Redis 的主从复制
Redis 主从复制是指:将一台 Redis 服务器的数据复制到其它的 Redis 服务器,前者所在的 Redis 服务器也被称为 “主节点”(Master / Leader),后者则被称为 “从节点”(Slave / Follower)。数据从主节点复制到从节点,主节点的主要任务是实现写入数据的任务(也有读数据的权限),而从节点则只负责读取数据。在 Redis 的默认配置中,每个启动的 Redis 服务都是主节点
主节点
一个主节点可以有多个从节点,但是对于每个从节点来讲,它都只能属于一个主节点。即主节点和从节点之间的对应关系为 \(1\) 对 \(N\) ,如下图所示:
主从复制的目的
由于单个的 Redis 服务可能会出现异常,使得 Redis 服务不可用,因此有必要对这种情况进行进一步的处理。
主从复制的目的就是为了解决单一的 Redis 可能会出现的问题,同时,通过主从复制实现 Redis 的读写分离,能够进一步提高整体 Redis 的性能。
主从复制只要提供了如下的功能:
- 数据冗余:主从复制实现了数据的备份,实际上提供了数据冗余的实现方式
- 故障恢复:当主节点出现异常时,可以将一个从节点选举成为一个新的主节点,从而提供了故障恢复的功能
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务,分担服务器的负载。在写少读多的业务场景下,通过多个从节点分担读负载,可以极大地提高
Redis服务能够承载的并发量 - 高可用
环境搭建
具体可以参考官方文档:https://redis.io/topics/cluster-tutorial
或者 https://segmentfault.com/a/1190000038995016 也是一篇介绍比较全面的博客
集群搭建的步骤比较简单,在这里略过
主从复制的实现原理
Redis 的主从复制分为以下两个阶段:sync 阶段和 command propagate 阶段。
sync(同步)阶段
当从节点启动之后,会发送 sync 指令给主节点,要求全量同步数据,具体的步骤如下图所示:
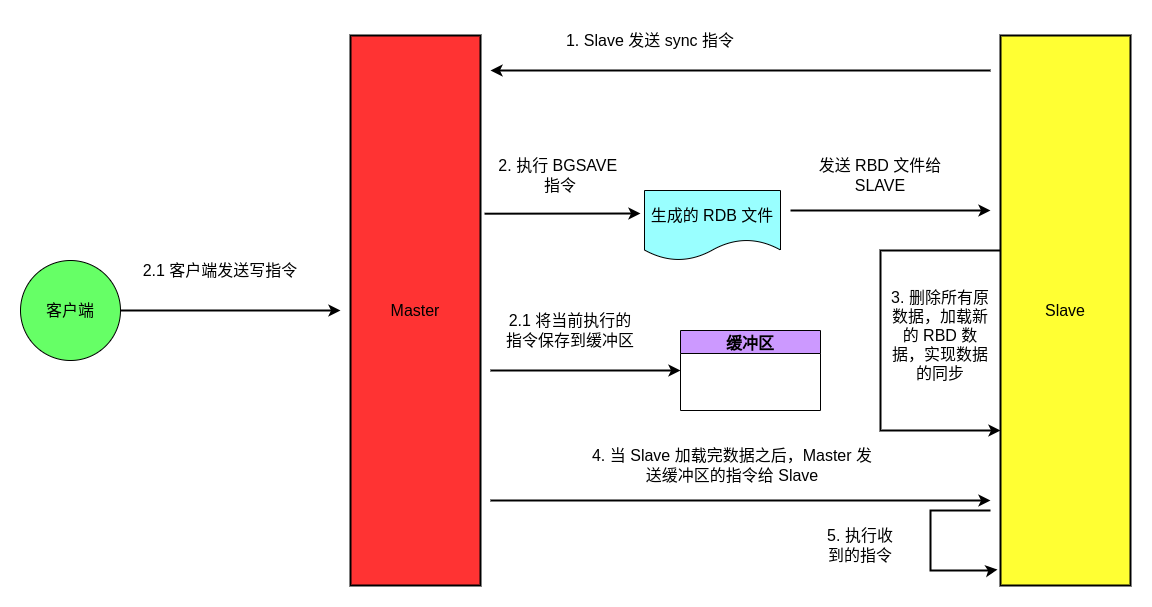
Slave节点向Master节点发送sync指令,以请求数据同步Master节点在接收到sync指令后,会执行一次BGSAVE指令,将当前Master节点中的数据保存到对应的RDB文件中。当Master节点完成RDB文件的导出后,再将导出的RDB文件发送给Slave节点。由于在这个过程中Master节点依旧有可能发生数据写入操作,在这种情况下Master节点会将执行的指令放入到对应的缓冲区Slave节点在接受到Master节点导出的RDB文件之后,会删除现有节点的所有数据,然后加载这个RDB文件的内容到Slave节点- 当
Slave节点数据加载完成之后,Master会将缓冲区中暂存的指令发送到Slave节点 Slave执行收到的指令,完成数据的同步
Command Propagate 阶段
这个阶段也被称为 “命令传播” 阶段,数据同步完成之后,如果后续 Master 节点继续收到了新的写入操作的指令,那么也需要将该命令传播到 Slave 节点以完成数据的同步。这个过程就被称为 “命令传播”
psync 指令
上文提到 Slave 节点在启动时通过发送 sync 指令到 Master 节点用户获取数据的同步,在 Slave 节点启动的时候执行 sync 指令来进行同步是很合理的。但是如果在运行的过程中,由于网络抖动,使得 Slave 断开了同 Master 节点的连接,那么 Slave 节点再再次连接到 Master 节点时依旧通过 sync 指令来进行同步,那么性能就会非常差。
为了解决这个问题,自 Redis 2.8 开始,引入了 psync 指令来代替 sync 指令
psync 指令会根据不同的情况,来执行全量重同步和部分重同步
- 全量重同步:当从节点是第一次与主节点建立连接的时候,那么就会执行全量重同步,这个同步过程和上文
sync+command propagate进行同步的过程一致 - 部分重同步:从
Slave节点的复制偏移量在Master节点的复制积压区中寻找待同步的数据
psync 通过 Redis 的节点 ID 来判断 Slave 节点是否是第一次与 Master 节点进行同步
复制偏移量:Master 节点和 Slave 节点都保存着一份赋值偏移量,当 Master 节点每次向 Slave 节点发送 \(n\) 字节的数据时,就会在 Master 节点上将偏移量增加 \(n\);而每次 Slave 节点在接收到 \(n\) 字节的数据时,也会将节点上的偏移量增加 \(n\)。
在 “命令传播阶段”,Slave 节点会定期发送心跳 REPLYCONF ACK {offset} 指令,这里的 offset 就是 Slave 节点的偏移量。当 Master 节点在收到这个心跳指令之后,会对比自己的 offset 和收到的 offset,如果发现有数据丢失,那么 Master 节点就会推送丢失的那段数据给 Slave 节点。这个过程如下图所示:
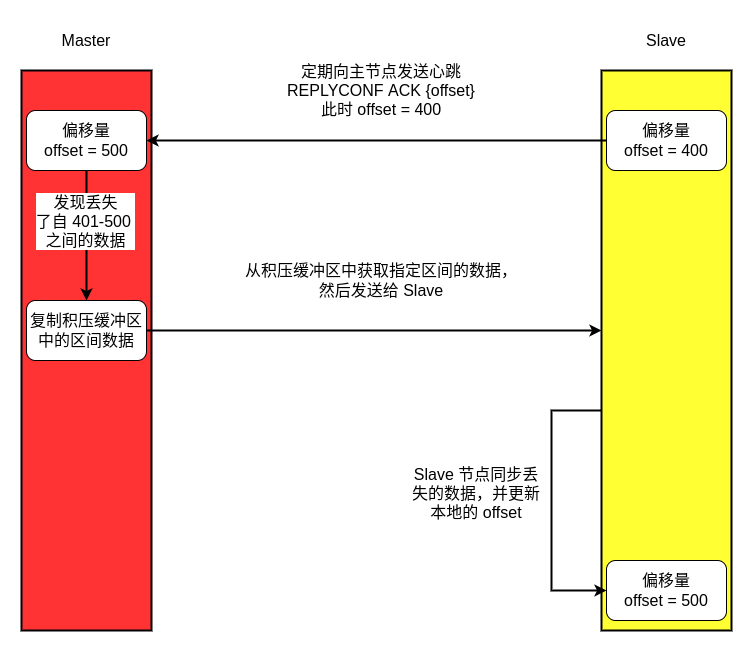
复制积压缓冲区:由主节点维护的的一个固定长度(默认为 \(1\) MB)的队列,该队列存储了每个字节值与对应的复制偏移量。
由于复制积压缓冲区的大小是固定的,因此它保存的是最近 Master 节点执行的写操作命令。当 Slave 节点将 offset 发送给 Master 节点之后,Master 节点会根据 offset 与复制积压缓冲区的大小来决定是否可以使用部分重同步。如果 offset 后面的数据依旧存在于复制积压缓冲区,则执行部分重同步,否则执行全量重同步
节点 ID:Redis 实例启动之后,就会产生一个唯一的标识 ID,用于标识当前的 Redis 实例
当 Master 节点同 Slave 节点进行第一次连接同步时,Master 节点会将 ID 发送给 Slave 节点,Slave 节点在收到 Master 节点的 ID 之后会将他们进行保存。如果在 Slave 节点和 Master 节点之间的连接由于某些原因断开了,那么当 Slave 在恢复到与 Master 节点之间的链接时,Slave 节点会将这个 ID 发送给 Master 节点,Master 节点会将该 ID 与自己的实例 ID 进行比较,如果相同,则说明该 Slave 之前同 Master 节点是连接的。
Redis 哨兵
上面的集群搭建之后,如果 Master 节点崩溃了,在上面的情况下不会将 Slave 节点转换为 Master 节点,因此 Master 节点崩溃之后整个 Redis 集群就不能再执行写入操作。
为了解决这个问题,提高系统的可用性,Redis 提供了 Sentinel(哨兵)来实现 Slave 节点到 Master 节点的转换
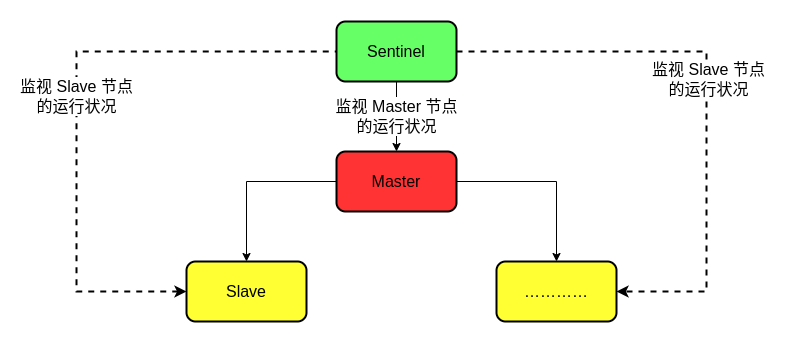
“哨兵” 节点本质上也是一个 Redis 节点,但是和 Master 节点和 Slave 节点不同,“哨兵” 节点只是监视 Master 节点和 Slave 节点,并不执行相关的业务操作。具体关系如下图所示:
“哨兵” 的主要有以下几个作用:
- 监控
Redis节点运行状态 - 通知:当被监控的
Redis节点出现问题时,Sentinel可以通过向API或者管理员以及其它应用发送通知 - 自动故障转移:当一个主服务器不能正常工作时,
Sentinel会开始一次自动故障迁移,它会在失效的Redis集群中寻找一个有效的节点,并将它升级为新的Master节点,并将原来失效的Master节点降级为Slave节点。当客户端试图访问已经失效的Master节点时,Redis集群也会想客户端返回新的Master节点的地址,使得Redis集群可以使用新的Master节点代替失效的Master节点
由于使用单个的 “哨兵” 来监视 Redis 集群的节点也不是完全可靠的,因为 “哨兵” 节点也有可能会出现故障,因此,一般情况下会使用多个 “哨兵” 节点来监视整个 Redis 集群,如下图所示:
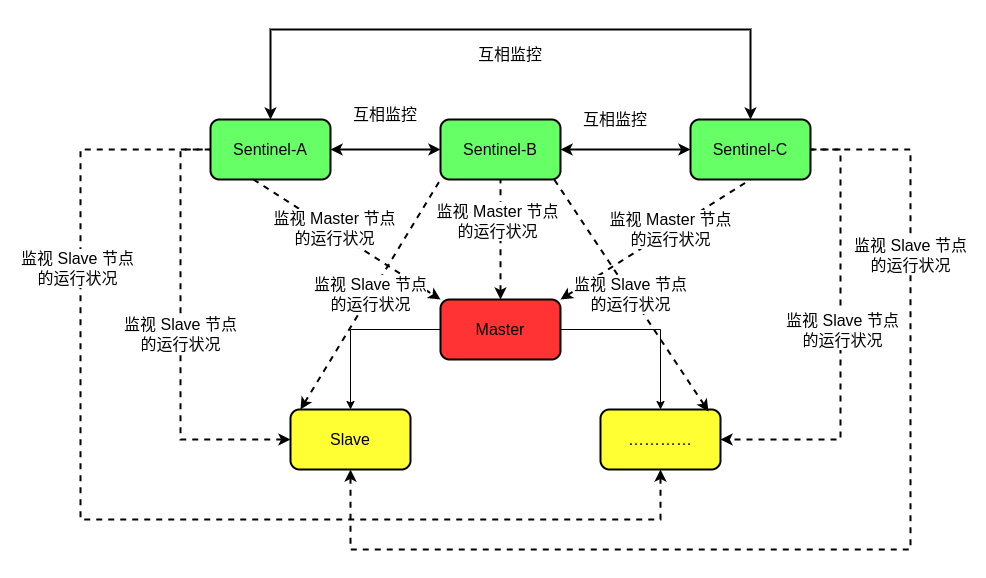
由于存在多个 哨兵 节点,因此在 Redis Sentinel 中,对于 Redis 节点的下线也有区分:
- 主观下线(Subjectively Down,即 SDOWN):指单个
Sentinel节点对集群中的节点作出下线判断 - 客观下线(Objectively Down,即 ODOWN):指多个
Sentinel节点对集群中的节点作出 “SDOWN” 判断,并且通过SENTINEL is-master-down-by-addr命令互相交流之后,作出Redis节点下线的判断
一个 Sentinel 节点可以通过向另一个 Sentinel 节点发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的节点已经下线
Redis Sentinel 部署
具体可以参考:https://www.cnblogs.com/youzhibing/p/8466491.html#autoid-4-0-0,这个部署比较简单,在此略过
值得注意的是有关 sentinel 的配置文件:
# sentinel的端口号,如果配置3个Sentinel,只需要修改这个port即可,即:26380、26381、26382
port 26381
# 设置当前 sentinel 是否放入后台运行
daemonize yes
# 设置当前 sentinel 的日志输出文件
logfile "/tmp/sentinel/sentinel-26381.log"
# 该 sentinel 对应的进程对应的文件描述符
pidfile "/var/run/redis-sentinel-26381.pid"
# 监视127.0.0.1:6701、6700、6702 的节点,且至少有2个Sentinel判断主节点失效,才可以自动故障迁移
sentinel monitor myslave-2 127.0.0.1 6702 2
sentinel monitor mymaster 127.0.0.1 6700 2
sentinel monitor myslave-1 127.0.0.1 6701 2
# 那么Sentinel将这个服务器标记为主观下线(subjectively down,简称 SDOWN )
sentinel down-after-milliseconds mymaster 60000
具体的配置文件的相关属性可以参考官方文档:https://redis.io/topics/sentinel
实现原理
对于节点的检测,主要通过以下三种方式来进行检测:
- 每个
Sentinel会每隔 \(10\)s 向主节点中发送INFO指令,通过该指令可以获得整个Redis节点的拓扑图。在这个时候,如果有新的节点加入或者有节点退出当前的集群,那么Sentinel就能够感知到拓扑图结构的变化。 - 每个
Sentinel节点每隔 \(2\)s 会向指定的 Channel 发布自己对Master节点是否正常的判断以及当前Sentinel节点的信息,通过订阅这个Channel,可以获得其它Sentinel节点的信息以及对Master节点的存活状态的判断 - 每个
Sentinel节点每隔 \(1\)s 就会向所有节点(包括Sentinel节点、Master节点以及Slave节点)发送PING指令来检测节点的存活状态
主节点的选举流程:
- 当一个
Sentinel节点判断Master节点不可用时,首先进行 “SDOWN”(主观下线),此时,这个Sentinel通过SENTINEL is-masterdown-by-addr指令获取其它哨兵节点对于当前Master节点的判断情况,如果当前哨兵节点对于当前Master节点的下线判断数量超过了在配置文件中定义的票数,那么该Master节点就被判定为 “ODOWN”(主观下线) Sentinel节点列表中也会存在一个Leader Sentinel,该Sentinel会从原主节点的从节点中选出一个新的主节点,具体步骤如下所示:- 首先,过滤掉所有的
ODOWN节点 - 选择
slave-priority最大的节点,如果存在则选择这个节点为新的主节点,如果没有则继续下面的流程 - 选出复制偏移量最大的节点,如果有则返回;如果没有则继续执行下面的流程
- 选择
run_id(服务运行 id) 最小的节点
- 首先,过滤掉所有的
- 当选择出新的主节点之后,
Leader Sentinel节点会通过SLAVEOF NO ONE命令让选择出来的节点成为主节点,然后通过SLAVEOF命令让其他节点成为该节点的从节点
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号