Spring Batch 的基本使用
简介
A lightweight, comprehensive batch framework designed to enable the development of robust batch applications vital for the daily operations of enterprise systems.
Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advanced technical services and features that will enable extremely high-volume and high performance batch jobs through optimization and partitioning techniques. Simple as well as complex, high-volume batch jobs can leverage the framework in a highly scalable manner to process significant volumes of information.
大体翻译如下:
一个轻量的、广泛的批处理框架,该框架的设计目的是为了支持对企业系统日常运营至关重要的批处理应用程序的开发。
Spring Batch 提供了在处理大量记录时必需的可复用功能,包括日志记录/跟踪、事务管理、任务处理统计、任务重启、任务跳过和资源管理。它也提供了更加高级的技术服务和特征,通过优化和分区的方式获得极高容量和高性能的批处理任务。简单和复杂的大容量批处理任务都可以以高度可扩展的方式利用该框架来处理大量的信息
处理架构
Spring Batch 的处理结构如下所示:
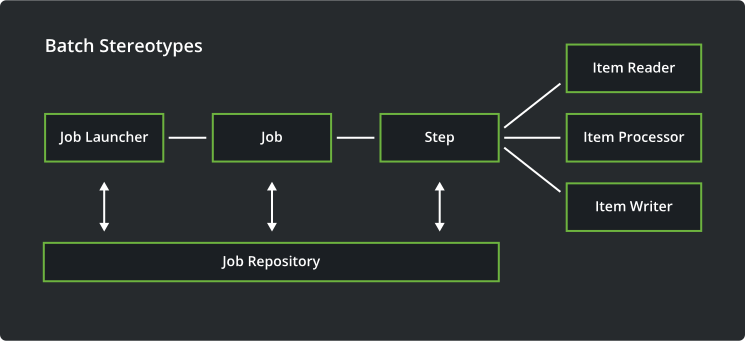
其中,任务的处理是在 Step 这个阶段定义的。在 Step 中,需要定义数据的读取、数据的处理、数据的写出操作,在这三个阶段中,数据的处理是真正进行数据处理的地方。具体 Step 的流程如下图所示:
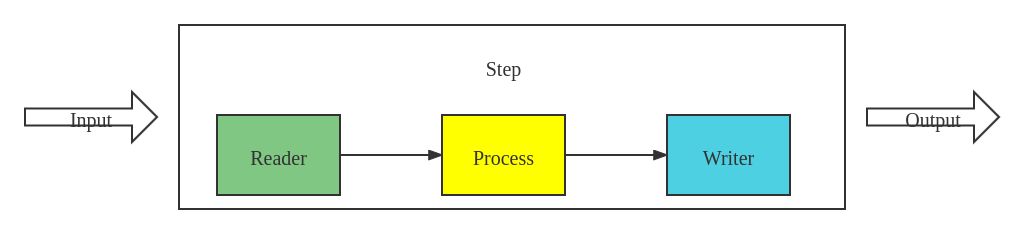
Reader(架构图中的Item Reader):主要的任务是定义数据的读取操作,包括读取文件的位置、对读取首先要进行的划分(如以 ',' 作为分隔符)、将读取到的文件映射到相关对象的属性字段等Process(架构图中的Item Processor):这里是真正对数据进行处理的地方,数据的处理逻辑都在这里定义Writer(架构图中的Item Writer):这个阶段的主要任务是定义数据的输出操作,包括将数据写入到数据库等
使用前的准备
在使用 Spring Batch 之前,首先需要创建 Spring Batch 需要的元数据表和它需要使用的元数据类型,这些可以在数据库中进行定义,这些元数据表和元数据类型是和 Spring Batch 中的域对象紧密相关的。
元数据表
元数据表的关联关系如下所示:
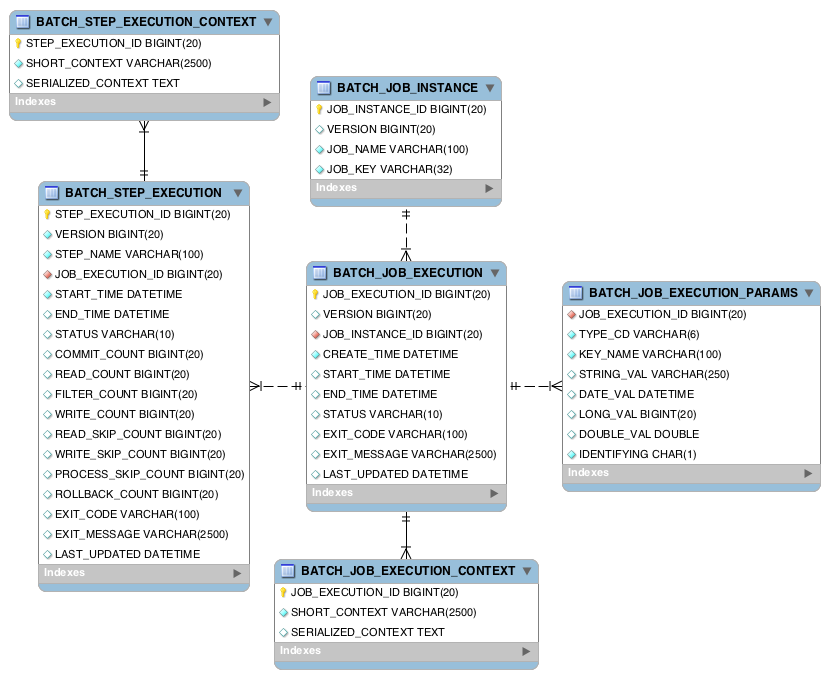
相关的表解释如下:
BATCH_JOB_INSTANCE:与这个表相对应的是JobInstance域对象,这个域对象是整个层次结构的顶层,表示具体的任务BATCH_JOB_EXECUTION_PARAMS:与这个表对应的是JobParameters域对象,它包含了 0 个或多个 key-value 键值对,作为每次运行任务时使用的参数,通过JobParameters对象和Job对象,可以得到唯一确定的JobInstance实例BATCH_JOB_EXECUTION:与这个表对应的是JobExecution域对象,每次运行一个任务时,都会创建一个新的JobExecution对象BATCH_STEP_EXECUTION:与这个表对应的是StepExecution对象,这个对象与JobExecution类似,与JobExecution相关联的地方在于一个JobExecution可以有多个StepExecutionBATCH_JOB_EXECUTION_CONTEXT:这个表存储的是每个Job的执行上下文信息BATCH_STEP_EXECUTION_CONTEXT:这个表存储的是每个Job中每个Step的执行上下文信息
元数据类型
BATCH_JOB_INSTANCE、BATCH_JOB_EXECUTION、BATCH_STEP_EXECUTION 这三个表都包含了以 _ID 结尾的列,这个列会作为它们所在表的实际主键。然而,这个列不是由数据库产生的,而是由单独的序列来产生的,这是因为:在插入数据之后,需要在插入的数据上设置给定的键,这样才能确保它们在 Java 应用中的唯一性。尽管较新的 JDBC 支持主键自增,但是为了能够更好地兼容,因此还是有必要为这三个数据表设置对应的序列类型。
定义元数据类型的 SQL 如下:
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_SEQ;
由于有的数据库(如MySQL)不支持 SEQUENCE 这种类型,一般的做法是创建一个表来代理 SEQUENCE:
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (ID BIGINT NOT NULL) ENGINE = InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (ID BIGINT NOT NULL) ENGINE =InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_SEQ (ID BIGINT NOT NULL) ENGINE = InnoDB;
INSERT INTO BATCH_JOB_SEQ values(0);
最终创建元数据表和元数据类型的 SQL 脚本如下:
PostgreSQL:https://raw.githubusercontent.com/LiuXianghai-coder/Test-Repo/master/SQL/batch_postgresql_meta.sql
MySQL:https://raw.githubusercontent.com/LiuXianghai-coder/Test-Repo/master/SQL/batch_mysql_meta.sql
开始使用
在这个例子中,需要实现的功能为:从一个文件中批量地读取数据,将这些数据进行相应的转换(小写字母变大写),再将它们写入到数据库中。
对应的数据文本如下(sample-data.csv):
Jill,Doe
Joe,Doe
Justin,Doe
Jane,Doe
John,Doe
创建实体类
首先,创建处理的数据对应的实体和关联的数据表,如下所示:
// 与数据
public class Person {
private final String lastName;
private final String firstName;
public Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
// 省略一部分 getter 方法
}
对应的实体表如下所示:
-- 以 PostgreSQL 为例
CREATE TABLE people
(
person_id SERIAL8 NOT NULL PRIMARY KEY,
first_name VARCHAR(20),
last_name VARCHAR(20)
);
处理的核心逻辑
接下来,需要定义对于每条数据的处理逻辑,处理逻辑对应的类需要实现 org.springframework.batch.item.ItemProcessor<I, O> 接口,其中,I 范型表示要处理的实体类类型,O表示经过处理之后返回的结果类型。由于这里只是对 Peroson 类的名和姓进行大写的转换,因此输入类型和输出类型都是 Person
具体的处理逻辑如下:
import org.springframework.batch.item.ItemProcessor;
/*
处理数据的逻辑类,对应架构中的 Item Processor 部分
*/
public class PersonItemProcessor implements ItemProcessor<Person, Person> {
@Override
public Person process(Person person) {
final String firstName = person.getFirstName().toUpperCase();
final String lastName = person.getLastName().toUpperCase();
// 可以在这个处理逻辑中定义一些其它的操作。。。。。。。。。
return new Person(firstName, lastName);
}
}
数据的读取
有了处理的核心逻辑部分之后,剩下的重要部分就是数据的输入和输出了,正如上文所描述的那样,输入部分定义了数据的来源、对初始数据进行处理等任务。
数据的读取部分如下所示:
@Bean(name = "reader") // 可以把这个 Bean 放在任意的一个配置类或组件类中
/*
由于读取的数据来源是来自一般的文件,因此采用 FlatFileItemReader 的实现类;
其它的实现类可以查看 org.springframework.batch.item.ItemReader 的实现类
*/
public FlatFileItemReader<Person> reader() {
return new FlatFileItemReaderBuilder<Person>() // 以构建者模式的方式构建新的 FlatFileItemReader 对象
.name("personItemReader")
.resource(new ClassPathResource("sample-data.csv")) // 读取数据的来源,这里表示在类路径的 resourcec 目录下的 sample-data.csv 文件
.delimited().delimiter(",") // 指定每行的数据字段的分割符为 ,
.names("firstName", "lastName") // 将分割的字段映射到 firstName 和 lastName 属性字段
.fieldSetMapper(new BeanWrapperFieldSetMapper<>() {{
setTargetType(Person.class);
}}) // 这些分割的属性字段对应的类,使用 {{}} 的方式来将初始化的 BeanWrapperFieldSetMapper 调用 setTargetType 方法,可能是一个比较简洁的方式,但这种方式可能会导致内存泄漏
.build(); // 通过设置的属性构造 FlatFileItemReader 对象
}
数据的写出
数据的写出部分如下所示:
@Bean(name = "writer")
/*
由于这里的写出是写入的数据库中,因此采用 JdbcBatchItemWriter 的实现类进行写出;
其它的实现类可以查看 org.springframework.batch.item.ItemWriter 的实现类
*/
public JdbcBatchItemWriter<Person> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Person>() // 以构建者模式的方式创建 JdbcBatchItemWriter 实例对象
.itemSqlParameterSourceProvider(
new BeanPropertyItemSqlParameterSourceProvider<Person>() // 提供执行相关 SQL 需要的参数,这里以实体类(输出类)的方式存储需要的参数
)
.sql("INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)") // 写入数据库中具体执行的 SQL
.dataSource(dataSource) // 设置数据源,这个对象可以手动创建,但是一般在配置相关的 datasource 属性之后,Spring 会自动生成这个类型的 Bean
.build();
}
整合到 Step
上文介绍过,一个 Step 包含了数据的读取、数据的处理、数据的写出三个部分,而一个批处理任务可以由多个 Step来组成。现在,需要做的是将上文提到的写入、处理、写出三个部分组合成为一个 Step
具体代码如下所示:
@Bean(name = "step1") // Step 也是一个 Bean,这里将它命名为 step1
// Step 类是批处理任务的执行单元
public Step step1(JdbcBatchItemWriter<Person> writer) {
return stepBuilderFactory // 由 Spring 容器自行注入;注意这里使用的工厂模式
.get("step1") // 创建一个会创建名为 step1 的 StepBuilder 对象;注意这里的构建者模式的使用
.<Person, Person>chunk(10) // 这个 Step 一次处理的数据的数量,前缀 <I, O> 范型表示的含义与 Item Process 中的一致,因此这里两个范型都设置为 Person
.reader(reader()) // 数据的读取部分
.processor(processor()) // 数据的处理部分
.writer(writer) // 写出部分,由于 writer 需要注入 DataSurce 对象,因此直接作为一个注入参数参数并使用会更加方便;当然,reader 和 process 也可以通过注入参数的方式直接使用,因为它们都被定义成了 Spring 中的 Bean
.build();
}
任务执行监听器
如果想要在任务执行前或者任务执行之后做一些相关的处理操作,那么设置对应的任务执行监听器会很有用。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Component;
@Component
public class JobCompletionNotificationListener implements JobExecutionListener {
// 日志打印对象
private final static Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override // 执行任务之前的一些操作
public void beforeJob(JobExecution jobExecution) {
log.info("Ready to execution job.......");
}
@Override // 在任务执行完成之后执行的一些操作,这里是执行完成之后查询写入到数据库中的结果
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED! Time to verify the results");
jdbcTemplate.query("SELECT first_name, last_name FROM people",
(rs, rowNum) -> new Person(rs.getString(1), rs.getString(2))
).forEach(person -> log.info("Found <" + person.toString() + "> in the database."));
}
}
}
创建 Job
批处理的最顶层的抽象便是 Job,Job 是一个批处理任务,现在整合上文的内容,创建一个 Job
@Bean(name = "importUserJob")
public Job importUserJob(JobCompletionNotificationListener listener, Step step1) {
return jobBuilderFactory // 这个工厂对象是由 Spring 自动注入的;同样地,使用的是工厂模式
.get("importUserJob") // 创建一个会创建 importUserJob 任务的 JobBuilder 对象;构建者模式
.incrementer(new RunIdIncrementer()) // 增加这个 Job 的参数信息,具体可以参见 Spring Batch 的元数据信息
.listener(listener) // 添加之前创建的任务执行监听器,使得在任务开始和结束时执行相应的操作
.flow(step1) // 添加上文定义的 step1 处理
.end() // 任务结束
.build();
}
如果想要添加多个 Step,那么可以按照下面的方式进行添加:
@Bean(name = "importUserJob")
public Job importUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory
.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.start(step1) // 定义的 step1
.next(step2) // 定义的 step2
.build();
}
值得注意的是,由于上文定义的任务执行监听器监听的是任务(即 Job) 的状态,因此当添加多个 Step 时,只有在完成最后的 Step 之后才会触发这个事件监听。
启动批处理任务
如果想要启动批处理任务,首先需要创建一个配置类,如下所示:
mport org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.Resource;
@Configuration
@EnableBatchProcessing // 使得能够开启批处理任务处理,这样 JobBuilderFactory 才能够被 Spring 注入
public class TestConfiguration {
private final JobBuilderFactory jobBuilderFactory;
@Resource(name = "step1")
private Step step1;
@Resource(name = "step2")
private Step step2;
public TestConfiguration(JobBuilderFactory jobBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
}
@Bean(name = "importUserJob") // 具体的任务 Bean,这个 Bean 会在 Spring 容器启动的时候进行加载,因此任务也会执行
public Job importUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory
.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.start(step1)
.next(step2)
.build();
}
}
除了在配置类中加上 @EnableBatchProcessing 开启批处理任务之外,在配置文件 application.yml 文件中也需要做相应的配置:
spring:
batch:
job:
enabled: true # 使得能够开启批处理任务
现在,启动 Spring 应用程序(可以使用 SpringApplication.run() 方法来启动),你会发现正在进行批处理任务:

任务执行完成之后,查看数据库的写入内容:

可以发现,处理过的数据已经成功写入到数据库中了
查看执行的日志,可能如下所示:

以上就是有关 Spring Batch 的一些基本使用,希望它可以帮到你
项目地址:https://github.com/LiuXianghai-coder/Spring-Study/tree/master/spring-batch
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号