伪共享
非标准定义:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就被称之为伪共享。
CPU 缓存
在计算机系统中,CPU 高速缓存(CPU Cache)是用于减少处理器访问内存所需的平均时间的部件。在金字塔式存储结构中位于自顶向下的第二层,仅次于 CPU 寄存器。其容量远远小于内存,但是速度却可以接近处理器的频率。
金字塔式存储结构:
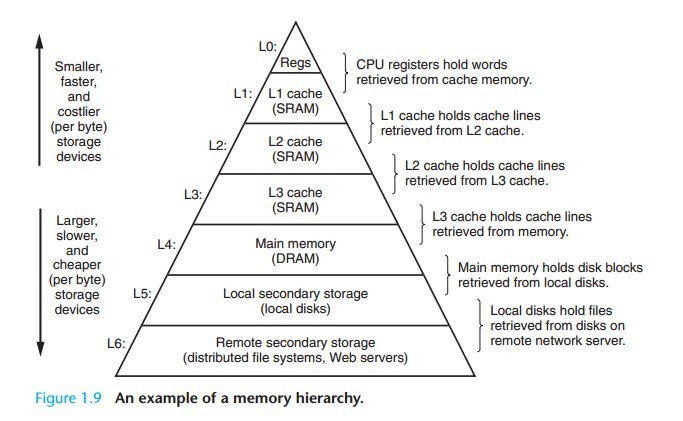
按照读取顺序和 CPU 结合的紧密程度,CPU 缓存可以分为一级缓存、二级缓存、部分高端 CPU 还有三级缓存。每一级缓存的数据都是下一级缓存的一部分,越靠近CPU 的缓存访问速度越快并且容量也越小。
当 CPU 执行运算的时候,将会首先去一级缓存查找数据,然后再去二级、三级。如果缓存中没有数据,那么所需要的数据将会从内存中获取。
MESI 协议和 RFO 请求
在 CPU 中,每个核都有自己的一级、二级缓存,因此如果当另一个核的线程想要访问当前核的缓存行数据,将会变得比较慢。为了解决这个问题,CPU 在设计的时候,将 CPU 的核缓存整个发送到另一个核心,减少了数据的传输。
MESI 协议
M(Modified):本地处理器已经修改缓存行,即已经成为了脏行。它的内容和内存中的内容不一样,并且该已经修改的缓存只有在当前核才有
E(Exclusive):缓存行内容和内容中的一样,而且其它核都没有这行数据
S(Shared):缓存行内容和内存中的一样,有可能其它处理器也存在此缓存行的拷贝
I(Invalid):当前的缓存行失效,不能再使用
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S 共享 (Shared) | 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 该Cache line无效。 | 无 |
对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
状态之间的转换
初始状态:缓存行没有加载任何数据,所以它处于 I 状态
本地写(Local Write):如果本地处理器写数据至 I 状态的缓存行,则缓存行的状态变为 M
本地读(Local Read):如果本地处理器读取处于 I 状态的缓存行,很明显此缓存行没有数据可读。
此时分为两种情况:
(1)其它处理器的缓存里也没有此行数据,则从内存中加载数据到此缓存行之后,再将它设置为 E 状态
(2)其它处理器的缓存有此行数据,则将此缓存行的状态设置为 S 状态。(如果处理 M 状态的缓存行。再由本地处理器写入/读 出,状态是不会发生改变的)
远程读(Remote Read):对于两个处理器
C1和C2,如果C2需要读取另外一个处理器C1的内容,C1需要把它的缓存行的内容通过内存控制器 (Memory Controller) 发送给C2,C2在接受到缓存行之后将对应的状态设置为 S。在设置之前,内存也会从总线上得到这份数 据远程写(Remote Write):
C2在得到C1的数据之后,不是为了读,而是为了写。这种写也算作本地写。由于此时C1也存在这份缓存数据,因此在C2写 入之后将会变为脏数据。为了解决这个问题,C2将发送一个 RFO (Request For Owner)请求,它需要拥有这行数据的权限, 其它处理器等相应缓存设置为 I,除了它自己,谁也不能动这行数据。这保证了数据的安全,同时处理 RFO 请求以及设置 I 的过 程将给写操作带来很大的性能消耗。
转换图:

RFO
发送 RFO 的情况:
- 当线程的工作从一个处理器转移到另一个处理器,它操作的所有缓存行都需要移动到新的处理器上。如果此后再写缓存行,则此缓存行在不同核上有多个拷贝,此时就需要发送 RFO 请求了
- 两个不同的核需要操作相同的缓存行,此时也需要发送 RFO 请求
缓存行
在缓存系统中,数据是以缓存行为单位进行存储的。一般来讲,一个缓存行的大小通常是 64 位,并且有效地引用主内存中的一块地址。以 Java 为例,一个 long 的长整形基本数据类型是 8 个字节,因此在一个缓存行中可以存储 8 个 long 类型的变量。如果当前访问的是一个 long 类型的数组,由于数组的内存空间是连续的,因此当数组中的一个值被加载到缓存中时,也会额外加载另外7个,因此能够非常快速地访问这个数组。然而,如果访问的数据结构的内存空间不是连续的,将无法得到由于缓存带来的优势。
伪共享问题
假设现在在两个核中现在存在相同的缓存行(缓存行中的数据以上文的 long 数组为例),但是这两个核中的线程会操作这个缓存行中不同位置的数据,此时的情况如下图所示:
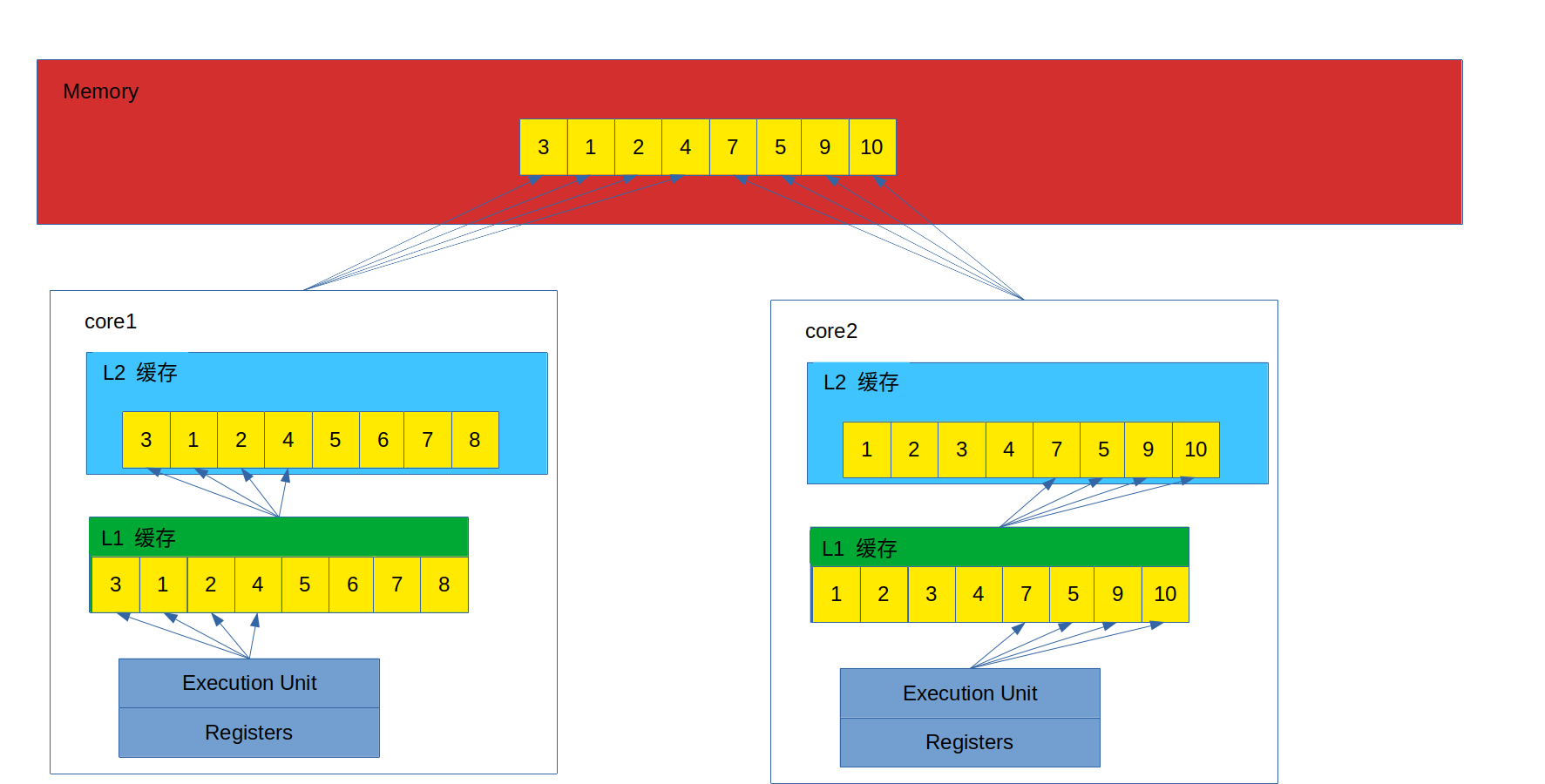
现在,core1 想要更新索引 [0, 3] 中的数值,而 core2 想要更新索引 [4, 7] 之间的元素。然而,由于两个核修改的变量都在同一个缓存行上,因此这两个线程之间就会轮番地发送 RFO 消息,以使得自己享有此缓存行的所有权。当 core1 获得缓存行的所有权开始更新 [0, 3] 之间的元素,此时 core2 对应的缓存行需要设置为 I 状态;当 core2取得了所有权开始更新索引为 [4, 7] 之间的元素时,需要将 core1 的缓存行置为 I 状态。
不仅仅是由于轮番夺取所有权带来的大量 RFO 消息影响性能,而且由于某个线程需要读取此缓存行数据时,L1、L2 上的数据都是失效的数据,这就使得只能去内存中加载数据了。
伪共享示例
public class Application implements Runnable {
private static final int CORE_NUM = Runtime.getRuntime().availableProcessors();
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public static long SUM_TIME = 0L;
public Application(int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public final static class VolatileLong {
public long value = 0L;
public long p1, p2, p3, p4, p5, p6, p7; // 填充缓存行
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[CORE_NUM];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new Application(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
@Override
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public static void main(String[] args) throws InterruptedException {
Thread.sleep(10000);
for(int j=0; j < 10; j++){
System.out.println(j);
longs = new VolatileLong[CORE_NUM];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.nanoTime();
runTest();
final long end = System.nanoTime();
SUM_TIME += end - start;
}
System.out.println("平均耗时:"+SUM_TIME/10);
}
}
结果分析:
- 在去掉
VolatileLong填充的缓存数据后,执行的平均耗时为:419543020nanos - 在填充
VolatileLong的缓存数据后,执行的平均耗时为:295805484nanos
两者相差了接近 1.5 倍
避免伪共享
就像上文的示例,只要避免每个线程写入数据的对象不在同一个缓存行中就可以避免伪共享,上文的 VolatileLong 的 p1、p2、p3……p7 都是为了填充缓存行,使得每个数据写入都不在同一个缓存行而存在的。
对于 Java 来讲,由于编译器的优化,可能会使得补齐的数据在编译期间被丢弃,因此需要添加对应的方法使用这些字段,使得这些填充的数据不会被编译器优化掉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号