得到消息队列的 id,函数如下所示:
#include <sys/msg.h>
// 如果通过 key 创建队列成功,则返回该队列的 id;否则,返回 -1
int msgget(key_t key, int msgflg);
如果希望完全由内核来生成消息队列,可以将 key 换成 IPC_PRIVATE,这样内核每次就会返回一个新的消息队列,注意这里的 IPC_PRIVATE 不能作为唯一的键来引用创建的消息队列(这是一个特殊键)
接下来就是创建消息队列,在创建消息队列之前,首选需要初始化 struct msgid_ids 对象,该结构体的具体字段如下:
struct msqid_ds {
/* 权限所有者 ,默认赋值*/
struct ipc_perm msg_perm;
time_t msg_stime; /* 最近一次的消息发送时间, 初始化为 0 值*/
time_t msg_rtime; /* 最近一次收到消息的时间 , 初始化为 0 值*/
time_t msg_ctime; /* 该消息队列的创建时间或者最近一次修改该消息队列的时间,设置为当前时间 */
unsigned long __msg_cbytes; /* 当前消息队列中的字节数, 初始化为 0 值*/
msgqnum_t msg_qnum; /* 当前队列中的消息数量, 初始化为 0 值*/
msglen_t msg_qbytes; /* 在当前消息队列中允许的最大字节数 ,设置为系统限制数*/
pid_t msg_lspid; /* 最近一次发送消息的进程 ID */
pid_t msg_lrpid; /* 最近一次收到消息的进程 ID */
};
之后,调用 msgctl 创建消息队列,函数原型如下:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
// 如果创建成功,则返回 0;否则,返回 -1
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
其中,cmd 参数制定对 msgid 执行的相关命令:
IPC_STAT:获取当前队列的msqid_ds结构,并将它存放在buf指向的结构中IPC_SET:将字段msg_perm.uid、msg_perm.gid、msg_perm.mode和msg_qbytes复制从buf指向的结构复制到和这个队列相关联的msqid_ids中,此命令只能由以下两种进程执行:一种是其有效用户 ID 等于msg_perm.cuid或者msg_perm.uid;另一种是具有超级用户权限的进程IPC_RMID:从系统中删除该消息队列以及仍在消息队列中的所有数据,这种删除将会立刻生效
如果想要将消息发送到消息队列中,可以调用 msgsnd 系统调用函数,函数原型如下:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
每个消息由三部分组成:一个正的长整形的 type 字段、一个非负的长度(msgsz)以及实际数据字节数
msgp 参数指向一个长整形数,包含了正的整形消息类型,后面紧接的是消息数据(如果 msgsz 为 0,则没有数据)。例如,如果希望发送的消息最长是 512 字节,可以定义以下的结构体:
struct msg {
long mtype; /* 消息类型 */
char mtext[512]; /* 消息实际数据 */
}
第三个参数 flag 可以指定玩儿 NO_WAIT,如果消息队列已经满了,那么指定了 NO_WAIT 标记将会使得 msgsnd 调用立刻出错并返回一个 EAGIN,如果没有指定 NO_WAIT 标记,那么进程将会一直阻塞,直到发生下列事件之一:消息队列有足够的空间容纳将要发送的消息;内核删除了该消息队列;捕捉到一个信号,并从信号处理程序返回。在第二种情况下,将会返回 EIDMR 错误,而在第三种情况下将会返回 EINTER 错误
通过 msgrcv 来接受消息队列中的消息,函数原型如下所示:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
/*
msgp 指向消息变量,msgsz 表示指定接受缓冲区的长度
msgtp 表示要接受的消息的类型
*/
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,
int msgflg);
如果接受到的消息的长度大于 msgsz,并且此时将 flag 设置为了 MSG_ERROR,那么该消息将会被截断(不会告知消息是否被截断,被截去的部分将会被丢弃);如果 flag 没有设置该标记,那么当消息太长是将会出错并返回 E2BIG(消息依旧保留在消息队列中)
参数 msgtype 表示希望接受的消息的类型,有以下三种选项:
type == 0:返回消息队列中的第一个消息type > 0:返回队列中消息类型为type的第一个值type < 0:返回队列中消息类型值小于等于type绝对值的消息,如果这种消息有很多个,那么返回类型值最小的消息,使用这个方式可以实现以非先进先出的顺序读取消息
可以将 flag 参数设置为 IPC_NOWAIT,使得操作不阻塞,在这种情况下,如果没有指定类型的消息,那么 msgrcv 将会返回 -1,如果没有设置 IPC_NOWAIT,那么进程将会在这个系统调用上一直阻塞,直到发生以下事件之一:消息队列中有满足条件的消息;内核删除了此消息队列,这种情况下会出错 EINDRM,并且返回 -1;捕捉到一个一个信号并且从信号处理程序中返回(返回值为 -1,出错情况为 EINTR)
当 msgrcv 成功执行时,内核会自动更新消息队列的状态
信号量
信号量是一个计数器,用于提供多个进程之间对共享数据的访问功能
一个进程如果想要获取共享资源,那么它需要经历以下几个操作:
- 测试控制该资源的信号量
- 如果该信号量为正,那么这个进程就可以使用该资源,在这种情况下,进程会将信号量的值 -1,表示当前的进程使用了一个资源单位
- 如果该信号量为 0,那么进程将会进入阻塞状态,直到当前检查的信号量的值大于 0,当进程正常恢复时,将会重复步骤 1
- 当一个进程不再使用一个由信号量控制的共享资源时,将会将该信号量 +1,如果此时有进程在等待这个信号量,那么唤醒这些进程
由于一个信号量可能会被多个进程同时访问,因此为了保证信号量的正确性,这些增减操作都必须是原子操作,因此信号量一般都在内核中实现
内核会为每个信号量维护一个 semid_ds 的结构,如下所示:
#include <sys/sem.h>
struct semid_ds {
struct ipc_perm sem_perm; /* Ownership and permissions */
time_t sem_otime; /* 上次的 semop 时间 */
time_t sem_ctime; /* 创建时间或者上次修改时间 */
unsigned long sem_nsems; /* 在集合中的信号量的编号 */
};
如果希望使用信号量时,首先需要通过 semget 来获取一个信号量 ID,该函数的原型如下所示:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
/*
nsems 表示信号量的个数,如果是创建新的 IPC,那么必须指定 nsems;如果是引用一个现有的 IPC,则将 nsems 置为 0
*/
int semget(key_t key, int nsems, int semflg);
创建完成信号量之后,通过 semctl 来操作信号量,该函数的原型如下所示:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semctl(int semid, int semnum, int cmd, ...);
第四个可选参数为一个共用体,具体原型如下所示:
union semun {
int val; /* Value for SETVAL */
struct semid_ds *buf; /* Buffer for IPC_STAT, IPC_SET */
unsigned short *array; /* Array for GETALL, SETALL */
struct seminfo *__buf; /* Buffer for IPC_INFO
(Linux-specific) */
};
可以通过 semop 函数来自动执行信号量集合上的操作数组,该函数原型如下所示:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
/*
sops 指向信号量操作集合,其结构体包含如下的几个字段:
unsigned short sem_num; // 信号数,即操作信号量集合中的信号的 id
short sem_op; // 对该信号执行的操作,可以为正值、0、负值
short sem_flag; // 操作标记
*/
int semop(int semid, struct sembuf *sops, size_t nsops); // semop 具有原子性
sem_op 的取值介绍如下:
-
如果
sem_op为正值:该值对应于进程释放的占用的资源数,经过该操作之后,会将sem_op的值加到信号量的值上。如果将sem_flag设置为SEM_UNDO,那么会将调整后的信号量的值再减去sem_op,相当于没有进行操作 -
如果
sem_op为负值:表示要获取由该进程控制的资源。如果该信号量的值大于等于
sem_op的绝对值,那么会从信号量值中减去sem_op的绝对值。如果制定了sem_flag为SEM_UNDO,那么sem_op的绝对值也会加到该进程的此信号调整值上如果该信号量的值小于
sem_op的绝对值,那么会有以下几种情况:- 如果指定了
sem_flag为IPC_NOWAIT,那么semop就会出错并返回EAGIN - 如果没有指定
IPC_NOWAIT,那么就会将该信号量的semcnt加一(进程进入休眠状态),然后调用进程被挂起,直到发生以下事件之一:- 信号量的值大于等于
sem_op的绝对值,此时信号两的semcnt值 -1(进程等待结束),然后再按照类似的方式从信号量的值中减去sem_op的绝对值 - 系统删除了次 IPC,在这种情况下,将会出错并返回
EIDRM - 进程捕捉到一个信号,并从信号处理程序中返回,在这种情况下,此信号量的
semcnt将会 -1(进程不再等待),并且函数出错并返回EINTR
- 信号量的值大于等于
- 如果指定了
-
如果
sem_op的值为 0:表示调用进程希望等待直到信号量的值变为 0。如果当前信号量的值为 0,那么当前函数将会立刻返回;如果此时的信号量不是 0,那么有如下几种情况:- 如果
sem_flag指定了IPC_WAIT,则出错返回EAGIN - 如果未指定
IPC_WAIT,那么该信号量的semcnt的值 +1(进程进入休眠状态),然后进程被挂起,等待以下的事件发生:- 此信号值变为 0,此时会将
semcnt值 -1(等待进程结束等待) - 系统删除了此 IPC,在这种情况下,函数出错并返回
EIDRM - 进程捕捉到一个信号,并从信号等待程序中返回,在这种情况下,此信号的
semcnt的值 -1(调用进程不再等待),并且函数出错并返回EINTR
- 此信号值变为 0,此时会将
- 如果
共享存储
共享存储允许两个或者多个进程贡献一个给定的存储区,由于数据不需要在进程之间进行复制,因此这是最快的一种 IPC。由于同一时刻可能会有多个进程同时访问某个共享存储,因此需要注意这些操作的同步问题。
内核会为每个共享存储维护一个结构体变量,这个结构体变量应当至少包含以下几个字段:
struct shmid_ds {
struct ipc_perm shm_perm; // IPC 权限
size_t shm_segsz; /* 共享存储段的长度 */
pid_t shm_lpid; /* 上次调用 shmop() 的进程 ID */
pid_t shm_cpid; /* 创建该 IPC 的进程 ID */
shmatt_t shm_nattch; // 当前访问该 IPC 的进程数
time_t shm_atime;
time_t shm_dtime;
time_t shm_ctime;
}
如果希望创建一个共享存储,首先需要调用 shmget 获得一个贡献存储的唯一标识,该函数原型如下所示:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
对于参数 size 来讲,表示该共享存储段的长度,以字节为单位,实现时通常会向上取整为系统内存的页大小的整数倍,如果指定的 size 不是系统页大小的整数倍,那么最后一页的剩余部分将会是不可用的。如果希望创建一个新的共享存储段,那么必须指定 size 参数,但是如果是引用一个现存的共享存储段,那么一般会将 size 参数置为 \(0\)。
可以通过 shmctl 对共享存储段执行多种操作,该函数原型如下所示:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
其中,cmd 参数至少可以为以下几种参数中的一种,并使其在 shmid 指定的段上执行:
-
IPC_STAT:获取当前段的
shmid_ds结构,并将其存储到buf指向的结构体中 -
IPC_SET:按照buf指向的结构中的值设置和此共享存储段相关联的shmid_ds结构体中的 \(3\) 个字段:shm_perm.uid、shm_perm.gid、shm_perm.mode。这个命令只能有创建该 IPC 的用户或者具有超级用户权限的用户才能执行 -
IPC_RMID:从共享存储中删除此共享存储段。由于每个共享存储段都维护着一个连接计数字段(shmid_ds.shm_nattch),因此只有在使用该存储段的最后一个进程终止或者与该存储段分离,否则实际上不会删除该共享存储段。然而,不管该共享存储段是否被使用,该段的标识符都会被立即删除,因此不能再使用shmat连接该存储段。该命令同样只能具有对应的权限的用户进程才能执行
一旦创建了一个共享存储段,那么进程就可以通过调用 shmat 将其连接到它的地址空间中,该函数的原型如下所示:
#include <sys/ipc.h>
#include <sys/shm.h>
// 如果调用成功,返回指向共享存储段的指针;如果出错,返回 -1
void *shmat(int shmid, const void *addr, int flag);
共享存储段连接到调用进程的地址空间位置有由 addr 参数和 flag 参数是否指定 SHM_RND 有关:
-
如果
addr参数为 \(0\) :将此共享存储段连接到内核可以选择的第一个可用地址上,这也是推荐的方式 -
如果
addr参数不为 \(0\),并且没有指定SHM_RAND标记,那么此共享段将会连接到addr指定的地址上 -
如果
addr不为 \(0\),并且指定了SHM_RAND标记,那么将会将此共享段连接到 \(addr - (addr \mod SHMLBA)\) 表示的地址上。SHM_RAND表示向下取整,而SHMLBA表示 “低边界地址数”
如果指定了 flag 为 SHM_RDONLY,则以只读的方式连接此共享存储段,否则以读写的方式连接此共享存储段
如果对共享存储段的操作已经结束,可以通过调用 shmdt 将调用进程和共享存储段进行分离(这并不会导致系统删除其表示符以及相关的数据结构),该函数原型如下所示:
#include <sys/ipc.h>
#include <sys/shm.h>
/**
addr 表示之前调用 shmat 得到的连接地址
*/
int shmdt(const void *addr);
Unix 域套接字
和一般的套接字连接两台计算机之间的通信类似,与之不同的是 Unix 域套接字只用于同一台计算机上运行的进程之间的通信,由于 Unix 域套接字不需要处理额外的协议信息,因此相对于一般的套接字来讲会更加高效
Unix 域套接字提供流和数据报两种接口,Unix 域数据报服务是可靠的,既不会丢失报文也不会在传递的过程中出错。Unix 域套接字更加像是套接字和管道的混合。可以通过 socketpair 函数来创建一对没有名字的、互相连接的 Unix 域套接字,该函数原型如下所示:
#include <sys/types.h>
#include <sys/socket.h>
int socketpair(int domain, int type, int protocol, int sv[2]);
通过 socketpair 创建的 Unix 域套接字可以起到全双工管道的作用,即两端对于读和写都是开放的,如下图所示:
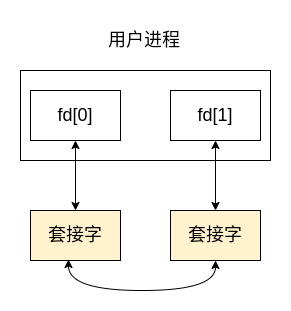
由于套接字本身是一个文件,因此它可以享受到由 IO 多路复用技术带来的优势,不仅如此,Unix 域套接字也可以结合 XSI 消息队列来使得消息队列能够享受到 IO 多路复用带来的好处,具体做法是:在消息队列中开启一个线程,该线程一直阻塞直到从消息队列中获取到消息,当消息到达时,该线程会将它写入到 Unix 域套接字对中,然后再通过 select 或 poll 检查可用的套接字 fd,此时进程将会从套接字对的另一端读取到数据
命名 Unix 域套接字
使用 socketpair 可以很方便地创建一个互相连接的套接字对,但是这样创建的套接字对由于没有名字或者唯一的表示符,因此其它的进程便不能够使用这个套接字对。
正如一般的套接字编程一样,可以给每个 Unix 域套接字命名,使得其它的进程都能够使用这个套接字,如下示例所示:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <stddef.h>
#include <sys/socket.h>
#include <sys/un.h>
int main(int argc, char **argv) {
int fd, size;
struct sockaddr_un un;
un.sun_family = AF_UNIX;
strcpy(un.sun_path, "foo.socket");
if ((fd = socket(AF_UNIX, SOCK_STREAM, 0)) < 0) {
fprintf(stderr, "socket failed.\n");
exit(1);
}
size = offsetof(struct sockaddr_un, sun_path) + strlen(un.sun_path);
if (bind(fd, (struct sockaddr *) &un, size) < 0) {
fprintf(stderr, "bind failed.\n");
exit(1);
}
fprintf(stdout, "Unix Domain Socket bound.\n");
exit(0);
}
struct sockaddr 包含了了一 sun_path 的属性,这个属性表示创建的套接字文件所在的路径,当调用 bind 方法时,将会自动创建一个 S_IFSOCKT 类型的文件,由于这个文件具有名字,因此此时的 Unix 域套接字也就同时具备了名字。
注意这个文件仅仅只是为了告诉其它的进程存在这样的一个 Unix 域套接字,这个文件不能被打开,也不能被应用程序用于通信,如果希望创建套接字使得两个进程通过该套接字进行通信,可以考虑使用 accept
几种 IPC 的比较
如上所述,XSI IPC 一般情况下不应该被考虑,由于传统的管道一般只能提供半双工的通信机制,因此传统的管道也不应当被选取。
因此,一般会在 FIFO 和 Unix 域套接字之间进行选择,以实现在同一台计算机上不同进程之间的通信的目的。一般来讲,Unix 域套接字的性能会比 FIFO 更加好,并且 Unix 域套接字更加灵活,如果不是特别需要的话,一般建议使用 Unix 域套接字作为 Unix 中的 IPC 方式
参考:
[1] 《Unix 环境高级编程》(第三版)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号