
GAN的原理和实现
GAN,生成式对抗网络(Generative Adversarial Networks)是一种深度学习模型,是近几年来复杂分布上无监督学习最具前景的方法之一。
机器学习的模型可大体分为两类,生成模型(Generative model)和判别模型(Discriminator model),判别模型需要输入变量,通过某种模型来预测,生成模型是给定某种隐含信息,来随机产生数据。
GAN主要包括了两个部分,即生成器generator与判别器discriminator。生成器主要用来学习真实图像分布从而让自身生成的图像更加的真实,以骗过判别器。判别器则需要对接受的图片进行真假判别。

原理:
在训练过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别图像的真假,这个过程相当于二人进行博弈,随着时间的推移,生成器和判别器在不断地进行对抗。最终两个网络达到了一个动态平衡,生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近0.5(相当于随机猜测类别)。
最终的结果:
G可以生成足以'以假乱真'的图片G(z),对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z))=0.5,目的就是为了得到一个生成模型G,可以用来生成图片。
GAN的应用领域:
- 图像生成
- 图像增强
- 风格化
- 艺术的图像创造
GAN的简单实现
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers import matplotlib.pyplot as plt import numpy as np import glob import os (train_images,train_labels),(_,_) = tf.keras.datasets.mnist.load_data() train_images = train_images.reshape(train_images.shape[0],28,28,1) train_images = tf.cast(train_images,tf.float32) train_images = (train_images - 127.5) / 127.5 BATCH_SIZE = 256 #None就是每个BATCH BUFFER_SIZE = 60000 datasets = tf.data.Dataset.from_tensor_slices(train_images) print(datasets) #<TensorSliceDataset shapes: (28, 28), types: tf.float32> datasets = datasets.shuffle(BUFFER_SIZE).batch(BATCH_SIZE) def generator_model(): model = tf.keras.Sequential() model.add(layers.Dense(256,input_shape=(100,),use_bias=False)) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Dense(512,use_bias=False)) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Dense(28*28*1,use_bias='False',activation='tanh')) model.add(layers.BatchNormalization()) model.add(layers.Reshape((28,28,1))) return model def discriminator_model(): model = tf.keras.Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512,use_bias=False)) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Dense(256,use_bias=False)) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) #先不用进行激活,可以利用损失函数 model.add(layers.Dense(1)) return model cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits='True') #告诉损失函数我们最后一层没有激活 def discriminator_loss(real_out,fake_out): #这里希望让真实图像被判定为1,假的图像判定为0 real_loss = cross_entropy(tf.ones_like(real_out),real_out) fake_loss = cross_entropy(tf.zeros_like(fake_out),fake_out) return real_loss + fake_loss #生成器接收假的的图片并希望能够被判为真 def generator_loss(fake_out): return cross_entropy(tf.ones_like(fake_out),fake_out) #创建生成器优化器 generator_optimizer = tf.keras.optimizers.Adam(1e-4) #创建判别器优化器 discriminator_optimizer = tf.keras.optimizers.Adam(1e-4) generator = generator_model() discriminator = discriminator_model() EOPCHS = 10 NOISE_DIM = 100 num_ex_to_generate = 16 #生成16个长度为100的向量 seed = tf.random.normal([num_ex_to_generate,NOISE_DIM]) def train_step(images): noise = tf.random.normal([BATCH_SIZE,NOISE_DIM]) with tf.GradientTape() as gen_tape,tf.GradientTape() as disc_tape: real_out = discriminator(images,training=True) gen_image = generator(noise,training=True) fake_out = discriminator(gen_image,training=True) gen_loss = generator_loss(fake_out) disc_loss = discriminator_loss(real_out,fake_out) gradient_gen = gen_tape.gradient(gen_loss,generator.trainable_variables) gradient_disc = disc_tape.gradient(disc_loss,discriminator.trainable_variables) generator_optimizer.apply_gradients(zip(gradient_gen,generator.trainable_variables)) discriminator_optimizer.apply_gradients(zip(gradient_disc,discriminator.trainable_variables)) #画出这一个批次的图片 def generate_plot_image(gen_model,test_noise): pre_images = gen_model(test_noise,training=False) fig = plt.figure(figsize=(4,4)) for i in range(pre_images.shape[0]): plt.subplot(4,4,i+1) #因为在生成图片最后用激活函数tanh把图片映射到[-1,1]之间,现在要把取值范围改变成[0,1]的范围 plt.imshow(pre_images[i,:,:,0] + 1/ 2,cmap='gray') plt.axis('off') plt.show() def train(dataset,epochs): for epoch in range(epochs): print('Epoch',epoch + 1,':') for image_path in dataset: train_step(image_path) print('.',end='') generate_plot_image(generator,seed) print('\n') train(datasets,EOPCHS)
DCGAN
DCGAN就是将CNN和原始的GAN结合到了一起,生成的模型和判别模型都运用了深度卷积神经网络的生成对抗网络。这个网络架构由<<Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks>>这篇论文提出,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度。
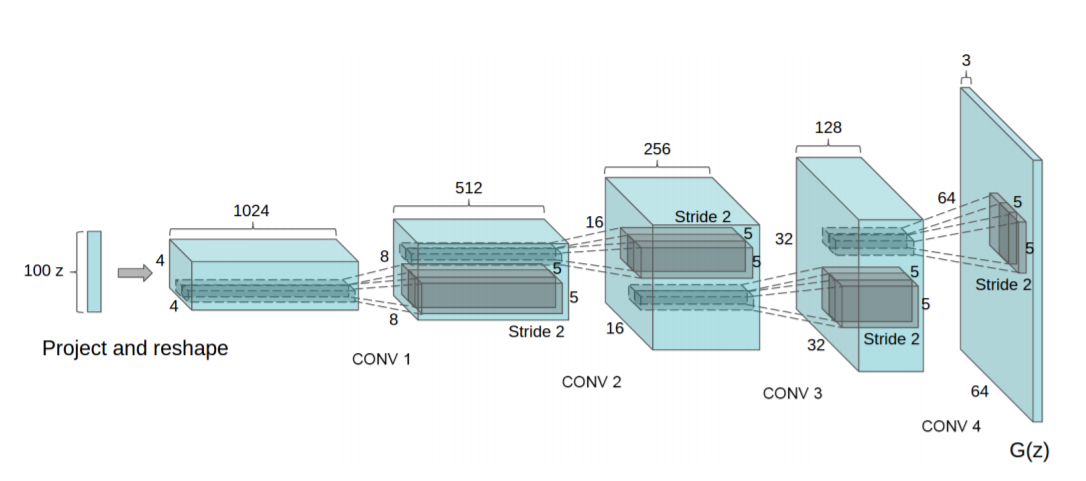
DCGAN的主要设计技巧:
1.取消所用pooling层。生成器网络中使用转置卷积(transposed convolution layer)进行上采样,判别器网络中加入stride的卷积代替pooling。
2.去掉全连接层(FC),使网络变成全卷积网络。
3.生成器网络中使用Relu作为激活函数,最后一层使用tanh。
4.判别器网络中使用LeakyRelu作为激活函数。
5.在Generator和Discriminator上都使用BatchNorm解决初始化差的问题,帮助梯度传播到每一层,防止Generator把所有样本都收敛到同一个点,直接将BatchNorm应用到所有层会导致样本震荡和模型不稳定,通过在Generator输出层和Discriminator输入层不采用BatchNorm可以防止这种现象。
6.使用Adam优化器,beta1(1阶矩估计的指数衰弱率)的值设置为0.5
7.论文参数
LeakyReLU的参数设置为0.2、learning rate=0.002、batch size=128
def generator_model(): model = tf.keras.Sequential() model.add(layers.Dense(7*7*256,input_shape=(100,),use_bias=False)) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Reshape((7,7,256))) model.add(layers.Conv2DTranspose(128,(5,5),strides=(1,1),padding='same',use_bias=False)) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Conv2DTranspose(64,(5,5),strides=(2,2),padding='same',use_bias=False)) model.add(layers.BatchNormalization()) model.add(layers.LeakyReLU()) model.add(layers.Conv2DTranspose(1,(5,5),strides=(2,2),padding='same',use_bias=False,activation='tanh')) return model def discriminator_model(): model = tf.keras.Sequential() model.add(layers.Conv2D(64,(5,5),strides=(2,2),padding='same',input_shape=(28,28,1))) model.add(layers.LeakyReLU()) model.add(layers.Dropout(0.3)) model.add(layers.Conv2D(128,(5,5),strides=(2,2),padding='same')) model.add(layers.LeakyReLU()) model.add(layers.Dropout(0.3)) model.add(layers.Conv2D(256,(5,5),strides=(2,2),padding='same')) model.add(layers.LeakyReLU()) model.add(layers.Flatten()) model.add(layers.Dense(1)) return model
cGAN
原始GAN的缺点
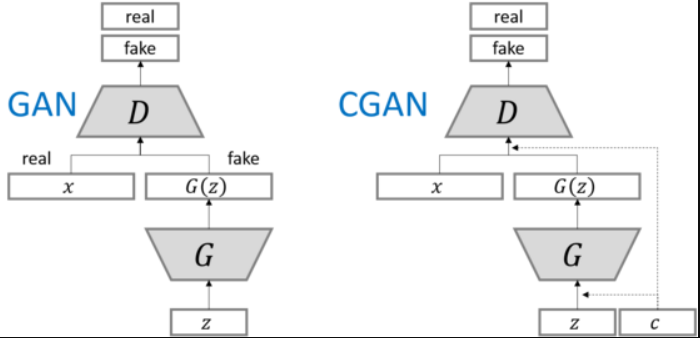
生成的图像是随机的,不可预测的,无法控制网络输出特定的图片,生成目标不明确,可控性不强,针对原始GAN不能生成具有特定属性的图片的问题,Mechi Mirza等人提出了cGAN,其核心在于将属性信息y融入生成器G和判别器D中,其核心在于将属性y可以是任何标签信息,例如图像的类别、人脸图像的面部表情等。
把无监督学习转化为有监督学习。

cGAN网路架构
cGAN缺陷
cGAN生成虽有很多缺陷,譬如图像边缘模糊,生成的图像分辨率太低等,但是它为后面的Cycle-GAN开拓了道路,这两个模型转换图像的风格时对属性特征的处理方法均受cGAN的启发。
ACGAN
CGAN通过在生成器和判别器中均使用标签信息进行训练,不仅能产生特定标签的数据,ACGAN是条件GAN的另一种实现,既使用标签信息进行训练,同时也重建标签信息。
生成器的输入包含class与noise两个部分,其中class为训练数据标签信息,noise为随机向量,然后将两者进行拼接,生成的输出张量为图片,(batch_size, channel, height, width)。
判别器的输出为图片(生成图片和真实图片),判别器的输出为两个部分,一部分是源数据真假的判断,形状为:(batch_size,1),一部分是输入数据的分类结果,形状为( batch_size, class_num)
判别器的输出部分,因此判别器的最后一层有两个并列的全连接层,分别得到这两部分的输出结果,即判别器的输出有两个张量(真假判断张量和分类结果张量)。
损失函数
对于判别器而言,既希望分类正确,又希望能正确分辨数据的真假,对于生成器而言,也希望能够分类正确,但希望判别器不能正确分类假数据。
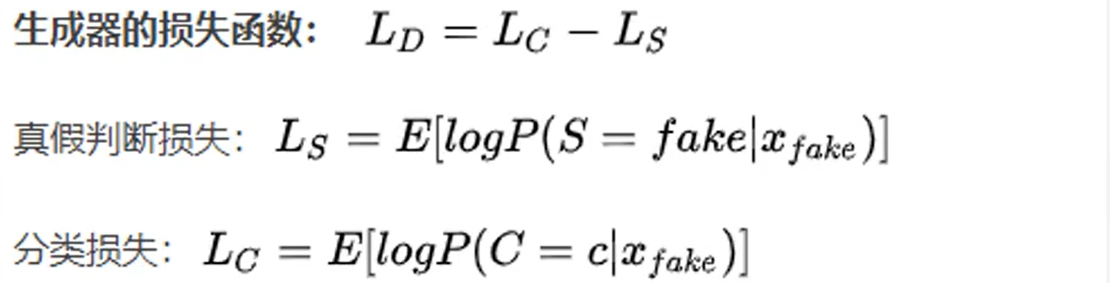
InfoGAN
在CGAN中,生成器网络还有一个附加参数c,即G(z,c)其中c是一个条件变量,在CGAN中,c假设在语义上是已知的,例如标签,因此在训练期间我们必须提供它,在InfoGAN中,我们假设c不知道,所以我们做的是为c提出一个先验,并根据数据推断它,即我们想找到后验p(c|x,z)。
InfoGAN所要表达的目标就是通过非监督学习得到可分解的特征表示,使用GAN加上最大化生成的图片和编码之间的交互信息。最大的好处就是可以不需要监督学习,而且不需要大量额外的计算花销就能得到可解释的特征。
InfoGAN的出发点,它试图利用z,寻找一个可解释的表达,于是它将z进行了拆解,一是噪声z,二是可解释的隐变量c,而我们希望通过约束c与生成数据之间的关系,可以使得c里面包含有对数据的可解释信息。
对于MNIST数据,c可以分为categorical latent code代表数字的种类信息(0-9),以及continuous latent code来表示倾斜度、笔画粗细等。
这些特征在数据空间中以一种复杂的无序方式进行编码,但是如果这些特征是可分解的,那么这些特征将具有更强的可解释性,我们将更容易的利用这些特征进行编码,所以,我们将如何通过非监督学习方式获取这些可分解的特征呢?InfoGAN通过使用连续的和离散的隐含因子来学习可分解的特征。
如果从表征学习来看GAN模型,由于在生成器使用噪声z的时候没有加任何的限制,所以在以一种高度混乱的方式使用z,z的任何一个维度都没有明显的表示一个特征,所以在数据生成的过程,我们无法得知什么样的噪声z可以用来生成数字1,什么样的噪声z可以用来生成数字3,这一点限制了我们对GAN的使用。在生成器中除了原先的噪声z还增加了一个隐含编码c,所谓InfoGAN,其中Info代表互信息,它表示生成数据x与隐藏编码c之间关联程度的大小,为了使x与c之间关系密切,所以我们需要最大化互信息的值,据此对原始GAN模型的值做了一些修改,相当于加了一个互信息的正则化项。
什么是互信息?我们可以把互信息看成当观测到y值而造成的x的不确定性的减小,如果x,y是相互独立的没有相关性,即互信息的值为0,那么已知y值的情况下推测x与x的原始分布没有区别;如果x,y有相关性,即互信息的值大于0,那么在已知y的情况下,我们就能知道哪些x的值出现的概率更大。
在训练期间,我们可以任意分配一个先验c给一张图片,实际上,我们可以根据需要添加任意数量的先验,InfoGAN可能会为它们分配不同的属性,InfoGAN的作者将其称为"解开的表示",因为它将数据的属性分解为几个条件参数。
InfoGAN设计
判别器网络D(x)和生成器网络G(z,c)的训练过程与CGAN非常相似,差异是:代替D(x,c),我们在InfoGAN中使用判别器GAN:D(x),即无条件判别器,对于生成器网络,我们给予了一个观察数据(或者说条件)c,即G(z,c)。
除了D(x),G(z,c),我们需要在训练一个网络Q(c|x)这样我们就能计算互信息。Q也可以视作一个判别器,输出类别c。
pix2pix GAN
主要用于图像转换,又称为图像翻译。普通的GAN接收的G部分是随机向量,输出的是图像,D部分接收的输入是图像,生成的或是真实的,输出是对或者错,这样G和D就能联手输出真实的图像。
对于图像翻译任务来说,它的G输入显然应该是一张图x,输出当然也是一张图y,不需要添加随机输入。对于图像翻译任务而言,输入与输出之间会共享很多的信息,比如轮廓信息是共享的。如果使用普通的卷积神经网络,那么会导致每一层都承载保存着所有的信息,这样神经网络很容易出错。

U-net是变形的Encoder-Decoder模型,它将第i层拼接到第n-i层,这样做是因为第i层和第n-i层的图像大小是一致的,可以认为他们承载着类似的信息。但是D的输入却发生了一些变化,因为除了要生成真实图像之外,还要保证生成的图像是匹配的,于是D的输入就做了一些变动,D中要输入成对的图像,类似于CGAN。Pix2Pix中的D在论文中被实现为Patch-D,所谓的Patch,是指无论生成的图像有多大,将其切分为多个固定大小的Patch输入进入D去判断。这样设计的好处在于D的输入变小,计算量变小,训练速度快。
损失函数
D网络损失函数:
1.输入真实的成对图像希望判定为1
2.输入生成与原图像希望判定为0
G网络损失函数:
1.输入生成图像与原图像希望判定为1
对于图像翻译任务,G的输入和输出之间其实共享了很多信息,比如图像上色的任务,输入和输出之间就共享了边缘信息,因此为了保证输入图像和输出图像之间的相似度还添加了L1损失。
![]()
论文要点
1.类似CGAN,输入为图像而不是随机向量。
2.使用U-net,使用跳阶来共享更多的信息。
3.输入成对的图像到D保证映射。
4.使用Patch-D来降低计算量提升效果。
5.L1损失函数的加入来保证输入和输出之间的一致性。
Cycle GAN
主要用于图像之间的转换,如图像风格转换。Cycle GAN适用于非配对的图像到图像风格的转换,它解决了需要成对数据进行训练的困难。
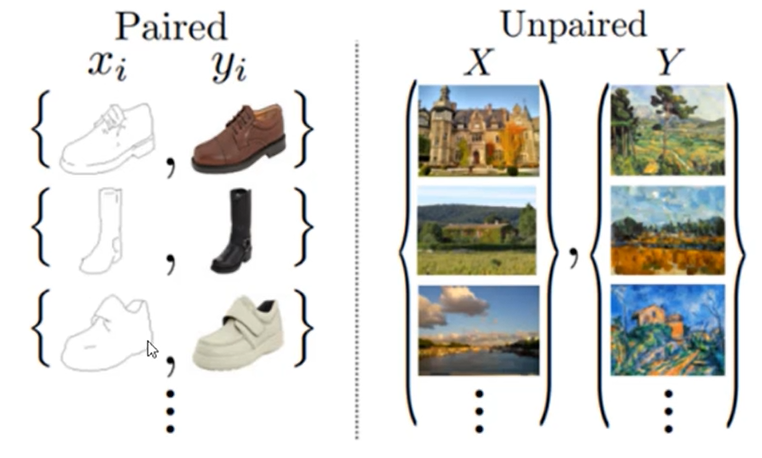
原理:将一类图片转化为另一类图片,即现在有两个样本空间,X和Y,我们希望把X空间中的样本转换成Y空间的样本(获取一个数据集的特征,并转换为另一个数据集特征)。我们的实际目标就是学习从X到Y空间的映射,设这个映射为F,它就对应GAN中的生成器,F可以将X中的图片x转换为Y中的图片F(x)。对于生成的图片,我们需要GAN的判别器来判断它是否为真实图片,由此构成对抗生成式网络。从理论上来讲,对抗训练可以学习和产生与目标域Y相同分布的输出,但会产生一些问题。
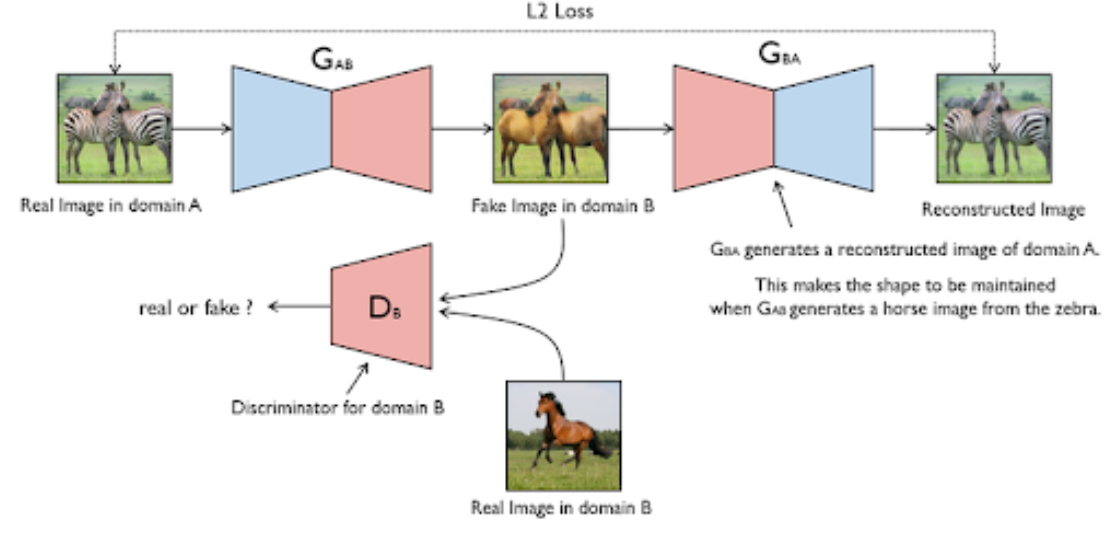
单向Cycle GAN
在足够大的样本容量下,网络可以将相同的输入图像集合映射到目标域中图像的任何随机排列,其中任何学习的映射可以归纳出与目标分布匹配的输出分布,即映射F完全可以将所有x都映射为Y空间的同一张图片,是损失无效化。因此,单独的对抗损失Loss不能保证学习函数可以将单个输入Xi映射到期望的输出Yi,对此作者又提出了"循环一致性损失",cycle consistency loss。
我们希望能够把domain A的图片(命名为图a)转化为domain B的图片(命名为图b),为了实现这个过程,我们需要生成器G_AB和G_BA,分别把domain A和domain B的图片进行互相转换。将X的图片转换到Y空间后,应该还可以在转换回来,这样就能杜绝模型把所有X的图片转换为Y空间的同一张图片了。
最后为了训练这个单向GAN需要两个loss,分别是生成器的重建loss和判别器的判别loss。
1.判别loss D_B使用来判断输入的图片是否为真实的domain B的图片。
![]()
2.生成loss:生成器用来重建图片a,目的是希望生成的图片G_BA(G_AB(a))和原图a尽可能的相似,那么可以很简单的采取L1 loss或者L2 loss,最后生成loss表示为:
![]()
Cycle GAN其实就是一个A->B单向GAN加上一个B->A单向GAN,两个GAN共享两个生成器,然后自带一个判别器,所以加起来总共有两个判别器和两个生成器。一个单向GAN有两个loss,而Cycle GAN加起来有四个loss。
局限性:
对于颜色、纹理等的转换效果比较好,对多样性高的、多变的效果转换不好(如几何转换)。
SSGAN
SSGAN是一个半监督学习生成对抗网络,初衷是利用GAN生成器生成的样本来改进和提高图像分类任务的性能。
SSGAN的主要设计思想在鉴别器的设计,我们希望设计的鉴别器扮演执行图像分类任务的分类器的角色,又能区分由生成器生成的生成样本和真实数据。
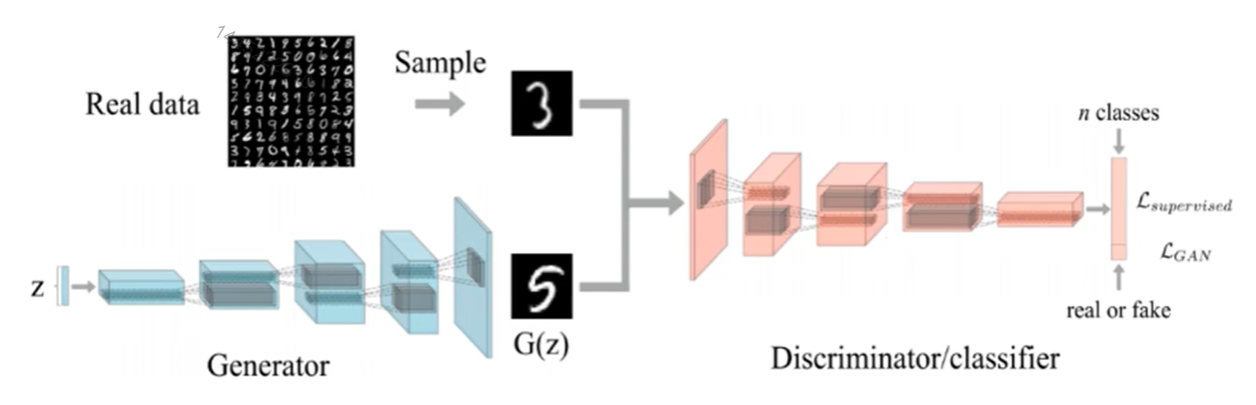
对于包含N个类别的数据集,真实的图像将被分类到N个类别中,生成的图像将被分入第N+1类中。
损失函数:
1.鉴别器损失函数
![]()
2.生成器损失函数
![]()
SSGAN实现中最关键的是损失函数的构建:鉴别器引入huber loss,就是L2损失,目的是生成器生成的图像与真实输入图像的损失越小越好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号