


Elasticsearch Index模块
Index配置
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/index-modules.html#index-modules-settings
static
static的配置只能在 closed index 时才能修改。
index.number_of_shards 默认1,最大1024,该参数即使close了index也不能修改
dynamic
dynamic的配置可以通过RESTAPI update-index-settings 动态修改。
index.number_of_replicas 默认1
index.max_result_window 默认10000index.max_inner_result_window 默认100index.max_rescore_window 默认10000index.max_docvalue_fields_search 一次查询最多文档数量,默认100index.max_script_fields 最多script_fields限制,默认32
index.max_regex_length 正则查询的最大长度,默认1000index.query.default_field-
控制以下查询在哪些字段上进行,默认*
index.routing.allocation.enable 控制shard的分配,默认all,可选all、primaries、replicas、noneindex.routing.rebalance.enable 默认all,可选all、primaries、replicas、noneindex.gc_deletes 默认60s
Index Shard Allocation索引分片分配
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/index-modules-allocation.html
Index级别分片分配过滤器
node节点的配置中,可以配置attribute打标签,例如 node.attr.size: medium
Index的设置可以使用对应的attribute条件进行分配,例如
PUT test/_settings 分配给size是big或medium的节点
{
"index.routing.allocation.include.size": "big,medium"
}
PUT test/_settings 分配给size是big且rack是rack1的节点
{
"index.routing.allocation.include.size": "big",
"index.routing.allocation.include.rack": "rack1"
}
条件匹配规则
index.routing.allocation.include.{attribute} 至少符合1个,逗号分割
index.routing.allocation.require.{attribute} 全部符合,逗号分割
index.routing.allocation.exclude.{attribute} 全部都不能符合,逗号分割
已内置的attr有:
|
|
Match nodes by node name |
|
|
Match nodes by host IP address (IP associated with hostname) |
|
|
Match nodes by publish IP address |
|
|
Match either |
|
|
Match nodes by hostname |
|
|
Match nodes by node id |
条件匹配可以使用通配符
PUT test/_settings
{
"index.routing.allocation.include._ip": "192.168.2.*"
}
节点离开后的延迟分片分配
当节点出于任何原因离开集群时,master节点的反应是:
将replica shard升级为primary shard(如果有replica shard)。
分配replica shard以替换丢失的replica shard(假设有足够的节点)。
在其余节点上均匀地重新平衡shard。
如果节点只是短暂的离开(网络原因),节点加入后将触发分片再均衡,若频繁发生这种清空将给集群带来较大负担,因此有节点离开后延迟分配。
若没有延迟分配机制,则场景会是这样:
节点5失去网络连接。
对于节点5上的每个primary shard,master将replica shard升级到primary shard。
master将新replica shard分配给群集中的其他节点。
每个新replica shard都会通过网络进行复制。
将更多的shard移动到不同的节点以重新平衡集群。
节点5在几分钟后返回。
master通过将shard分配给节点5来重新平衡集群。
可以通过 index.unassigned.node_left.delayed_timeout 动态配置延迟大小,默认1m
PUT _all/_settings 可以在指定离开的index上或_all设置
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
在延迟分配机制下,就会是这样:
节点5失去网络连接。
对于节点5上的每个primary,master将replica升级到primary。
master会记录一条消息,说明未分配shard的分配已延迟,以及延迟了多长时间。
群集保持黄色,因为存在未分配的replica shard。
节点5在几分钟后,即超时到期之前返回。
丢失的replica被重新分配给节点5(同步刷新的shard几乎立即恢复)。
NOTE:此设置不会影响将replica升级到primary(即只影响新的replica分配),也不会影响以前未分配的副本的分配。特别是,延迟分配在集群完全重启后不会生效。此外,在主故障切换情况下,经过的延迟时间被遗忘(即重置为完全初始延迟)。
运维技巧 删除节点场景:即某节点永远不会回来,并且希望Elasticsearch立即分配丢失的碎片,只需将超时更新为零
PUT _all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "0"
}
}
索引恢复优先级
优先级按照
可选的index.priority设置
索引创建日期
索引名称
这意味着,默认情况下,较新的索引将在较旧的索引之前恢复。
可以使用 index.priority 设置优先级,数字越大越高。
PUT index_4
{
"settings": {
"index.priority": 5
}
}
或
PUT index_4/_settings
{
"index.priority": 1
}
每个节点总分片数
集群需要尽可能的在各个节点上均衡的分配分片,支持以下配置
index.routing.allocation.total_shards_per_node Index维度,单个节点上最多分片数(主分片和副本分片),默认无界。
cluster.routing.allocation.total_shards_per_node 全局维度,单个节点上最多分片数(主分片和副本分片),默认无界。
Index Blocks 索引限制
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/index-modules-blocks.html
可以阻止写、读或元数据操作。
支持配置:
index.blocks.read_only true则index和index metadata只读
index.blocks.read_only_allow_delete 只读但允许删除操作
index.blocks.read true则禁止读
index.blocks.write true则禁止写,但不影响metadata。例如,可以用写块关闭索引,但不能用只读块关闭索引。
index.blocks.metadata true则禁止读写
索引的Mapper 见 Elasticsearch Mapping
translog 事务日志
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/index-modules-translog.html
与其他分布式系统的刷盘相似,由于Lucene的commit代价很高,因此写操作数据会先进入translog(系统页缓存),当崩溃时从translog回复
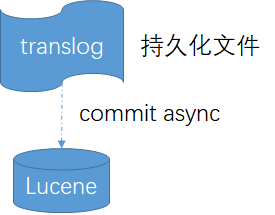
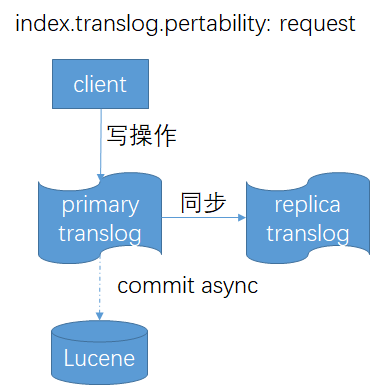
默认情况下,index.translog.pertability设置为request,就会在每次写操作请求时都执行fsync写入translog,这意味着需要在primary和每个replica的副本上成功同步和提交后,才会向客户端报告索引、删除、更新或批量请求的成功。
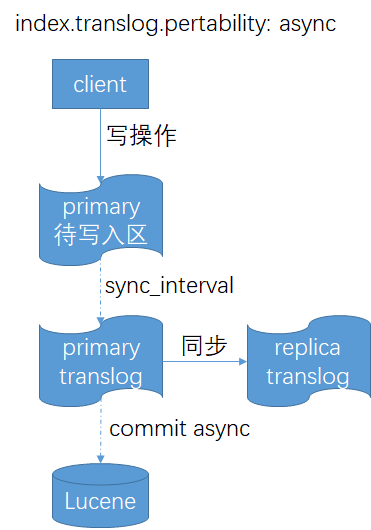
如果index.translog.pertability设置为async,就会使用 定时 同步机制 index.translog.sync_interval 把数据fsync到primary和每个replica的translog,这意味着在primary中尚未写入translog的数据当primary崩溃时会丢失,当然选择该方式可以提升一定的性能。
支持以下配置:
index.translog.sync_interval translog同步到磁盘并提交的频率。默认为5s。不允许小于100ms的值。
index.translog.durability request(默认)和async
index.translog.flush_threshold_size translog的文件大小,一旦达到最大大小,就会发生刷新,生成一个新的Lucene提交点。默认值为512mb。translog如果太大,恢复时间就会长。
index.translog.retention.size 控制每个shard保留的translog文件的总大小。默认值为512mb。
index.translog.retention.age 控制每个shard保存translog文件的最长持续时间。默认为12小时。
History retention 历史保留
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/index-modules-history-retention.html
在Lucene级别,写操作只有两个:索引一个新文档或删除一个文档。由于副本复制或跨集群复制时需要这2种数据信息,而索引一个新文档本身就已包含了数据信息,但删除操作的动作信息需要在一段时间内保留,因此有配置支持保留时间。
index.soft_deletes.retention_lease.period 默认12h。
Index Sorting 索引排序
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/index-modules-index-sorting.html
index的每个shard内的文档可以进行排序(注意是每个shard),默认不排序。
PUT my-index-000001
{
"settings": {
"index": {
"sort.field": "date",
"sort.order": "desc"
}
},
"mappings": {
"properties": {
"date": {
"type": "date"
}
}
}
}
PUT my-index-000001 配置多个字段的排序
{
"settings": {
"index": {
"sort.field": [ "username", "date" ],
"sort.order": [ "asc", "desc" ]
}
},
"mappings": {
"properties": {
"username": {
"type": "keyword",
"doc_values": true
},
"date": {
"type": "date"
}
}
}
}
支持以下配置:
index.sort.field 排序的字段,仅支持 boolean, numeric, date and keyword
index.sort.order asc 或 desc
index.sort.mode 由于排序支持多值的字段,因此需要配置取多值中的哪个值进行排序,min 或 max
index.sort.missing missing参数指定应如何处理缺少该字段的文档,可以选择排到 _last 或 _first
默认情况下,搜索请求必须访问与查询匹配的每个文档,但是当 index.sort.* 的配置与search的排序相同时,则可以使搜索提前结束以减少访问的文档数量。
例如下面这个例子就可以提前终止搜索请求得到正确的结果
PUT events 按timestamp倒排
{
"settings": {
"index": {
"sort.field": "timestamp",
"sort.order": "desc"
}
},
"mappings": {
"properties": {
"timestamp": {
"type": "date"
}
}
}
}
GET /events/_search 按timestamp的倒排search前10条
{
"size": 10,
"sort": [
{ "timestamp": "desc" }
]
}
GET /events/_search 不但提前结束,还进一步告诉ES不需要total字段,节省了ES内部一次count查询
{
"size": 10,
"sort": [
{ "timestamp": "desc" }
],
"track_total_hits": false
}
{ 不需要total字段的结果展示
"_shards": ...
"hits" : {
"max_score" : null,
"hits" : []
},
"took": 20,
"timed_out": false
}
Indexing pressure 索引压力
https://www.elastic.co/guide/en/elasticsearch/reference/7.15/index-modules-indexing-pressure.html
由于ES对每个索引都有一定的自动处理机制,如协调、主和副本阶段。如果在系统中引入太多的索引工作,集群可能会饱和。这可能会对其他操作产生不利影响,例如搜索、群集协调和后台处理。
为了防止这些问题,Elasticsearch在内部监视索引负载。当负载超过某些限制时,新的索引工作将被拒绝。
索引压力配置:
indexing_pressure.memory.limit索引请求可能使用的未完成字节数。当达到或超过此限制时,节点将拒绝新的协调和主操作。当副本操作消耗该限制的1.5倍时,节点将拒绝新的副本操作。默认值为堆的10%。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!