Kafka 具体分析
前面的相关文件简要地介绍了 Kafka 的基本使用,本文将将要介绍一下关于 Kafka 的集群关系、存储结构以及架构方面的内容进行简要的解析
组件之间的关系
Kafka 中,各个组件之间的关系如下图所示:
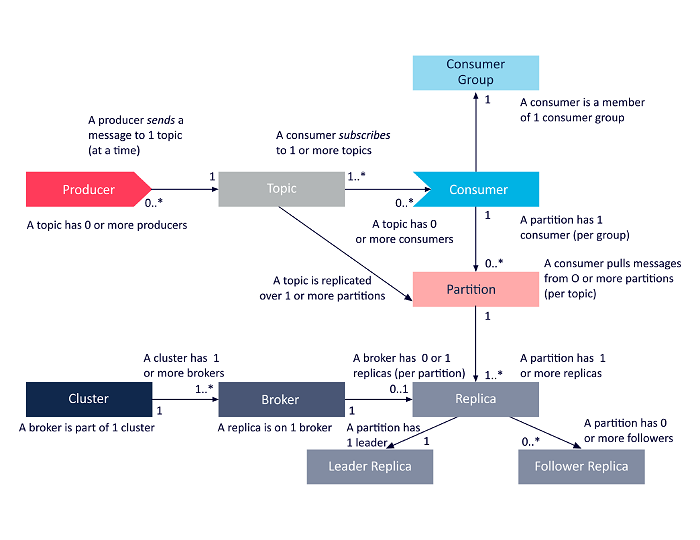
每个组件的解释如下:
- Producer:生产者,实际产生消息的角色
- Topic:直接翻译过来就是 “主题” 的意思,相当于一个收视频道,生产者将消息发送到这个频道,消费者则从这个频道中拉取消息。该组件是一个逻辑上的概念,在物理存储上并不存在
- Consumer Group:消费消息的基本单位,消息的消费是通过消费组进行消费的,不同的消费组之间消费消息的情况是彼此隔离的
- Consumer:消费者,实际消费消息的角色,位于对应的消费组中,同一个消费组中的消费者消费相同的 Topic 的不同分区的消息,彼此之间的消费情况都是 “可见的”
- Partition: Topic 中消息具体的存储结构,每个 Partition 下都会存有消息的实际存储文件以及对应的索引文件等信息,在单个的 Partition 中的消息内容是有序的,但是从整体的 Topic 来看,由于一般会采用多个 Partition 的方式来存储消息,因此 Topic 的消息一般不会是严格有序的
- Replica: Partition 的副本,为了维护消息的高可用i性,一般会创建多个 Partition 的副本,每个 Partition 的副本数不能超过实际 Broker 的数量
- Leader Replica:当前实际使用的 Partition
- Follower Replica:相当于 “备胎”,只有当 Leader Replica 不可用时才会考虑使用,选一个作为新的 Leader Replica
- Broker:即 Kafka 服务器的数量,这个是实际存储 Partition 的 Kafka 服务器,该组件可以通过创建多个来维持 Kafka 的高可用性,通过 Zookeeper 来实现服务注册与发现
- Cluster: Kafka 集群,包含多个 Broker
实际使用时可能会构成类似于下图所示的存储结构:
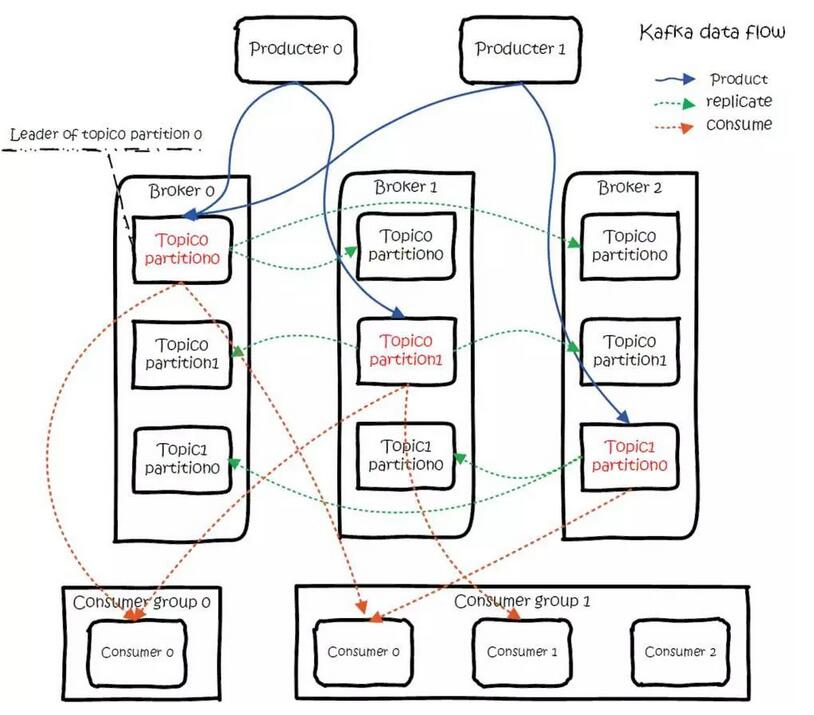
每个 Topic 的 Partition 都不会放到同一个 Broker 上,这是为了提高 Topic 的处理性能;由于一般会为 Partition 创建副本,但是副本是一定不能放在当前的 Broker 上(如果放到同一个 Broker 上就失去了副本存在的意义)
存储结构
Zookeeper 的存储
-
Broker 的注册
Kafka 的 Broker 注册在 Zookeeper 上,当启动 Broker 的时候,会在 Zookeeper 上生成一个临时节点,临时节点的值就是 Broker 在配置文件中设置的
broker.id的属性值。Kafka 在注册 Broker 的时候会在 Zookeeper 上生成一个名为
/brokers的节点,这个节点是一个临时节点,其中,注册 Broker 时会首先将 Broker 的 id 属性放到 Zookeeper 上生成一个对应的临时节点,具体位于/brokers/ids的节点下,如下图所示:
这些节点都是临时节点,其中
/brokers/ids/0表示已经注册了 id 为 0 的 Broker,因此此时如果有 id 相同的 Broker 再进行注册的话,将会失败,因为此时已经注册了这个 Broker当 Broker 由于某些原因崩溃之后,已经注册的 Broker 的会话信息将会被删除,即对应的 znode 节点将会被释放;如果 Broker 是通过正常的方式来关闭的,同样的节点也会消失,但是它的 id 依旧会存储在其它的数据结构中,在完全关闭一个 Broker 之后,如果使用相同的 Broker id 再启动一个 Broker,就会立刻加入集群,并拥有与原来注册的 Broker 相同的分区和副本[1]
-
Topic 的存储
在 Zookeeper 上查看对应的 Topic 的节点信息,如下图所示:
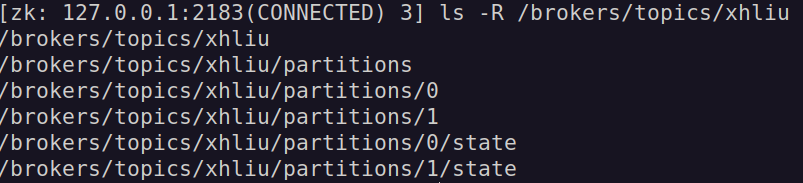
可以看到,在名为 “xhliu” 的主题上存在的节点信息,查看
/brokers/topics/xhliu节点的信息,如下图所示: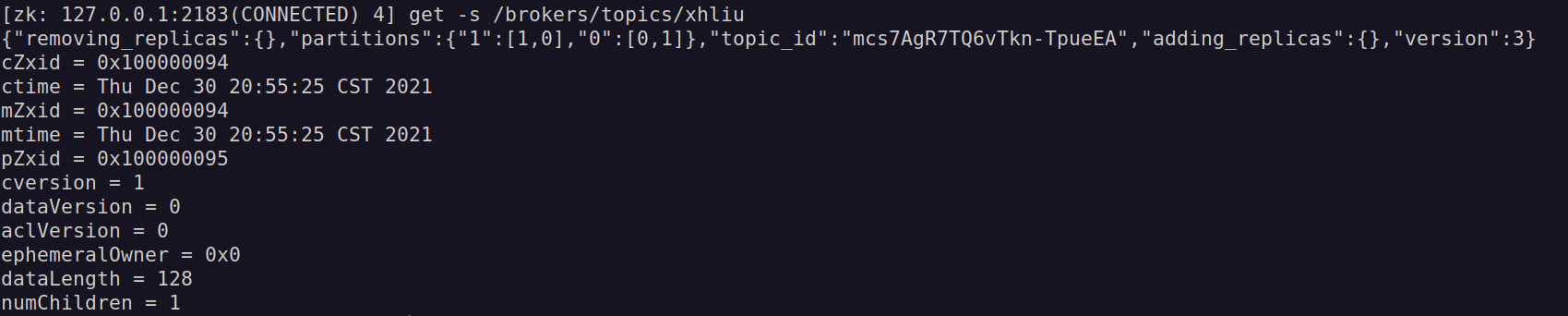
其中的节点的数据内容包含了相关的元数据信息,包括分区信息等
-
控制器
控制器是一个 Broker,和一般的 Broker 的功能类似,但是它有额外的功能:帮助主题的分区副本选举 Leader 副本,集群中第一个启动的 Broker 会在 Zookeeper 中创建一个名为
/controller的临时节点。其它的 Broker 在启动时则会通过 Zookeeper 的 Watch 机制来监视这个节点,如果创建/controller临时节点的 Broker 崩溃了,由于 Watch 机制的存在,其它 Broker 会再去创建/controller的临时节点
副本间的复制
在主题中,会存在一个 Leader 副本和若干个 Follower 副本(理想情况),Follower 副本会尝试从 Leader 副本处获取数据,以达到和 Leader 副本之间的数据一致性。
一般来讲 Follower 副本从 Leader 副本中获取数据的流程如下:
- Follower 副本向 Leader 副本发送三个获取数据的请求,这里简称为请求 1、请求 2、请求 3
- 如果此时 Follower 副本没有同步完成这三条消息,则不会向 Leader 副本发送后面的数据请求
- 在 10s 内,如果 Follower 完全同步了之前的三条消息,那么 Leader 副本就会知道这个 Follower 副本已经完成了同步,则会将它加入到同步副本集合(ISR In-Sync Replica)中;否则,这个 Follower 就被视为是非同步的
可以通过 replica.lag.time.max.ms 配置来设置间隔时间,超过时间的 Follower 副本将会被踢出 ISR,如果已经被踢出 ISR 的 Follower 副本由于某些原因又同步到了 Leader 副本,则会又将它加入到 ISR 中
对于请求的处理
生产消息的请求
当生产者向一个主题的分区发送消息时,此时包含 Leader 副本的 Broker 在收到生产请求时,会对请求做一些验证:
- 发送数据的用户是否具有对 Topic 的写入权限
- 请求中包含的 acks 的值是否是有效的(只允许出现 0、1、-1)
- 如果 acks 的值是 -1,那么是否有足够多的同步副本保证消息已经被安全写入
从操作系统的层面上来看,消息会被首先写入到文件系统的缓存中,并不保证数据一定会被写入到磁盘上,Kafka 不会等待实际写入到磁盘中
当消息被写入到分区的 Leader 副本之后,Broker 会再次检测 acks 的配置参数,如果 acks 被设置为 0 或 1,那么 Broker 会立即返回响应;如果 acks 被设置成了 -1,那么请求将会保存到一个被称为 “hell” 的缓冲区中,直到所有的消息都已经被写入到 Follower 副本,才会将响应返回给客户端
消费消息的请求
消费信息的请求首先会到达指定的 Leader 分区上,客户端首先需要通过查询元数据来确保请求的路由是正确的;Leader 副本在收到请求时,首先会检测这个请求是否是有效的,比如:请求的 Offset 是否存在等一系列的检查
-
零拷贝技术
通过 Broker 对请求的检测之后,Broker 将会按照客户端的请求读取数据返回给客户端,在这个过程中 Kafka 采用了一种被称为 “零拷贝” 的技术来直接将数据发送给客户端,由于 Kafka 存储的是二进制数据,消费端也只是接受二进制数据,读取文件到 Kafka 这个过程是多余的,如下图所示:
在没有使用 “零拷贝” 技术之前,发送消息的过程如下所示:
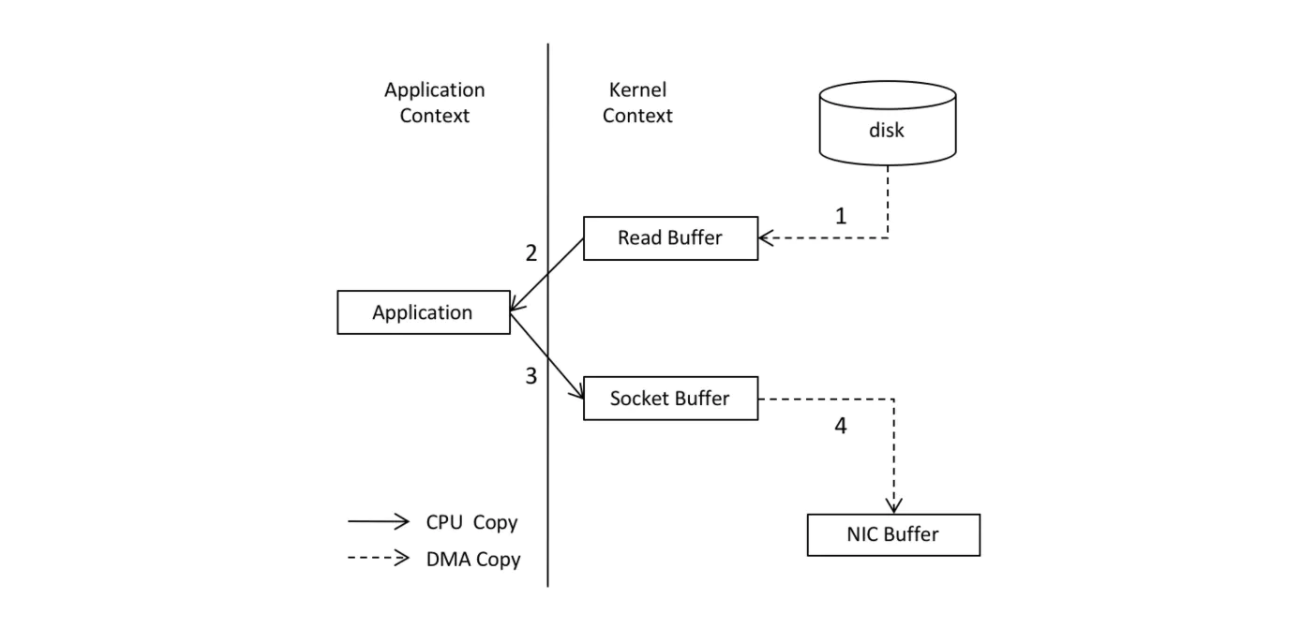
使用 “零拷贝” 技术之后,发送消息的过程如下图所示:
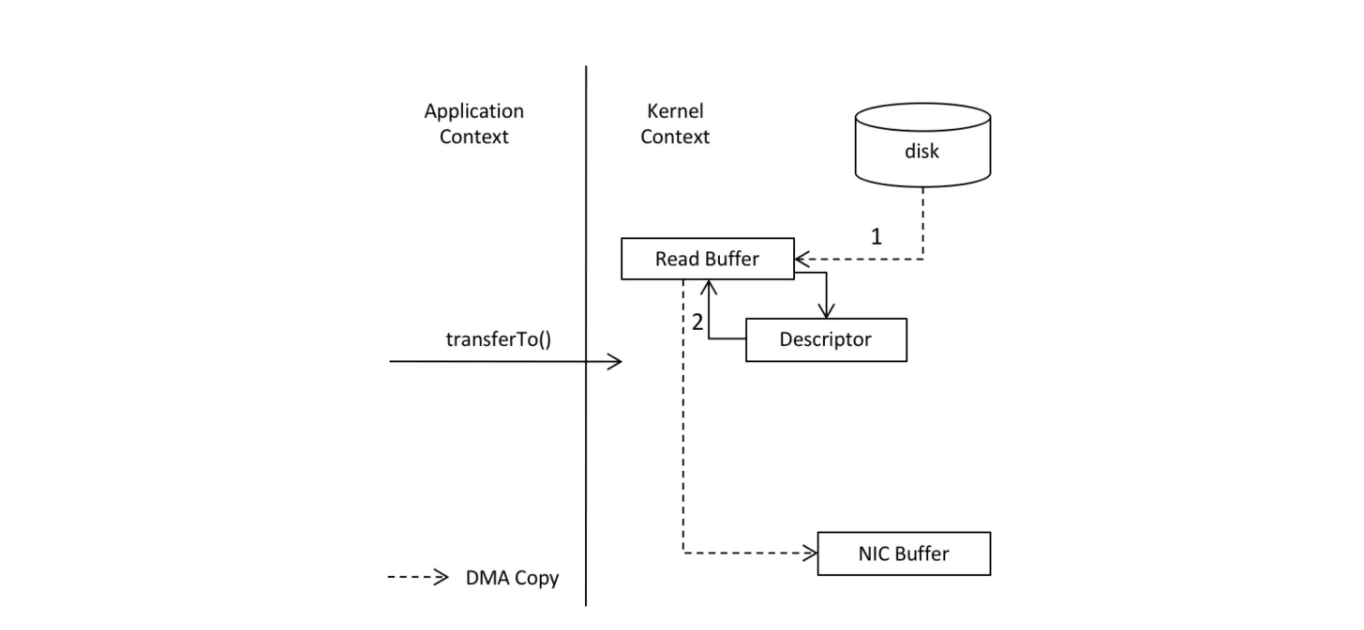
由于 “零拷贝” 减少了数据在操作系统和应用程序缓存之间的复制,因此提高了处理的性能
-
批次发送消息
除了使用 “零拷贝” 技术之外,Kafka 对于消息的发送还做了一些额外的处理以提性能,Broker 提供了设置数据量大小的上限和下限,设置上限是为了避免由于消息量太大导致系统崩溃,而设置下限则是为了发送消息的效率。一次发送一条消息显然不如一次发送 5 条消息来的快,具体如下图所示:
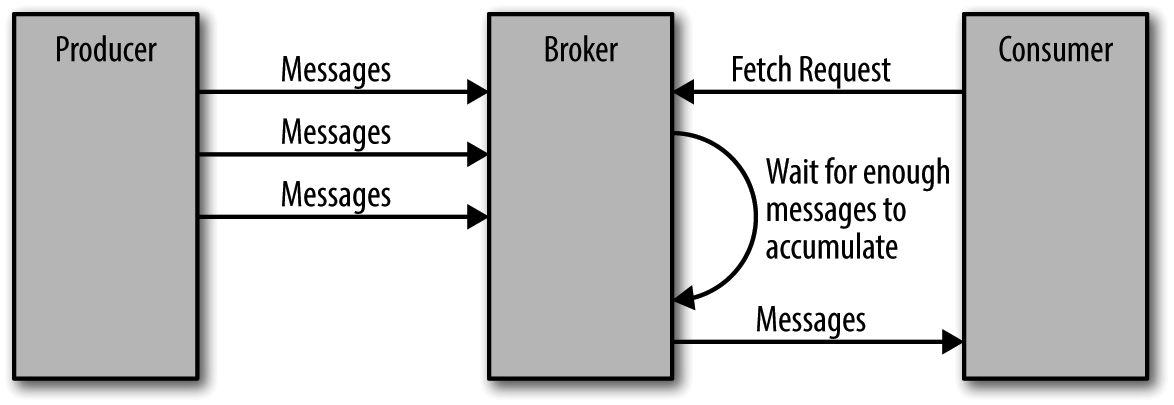
由于减少了发送的次数,因此提高了发送的效率
当然,也不是必须等待达到这个批处理的容量,当达到一定的时间间隔之后,无论是否达到了批量发送的大小,都会发送当前待发送的批量消息
-
HW
对于客户端来讲,并不是所有已经写入了 Leader 副本的消息都是可以读取的,消费者只能读取已经同步到所有副本的消息,因为未被同步的消息被视作 “不安全的”(Leader 副本的崩溃将会导致消息的丢失)
HW (High Water)翻译过来的意思是 “高水位”,这是相对来讲的,实际上是取所有副本的最小 offset,如果倒过来就是 offset 最小的水位线就是最高的,如下图所示:
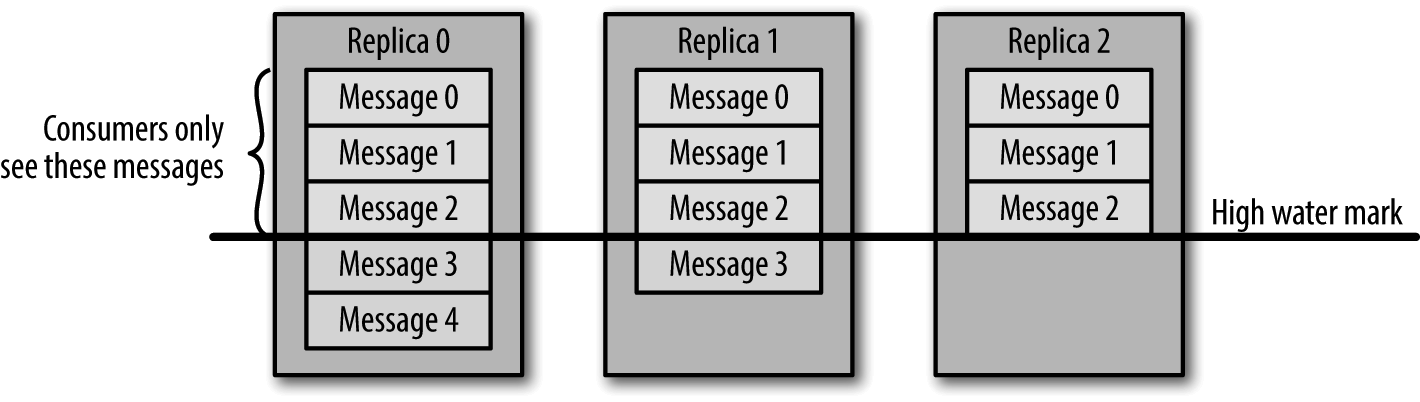
副本 2 的 offset 最小,对应的水位线就是最高的,使用时取最大的水位线
物理存储
Kafka 在物理磁盘上的存储是以分区的方式来存储的,分区是 Broker 中存储数据的最小单位(分区中的数据可以划分成多个文件,但是这些文件是不能放在不同的 Broker 中的)
分区分配
Kafka 通过轮询的方式来分配分区到对应的 Broker,比如,假设现在有 6 个 Broker,创建了一个包含 10 个分区的 Topic,这个 Topic 的复制系数为 3,具体的分配过程如下所示:
-
首先随机选择一个 Broker,假设随机选择的 Broker 是 4
-
通过轮询的方式给每一个 Broker 分配对应的分区
因此,最后的结果就是 Leader 分区 0 会在 Broker 4 上,Leader 分区 1 会在 Broker 5 上,Leader 分区 2 会在 Broker 0 上(从 0 开始计数),以此类推;分配完成 Leader 分区之后,副本就要按照轮询的方式再进行分配,比如,现在分区 1 的 Follower 分区 1 将会分配到 Broker 5 上,Follower 分区 2 将会分配到 Broker 0 上,以此类推
分区文件管理
Kafka 会保留数据一定的期限,但是不会一直保留数据,也不会等到所有的消费者都读取了消息之后再删除数据。Kafka 为每个 Topic 配置了数据保留期限,当超过期限时间或者单个文件的大小超过限制的大小时,将会自动删除数据
由于在单个的大文件中查找和删除消息比较费时,因此 Kafka 会将数据文件划分为多个 log 文件,默认情况下,一个 log 日志文件最多只能存储 1 GB 或者一周的数据,超出这个限制将会创建一个新的 log 文件;当 Broker 向分区的 log 文件中写入数据时,如果达到了上限,也会重新创建一个新的 log 文件
可以通过在创建 Broker 时指定 log.retention.ms 参数来设置数据文件的保留时间;log.retention.bytes 参数设置数据文件的最大大小
当前 Broker 正在写入的数据的 log 文件也被称为 “活跃的 log“,”活跃的 log“ 永远不会被删除,举个例子,如果设置了保存数据的最大限制时间为 1 天,但是这个 log 文件被 Broker 在持续 5 天都被写入,那么这个 log 文件将会被保留 5 天而不是配置的 1 天
文件格式
保存在磁盘上的数据格式和生产者发送过来的消息是一致的,这是由于 ”零拷贝“ 技术使用时考虑到的,这样直接发送二进制数据可以减少 CPU 的压力。
一般的消息的存储格式如下图所示:

在传输过程中,使用压缩算法对消息进行压缩是很常见的情况,常见的压缩算法有:Snappy、GZip 等,如果将消息进行压缩,那么此时的存储格式如下图所示:
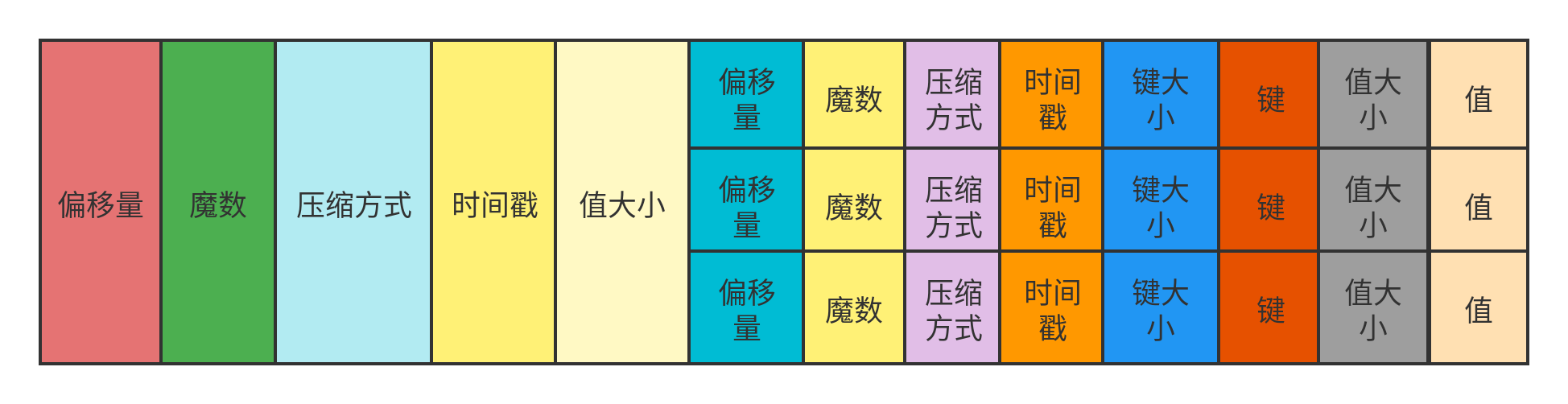
注意,其中的消息内容经过压缩后变成了一堆二进制数据,上图显示之所有有具体内容只是为了显示方便而已
索引
在磁盘上使用顺序读写的方式确实可以提高磁盘读取的效率(相对随机读写来讲),但是由于消费者在读取对应的消息时需要读取对应的 log 文件的偏移量的位置的数据,那么首先需要找到这个偏移量对应的位置。为了加快这个查找位置的速度,Kafka 为每个分区的 log 文件配置了对应的索引文件(即分区目录下的 .index 文件)
索引文件也会被分成多份,Kafka 不维护索引的校验和,当索引文件出现损坏时将会重新读取 log 文件来生成对应的索引文件,因此,如果有必要的话,可以放心地删除索引文件。
索引文件和 log 文件的对应关系如下所示
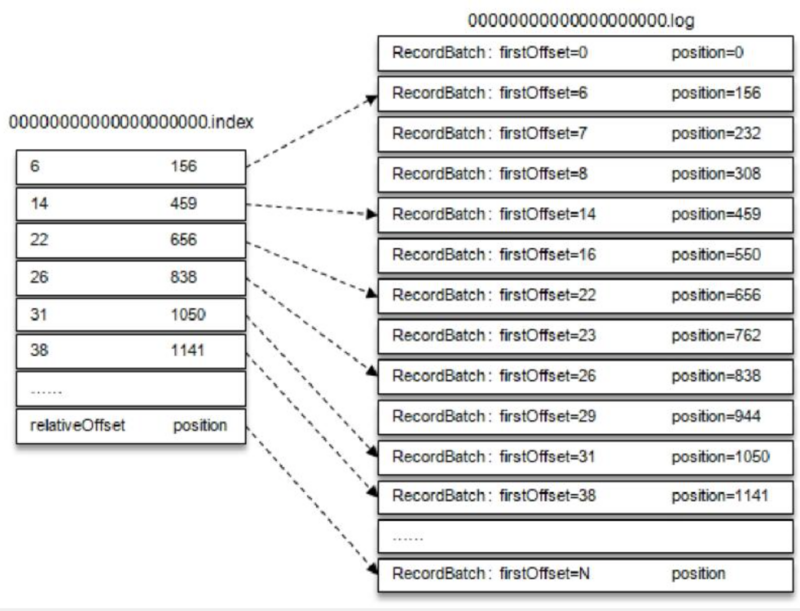
[2]
参考:
[1] 《Kafka 权威指南》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号