获取全世界所有国家的中文名称和英文名称
获取全世界所有国家的名称
一. 文本解析
首先有一个在线的文本数据,里面包含了世界上所有国家,只不过是txt文本,格式类似于JSON
https://wuliu.taobao.com/user/output_address.do?range=country
将数据复制粘贴到txt文件中,然后开始解析
import lombok.extern.slf4j.Slf4j;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
/**
* create by fzg
* 2022/11/17 13:45
*/
@Slf4j
public class CountryCity {
public static void main(String[] args) {
log.info(getWorldAllCountrys().toString());
ArrayList<HashMap<String, Object>> list = getWorldAllCountrys();
}
/**
* 获取世界上所有国家中文名字和英文名
* @return
*/
public static ArrayList<HashMap<String,Object>> getWorldAllCountrys(){
// 文件位置
String countryUrl = "E:\\学习\\项目\\vue-vant-app\\myBlog\\myCaveolae_server\\src\\main\\java\\com\\fzg\\common\\demo\\country\\country.txt";
File file = new File(countryUrl);
BufferedReader bf;
String data = "";
try {
bf = new BufferedReader(new FileReader(file));
data = bf.readLine();
} catch (FileNotFoundException e) {
e.printStackTrace();
log.info("文件未找到");
} catch (IOException e) {
e.printStackTrace();
log.info("文件读取失败");
}
if (data.equals("")){
log.info("文件内容为空");
}else {
log.info("文件读取成功");
log.info(data);
// 去掉大括号以及前面的字符,以及最后面的大括号以及分号
String rData = data.substring(data.indexOf("{") + 1 , data.lastIndexOf("}"));
log.info(rData);
log.info(rData.indexOf("[") + "");
log.info(rData.indexOf("]") + "");
return convertStr(rData);
}
return null;
}
public static ArrayList<HashMap<String,Object>> convertStr(String str){
ArrayList<HashMap<String, Object>> list = new ArrayList<>();
// 第一个冒号之前的字符串去掉
String str1 = str.substring(str.indexOf(":") + 1);
log.info(str1);
// 最后一个冒号后面的国家单独提出来
String lastCountryStr = str1.substring(str1.lastIndexOf(":") + 1);
log.info(lastCountryStr);
// 最后一个国家字符串去掉两边的中括号
String lastCountryStr1 = lastCountryStr.substring(lastCountryStr.indexOf("[") + 1, lastCountryStr.lastIndexOf("]"));
log.info(lastCountryStr1);
// 最后一个国家字符串根据逗号分割
String[] lastCountryStr2 = lastCountryStr1.split(",");
// 最后一个国家的中文名
String lastCountryChineseName = removeQuotesBothSide(lastCountryStr2[0]);
log.info(lastCountryChineseName);
// 最后一个国家的英文名
String lastCountryEnglishName = removeQuotesBothSide(lastCountryStr2[2]);
log.info(lastCountryEnglishName);
// 接下来就是剩余部分
String str2 = str1.substring(0, str1.lastIndexOf(":"));
log.info(str2);
// str2是一个有规律的string,以冒号分割
String[] str3 = str2.split(":");
for (int i = 0; i < str3.length; i++) {
HashMap<String, Object> map = new HashMap<>();
log.info(str3[i]);
// 去掉中括号两边的字符串
String itemStr = removeStrBracketsBothSide(str3[i]);
log.info(itemStr);
// 第二个逗号之后的字符串就是国家英文名
String englishName = removeQuotesBothSide(itemStr.substring(itemStr.indexOf(",", itemStr.indexOf(",") + 1)));
log.info(englishName);
map.put("englishName",englishName);
// 第一个逗号之前的就是国家中文名
String chineseName = removeQuotesBothSide(itemStr.substring(0, itemStr.indexOf(",")));
log.info(chineseName);
map.put("chineseName",chineseName);
list.add(map);
}
// 最后put最后一个国家
HashMap<String, Object> map = new HashMap<>();
map.put("englishName",lastCountryChineseName);
map.put("chineseName",lastCountryEnglishName);
list.add(map);
return list;
}
/**
* 去掉引号
* @param s
* @return
*/
public static String removeQuotesBothSide(String s){
return s.substring(s.indexOf("'") + 1, s.lastIndexOf("'"));
}
public static String removeStrBracketsBothSide(String s){
return s.substring(s.indexOf("[") + 1,s.lastIndexOf("]"));
}
}
二. 将数据存储到MySQL中
首先建表:每行数据只有中文名和英文名,所以新建两个字段就行了,加上创建时间和更新时间也可以。
springboot 框架代码生成对应实体类,mapper,等。
在service层插入代码
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
/**
* <p>
* 存储世界上全部国家的英文名,中文名 服务实现类
* </p>
*
* @author fzg
* @since 2022-11-17
*/
@Service
@Slf4j
public class CountryNameServiceImpl extends ServiceImpl<CountryNameMapper, CountryName> implements CountryNameService {
@Autowired
private CountryNameMapper countryNameMapper;
/**
* 获取世界上所有国家名字
* 并且存储到MySQL表中
*/
@Override
public String getWorldCountry() {
log.info(getWorldAllCountrys().toString());
ArrayList<HashMap<String, Object>> list = getWorldAllCountrys();
int count = 0;
for (HashMap<String, Object> map : list) {
int insert = countryNameMapper.insert(new CountryName() {{
setChineseName(map.get("chineseName").toString());
setEnglishName(map.get("englishName").toString());
}});
count += insert;
}
log.info("插入了" + count + "行数据");
return "插入了 " + count + "行数据。";
}
@Override
public String test() {
return "范占国";
}
/**
* 获取世界上所有国家中文名字和英文名
* @return
*/
public ArrayList<HashMap<String,Object>> getWorldAllCountrys(){
// String countryUrl = "src\\main\\java\\com\\fzg\\common\\demo\\country\\country.txt";
String countryUrl = "E:\\学习\\项目\\vue-vant-app\\myBlog\\myCaveolae_server\\src\\main\\java\\com\\fzg\\common\\demo\\country\\country.txt";
File file = new File(countryUrl);
BufferedReader bf;
String data = "";
try {
bf = new BufferedReader(new FileReader(file));
data = bf.readLine();
} catch (FileNotFoundException e) {
e.printStackTrace();
log.info("文件未找到");
} catch (IOException e) {
e.printStackTrace();
log.info("文件读取失败");
}
if (data.equals("")){
log.info("文件内容为空");
}else {
log.info("文件读取成功");
log.info(data);
// 去掉大括号以及前面的字符,以及最后面的大括号以及分号
String rData = data.substring(data.indexOf("{") + 1 , data.lastIndexOf("}"));
log.info(rData);
log.info(rData.indexOf("[") + "");
log.info(rData.indexOf("]") + "");
return convertStr(rData);
}
return null;
}
public ArrayList<HashMap<String,Object>> convertStr(String str){
ArrayList<HashMap<String, Object>> list = new ArrayList<>();
// 第一个冒号之前的字符串去掉
String str1 = str.substring(str.indexOf(":") + 1);
log.info(str1);
// 最后一个冒号后面的国家单独提出来
String lastCountryStr = str1.substring(str1.lastIndexOf(":") + 1);
log.info(lastCountryStr);
// 最后一个国家字符串去掉两边的中括号
String lastCountryStr1 = lastCountryStr.substring(lastCountryStr.indexOf("[") + 1, lastCountryStr.lastIndexOf("]"));
log.info(lastCountryStr1);
// 最后一个国家字符串根据逗号分割
String[] lastCountryStr2 = lastCountryStr1.split(",");
// 最后一个国家的中文名
String lastCountryChineseName = removeQuotesBothSide(lastCountryStr2[0]);
log.info(lastCountryChineseName);
// 最后一个国家的英文名
String lastCountryEnglishName = removeQuotesBothSide(lastCountryStr2[2]);
log.info(lastCountryEnglishName);
// 接下来就是剩余部分
String str2 = str1.substring(0, str1.lastIndexOf(":"));
log.info(str2);
// str2是一个有规律的string,以冒号分割
String[] str3 = str2.split(":");
for (int i = 0; i < str3.length; i++) {
HashMap<String, Object> map = new HashMap<>();
log.info(str3[i]);
// 去掉中括号两边的字符串
String itemStr = removeStrBracketsBothSide(str3[i]);
log.info(itemStr);
// 第二个逗号之后的字符串就是国家英文名
String englishName = removeQuotesBothSide(itemStr.substring(itemStr.indexOf(",", itemStr.indexOf(",") + 1)));
log.info(englishName);
map.put("englishName",englishName);
// 第一个逗号之前的就是国家中文名
String chineseName = removeQuotesBothSide(itemStr.substring(0, itemStr.indexOf(",")));
log.info(chineseName);
map.put("chineseName",chineseName);
list.add(map);
}
// 最后put最后一个国家
HashMap<String, Object> map = new HashMap<>();
map.put("englishName",lastCountryChineseName);
map.put("chineseName",lastCountryEnglishName);
list.add(map);
return list;
}
/**
* 去掉引号
* @param s
* @return
*/
public String removeQuotesBothSide(String s){
return s.substring(s.indexOf("'") + 1, s.lastIndexOf("'"));
}
public String removeStrBracketsBothSide(String s){
return s.substring(s.indexOf("[") + 1,s.lastIndexOf("]"));
}
}
这里我将前面文本解析的方法都搬过来了,并且将方法都改为了非静态的
这是因为service,mapper等都是非静态的,静态方法在类加载的时候就执行。
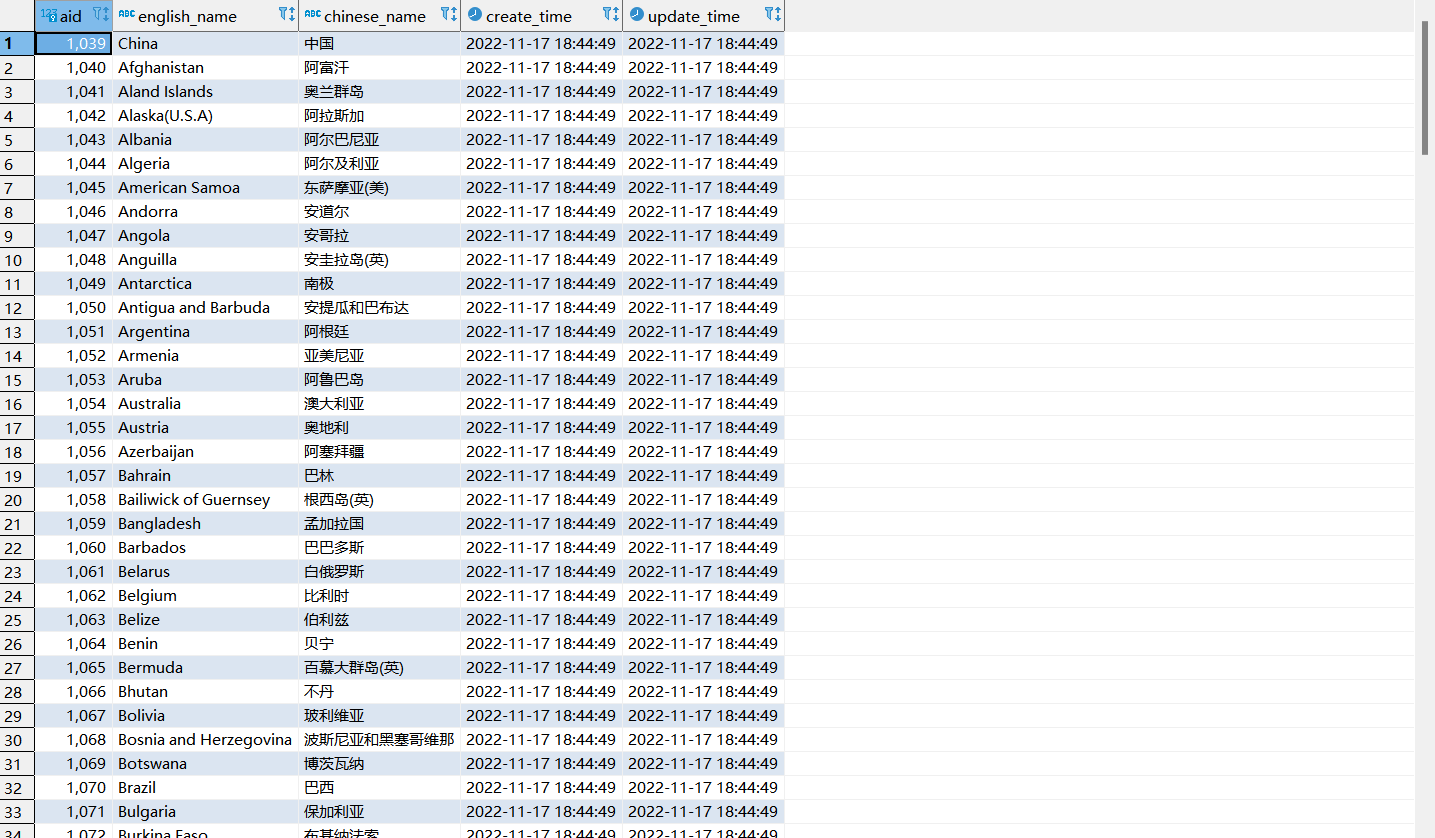
最后数据导入成功
原文本数据

导入到数据库之后
ok

