


ZooKeeper指南
数据模型
ZooKeeper的namespace每个节点都可以有与其关联的数据以及子节点。到节点的路径始终表示为规范的、绝对的、斜杠分隔的路径;没有相对路径。任何unicode字符都可以在受以下约束的路径中使用:
- null character (\u0000) 不能使用.
- 不能使用的characters : \u0001 - \u001F and \u007F
- \u009F.
- 不能使用的characters: \ud800 - uF8FF, \uFFF0 - uFFFF.
- "." character 不能使用, 不合法的比如: "/a/b/./c" or "/a/b/../c".
- "zookeeper" 是保留字.
Znode
ZooKeeper树中的每个节点都称为znode。znode维护一个stat结构,其中包括数据更改、acl更改的版本号。每次znode的数据更改时,版本号都会增加。当客户机执行更新或删除时,它必须提供正在更改的znode数据的版本。如果它提供的版本与数据的实际版本不匹配,则更新将失败。(此行为可以被覆盖。
ZooKeeper不是设计为一个通用数据库或大型对象存储。相反,它管理协调数据。这些数据可以以配置、状态信息、会合等形式出现。各种形式的协调数据的一个共同特点是它们相对较小:以KB为单位。ZooKeeper客户端和服务器实现都有健全性检查,以确保zNode的数据少于1M。在相对较大的数据量上操作会导致某些操作比其他操作花费更多的时间,并且会影响某些操作的延迟,因为通过网络和存储介质移动更多数据需要额外的时间。如果需要大数据存储,处理此类数据的通常模式是将其存储在大容量存储系统(如NFS或HDFS)上,并在ZooKeeper中存储指向存储位置的指针。
ZooKeeper的临时节点不允许有children。可以使用getEphemerals()api检索session的临时节点列表。
getEphemerals()
使用指定的path检索session创建的临时节点列表。如果路径为empty,将列出session的所有临时节点。
序列节点——唯一命名:创建znode时,还可以在路径末尾附加一个单调递增的计数器。此计数器对于父znode是唯一的。计数器的格式为%010d,即10位数字加0(零)填充(计数器的格式为简化排序),即“000000000 1”。当递增超过2147483647时,计数器将溢出(产生名称“-2147483648”)。
容器节点(3.6.0新增特性)
容器znode是一种特殊用途的znode,可用于leader, lock等技巧。当删除的最后一个child时,该容器znode将被server自动删除。
由于这个特性,在容器zNode内创建child时,应该随时准备catch KeeperException.NoNodeException,因为容器znode随时可能被server删除,并在发生KeeperException.NoNodeException 时重新创建容器znode。
TTL节点(3.6.0新增特性)
创建PERSISTENT 或PERSISTENT_SEQUENTIAL znode时,可以选择为znode设置以毫秒为单位的TTL。如果znode没有在TTL中修改,并且没有子节点,该容器znode将被server自动删除。
注意:TTL节点必须通过System property启用,因为默认情况下它们是禁用的。见 Administrator's Guide . 如果尝试在未设置正确System property的情况下创建TTL节点,将抛出KeeperException.UnimplementedException。
ZooKeeper的时间
ZooKeeper以多种方式跟踪时间:
Zxid - 对ZooKeeper状态的每次更改都会收到Zxid(ZooKeeper事务Id)形式的戳记。这将向ZooKeeper公开所有更改的总顺序。每个变化都有一个唯一的zxid,如果zxid1小于zxid2,那么zxid1发生在zxid2之前。
version - 对节点的每次更改都会使该节点的一个版本号增加。这三个版本号分别是version(对znode数据的更改次数)、cversion(对znode子级的更改次数)和aversion(对znode的ACL的更改次数)。
ticks - 使用ZooKeeper集群时,服务器使用ticks来定义事件的计时,如状态上报、会话超时、对等方之间的连接超时等。The tick time is only indirectly exposed through the minimum session timeout (2 times the tick time); if a client requests a session timeout less than the minimum session timeout, the server will tell the client that the session timeout is actually the minimum session timeout.
ZooKeeper不使用真实的时间,除了在znode创建和znode修改时将时间戳放入stat结构中。
ZooKeeper的Stat结构
- czxid The zxid of the change that caused this znode to be created.创建时的zxid
- mzxid The zxid of the change that last modified this znode.修改自己的zxid
- pzxid The zxid of the change that last modified children of this znode.修改children的zxid
- ctime The time in milliseconds from epoch when this znode was created.创建时间
- mtime The time in milliseconds from epoch when this znode was last modified.修改时间
- version The number of changes to the data of this znode.修改自己的版本
- cversion The number of changes to the children of this znode.修改children的版本
- aversion The number of changes to the ACL of this znode.修改ACL的版本
- ephemeralOwner The session id of the owner of this znode if the znode is an ephemeral node. If it is not an ephemeral node, it will be zero.临时节点是被哪个session id创建的,如果不是临时节点则是0
- dataLength The length of the data field of this znode.数据字段的长度
- numChildren The number of children of this znode.children数量
Session
ZooKeeper客户端使用语言绑定与ZooKeeper建立的session。在正常操作期间session将处于连接启动和已连接2种状态之一。如果出现不可恢复的错误,例如会话过期或身份验证失败,或者如果应用程序显式关闭句柄,则session将会关闭状态。下图显示ZooKeeper客户端可能的状态转换:
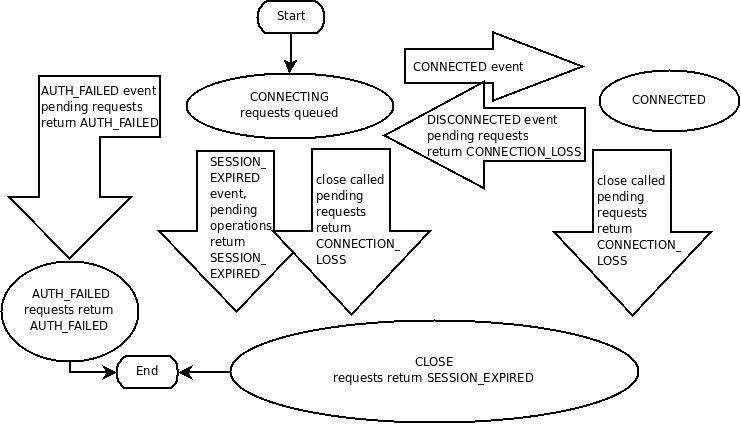
ZooKeeper使用连接字符串连接到集群,例如"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002"。
在3.2.0新增了chroot作为后缀的特性,类似Unix的chroot改变根目录,例如"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002/app/a"将把/app/a作为跟目录,“/foo/bar”将在“/app/a/foo/bar”上运行操作。
session当前的实现要求超时时间至少为tickTime的2倍(在服务器配置中设置),最多为tickTime的20倍。
当ZK集群发生网络分区时,客户端将开始搜索服务器列表。最终,当客户端和至少一台服务器之间的连接重新建立时,会话将再次转换为“已连接”状态(如果在会话超时值内重新连接),或者转换为“已过期”状态(如果在会话超时后重新连接)。不建议为断开连接创建新的session,ZK客户端库将处理重新连接。特别是,在客户端库中内置了启发式算法来处理“从众效应”等问题。。。仅在收到会话到期通知时创建新会话(强制)。
会话过期由ZooKeeper群集本身管理,而不是由客户端管理。当ZK客户机与集群建立会话时,它会提供上面详述的“超时”值。集群使用此值确定客户端会话何时过期。当集群在指定的会话超时期间(即没有心跳)内没有收到客户端的消息时,就会发生过期。在会话到期时,集群将删除该会话拥有的所有临时节点,并立即通知所有watch这些znode的客户端。此时,已过期会话的客户端仍与群集断开连接,除非它能够重新建立与群集的连接,否则不会收到会话过期的通知。客户端将保持断开连接状态,直到与集群重新建立TCP连接,此时过期会话的观察者将收到“会话过期”通知。以下是案例过程
- 'connected' : session is established and client is communicating with cluster (client/server communication is operating properly) session正常建立连接并通讯中
- .... client is partitioned from the cluster 客户端所在的server发生分区(脱离了集群)
- 'disconnected' : client has lost connectivity with the cluster 客户端失去了集群连接
- .... time elapses, after 'timeout' period the cluster expires the session, nothing is seen by client as it is disconnected from cluster 过了一会儿,达到集群超时时间,当客户端从群集断开连接时,客户端看不到任何内容
- .... time elapses, the client regains network level connectivity with the cluster 过了一会儿,客户端重新恢复了与正确的集群的网络连接
- 'expired' : eventually the client reconnects to the cluster, it is then notified of the expiration 最后客户端重新连接,会收到超时通知
本地session(3.5.0新特性)
在ZooKeeper中,会话的创建和关闭成本很高,因为它们需要仲裁确认。当ZooKeeper集成需要处理数千个客户端连接时,会话成为其瓶颈。因此引入了一种新类型的会话:本地会话,它没有普通(全局)会话的全部功能,通过启用LocalSessionEnabled,可以使用此功能。
禁用LocalSessionUpgradinEnabled时,本地session不能创建临时节点,启用LocalSessionUpgradingEnabled时,本地会话可以自动升级到全局会话。
Watch
所有的读操作都可以设置watch,watch有几个特点:
- One-time trigger 当数据发生改变时向客户端发送event,例如一个客户端使用getData("/znode1", true),然后/znode1的数据改变或删除,客户端就会收到/znode1的event,如果/znode1再次改变,则客户端不会收到event,除非再次设置watch.
- Sent to the client watch以异步方式发送给观察者。ZooKeeper提供了一个顺序保证:客户机在第一次看到watch事件之前,永远不会看到它设置了watch的更改。网络延迟或其他因素可能导致不同的客户端在不同的时间看到手表并返回更新代码。关键的一点是,不同客户看到的所有东西都有一个一致的顺序。
- The data for which the watch was set 这是指节点可以改变的不同方式。它有助于将ZooKeeper视为维护两个watch列表:data watches 和 child watches。getData()和exists()设置data watches。getChildren()设置child watches。或者,可以考虑根据返回的数据类型设置手表。getData()和exists()返回有关节点数据的信息,而getChildren()返回子节点列表。因此,setData()将触发正在设置的znode的data watches (假设设置成功)。成功创建()将触发正在创建的znode的data watches 和父znode的child watches。成功的delete()将触发要删除的znode的data watches 和child watches (因为不能再有子监视)以及父znode的子监视。
3.6.0中的新增功能:客户机还可以在znode上设置永久的递归监视,这些监视在触发时不会被删除,并且可以递归地触发已注册znode以及任何子znode上的更改。
watch的对应关系
- Created event: Enabled with a call to exists.
- Deleted event: Enabled with a call to exists, getData, and getChildren.
- Changed event: Enabled with a call to exists and getData.
- Child event: Enabled with a call to getChildren.
持久的、递归的watch
这些watch会触发事件类型NodeCreated、NodeDeleted和NodeDataChanged,并且可以选择递归地触发从监视注册的znode开始的所有znode。对于持久递归监视,不会触发NodeChildrenChanged事件,因为它是冗余的。
使用addWatch()方法设置持久watch。触发语义和保证(一次性触发除外)与标准watch相同。关于事件的唯一例外是递归持久性观察程序从不触发子更改事件,因为它们是冗余的。使用具有watcher类型WatcherType.Any的removeWatches()删除持久watch。
删除watch
可以通过调用removeWatches删除在znode上注册的watch。此外,ZooKeeper客户端可以通过将 local flag 设置为true,在没有服务器连接的情况下本地删除。以下列表详细说明了成功移除watch后将触发的事件。
- Child Remove event: Watcher which was added with a call to getChildren.
- Data Remove event: Watcher which was added with a call to exists or getData.
- Persistent Remove event: Watcher which was added with a call to add a persistent watch.
watch的保证
watch是根据其他事件、其他watch和异步回复进行排序的。ZooKeeper客户端lib确保按顺序调度所有内容。
在看到与该znode对应的新数据之前,客户端将看到它正在监视的znode的监视事件。
ZooKeeper的观察事件顺序与ZooKeeper服务看到的更新顺序相对应。
对watch要记住的事情
.标准watch是一次性触发器;如果获得了一个监视事件,并且希望获得有关未来更改的通知,则必须设置另一个监视。
.由于标准watch是一次性触发器,并且在获取事件和发送新请求获取watch之间存在延迟,因此无法可靠地看到ZooKeeper中节点发生的每个更改。准备好处理znode在获取事件和再次设置watch之间多次更改的情况。(你可能不在乎,但至少意识到它可能发生。)
.对于给定的通知,watch object或函数/上下文对只会触发一次。例如,如果为同一文件的exists和getData调用注册了同一个watch object,并且该文件随后被删除,则该watch object将仅在文件的删除通知中被调用一次。
.当断开与服务器的连接时(例如,当服务器出现故障时),在重新建立连接之前,将无法获得任何监视。因此,会话事件被发送到所有未完成的监视处理程序。使用session event进入安全模式:断开连接时将不会接收事件,因此进程应在该模式下保守操作。
ACL
ZooKeeper使用ACL控制对其ZNode的访问。ACL实现与UNIX文件访问权限非常相似:它使用权限位来允许/禁止对节点和应用权限位的范围执行各种操作。与标准UNIX权限不同,ZooKeeper节点不受用户(文件所有者)、组和世界(其他)三个标准作用域的限制。ZooKeeper没有一个znode所有者的概念。相反,ACL指定与这些ID关联的ID和权限集。
ACL不是递归的,ACL只与指定的znode相关,例如 /app只能通过ip:172.16.16.1读取,/app/status是世界可读的,则任何人都可以读取/app/status .
ACL权限
- CREATE: you can create a child node
- READ: you can get data from a node and list its children.
- WRITE: you can set data for a node
- DELETE: you can delete a child node
- ADMIN: you can set permissions
一致性保证
ZooKeeper是一种高性能、可扩展的服务。虽然读操作比写操作快,但读操作和写操作都设计得很快。原因是,在读取的情况下,ZooKeeper可以提供较旧的数据,这反过来是由于ZooKeeper的一致性保证:
-
Sequential Consistency顺序一致性 : 客户端发起的更新将按发送顺序执行.
-
Atomicity 原子性: 要么全部成功,要么全部失败.
-
Single System Image 单系统image: 客户端将看到相同的服务视图,而不管它连接到哪个ZooKeeper server.
-
Reliability 可靠性: 一旦有更新就会持久化,直到下次又被更新:
- 如果客户机获得成功的返回代码,则表示已应用了更新;而对于某些故障(通信错误、超时等),客户端将不知道是否应用了更新。我们采取措施尽量减少故障,但只有在client收到成功返回代码时才能完全保证,否则是尽可能保证。(这在Paxos中称为单调性条件。)
- 当从服务器故障中恢复时,客户端通过读取请求或成功更新看到的任何更新都不会回滚.
-
Timeliness 及时性: 保证系统的客户端视图在一定时间范围内是最新的。
这里有个需要注意的事项,看下面这个例子:
*同时一致的跨客户端视图*:ZooKeeper不保证在每个时间实例上,两个不同的客户端将具有相同的ZooKeeper数据视图。由于网络延迟等因素,一个客户端可能会在另一个客户端收到更改通知之前执行更新。考虑两个客户端A和B的场景。如果客户端A从0到1设置znode /a的值,那么告诉客户端B读/ A,客户端B可以读取0的旧值,这取决于它连接到哪个服务器。如果客户端A和客户端B读取相同的值很重要,那么客户端B应该在执行读取之前从ZooKeeper API方法调用sync()方法。因此,ZooKeeper本身并不保证在所有服务器上同步发生更改,但ZooKeeper原语可用于构建更高级别的函数,以提供有用的客户端同步。
通过这个例子我们可以知道ZooKeeper集群中的数据在同一时刻可能并不是强一致性的,对于CAP的C有它自己的特点。
常见问题
- If you are using watches, you must look for the connected watch event.当ZooKeeper客户端与服务器断开连接时,在重新连接之前,不会收到更改通知。如果正在监视znode的存在,如果在断开连接时创建并删除znode,将错过该事件。
- 您必须测试ZooKeeper服务器故障。使用由多台服务器组成的ZooKeeper服务进行测试,然后让它们重新启动。尽管ZooKeeper只要大多数服务器处于活动状态,就可以在故障中生存。但必须确保恢复状态和任何未完成的失败请求。
- 客户端的连接串最好使用整个ZooKeeper的server列表地址,虽然填错几个也可以工作,但不是最好的.
- ZooKeeper最关键的性能部分是transaction log。ZooKeeper必须在返回响应之前将事务同步到媒体。使用专用transaction log设备是保持良好性能的关键。将日志放在繁忙的设备上会对性能产生不利影响。如果只有一个存储设备,请将跟踪文件放在NFS上并增加快照计数;它不能消除问题,但可以缓解问题.
- 正确设置Java最大堆大小。避免swapping是非常重要的。在ZooKeeper中,一切都是有序的,因此,如果一个请求命中磁盘,则所有其他排队的请求都命中磁盘。为了避免交换,将heapsize设置为拥有的物理内存量减去操作系统和缓存所需的量。为配置确定最佳堆大小的最佳方法是运行负载测试。例如,在4G机器上,3G堆是一个保守的估计.
