
Python学习日记(十九) 模块导入
模块导入
当文件夹中有这样一个自定义的command模块

在它的内部写下下列代码:
print('这个py文件被调用!') def fuc(): print('这个函数被调用!')
然后我们在command模块中执行下列代码:
import command #这个py文件被调用!
我们如果在这段程序中反复执行多次这一段代码,这一个文件结果也只会被导入一次
import command #这个py文件被调用! import command import command import command import command import command
调用command模块中的方法fuc()
import command #这个py文件被调用! command.fuc() #这个函数被调用!
当我们写这样一个代码的时候,计算机会先去找到这一个模块,找到之后再创建这个模块的命名空间,把文件夹的名字都放在命名空间里
如果我们在temp_py.py中也写一个fuc()函数:
import command #这个py文件被调用! def fuc(): print('hello __fuc__') command.fuc() #这个函数被调用!
那么实际上它调用的还是command模块内的函数
如果在command模块内和temp_py.py中加入相同的变量:
command模块代码:
print('这个py文件被调用!') number = 150 def fuc(): print('这个函数被调用!',number) #number获取到一个内存地址再从中拿到值
temp_py.py执行代码:
import command #这个py文件被调用! number = 300 print(command.number) #150 print(number) #300
当你要导入一个模块的时候,计算机会先到sys.modules()中去找你导入的这个模块是否在这个里面
import command #这个py文件被调用! import sys print(sys.modules.keys()) #dict_keys(['sys', 'builtins', '_frozen_importlib', '_imp', '_thread', '_warnings', '_weakref', 'zipimport', '_frozen_importlib_external', '_io', 'marshal', 'nt', 'winreg', 'encodings', 'codecs', '_codecs', 'encodings.aliases', 'encodings.utf_8', '_signal', '__main__', 'encodings.latin_1', 'io', 'abc', '_abc', 'site', 'os', 'stat', '_stat', 'ntpath', 'genericpath', 'os.path', '_collections_abc', '_sitebuiltins', '_bootlocale', '_locale', 'encodings.gbk', '_codecs_cn', '_multibytecodec', 'encodings.cp437', 'command'])
在最后我们可以看到之前的command模块有被成功导入
如果我们要找的这个模块在sys.modules()中找不到,那么就依据sys.path()路径去找到模块,若找到就创建这个模块的命名空间再把文件名陈放在内存里并执行,若找不到那么就会报错
给模块取别名:
语法:import '模块名' as '别名'
import command as comd #这个py文件被调用! comd.fuc() #这个函数被调用! 150 import time as t print(t.time()) #1567359703.0011516 print(time.time()) #NameError: name 'time' is not defined
假设有两个模块xmlreader.py和csvreader.py,它们都定义了函数read_data(filename):用来从文件中读取一些数据,但采用不同的输入格式.可以编写代码来选择性地挑选读取模块,例如
if file_format == 'xml': import xmlreader as reader elif file_format == 'csv': import csvreader as reader data=reader.read_date(filename)
一行获取模块:
import sys,os,pickle,shelve,json
不推荐这样写后期不好维护,建议一行一行写在开头,能够让人一目了然
模块的写法顺序:
内置模块(re、time等)、扩展的模块(django等)、自定义的模块
from...import...的用法
from time import time print(time()) #1567360779.0056956 from sys import version print(version) #3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)]
在pycharm中,如果是自定义模块要用from...import...调用方法有红色的波浪线报错是因为pycharm主观认为从根目录去找这个模块,结果却找不到,但其实这个模块可以从sys.path()中找到
若在temp_py.py定义一个和fuc同名的函数,让我们来看看执行结果:
from command import fuc #这个py文件被调用! def fuc(): print('!!!!!!!') #!!!!!!! fuc()
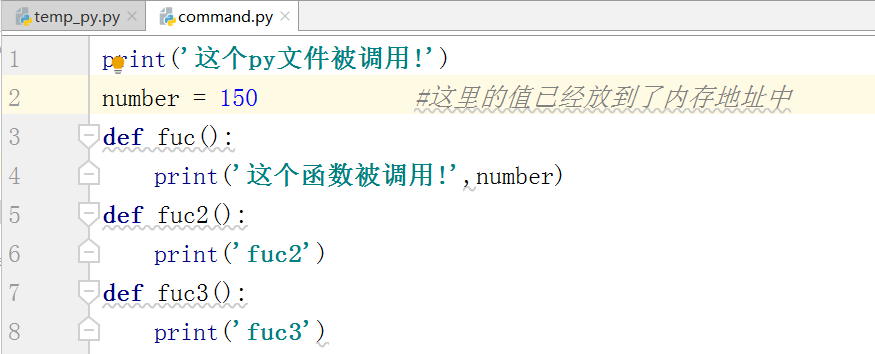
也支持获取多个方法:


from 模块名 import *
它能把模块内的名字都调用
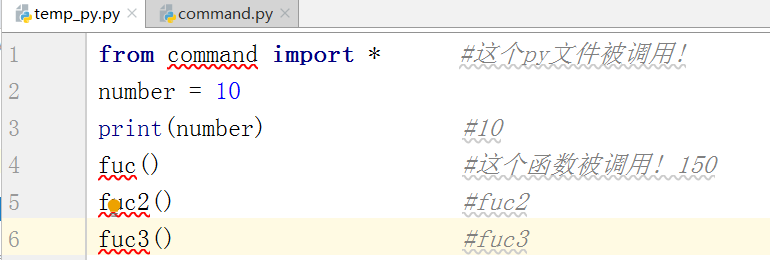
缺点:不安全怕重名
from time import * sleep = 10 sleep(0.1) #TypeError: 'int' object is not callable
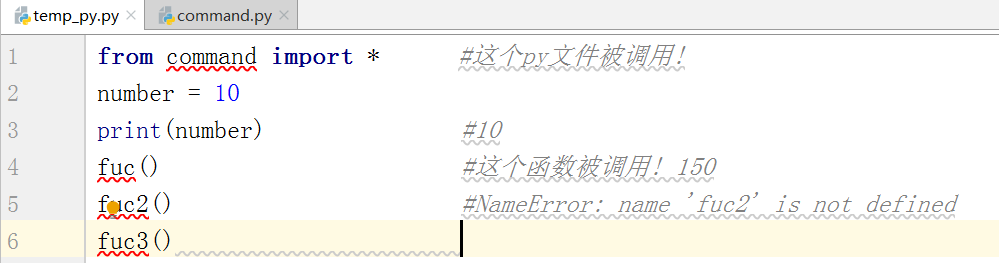
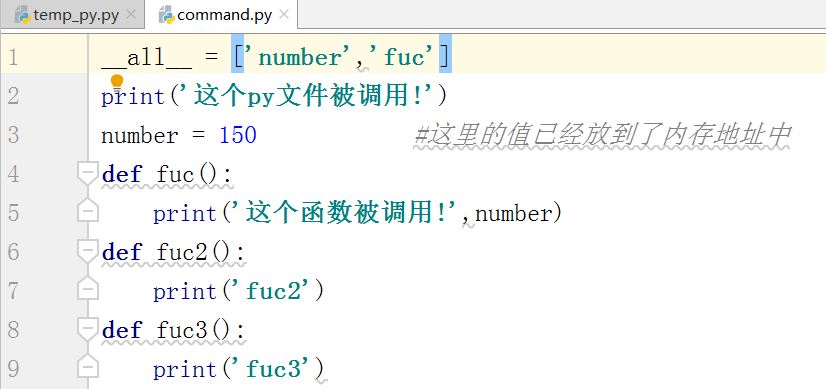
__all__
只和from 模块名 import *有关
如果有被__all__约束住那么才能够执行
__name__
当我们直接执行这个模块的时候,这里的__name__就等于'__main__'
__all__ = ['number','fuc'] print('这个py文件被调用!') number = 150 #这里的值已经放到了内存地址中 def fuc(): print('这个函数被调用!',number) def fuc2(): print('fuc2') def fuc3(): print('fuc3') print(__name__) #__main__
当我们执行其他模块的时候,在其他模块中引用这个模块,这个模块中的__name__就等于'这个模块的名字'
import command #这个py文件被调用! #command
有些时候当我们在其他模块中调用模块时,调用的这个模块本身可能有一些测试的代码,如果我们直接调用的话那么这些测试的代码也会跟着一起执行出来,但是实际上我们在调用这个模块的时候并不想让它里面的内容直接就跑出来,所以我们就要在这个模块中添加一个判断来确定它的__name__
当在这个模块执行时:
__all__ = ['number','fuc'] print('这个py文件被调用!') number = 150 #这里的值已经放到了内存地址中 def fuc(): print('这个函数被调用!',number) def fuc2(): print('fuc2') def fuc3(): print('fuc3') if __name__ == '__main__': print('执行下列调试代码或其他功能代码...') #执行下列调试代码或其他功能代码...
在其他模块调用这个模块时,模块中的那些调试代码就不会再被直接执行了
import command #这个py文件被调用!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号