MySQL 基础(一)数据存储
存储在磁盘上的数据需要通过 IO 来读取,这是一个比较耗时的操作,为了能够提高访问速度,MySQL 引入了 Page 的结构作为客户端与数据交互的基本单元。
Page 结构
Page 的大小默认为 16 kb,由于这个大小可能无法与某些操作系统的页大小相匹配,这种情况下可能会使得对于 Page 的写入无法保证原子性(即 Page 没有完全写入,这种情况非常危险),为了解决这个问题,可以设置 Page 的大小,具体在 /etc/my.inf 文件中配置(windows 上为 my.ini 文件):
# 将 Page 的大小设置为 4kb,只有在 MySQL 5.6 之后使用 InnoDB 存储引擎才可以修改
innodb_page_size=4K
出于不同的目的,Page 也有许多类型,比如,用于存储索引的 Page 被称为索引页,存储数据的 Page 被称为数据页,存储日志的 Page 被称为日志信息页等
Page 的一般结构如下图所示:
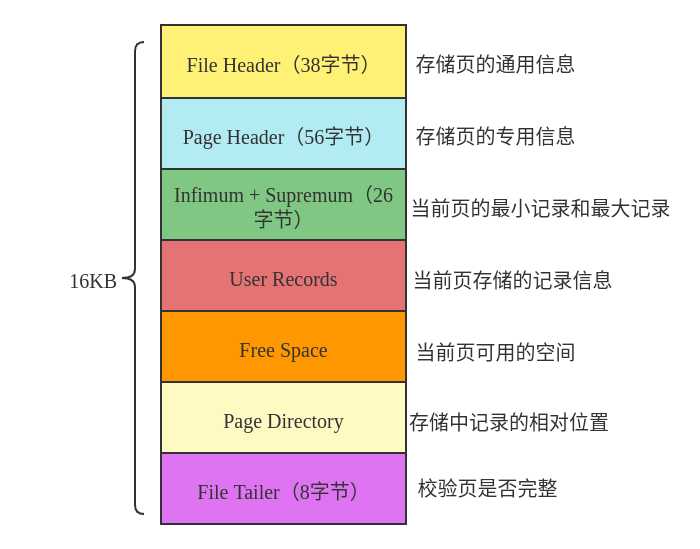
具体介绍如下:
File Header:38 字节,用于存储页的通用信息Page Header:56 字节,用于存储页的专用信息,即页的状态信息Infimum + Supermum:26 字节,用于存储当前页的最小记录和最大记录User Records:用于存储在当前页中实际存储的数据Free Space:表示当前页可用的存储空间Page Directory:页目录,存储用户记录的相对位置File Tailer:8 字节,这个属性的主要目的是用于检测当前的Page是否是完整的
Row 的结构
当读取数据时,将会从 Table 中加载数据到 Page,而在表中数据是以 row 为基本单位读取到 Page 中,即存储在 User Record 中的数据是以 row 为单位的
MySQL 中 row 的结构如下图所示(以 COMPACT 行格式为例):
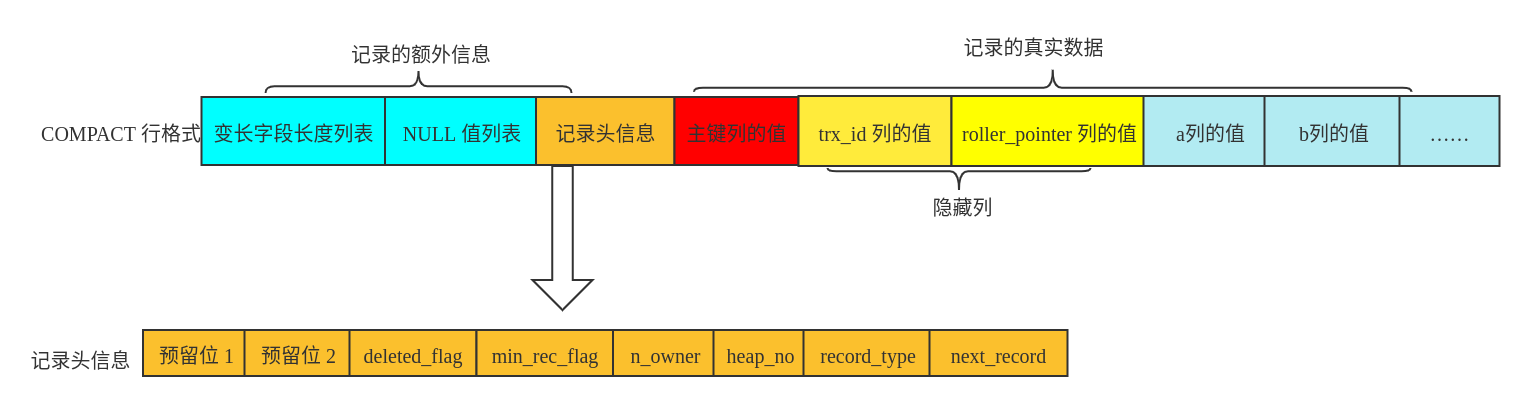
关键的部分在于记录头信息的组成部分,具体解释如下:
-
“预留位 1” 和 “预留位 2”:这两个位置是保留位使得之后的版本可以进行扩展
-
deleted_flag:当前对应的row是否被删除,这里只是逻辑上的删除。将这个位置为 1 表示已经被删除,通过这个标记位,可以将所有被删除的row组合称为一个 “垃圾链表”,同时使得当前row的空间可以被复用 -
min_rec_flag:B+ 树每层非叶子节点中标识最小的目录项记录 -
n_owner:把一个页划分成若干个组,提高整体的性能。该组中主键最大的row将会保存该值,表示该组中存在的记录的数量 -
heap_no:堆号,每条插入进来的记录都会被分配一个堆号,插入的堆号从 2 开始,这是因为Infimum的堆号设置为 0,Supremum的堆号设置为 1,因此新插入的记录的堆号需要从 2 开始计数 -
record_type:插入的记录的类型,0 表示普通数据记录,1 表示 B+ 树的非叶子节点目录项记录,2 表示Infimum的记录,3 表示Supremum的记录 -
next_record:下一条记录,从当前记录的真实数据到下一条的真实数据的距离(忽略 “记录的额外信息部分”)
底层 row 的存储将会按照主键的顺序从小到大依次排序,因此即使数据的插入顺序不是按照顺序来的,那么最后的存储依旧会是有序的
底层的 row 记录的特点:
- 记录会按照主键顺序从小到大排列
row的存储是通过链式结构来连接
Page Directory
由于底层的 row 的存储是以链式的结构来连接的,如果所有的数据都通过这种方式来连接,这样会使得数据的查找变得相当缓慢。为了提高查找的速度,在 MySQL 中将会通过 Page Directory 来将记录进行分组,每个组对应一个 solt,查找时首先通过定位到对应的 solt,然后再去按照链表的顺序进行遍历查找,从而提升了查找的速度
具体的结构如下图所示:
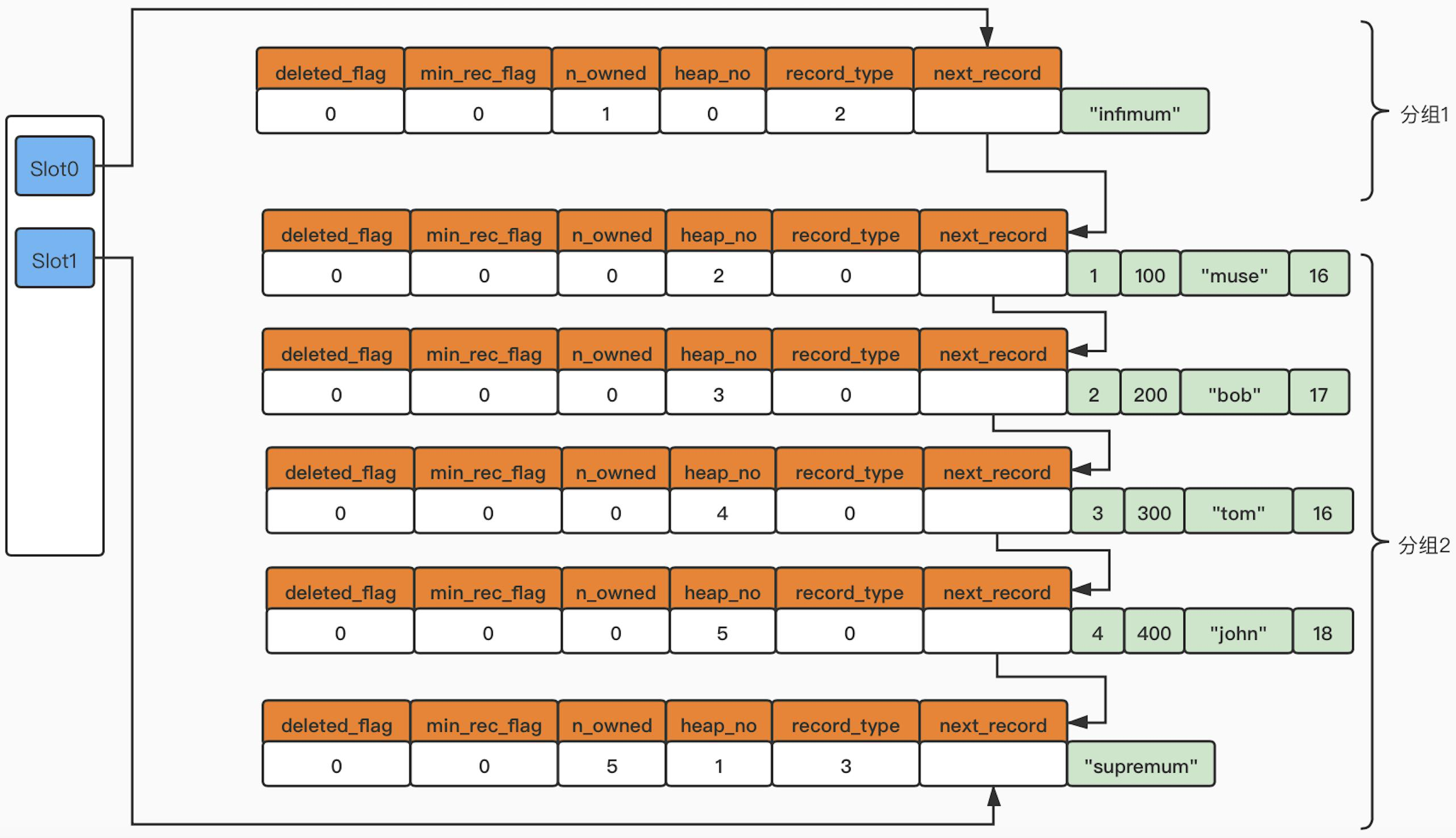
分组的规则:
- 对于
Infimum记录,组内只能有一条记录,即Infimum记录本身 - 对于
Supremum记录,组内只能有 1 ~ 8 条记录 - 对于其它的记录,组内只能有 4 ~ 8 条记录
分组的步骤:
- 首先,最初的时候,没有记录,此时数据页中只有两个组:
Infimum和Supremum,此时每个组中都只有一条记录 - 之后再插入数据,会将数据插入到
Supremum对应的组中 - 当插入的数据使得
Supremum对应的组达到上限,此时就会使得组分裂,申请新的solt,指向插入组中的主键最大的记录
记录的删除
为了提高系统的性能,在删除记录时不会直接删除数据,而是在 Page 中执行以下步骤:
- 找到要删除的记录,将当前记录的
deleted_flag标记位置为 1,表示该记录已经被删除 - 修改上一条记录的
next_record指针,使得它指向当前数据的下一条记录 (由于Infimum和Supremum记录的存储,任意一条记录的前后记录都不会为空,保证了稳定性) - 之后,需要修改对应的组中持有
n_owner值的记录,将这个组中的n_owner的值 -1
由于删除时并没有立刻直接将记录所在的内存给释放,因此如果之后再有新的数据插入时,对于满足条件的记录将会复用当前删除的记录所在的内存空间,再修改相关联的属性,这样就避免了由于频繁地申请和释放空间而带来的时间消耗
记录的插入
正常情况下,如果当前的 Page 能够容纳插入的数据,那么就会直接将数据放入的当前的 Page 中,然后修改相关联的指针、n_owner 、分组等数据
如果插入的数据在当前页没有足够的空间能够容纳它,那么将会首先申请一个新的 Page,然后将当前页中主键最大的记录提取到新申请的页中,再将新的数据插入到当前处理的 Page 中,最终需要保证数据在这两个页中依旧是按照主键的顺序从小到大排序的。
结合这一点,在设计表时建议使用自增的字段作为主键,这样就能够避免由于在两个页之间移动记录所带来的开销
索引
在单个 Page 中查找数据较为简单,也比较快,但是当查找的数据量很大时,将会在多个 Page 中查找数据,此时如果再按照顺序查找的方式进行查找,那么效率将会十分低下。为了提高查找的效率,引入索引来加快查找的速度。
一般来讲,数据库管理系统中一般存在两种索引:Hash 索引和 B 树索引,由于 Hash 索引在 MySQL 的高版本的引擎中已经不再使用了,因此在这里不做介绍。当下最为流行的是使用 B+ 树作为索引结构
B+ 树索引
B- 树和 B+ 树是数据结构相关的内容,在此不做过多的介绍,感兴趣的可以参考:https://www.cnblogs.com/nullzx/p/8729425.html
一个使用 B+ 树索引的表的存储结构如下:
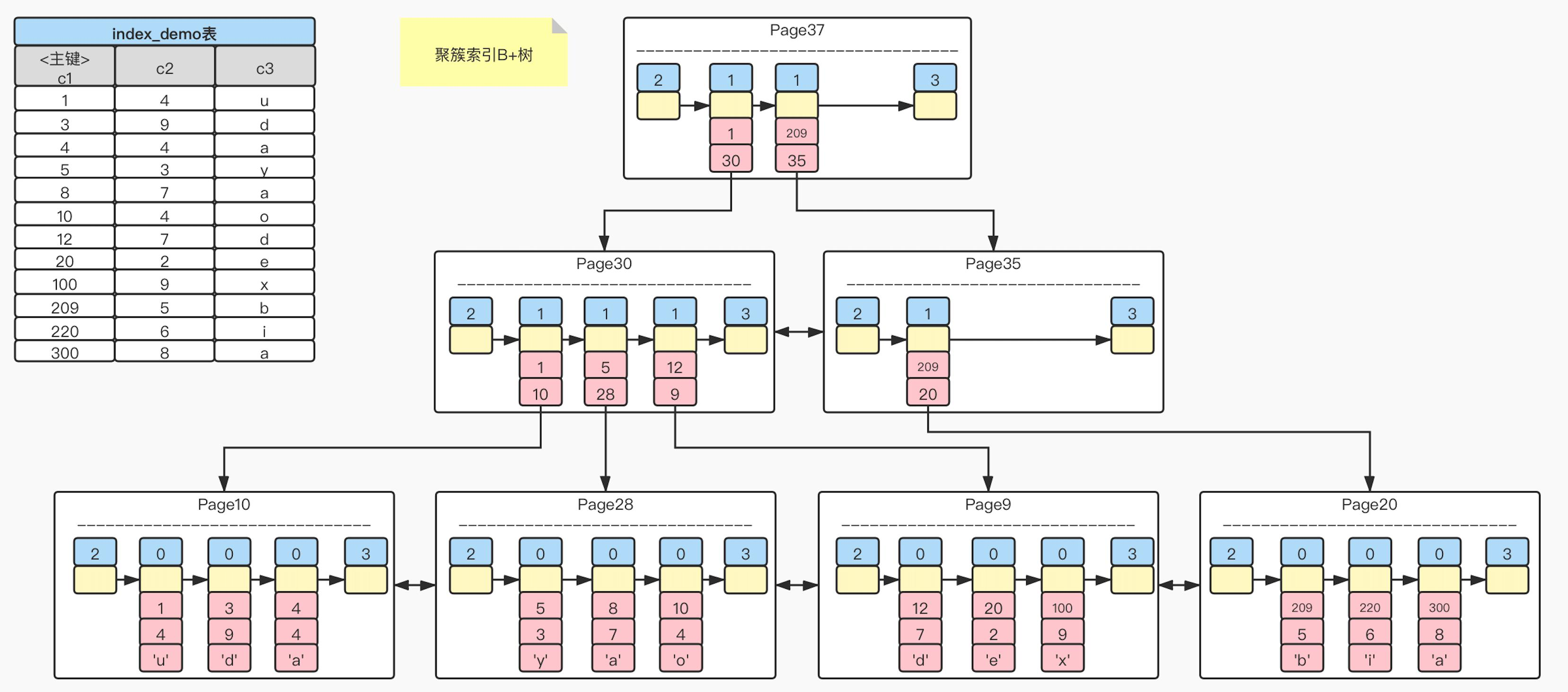
在图中,蓝色的部分表示记录所属的类型,回忆一下上文提到的关于 row 的 record_type 属性,0 表示普通数据,1 表示索引节点,2 表示 Infimum 记录,3 表示 Superemum 记录。图中 Page 37 、Page 30、Page 35 都是索引类型的 Page,这些 Page 与 B+ 树中的节点相对应,通过 B+ 树的索引节点,能够显著地加快查找的速度。
二级索引(非主键)
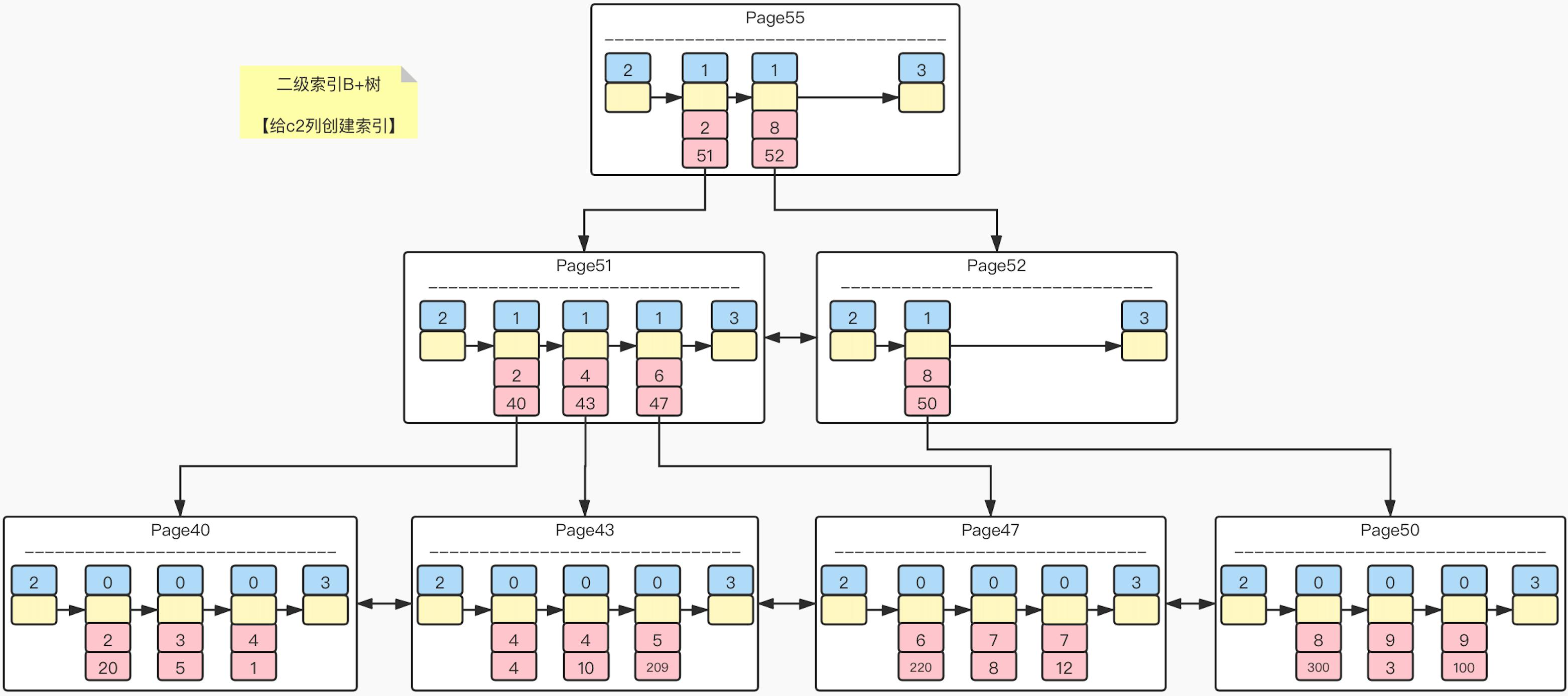
所谓二级索引,就是给非主键的列加上对应的索引,为了能够提高可用性,会在 B+ 树的叶子节点中加上记录对应的主键,以 “索引列 + 主键” 的形式存在,这样就能够通过主键执行 “回表” 查询。
依旧以上文图中的 index_demo 表中的数据为例,现在单独对 c2 列建立索引,此时的存储情况如下所示:
联合索引(多列)
默认情况下,在为单独的一列(非主键)加上索引时,只会为该列对应的叶子节点添加附属的主键的数据,这是为了节约内存而作出的选择。但是有时候可能为了加快搜索速度,并不希望再通过主键进行 “回表” 查询去获取另一列的数据,在这种情况下,可以考虑将额外的一列作为附属列添加到要添加索引的列中,这种索引也被成为 “联合索引”
“联合索引” 只是单纯地加上附属列的数据,附属列本身不具备索引,但是在底层排序时也会将附属列作为参考条件进行排序(优先级低于索引列),这也就是为什么联合索引走的是 “最左原则” 的原因
依旧以上文中的 index_demo 为例,现在同时对 c2 和 c3 加上联合索引,此时的索引结构如下图所示:
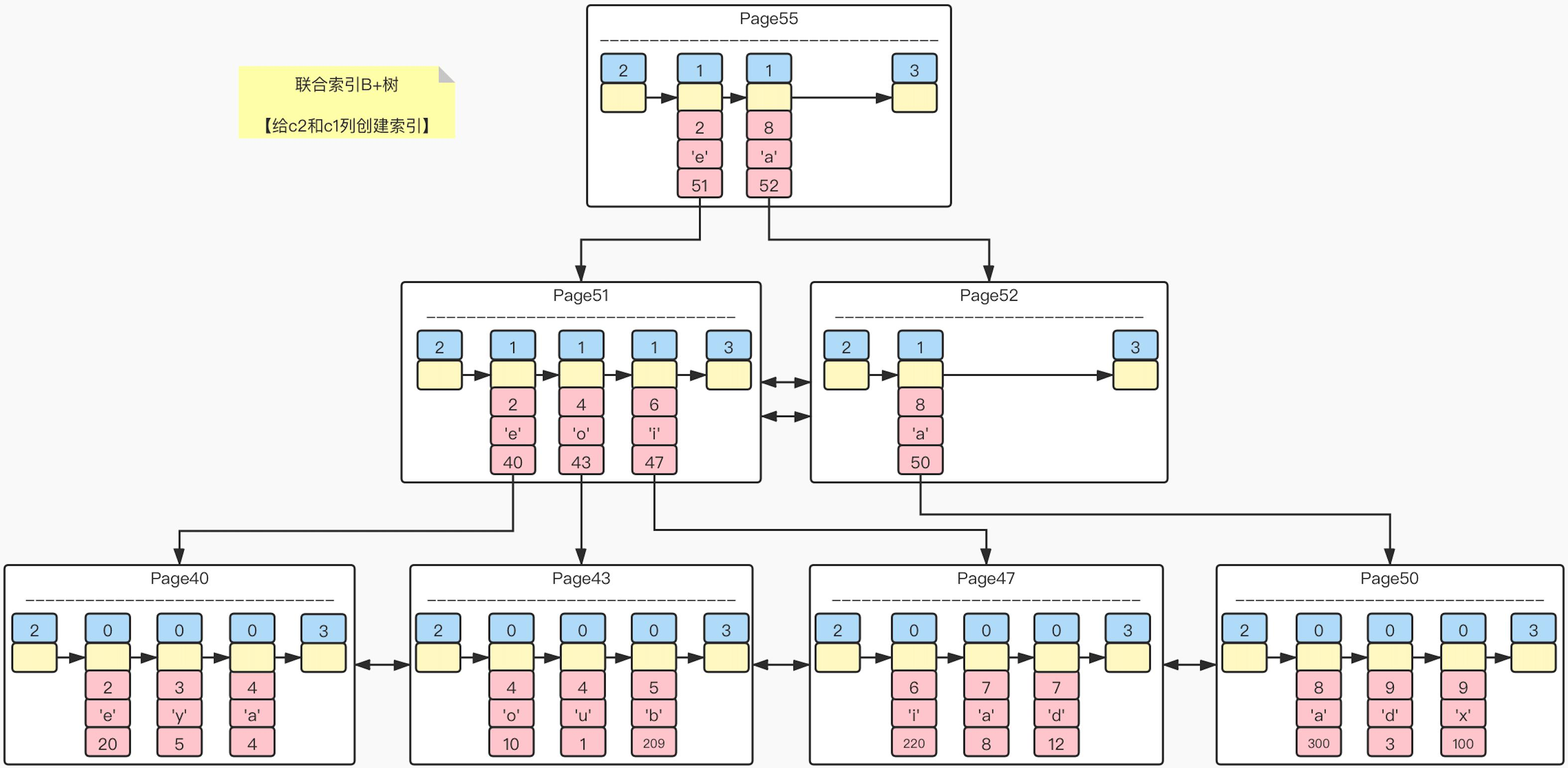
从图中可以看到,只有对 c2 列的数据进行查找时,才能通过索引来查找数据,单独通过 c3 是无法通过 “联合索引” 来查找的
目录项记录的唯一性
当创建的二级索引含有大量的相同的数据时,此时对于索引页来讲无法单独通过该索引列来继续进行向下的查找的。为了解决这个问题,MySQL 针对这种情况,将会在索引页中加上对应的主键属性,这样就能够结合主键来得到 “唯一性” 的保证
Buffer Pool
由于磁盘的 IO 处理速度要远小于计算机的处理速度,因此如果直接同磁盘进行 IO 的操作将会成为性能的瓶颈,为了提高处理的速度,MySQL 通过引入 Buffer Pool 作为和磁盘之间交互的缓冲区,大部分的操作将直接在缓冲区中完成,在一定的时间间隔后开启一个线程将数据冲刷到磁盘上,以此来提高数据库的整体性能
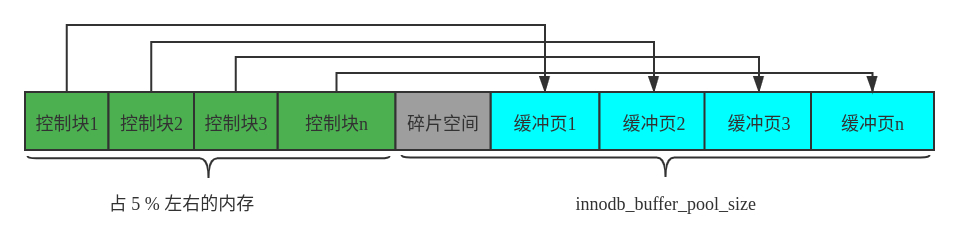
Buffer Pool 的基本结构如下图所示:
具体介绍:
- 整个内存区间是一块连续的内存区间,每个控制块对应着管理的缓冲页。
innodb_buffer_pool_size不包含控制块区域的大小,因此一般情况下申请的空间会大于innodb_buffer_pool_size指定的大小innodb_buffer_pool_size默认大小为 128 MB,可以通过在/etc/my.cnf文件中进行配置- 通过 Hash 表来判断数据库中的页是否加载到缓冲区,其中,Hash 表的 key 为 “表空间 + 页号”,value 为缓冲区中的控制块
free 链表
free 链表用于维护控制块,具体的结构如下图所示:
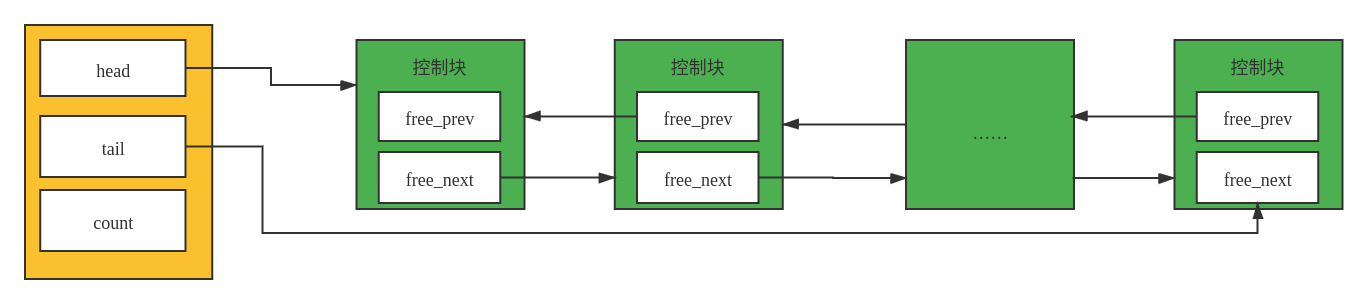
黄色区域表示的是及基节点,用于维护链表的头节点和尾节点,绿色部分表示链表中实际的控制块。
flush 链表
用于将在内存中的 Page 写回到磁盘中,具体的结构如下图所示:

该链表的作用是维护脏页对应的控制块,在某个时刻再将它们写回到磁盘中,具体的写入方式如下:
- 从 flush 链表中刷新一部分页面到磁盘,这是通过后台线程来实现的,
- 根据系统的繁忙程度来确定刷新的速度(BUFFER_FLUSH_LIST)。
- 系统很繁忙的情况下,会使得刷新脏页到磁盘的速度会很慢,可能会导致这么一种情况:当读取不在缓冲区中的数据页时,由于当前缓冲区的所有页都是脏页,将会导致无法将磁盘中的页读到缓冲区中。在这种情况下,将会去查看
LRU链表的尾部,检测是否存在可以直接释放的未修改的缓冲页;如果没有,将不得不将LRU链表尾部的一个脏页同步刷新到磁盘中。(BUFFER_FLUSH_SINGLE_PAGE)
- 从
LRU链表的冷数据汇总刷新一部分页到磁盘(BUFFER_FLUSH_LRU)
LRU 链表
这是一种在计算机系统中常用的处理链表,在 MySQL 中具体的结构如下:
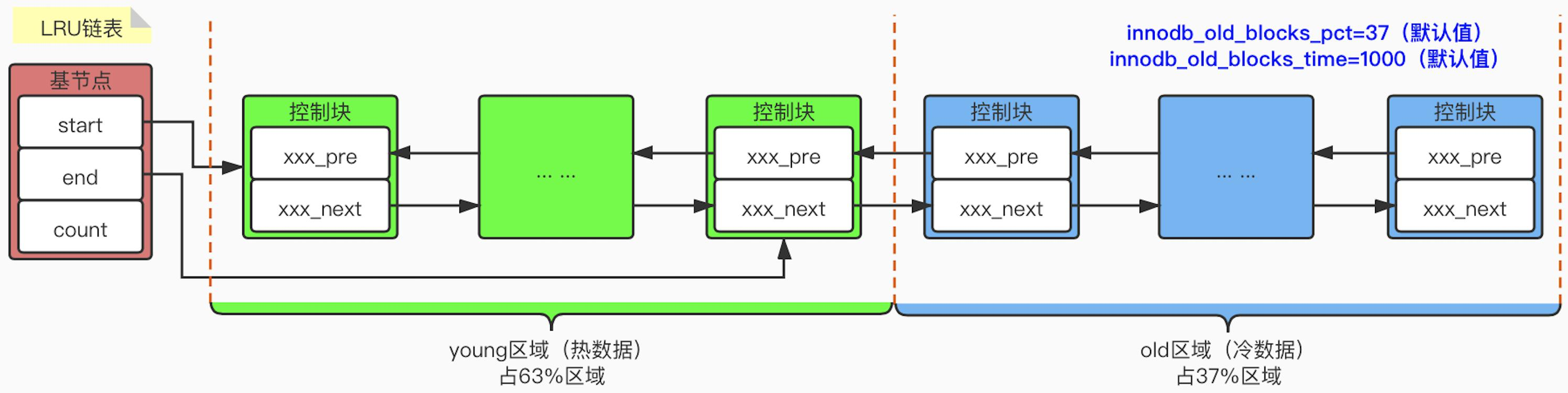
young 区表示最近频繁被访问的数据,也被称为热数据,由于经常被访问,因此它们存在的时间要比较长;而 old 区则表示很少被访问的页,也被称为冷数据,当需要释放内存时,将会首先释放 old 区的数据。
在 MySQL 中的 InnoDB 中,使用 LRU 链表会存在以下的一些问题:
- 预读问题
InnoDB认为对于当前页的读取,对于当前读取页之后的页,认为在查询该页周围的页,也是你将要读取的页。因此它会把当前读取页周围的一些页一并加载到缓冲池中,导致一部分缓冲池内的页失效。- 预读分为两种:线性预读和随机预读
- 线性预读:表空间—> 区(64个页) —> 页,当线性访问超过一定的阈值时,就会执行线性预读
- 随机预读:默认不开启,只要连续读取超过一定阈值,就会读取整个区的页。
- 解决方案
- 当页从磁盘中加载时,将加载的页放入冷数据区域。通过适当增大冷数据区的大小可以有效解决该问题。
- 设置冷数据区比例的参数:
innodb_old_blocks_pct(默认 37)
- 全表查询导致缓冲页失效
- 由于未加上查询条件,或者未命中索引,将会导致全表扫描,直接将整个表的页全部读取到缓冲池中,使得整个缓冲池中的页失效
- 解决方案
- 在从磁盘加载页到冷数据区之后,通过设置一个时间阈值,只有在该页上访问超过这个时间阈值时才能进入热数据区。
- 设置时间阈值的参数:
innodb_old_blocks_time(默认为 1000 ms)
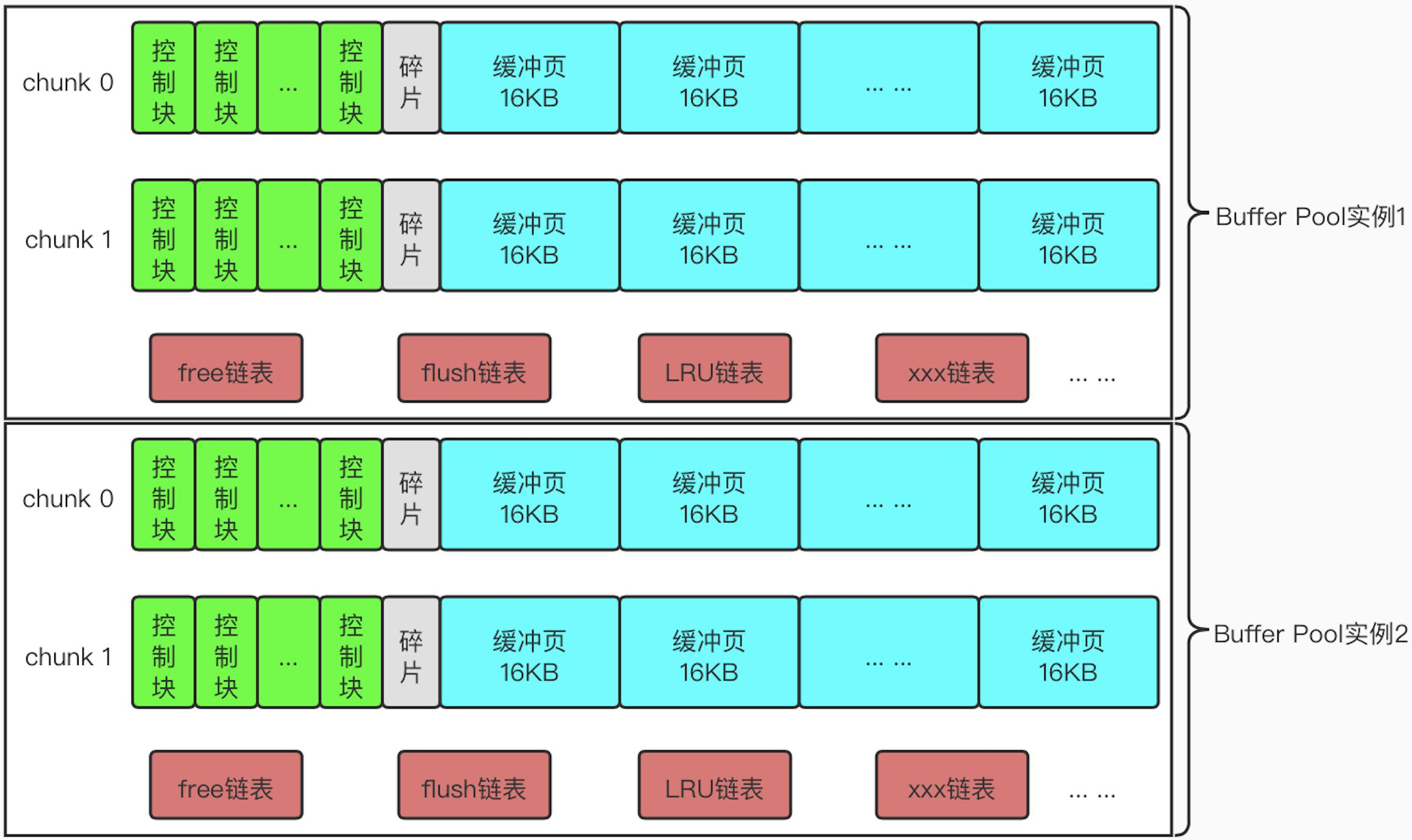
Chunk
由于多个线程的访问,可能会由于加锁的原因导致性能的下降,因此可以将 Buffer Pool 设置为多个实例
Chunk 的作用是为了细化 Buffer Pool,优化 Buffer Pool(因为较小连续的内存空间要比较大的连续内存空间更加容易分配)
引入 Chunk 后,最终内存中的数据组成结构如下所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号