


ZooKeeper概览
先来看官方对什么是zookeeper的描述:
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.
翻译:ZooKeeper是一种集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。所有这些类型的服务都以某种形式被分布式应用程序使用。每次实现它们时,都会有大量的工作用于修复不可避免的bug和竞争条件。由于实现这类服务的困难,应用程序最初通常会忽略它们,这使得它们在发生变化时变得脆弱,难以管理。即使操作正确,这些服务的不同实现在部署应用程序时也会导致管理复杂性。
意思大致是ZooKeeper专门用于 configuration information(配置信息), naming(命名), distributed synchronization(分布式同步), group services(分组服务);这些属于可复用的基础能力,如果每个系统都开发这样一套就会有大量的工作和bug,而且开发前期往往会忽略这些问题,到后期就很难维护,所以为了避免问题和重复造轮子,用ZooKeeper。
进一步来看官方overview对zk的描述
ZooKeeper的设计点:
简单:
ZooKeeper允许分布式进程通过共享的分层namespace相互协调,该namespace的组织方式类似于标准文件系统。namespace由数据寄存器组成——用ZooKeeper的说法,称为znode——这些寄存器类似于文件和目录。与为存储而设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟数。
ZooKeeper的实现使高性能、高可用性和严格有序的访问成为可能。ZooKeeper的性能方面意味着它可以用于大型分布式系统。可靠性方面使其不会成为单点故障。严格的排序意味着复杂的同步原语可以在客户端实现。
复制:
与它所协调的分布式进程一样,ZooKeeper本身旨在通过一组称为ensemble的主机进行复制。
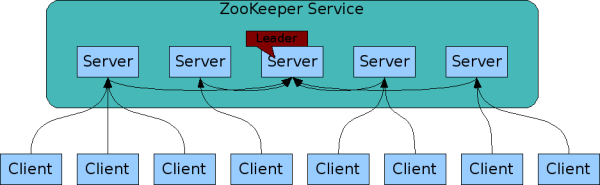
ZooKeeper的servers之间都知道相互之间的存在。它们维护状态的内存image,以及持久存储中的事务日志和快照。只要大多数服务器都可用,ZooKeeper服务就会可用。
客户端连接到单个server。客户端维护一个TCP连接,通过该连接发送请求、获取响应、获取watch event和发送心跳。如果与服务器的TCP连接中断,客户端将连接到其他server。
有序:
ZooKeeper在每次更新上都贴上一个数字,该数字反映了所有ZooKeeper事务的顺序。后续操作可以使用顺序实现higher-level abstractions,例如synchronization primitives。
快速:
它在“以读取为主”的工作负载中速度特别快。ZooKeeper应用程序在数千台机器上运行,在读操作比写操作更常见的情况下,它的性能最好,比率约为10:1。
ZooKeeper的数据模型和分层namespace:
下图就是ZooKeeper提供的namespace,与标准文件系统的名称空间非常相似。
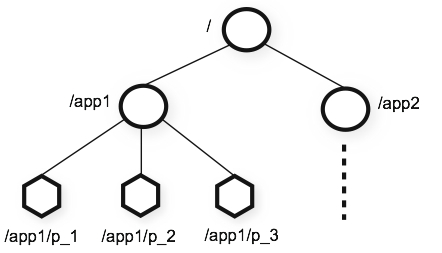
ZooKeeper的节点和临时节点:
与标准文件系统不同,ZooKeeper命名空间中的每个节点都可以有与其关联的数据以及子节点。这就像有一个文件系统,允许一个文件也成为一个目录。(ZooKeeper设计用于存储协调数据:状态信息、配置、位置信息等,因此每个节点上存储的数据通常很小,在字节到千字节的范围内。)使用znode一词来明确我们所说的ZooKeeper数据节点。
znode维护一个stat结构,其中包括数据更改、ACL更改和时间戳的版本号,以允许缓存验证和协调更新。每次znode的数据更改时,版本号都会增加。例如,每当客户机检索数据时,它也会收到数据的版本。
存储在名称空间中每个znode上的数据是以原子方式读取和写入的。读取获取与znode关联的所有数据字节,写入替换所有数据。每个节点都有一个访问控制列表(ACL),用于限制谁可以做什么。
ZooKeeper也有临时节点的概念。只要创建znode的session处于活动状态,这些znode就会存在。session结束时,znode将被删除。
ZooKeeper的条件更新和watch:
watch即监视,等待事件的通知。
ZooKeeper支持watch的概念。client可以在znode上设置watch。当znode发生变化时,将触发并移除watch。当一个watch被触发时,客户端收到一个数据包,表明znode已经改变。如果客户端和ZooKeeper server之间的连接断开,客户端将收到local notification。
3.6.0中的新增功能:客户机还可以在znode上设置永久的递归watch,这些watch在触发时不会被删除,并且可以递归地触发已注册znode以及任何子znode上的更改。
ZooKeeper的保证:
ZooKeeper非常快速和简单。但是,由于它的目标是作为构建更复杂服务(如同步)的基础,因此它提供了一组保证。这些是:
Sequential Consistency顺序一致性 - 客户端的更新将按发送顺序执行。
Atomicity原子性 - 更新要么全部成功,要么全部失败。
Single System Image单系统image - 客户端将看到相同的服务视图,而不管它连接到哪个ZooKeeper server。即CAP的C,一致性。
Reliability可靠性 - 一旦有更新就会持久化,直到下次又被更新。
Timeliness及时性 - 保证系统的客户端视图在一定时间范围内是最新的。即快速。
ZooKeeper的API简单:
ZooKeeper的设计目标之一是提供一个非常简单的编程接口。因此,它仅支持以下操作:
-
create : creates a node at a location in the tree
-
delete : deletes a node
-
exists : tests if a node exists at a location
-
get data : reads the data from a node
-
set data : writes data to a node
-
get children : retrieves a list of children of a node
-
sync : waits for data to be propagated
ZooKeeper的实现:
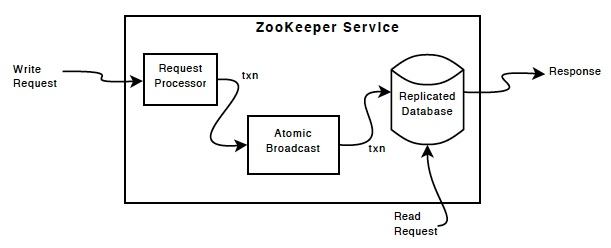
replicated database是包含整个数据树的内存中数据库。更新会记录到磁盘以实现可恢复性,写入操作会在应用到内存中数据库之前序列化到磁盘。
每个ZooKeeper服务器都为客户端提供服务。客户端只连接到一台服务器以提交请求。读取请求由每个服务器数据库的本地副本提供服务。更改服务状态的请求(写请求)由协议协议处理。
来自客户端的所有写请求都被转发到一个名为leader的服务器。其余的ZooKeeper服务器(称为followers)接收来自leader的消息,并同意消息传递。消息传递层负责在发生故障时更换leader,并将followers 与leader同步。
ZooKeeper使用自定义的原子消息传递协议。由于消息传递层是原子层,ZooKeeper可以保证本地副本不会发散(diverge)。当leader收到写入请求时,它计算应用写入时系统的状态,并将其转换为捕获此新状态的事务。
ZooKeeper的使用:
尽管ZooKeeper的编程接口非常简单。但是可以实现更高阶的操作,例如synchronizations primitives, group membership, ownership等。
ZooKeeper的性能:
ZooKeeper被设计成高性能的。但是是吗?雅虎的ZooKeeper's 开发团队的结果!研究表明确实如此。(请参阅ZooKeeper吞吐量,因为读写比率不同。ZooKeeper Throughput as the Read-Write Ratio Varies)在读多于写的应用程序中,它的性能尤其高,因为写操作涉及同步所有服务器的状态。(对于协调服务来说,读取的数量通常超过写入的数量。)
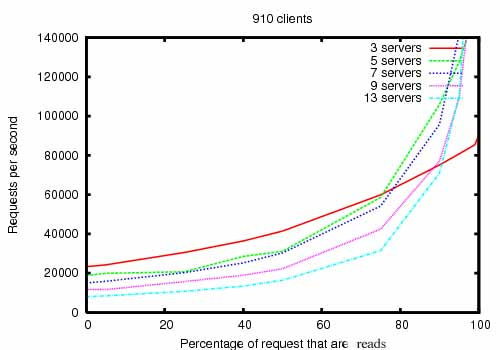
ZooKeeper的吞吐量随着读写比的变化而变化,这是ZooKeeper 3.2版的吞吐量图,运行在具有双2Ghz Xeon和两个SATA 15K RPM驱动器的服务器上。一个驱动器用作专用的ZooKeeper日志设备。快照已写入操作系统驱动器。写入请求为1K次写入,读取为1K次读取。“servers”表示ZooKeeper server的数量。大约30台其他服务器被用来模拟客户端。ZooKeeper集成已配置为leader不允许来自客户端的连接。
基准测试也表明ZooKeeper是可靠的。存在错误时的可靠性显示集群如何响应各种故障。图中标记的事件如下所示:
- Failure and recovery of a follower
- Failure and recovery of a different follower
- Failure of the leader
- Failure and recovery of two followers
- Failure of another leader
最后补充关于性能的官方优化推荐:要获得较低的更新延迟,必须有一个专用的transaction log目录。默认情况下,transaction log与数据快照和myid文件放在同一目录中。dataLogDir参数用于transaction log的不同目录配置。
ZooKeeper的可靠性:
为了显示发生故障时系统随时间的行为,运行一个由7台机器组成的ZooKeeper服务。运行与以前相同的饱和基准测试,但这次将写百分比保持在恒定的30%,这是预期工作负载的保守比率。
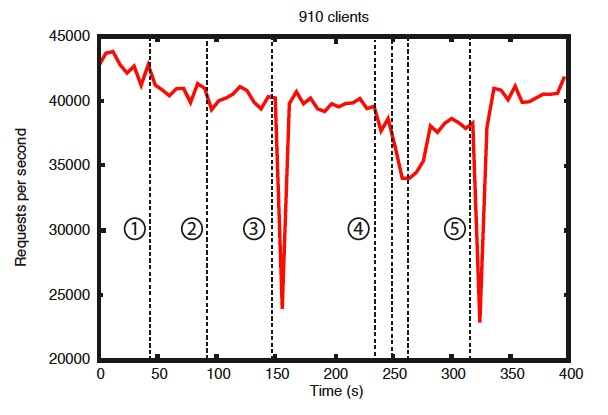
从这张图中有一些重要的观察结果。首先,如果followers失败并快速恢复,那么ZooKeeper能够在失败的情况下保持高吞吐量。但也许更重要的是,leader选举算法允许系统足够快地恢复,以防止吞吐量大幅下降。根据我们的观察,ZooKeeper用不到200ms的时间选出一位新的leader。第三,随着followers的恢复,ZooKeeper能够在他们开始处理请求后再次提高吞吐量。
